

Мы занимаемся построением хранилищ, Data Lake, платформ данных, ETL/EL-T и BI-систем. Последние 5–7 лет при построении хранилищ данных у наших заказчиков одна из часто встречаемых архитектур — Data Vault. Мы участвовали в доработке готовых хранилищ на базе Data Vault и делали Data Vault «с нуля».
Из опыта борьбы я вынес одно правило: Data Vault без фреймворка и автоматической генерации — большая беда. В этом посте расскажу, почему, а также поделюсь нашими подходами к созданию генератора. Сразу предупреждаю, что не дам готовых рецептов, но расскажу о наших основных подходах и что они нам дали.
Кому будет интересна эта статья?
Вы делаете Data Vault руками и подумываете его автоматизировать.
У вас есть генератор/фреймворк для Data Vault и вы хотите сравнить подходы.
Вы собираетесь строить хранилище и рассматриваете различные архитектурные подходы.
На всякий случай определимся с понятиями.
Data Vault — это архитектурный подход к построению хранилищ данных, в котором данные представляются в виде трех сущностей, каждая из которых проецируется в отдельную таблицу:
HUB — неизменяемая часть сущности (бизнес-ключ).
LINK — связь между HUB (все связи хранятся отдельно).
SATELLITE (SAT) — изменяемая часть атрибутов сущностей (историчность SCD2). SAT хранит атрибуты одного HUB или LINK, при этом для каждого HUB и LINK может быть несколько SAT.

По сути, Data Vault разделяет объекты (HUB) и их связи (LINK), а также обеспечивает отдельное хранение истории изменения атрибутов (SAT). Более детально архитектура описана в книге Daniel Linstedt, Michael Olschimke «Building a Scalable Data Warehouse with Data Vault 2.0» ну или во множестве постов на Habr.
Зачем вообще нужна генерация в DV?
Успешность проекта по созданию/модификации Data Vault, на мой взгляд, зависит прежде всего от наличия фреймворка с автоматической генерацией как структуры Data Vault, так и EL‑T процессов.
Делать Data Vault руками — сплошная боль! Объясняю, почему:
Приходится иметь дело с множеством таблиц с повторяемой структурой сервисных полей — можно легко ошибиться при их создании.
Необходим ручной контроль за правильностью связей объектов.
Повторяемый код в EL‑T, — не дай бог ошибиться в порядке расчета хеша по составному ключу на HUB и SAT.
Постоянно реализовывать один и тот же алгоритм SCD2 для каждого SAT очень утомительно.
Общее количество таблиц и EL‑T потоков в разы превышает их количество в стандартных проектах по построению хранилищ.
Поэтому, реализовывая проект по построению Data Vault с нуля, мы создали и использовали свой фреймворк, содержащий генератор структур и EL‑T для Data Vault. О подходах к его построению я сейчас расскажу.
Что под капотом? Структура генератора
Общие требования к созданию генератора у нас были следующие:
На вход подается описание Data Vault в понятном для системных аналитиков виде.
Перед генерацией кода выполняется проверка корректности перевода Data Vault из старого состояния в требуемое. Если такой переход некорректен, то генерация не происходит (сообщение об ошибках).
Генерация автоматическая — в код, созданный генератором, программисты не должны вмешиваться.
Возможность проверить сгенерированный код перед его применением.
Генерация создания и допустимых модификаций таблиц Data Vault.
Генерация EL‑T процедур для каждого HUB/SAT/LINK.
По возможности — генерация правил контроля качества данных.
В итоге у нас получился генератор, который выполняет следующие шаги:
На вход подается Excel файл, описывающий на разных вкладках: HUB/LINK, SAT, атрибуты всех сущностей, а также маппинг атрибутов на источники данных.
Генератор проводит валидацию поданной структуры относительно текущей структуры Data Vault и если в новой структуре есть ошибки — останавливает свою работу.
Генерирует SQL‑код по созданию/модификации таблиц Data Vault.
Генерирует SQL‑код по созданию EL‑T хранимых процедур для загрузки данных.
Генерирует SQL‑код для создания/отключения правил Data Quality.
Генерирует вспомогательный SQL‑код по модификации метасловаря системы, например, регистрация или, наоборот, выключение процедур загрузки.
Таким образом, если всё хорошо, на выходе генератора получаем набор SQL, который может быть проверен глазами и выполнен по указанию администратора системы.
Ниже я хотел бы остановиться на отдельных аспектах работы генерации.
Семь раз отмерь, один раз отрежь. Валидация входного описания
Валидация — это первый важный этап. Мы загружаем описание новой структуры в наш метаслой и сравниваем его с текущей структурой Data Vault и Stage-области. Мы не храним текущую структуру Data Vault, а получаем ее из системного словаря базы данных, чтобы быть уверенными в ее актуальности. Мы запрещаем вносить изменения в таблицы Data Vault руками, но по факту заказчик такое пару раз делал (например, увеличивал размерности полей), и то, что мы берем текущую структуру из словаря базы данных, спасало нас от ошибок.
Каждая проверка реализована в виде отдельной хранимой процедуры, что позволяет нам легко добавлять новые проверки.
На данный момент мы выполняем 22 проверки, например (приведены не все):
-
Базовые проверки:
корректность наименования идентификаторов;
корректность типов данных;
наличие атрибутов.
Проверки новой структуры на соответствие текущей структуре Data Vault.
-
Базовые проверки EL‑T:
для всех ли NOT NULL полей HUB/LINK/SAT описаны маппинги загрузки;
проверка, что если есть загрузка SAT, то есть и загрузка его HUB/LINK.
-
Проверки EL‑T на соответствие структуре Data Vault и источников данных:
корректность полей ссылок;
наличие таблицы источника в БД;
наличие колонки таблицы источника в БД;
тип данных колонки в источнике в БД совместим с типом данных в Data Vault.
Если все проверки пройдены успешно, мы переходим к генерации, т. е. мы создаем список ошибок для дальнейшего анализа.
Гибкость. Шаблоны

Вместо того, чтобы использовать хардкод SQL внутри себя, генератор использует шаблоны. И если необходимо поменять, например, параметры хранения таблиц или добавить служебные поля, нет необходимости менять код генератора, достаточно поправить шаблон генерации.
Например, для генерации таблицы SAT шаблон выглядит так:
CREATE TABLE DV.SAT_{{OBJECT_NAME}}
{{REF_OBJECT_TYPE}}_{{REF_OBJECT_NAME}}_HSK CHAR(32) NOT NULL,
SAT_{{OBJECT_NAME}}_LDTS TIMESTAMP NOT NULL,
SAT_{{OBJECT_NAME}}_EDTS TIMESTAMP,
SAT_{{OBJECT_NAME}}_RSRC VARCHAR(128) NOT NULL,
SAT_{{OBJECT_NAME}}_HDIFF CHAR(32) NOT NULL,
{{ATTRIBUTES}},
CONSTRAINT pk_SAT_{{OBJECT_NAME}} PRIMARY KEY ({{REF_OBJECT_TYPE}}_{{REF_OBJECT_NAME}}_HSK, SAT_{{OBJECT_NAME}}_LDTS)'
');
{{FOREIGN_KEY}}Идентификатор в {{}} генератор заменяет на конкретные значения при генерации.
При этом допустима вложенность, например, FOREIGN_KEY из примера выше описывается вот так:
ALTER TABLE DV.{{OBJECT_NAME}} ADD CONSTRAINT
fk_{{REF_OBJECT_NAME}}_{{OBJECT_NAME}}_{{SHORT_COLUMN_NAME}} FOREIGN KEY
({{FULL_COLUMN_NAME}}) REFERENCES DV.{{REF_OBJECT_NAME}}
({{REF_COLUMN_NAME}});Использование корректировки шаблонов вместо кода позволяет нам существенно экономить время.
Потенциально это позволит нам в дальнейшем реализовывать генерацию для разных баз данных.
Генерация EL-T
Сгенерированные ET‑L процедуры грузят данные, выполняя всю сложную логику заполнения Data Vault. Например, для SAT считается хэш строки атрибутов и сравнивается с хэшем в БД. Если он поменялся, создается новая версия строки, а старая версия строки закрывается временем загрузки. Если хэш не менялся, ничего не происходит.
Логика для LINK (в случае связи «один ко многим») отслеживает, что произошла замена связи с одного объекта на другой (например, поменялся менеджер, ведущий заказ), и создает новую запись в таблице LINK, а старую помечает (запись в SAT этого LINK) как недействительную.
Один раз отладив кодогенератор, мы получили достоверно работающие процедуры для всего EL‑T. У одного из наших заказчиков их более 800 — представьте, как бы это выглядело, если всё это делать руками.
Но где же здесь трансформация?
Будь мы Google, мы бы, конечно, придумали свой язык :) Но мы не хотели тратить лишнее время, поэтому использовали для трансформации язык SQL. Мы в отдельном слое хранилища создаем представления (View) над объектами Stage-областей, в которых и проводим все необходимые трансформации и обогащение данных. А затем ссылаемся на эти View из описания, которое подается на вход генератора.
Всё работает примерно вот так (про волшебное DQ — ниже):
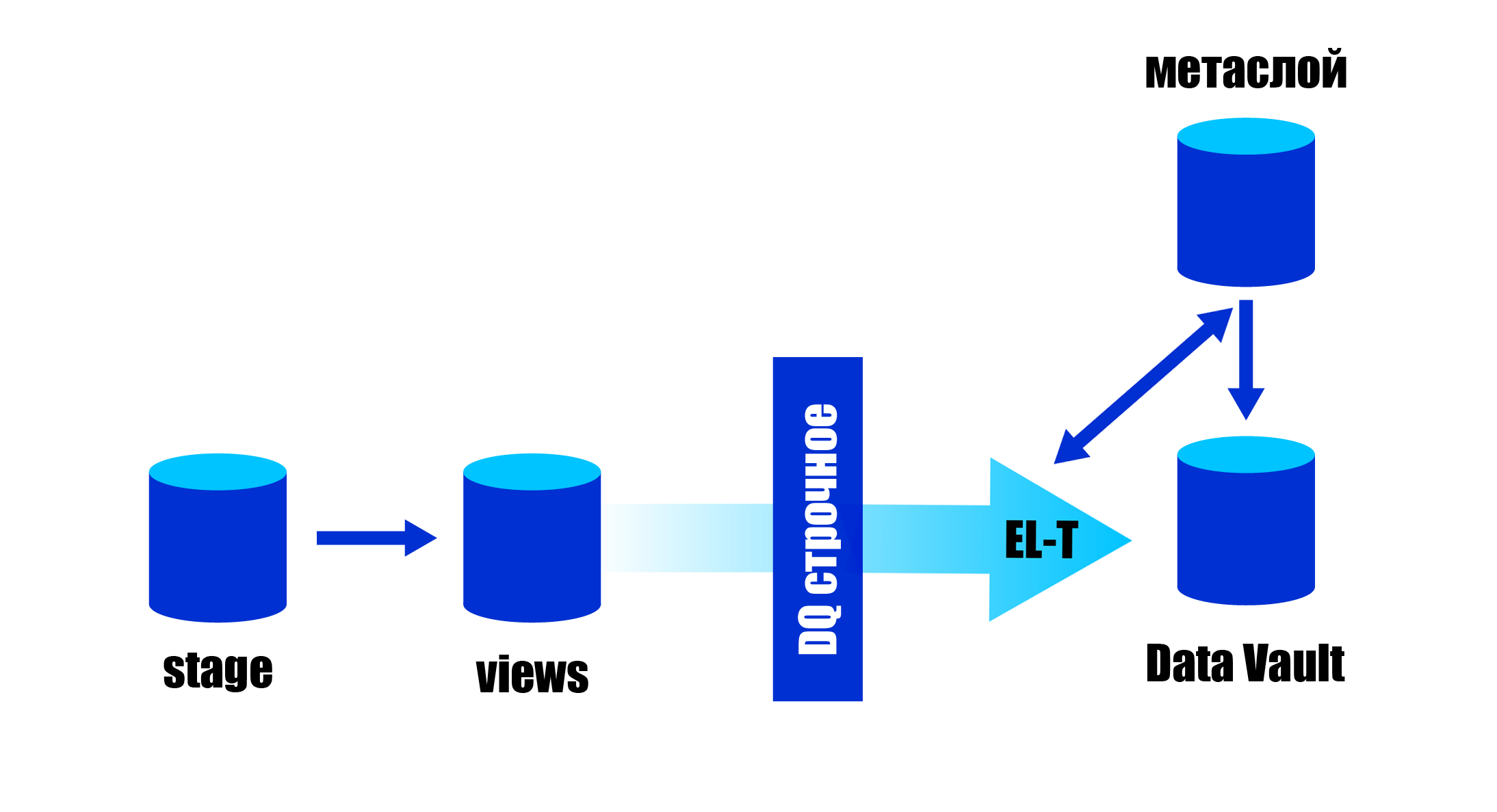
При этом одно View может использоваться для загрузки нескольких объектов. Например, из View факта продажи может грузиться соответствующий HUB, все его SAT, LINK «многие к одному» (связи с другими объектами и справочниками). Этот подход позволяет эффективно разделять рутину по загрузке (кодогенератор всё делает сам) и творческие задачи по трансформации данных.
Лирическое отступление: аналогичный подход реализован в популярном инструменте трансформации DBT. Описываете SELECT как источник данных, и DBT материализует его по вашему запросу. При этом в системе есть зависимости и встроенные средства оркестрации (порядок формирования). Сложную логику материализации (например, SCD2 или логику для LINK) придется делать руками, но если вам нужно просто формировать витрины по слоям, присмотритесь к DBT.
Доверяй, но проверяй. Генерация DQ

Когда вы грузите данные не построчно через ETL‑инструмент, а групповыми операторами типа INSERT SELECT, ошибка в любой загружаемой строке (например, NULL в NOT NULL колонке или дубликат первичного ключа) приведет к тому, что все данные не будут загружены.
Чтобы этого избежать, в нашем фреймворке Data Vault реализован механизм проверки качества данных.
Перед загрузкой данные проходят фильтр строчного Data Quality (DQ). По сути, подлежащие загрузке данные из View помещаются во временную таблицу, которая проверяется механизмом DQ.
Генератор автоматически создает проверки на дубликаты ключей и проверки на NULL в NOT NULL полях. Кроме того, инженер по контролю за качеством данных вручную может добавлять произвольные проверки, описанные на языке SQL.
При этом в случае обязательных проверок строки удаляются из временной таблицы и создаются инциденты DQ. Для произвольных проверок есть выбор — удалять данные или просто создать инцидент. После этого данные из временной таблицы загружаются в Data Vault. Для одного View проверка происходит один раз — независимо от того, сколько объектов Data Vault из него грузится.
Заключение
Выше я описал те подходы, которые мы использовали при построении кодогенератора нашего фреймворка Data Vault. На самом деле, конечно, наш фреймворк гораздо шире: тут и обвязка для параллельного запуска EL‑T, логирования работы, возможность группового постконтроля качества данных, версионирование, механизм создания PIT‑таблиц и многое другое. Но кодогенератор — это сердце фреймворка. И я попытался изложить основные подходы к его построению.
Не делайте Data Vault руками — кроме боли, страданий и ошибок, вы получите только замедление проекта в несколько раз из‑за количества таблиц и потоков ETL/EL‑T.
В результате применения фреймворка Time to Market сократился минимум в два раза при том же составе команды. На масштабе проекта в два года, даже учитывая затраты на разработку фреймворка, это дало существенную экономию. Ну и мы ни разу не имели в EL‑T проблем из‑за ошибок в его реализации.
Виктор Езерский, «Инфосистемы Джет».