

Всем привет! Меня зовут Николай Полушкин, я продуктовый аналитик в финансовом маркетплейсе Сравни. Недавно мы проводили тест-драйв новой системы A/B/n-тестирования, которую планируем внедрить в нашей компании. Хочу поделиться результатами с читателями Хабра, предупредить о подводных камнях и дать рекомендации тем, кто тоже планирует использовать многовариантное тестирование (MVT).
Как устроено А/B тестирование сейчас?
На данный момент аналитики нашей компании пользуются собственной системой A/B тестирования, которая реализована с использованием кук. Каждому продукту на сайте (а их у нас несколько десятков) определено свое уникальное название куки. Когда пользователь посещает сайт, сплитер системы A/B-тестов раздает куки всех активных тестов с соответствующим вариантом теста. То есть для каждого продукта — своя кука. Далее, когда пользователь попадает в один из продуктов, фронт реагирует на значение именно своей продуктовой куки и показывает пользователю определенный вариант дизайна.
Эта система оказалась достаточно работоспособной:
Она была относительно проста и понятна. Не составляло сложностей проверить корректность работы сплита в реальном времени и быстро фиксить баги.
Для аналитиков была написана админка, поэтому запуск теста отнимал минимальное кол-во времени.
Со стороны разработки требовались лишь минимальные доработки при запуске теста: нужно было реагировать на значение определенной куки.
Такая система позволяла проводить A/B тест на некоторой подвыборке пользователей (например, только для мобильного трафика или только для трафика с определенного канала).
Но в этой системе было и довольно важное ограничение — она могла разделять трафик только на две группы (для каждого продукта), поэтому у нас не было возможности проводить A/B/n-тестирование или несколько A/B тестов одновременно в рамках одного продукта.
Также, у системы иногда были проблемы с присваиванием значений кукам: мы детектировали случаи, когда сплит трафика проходил некорректно. Мы хотели расширить функциональность A/B тестирования, но совместно с разработкой пришли к выводу, что нынешний MVP невозможно доработать под необходимые требования. Нужно было писать систему заново, закладывая изначально более сложную логику. Мы оценили ресурсы для такого варианта и решили, что будет выгоднее воспользоваться внешней системой от EXPF.
Новая система
Довольно удачным выбором для нас оказалось коробочное решение Sigma от от экспертов в A/B тестировании, компании EXPF. Sigma представляет собой полноценную систему сплитования и полностью закрывает потребности аналитиков. С нашей стороны оставалось только протестировать и встроить эту систему в наши процессы.
Какие преимущества имеет новая система?
Один из главных плюсов Sigma — возможность A/B/n-тестирования, то есть попарного сравнения сразу нескольких вариантов интерфейса. Подробнее об этом расскажу чуть ниже.
Вторая ключевая фича — возможность проведения одновременного тестирования. В новой системе мы можем разделить входящий трафик на несколько групп и тем самым одновременно проводить независимые A/B-тесты.
Также изменится механика передачи данных в аналитику. Тестирование новой платформы показало, что новая механика работает корректнее. В частности, ушли некоторые проблемы с присвоением пользователям одного из вариантов теста.
Еще один плюс в том, что теперь у нас будет единая система для тестирования веб- и мобильного приложения, а приятным бонусом является возможность получить консультацию коллег из EXPF.
A/B/n-тестирование
В A/B/n-тестировании мы одновременно сравниваем не два, а сразу несколько вариантов интерфейса, его элементов или содержимого. Таким образом, трафик распределяется между этими вариантами в некоторой пропорции, в зависимости от конкретной задачи.
Давайте рассмотрим такой кейс. Представьте блок на странице, в котором есть несколько предложений финансовых продуктов (офферов). К каждому офферу ведет своя кнопка. И, например, мы хотим понять, сколько именно офферов вам нужно отрисовать в этом блоке, чтобы добиться максимальной конверсии.

В старой системе нам нужно было бы провести несколько последовательных A/B тестов, сравнивая разные конфигурации офферов, например, два против трех. Допустим, вариант с тремя офферами получает лучший результат. По итогам первого теста мы проводим второй, где сравниваем вариант с тремя офферами и вариант с четырьмя офферами. И так далее. Количество тестов будет зависеть от того, сколько вариантов компоновки вы придумаете.

В новой системе мы можем одновременно сравнить все варианты компоновки блока в одном тесте. Очевидно, что время, затраченное на тестирование в таком варианте, значительно меньше, чем на проведение нескольких последовательных тестов. Также аналитикам не придется после каждого теста обращаться к DWH и анализировать результаты, а разработчикам не придется каждый раз дорабатывать фронт, что сильно экономит время.

Одновременное тестирование нескольких гипотез
Представьте, что вы хотите изменить цвет верхнего главного меню в интерфейсе, а также попробовать поменять цвет внизу страницы у кнопок шерингов. Это две независимые гипотезы, так как справедливо предположить, что цвет главного меню никак не влияет на кликабельность шерингов, и наоборот.
В таком случае, вы можете просто разделить входящий трафик на четыре равных канала по 25% и тем самым одновременно провести два независимых A/B теста. В старой системе такого мы делать не могли — нам бы пришлось проводить два теста друг за другом.

Кроме того, в новой системе мы можем разделять трафик в любых соотношениях. Например, если главное меню и шеринги описываются разными метриками или вы ожидаете различное изменение метрики в разных тестах, но в то же время хотите завершить тест одновременно, то можете распределить трафик в разных пропорциях.
Множественная проверка гипотез.
Допустим, у нас в интерфейсе есть кнопка и мы хотим понять, какой формы и цвета ее лучше сделать. Таким образом, в старой системе для этого нужно было провести два теста: один на форму, второй на цвет.

Например, в первом тесте мы сравниваем голубую горизонтальную кнопку с голубой вертикальной, и если в нем выигрывает горизонтальная кнопка, то во втором тесте мы сравниваем уже две горизонтальные кнопки разных цветов. В этом случае мы не рассматриваем вариант с желтой вертикальной кнопкой, но теоретически это мог бы быть более конверсионный вариант, чем все остальные.

В новой системе мы можем провести один тест на все возможные варианты кнопки, то есть не упустим ни один из вариантов и сделаем более корректные выводы.
Хочется пояснить, что все примеры, описанные в статье, носят исключительно демонстративный характер. Мы не призываем красить кнопки в разные цвета, скорее наоборот — думать о более интересных и сильных гипотезах.
Проведение A/B на тестовой сборке
Очень полезной фичей является проведение A/B на тестовой сборке. Часто мы деплоим новый UI в виде теста, прежде чем залить его на прод. Также, довольно часто нам нужно протестировать какой-то элемент уже в новом UI.
В старой системе у нас нет полноценной возможности это сделать, так как если новый UI уже раскатан в системе A/B тестирования, то одновременно еще один тест в этом продукте мы проводить не можем. Таким образом, у нас есть два варианта: либо не проводить A/B тесты элементов и встраивать все изменения на свой страх и риск, либо ждать, пока новый UI будет протестирован и освободится место для экспериментов.

В новой же системе есть возможность распределить трафик в любой пропорции и протестировать любые фичи до того, как новый UI будет доступен для всего трафика.
Особенности и подводные камни
Тем не менее, с введением новой системы у нас появляются некоторые риски, которые могут негативно повлиять на результат эксперимента при его неправильном проведении.
Мы выделили четыре ключевых аспекта:
Неверное планирование времени эксперимента
Неверный выбор фичей для тестирования
Неверный выбор количества вариантов
Неверная поправка на множественную проверку
Рассмотрим подробнее каждый из этих рисков.
Неверное планирование времени эксперимента
Во-первых, прогноз длительности теста должен зависеть от особенностей пользовательского поведения в продукте. Проблема в том, что при многовариантном или одновременном тестировании увеличивается вероятность того, что, например, самые конверсионные клиенты попадут в бОльшем количестве в один из вариантов эксперимента и повлияют на его результат.
Давайте разберем данный аспект на примере. Представьте, что у вас есть кнопка в интерфейсе и вы знаете, что ее конверсия у пользователей мобильной версии сайта намного выше, чем у пользователей десктопной версии. Такое множество конверсионных пользователей, обладающих некоторым общим признаком (например, пользователи мобильной версии сайта), мы будем далее называть ключевой группой для этой метрики.
Важно, чтобы при разделении трафика на варианты теста у вас сохранилась примерно равная доля пользователей с мобильной версией сайта в каждом из вариантов. Если же в один из вариантов попадает значительно больше таких пользователей, то выбранная метрика в этой группе может показать бОльшую статистическую значимость не из-за дизайна этого варианта, а просто из-за неудачного разделения трафика.
Когда вы разбиваете пользователей на две группы, данная проблема незначительна, поскольку вероятность того, что сплит произойдет плохо, довольно мала. Но когда вы начинаете делить трафик на большее количество групп, скажем, на 5 или 10, то эта вероятность сильно возрастает и вы уже не можете игнорировать данную особенность.
Такой же эффект возникает при неправильном разделении пользователей по разным разделам продукта. Например, в журнале Сравни есть раздел с новостями и со статьями. Так как статьи длиннее новостей, то конверсия по некоторым кнопкам может значительно отличаться в этих двух разделах (например, в новостях конверсия выше). Соответственно, когда мы запускаем A/B по всему журналу, мы должны следить за тем, чтобы пользователи, читающие новости, попали в выборки примерно в равном количестве.

Справиться с этой проблемой можно с помощью грамотного планирования времени эксперимента. Необходимо продержать тест достаточное кол-во времени, чтобы пользователи ключевых групп равномерно распределились по вариантам теста.
Как можно понять, сколько времени нужно для проведения эксперимента? Решений несколько:
Самое простое — взять ретро данные и собственноручно симулировать сплитование трафика. Посмотреть как распределяется трафик в ключевых группах при некоторых параметрах сплита. Оценить длительность теста, при которой пользователи ключевой группы распределяются равномерно. Это простой и понятный способ, но он требует больших временных затрат.
Второй способ — это автоматизированный первый. Можно написать калькулятор, который бы проводил искусственный сплит и вычислял необходимое время эксперимента, чтобы минимизировать вероятность неверного разделения пользователей из ключевых групп.
Третий способ — это получить аналитическое, строгое решение данной задачи и перед запуском теста пользоваться готовой формулой.
Также с решением данной проблемы можно справиться с помощью пост-стратификации. То есть проводить тестирование как обычно, но при анализе результатов фиксировать равные доли ключевый групп в выборках для каждого из вариантов. У этого способа есть лишь один недостаток: может случиться так, что для фиксации равных долей ключевых групп вам придется выкидывать из выборки слишком большое кол-во пользователей и мощность вашей оставшейся выборки уже будет ниже выбранного вами порога (обычно это 80%).
Хочется отметить, что с этой проблемой, безусловно, успешно справляются с помощью стратификации, но мы намеренно не рассматриваем такой вариант, поскольку он намного сложнее в реализации и требует гораздо больше времени как от аналитиков, так и от разработчиков. Подробнее изучить такое решение можно в статье от коллег из Х5.
Что касается того, как делать не стоит — не стоит вычислять время эксперимента, пользуясь только классическим калькулятором Манну-Уитни. Этот калькулятор для двухвариантного A/B тестирования прогнозирует время проведения эксперимента исходя из выбранной вами статистической значимости, мощности и ожидаемой разницы в вариантах, но не берет в расчет никакие особенности вашей выборки пользователей. Также мощность, которая задается в калькуляторе — это мощность именно A/B тестирования, не стоит путать ее с совокупной мощностью при многовариантном тестировании.

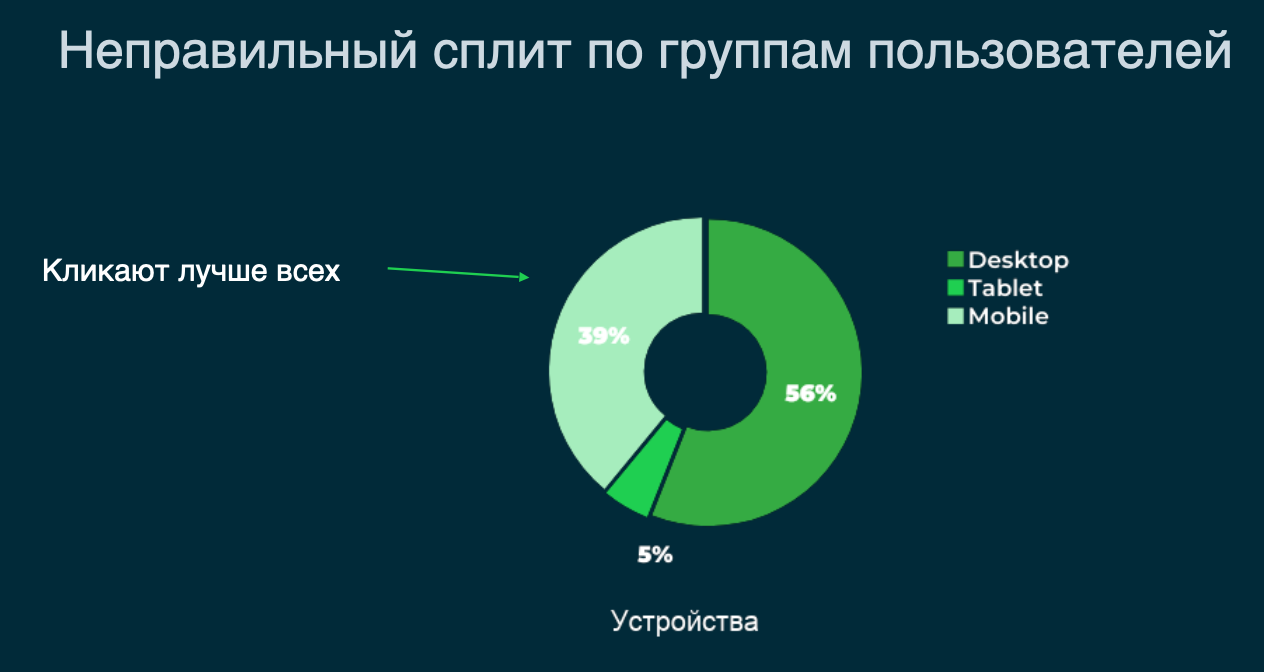
Наглядный пример: на графике представлена накопительная доля мобильного трафика в разрезе вариантов A/A/n теста от времени (пользователи мобильной версии сайта являются для данной метрики одной из ключевых групп) . Красной стрелкой отмечено время завершения теста, вычисленное с помощью калькулятора Манна-Уитни. Видно, что к этому времени доля мобильного трафика третьего (черного) варианта теста значительно больше, чем у всех остальных. Это, как мы говорили ранее, может повлиять на результаты эксперимента. Зеленой стрелкой отмечено корректное время завершения теста. Видно, что к этому времени пользователи мобильной версии примерно в равной доле распределились между вариантами теста.
Чтобы подчеркнуть важность проблемы, давайте рассмотрим график с накопительным P-value между вариантами 3 (черным) и 1 (красным) теста, который мы рассмотрели выше. Напомню, что мы проводили A/A/n тест, то есть дизайн интерфейса во всех вариантах был идентичен. Красная линия — это классический P-value в 5% (порог статистической значимости).

На графике видно, что с 17 по 27 ноября P-value был ниже 5%, и если бы мы остановили тест в любую из этих дат, то мы бы сделали неверные выводы. Но если бы мы изначально приняли в расчет особенность с неравномерным разбиением ключевой группы, то остановили бы тест значительно позже и получили бы ожидаемый, верный результат.
Неверный выбор фичей
Особенность в выборе фичей в A/B/n тесте заключается в том, что если тестировать фичи, которые очень слабо друг от друга отличаются, то на метрику будут сильно влиять неравномерное распределение ключевых групп пользователей, а также любой другой «шум» в данных. Увеличивается вероятность того, что вы сделаете неверные выводы, а именно, задетектируете статистически значимое изменение там, где его на самом деле нет (ошибка первого рода).

В идеале, фичи должны значительно отличаться друг от друга и воздействовать на пользовательское поведение, тогда сплит ключевых групп и шум уже не будет так сильно влиять на результат. Например, не стоит тестировать разные оттенки кнопки, изменять размер шрифта на 2-3 пиксела и т. д. С точки зрения бизнеса такие тесты также не имеют смысла, поскольку слабо изменяют метрику, но требуют большого количества ресурсов.
Неверный выбор количества вариантов
Вернемся к примеру с количеством офферов в блоке. Например, вы могли бы рассмотреть варианты с 3, 5, 7, 9, 11 и 13 офферами в блоке в рамках одного теста, разделив трафик на 6 веток. Но с увеличением числа веток растет вероятность того, что ключевые группы распределятся неравномерно по вариантам теста.
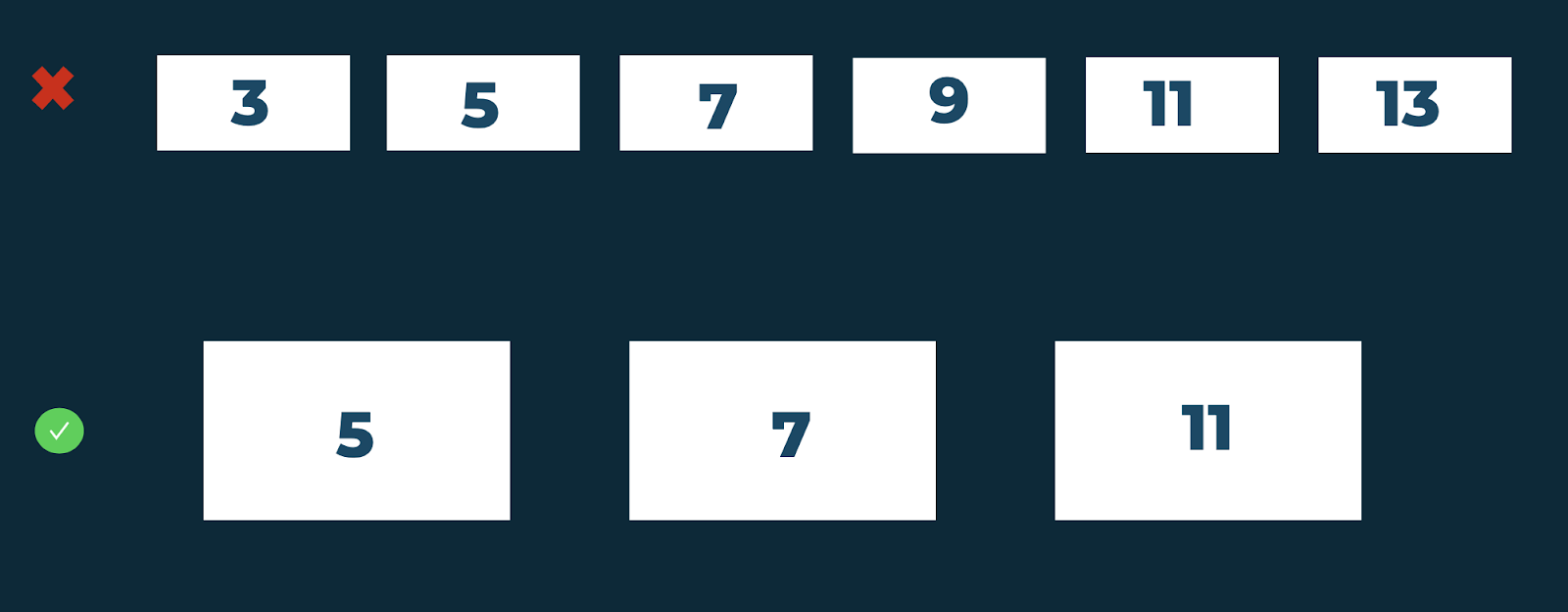
В таком случае, лучше убирать заведомо неподходящие варианты и сократить количество веток. Например, стоит убрать варианты, которые не подходят по бизнес-требованиям, плохо влияют на пользовательское поведение, негативно влияют на скорость загрузки страницы и т. д. Стоит оставлять только те варианты, которые наиболее жизнеспособны и которые вы точно встроите в продукт, если они выиграют.
Поправки на множественную проверку
При построении n выводов верхняя оценка вероятности того, что хотя бы один из них будет неверным, будет равна 1-(1-α)n, что составляет достаточно большое значение при небольших n. Например, при n = 5 и α = 5% эта вероятность равна ~23%.
Когда вы проводите A/B/n тест, при анализе результатов вы все равно сравниваете варианты попарно друг с другом. И при этом вы сравниваете каждый вариант с P-value, ограниченным в 5%. Но когда вы сравниваете много вариантов попарно, итоговая вероятность ошибки уже будет выше.
На гистограммах P-value это выглядит следующим образом:
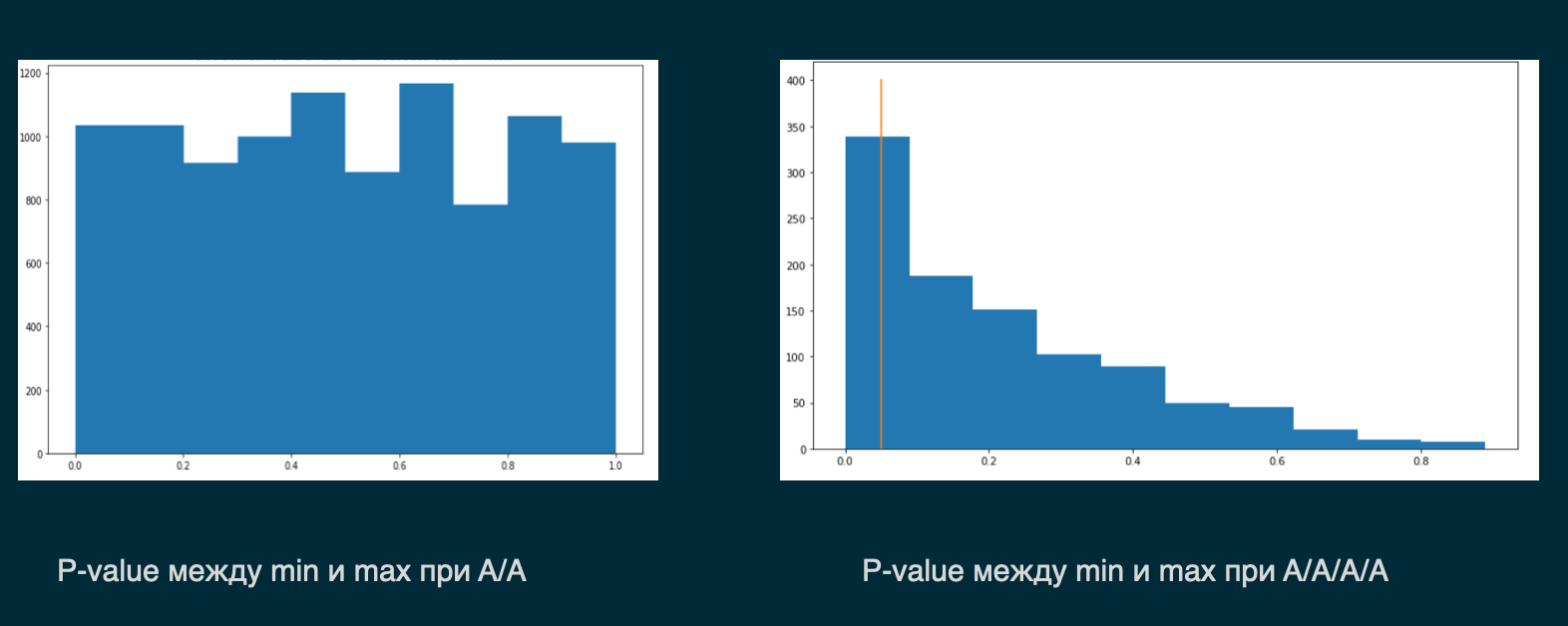
Слева мы видим P-value в рамках А/А-теста, а справа трафик делился на четыре ветки, проводится А/А/n тест. В левом варианте вероятность того, что выиграет первый вариант, равна вероятности второго (равномерное распределение), то есть эти варианты равнозначны друг другу (что логично, так как пользователи видят одно и то же). В правом варианте мы сплитуем пользователей на 4 ветки и видим, что распределение P-value уже не равномерное и мы с бОльшей вероятностью будет детектировать статистически значимую разницу там, где ее на самом деле нет.
Для борьбы с данной проблемой существует большое количество разных поправок на множественную проверку, например, поправка Бонферрони, метод Холма и другие. Как правило, они ограничивают P-value попарного сравнения вариантов. Например, при сравнении нескольких вариантов будет использоваться не стандартное α = 5%, а 2%, 3% или даже 1%.
При использовании этих поправок появляются две особенности. Во-первых, вы ограничиваете P-value, и вам сложнее задетектировать реальную разницу между вариантами, если она есть. Если в A/B-тесте вы использовали границу P-value в 5%, то здесь вы будете использовать поправку и сравнивать варианты попарно с более низкой границей, и та же самая разница может уже не быть статистически значимой.
Это может стать проблемой, особенно, если вы работаете с какими-то чувствительными метриками и предполагаете, что изменение дизайна повлияет на метрику очень слабо. Таким образом, если вы будете использовать поправки, то почти наверняка не обнаружите разницу — ни в бОльшую, ни в меньшую сторону — и никаких полезных выводов для себя не сделаете.
Вторая особенность в том, что использование этих поправок не решает проблему со сплитом ключевых групп. То есть нельзя просто использовать поправки и проигнорировать все описанные ранее особенности. Так или иначе, мы все равно должны смотреть на распределение ключевых групп, правильно выбирать фичи и т.д.
Рекомендации по поводу множественных проверок следующие:
1) Применять эти поправки стоит только в случае необходимости. Например, когда вам критически важно строго ограничить групповую вероятность ошибки. Допустим, если вы проводите тест в ключевом продукте и вам очень важно не уронить прибыль новыми изменениями в будущем. Во всех остальных случаях, особенно если у вас ограничено время или трафик, тех рекомендаций, которые были даны ранее, должно быть достаточно, чтобы проводить A/B/n корректно без использования поправок.
2) Не использовать поправки как альтернативу проверке на сплитование ключевых групп.
Подводя итоги
Во-первых, важно четко понимать ключевые группы пользователей, которые влияют на вашу метрику и выбирать время эксперимента с учетом их сплитования. Напомню, что для каждой метрики и для каждого виджета мы должны определять эти группы по отдельности и провести большую работу перед тем, как начать использовать A/B/n и множественное тестирование.
Во-вторых, важно выбирать фичи, значительно отличающиеся друг от друга. Чем больше они будут друг от друга отличаться, тем лучше. Далее, стоит минимизировать количество вариантов, убирая заведомо неудачные, неподходящие по каким-то требованиям или похожие друг на друга.
И, наконец, можно использовать поправку на множественную проверку в случае необходимости, когда вам намного важнее задеплоить точно выигравший вариант, чем случайно раскатать проигравший. В этом случае лучше использовать поправки. Так вы лишний раз убережете себя от ошибок.
Спасибо за внимание! Буду рад ответить на ваши вопросы и комменты.
Amedvedev07
Добрый день!
Почему по ВЗР вы убрали выбор из нескольких вариантов страхования?
Это как-то связано с проводимыми A/B/n экспериментами?
Раньше по каждой страховой компании было несколько вариантов страхования с разными опциями.
Сейчас по каждой страховой только один вариант.