
В январе 2022 мы подводили командные итоги 2021 и обнаружили, что у нас довольно много приемочных багов при тестировании новых фич. Мириться с этим было нельзя, и за дело принялся знающий человек — наш тимлид. Он собрал команду и поставил задачу: снизить количество приемочных багов до минимально возможного значения, желательно разика в три. Это был челлендж, который казался невыполнимым. Но сдюжили! Расскажу, как мы всего добились и почему это хорошо.
Что такое приемочные баги и как их посчитать
Вначале договоримся о понятиях, чтобы все сказанное было понято верно.
Приемочные баги — это дефекты, которые были выявлены в результате приемочного тестирования новой фичи.
Например, стояла задача прикрутить новую желтую кнопку в приложении. Разработчик на основании спецификации эту кнопку прикручивает, отдает задачу в тестирование. И если на этапе тестирования оказывается, что кнопка красная, а не желтая (т. е. реализация фичи не соответствует заявленным требованиям), то на такой дефект заводится приемочный баг. Еще мы называем их acceptance bug.
Отличие простого бага от приемочного в том, что простой баг не выявляется в ходе приемочного тестирования, а может обнаружиться, например, в проде.
Оформляется такой приемочный баг в виде сабтаски к основной таске, в рамках которой разработчик реализовывал новую фичу. Таких приемочных багов у каждой таски может быть много, в зависимости от количества выявленных дефектов.

Основная проблема большого количества приемочных багов — замедление доставки фичи конечному пользователю и удорожание этой самой доставки. Каждый выявленный приемочный баг — это дополнительный затраченный разработчиком временной ресурс на исправление дефекта.
Без багов фича будет доставлена пользователю за N времени, а с багами — за N времени + время на исправление дефектов. Если выявленных дефектов много, то доставка фичи может затянуться прямо в разы. А это все денежки.
В нашем случае количество приемочных багов за четвертый квартал 2021 года равно одному багу на таску. Казалось бы — не так уж и много, но при расчете мы учитывали все типы тасок, в том числе и tech, при тестировании которых приемочные баги почти не выявлялись.
С тасками же, реализующими задачи от бизнеса, были трудности. Рядовой случай — пять-шесть выявленных приемочных багов на одну таску. А некоторые задачки-рекордсмены цепляли на себя несколько десятков дефектов.
Мне до сих пор снится в кошмарах задача, которая породила больше шести десятков приемочных багов. Надо ли говорить, что ее доставка до пользователя тянулась чудовищно долго?
Посчитать количество приемочных багов на количество реализованных сторей совсем несложно, если использовать Jira в качестве таск-трекера. Достаточно применить немного JQL-магии, которой учат в Хогвартсе на первом курсе:
1. Находим количество реализованных тасок за определенный период через запрос: project = *название пространства команды* AND issuetype in (Bug, Story, Tech) AND status in (Released, Done) AND resolved >= 2022-01-01 AND resolved <= 2022-12-31

2. Находим количество приемочных багов за тот же период через запрос: project = *название пространства команды* AND issuetype = "Acceptance bug" AND status = Released AND resolved >= 2022-01-01 AND resolved <= 2021-12-31

3. Рассчитываем соотношение по формуле: Количество акцептансов / Количество сторей.
Откуда появляются приемочные баги
Точкой отсчета стало количество приемочных багов на таску. После этого мы стали искать основные причины возникновения дефектов.
Только поняв, из чего состоит враг, можно понять, как с ним бороться. Дж. Стетхем
Для выявления причин я взял реализованные задачи с самым большим количеством приемочных багов и пообщался с разработчиком каждой. Разговоры были без какого-либо шейминга, я сразу предупредил, что просто хочу понять причину и предложить пути ее уничтожения, чтобы наша жизнь стала чуть лучше и краше. В итоге получилось две глобальные причины.
Неточности, неясности и недосказанности в спецификациях. Продуктовые команды так или иначе сталкиваются с этой проблемой. Заказчик приносит спецификацию, в которой указано требование прикрутить желтую кнопку. Команда начинает работу и выясняет, что в спеке не полностью раскрыты некоторые вопросы, которые данная фича цепляет.
Например, не указано, куда желтая кнопка ведет, или нет дизайна кнопки. Не всегда соблюдены критерии качественного требования — подробнее про критерии можно почитать в чек-листе тестирования требований. Это не значит, что заказчик плохо делает свою работу и ему нужно делать ататашки. Просто иногда условный аналитик может попросту не знать, как работает именно ваше приложение, и чего-то не учесть. Ну или человеческий фактор выстреливает — и упускается что-то важное.
Самое неприятное в этом вопросе, что часто нюансы всплывают, когда задача уже в разработке или ушла в тестирование и породила приемочные баги. Начинаются уточнения, правка спеки и уже написанного кода. А это дорого. Гораздо дешевле было бы сразу учесть все аспекты задачи в требованиях до момента перехода задачи в разработку. И перед разработчиком была бы кристально чистая картина требований, учитывающая все возможные детали.
При реализации фичи разработчик не всегда учитывает все кейсы, которыми в дальнейшем данная фича будет тестироваться. Вторая популярная причина приемочных багов у нас заключалась в том, что тестировщик проверил какой-то кейс, который разработчик даже и не учитывал при написании кода. Например, у пользователя может быть двойная фамилия, а разработчик навесил валидатор, что можно вставлять в это поле только буквы, не предусмотрев дефис.
Это не значит, что разработчик плохой. Просто его обязанность — писать код, а не жонглировать техниками тест-анализа и тест-дизайна. Была нередкой проблема, когда тестировщик заводил приемочный баг, основываясь на не совсем очевидном кейсе, а разработчик при этом удивленно восклицал: «Ого, а так можно?! А я думал сова!»
Как мы снизили количество приемочных багов
Вот к чему мы пришли, когда пофиксили основные причины появления приемочных багов.
Изменили флоу поступления в работу задач, чтобы решить проблему с неточностями в спецификациях. Раньше мы просто брали в работу спеку, бегло прочитав при планировании и не слишком глубоко погружаясь в нее до момента разработки. А сейчас ввели этап так называемого ревью спецификации, которое, по сути, является тестированием документации. На этом этапе заказчик отдает команде на растерзание на ревью первоначальный вариант спецификации.
Разработчики и тестировщики внимательно читают спеку и оставляют свои комментарии. Удобно использовать Конфлюэнс для таких задач: выделяешь кусочек нужного текста — появляется иконка «Оставить комментарий». После ревью команды остаются заметки, сгенерированные коллективным разумом, и если их проработать, спецификация будет отшлифована. При этом списка обязательных ревьюеров у нас нет. К ревью задачи подключаются все члены команды, которые будут вовлечены в реализацию задачи, независимо от ее типа. Ведь именно им придется с этой спецификацией в дальнейшем работать и она должна быть максимально понятна для них. А так как команда на хорошем уровне знает свой продукт, эти комментарии позволяют подсветить практически все нераскрытые в спеке места.

Все замечания мы оставляем без эмоций и личностей, просто подсвечивая возможные тонкие и слабые места. Такое ревью проходит асинхронно. В шапке спецификации есть блок с чекбоксами, который называется «Ревью спецификации», и в каждом чекбоксе указан инженер, который должен спеку поревьюить.
После ревью инженер проставляет чекбокс напротив своего имени в этом блоке. После того как все чекбоксы проставлены, заказчик понимает, что можно дорабатывать спеку на основании комментариев.

Какие-то комментарии заказчик отрабатывает самостоятельно, а какие-то мы обсуждаем вместе на обязательной встрече, которая проходит перед окончательным апрувом спеки и началом работы.
На встрече мы всей командой еще раз проходим по спецификации и совместно разбираем комментарии, которые заказчику не удалось разобрать самостоятельно. Обсуждаем каждый такой комментарий и приходим к согласию общими усилиями.
Благодаря ревью ТЗ до реальной работы доходит практически идеально отшлифованная документация, что упрощает процесс разработки, тестирования и, как следствие, доставки фичи конечному пользователю. И, конечно, существенно снижает количество приемочных багов, что видно на графике нашей команды за 2022 год:

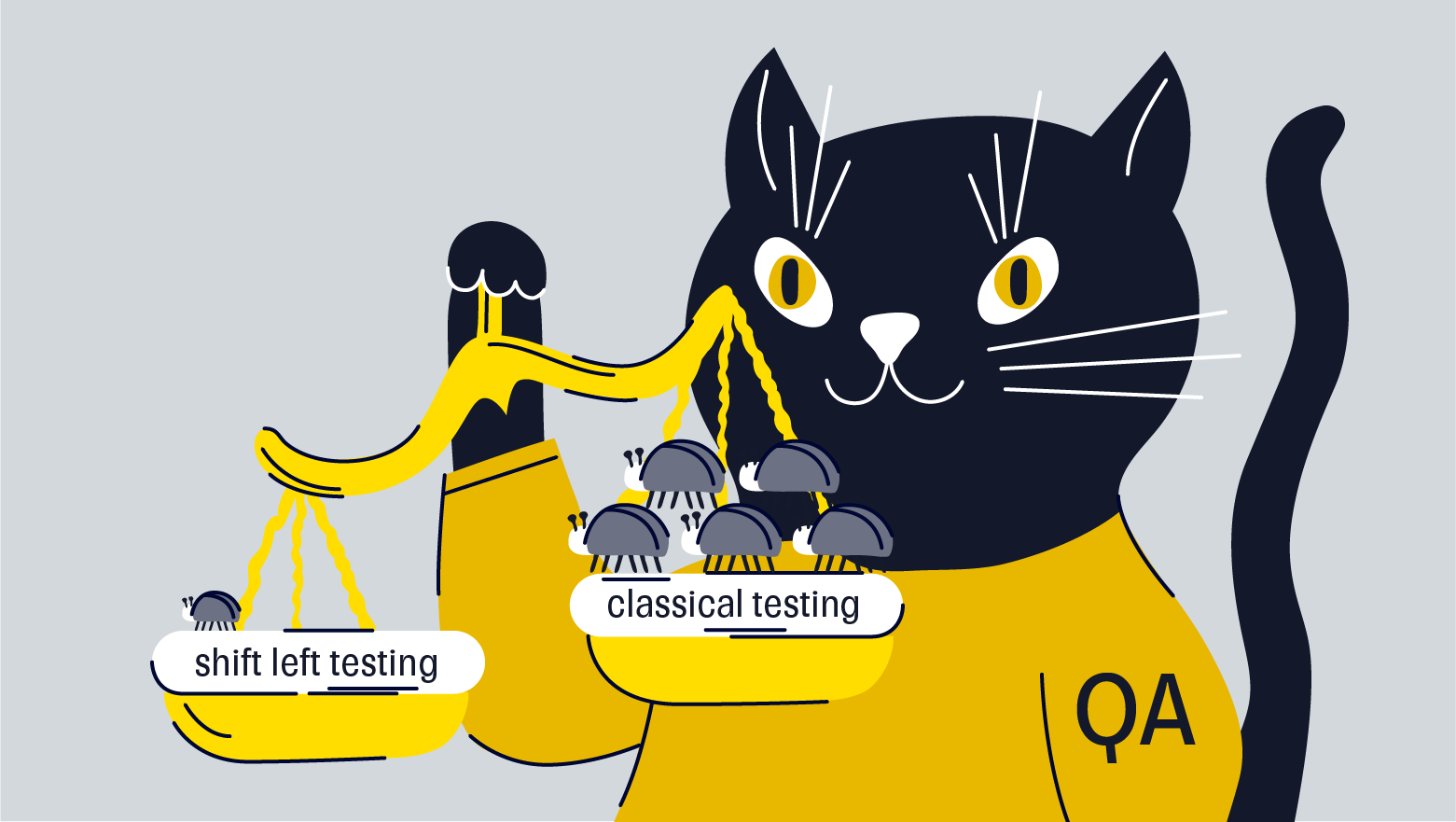
Для решения проблемы учета всех возможных кейсов мы сместили процесс тестирования как можно левее. Использовали тот самый shift left testing.
Когда разработчик берет задачу в работу, он дробит ее на много сабтасков, в которых и реализует фичу. Среди этих сабтасков он обязательно добавляет еще один: «Написание тест-кейсов». Такой сабтаск нужен для тестировщиков, чтобы QA-спецы написали кейсы, которыми будут эту фичу проверять. Причем это происходит параллельно с разработкой, чтобы выполнить задачу до того, как закончит свою работу разработчик.
Разработчик ревьюит написанные кейсы и знакомится с тем, как фича будет протестирована. Это помогает ему предусмотреть в коде все описанные случаи. Кстати, ревью кейсов еще полезно тем, что разработчик может со своей стороны подсказать, как еще можно потестить фичу и чего не хватает в кейсах.
Так до приемочного тестирования доходит код, в котором уже учтены все тест-кейсы, и это прямо влияет на кратное снижение количества приемочных багов.
Самое сложное в описанных процессах — выделить время, которое теперь приходится уделять ревью спецификаций. Всегда есть неотложные рабочие контексты, и найти время на ревью спек бывает непросто. Но проблема больше иллюзорная, главное — осознать, что ревью спеки — это уже процесс разработки фичи.

Важно донести до команды, что все неточности спецификации всплывут при разработке и тестировании, если ее не поревьюить на раннем этапе. Ведь проще решить проблемы спецификации до разработки, чем делать то же самое после.
Что у нас получилось
Через год — в январе 2023 — мы подвели итоги по снижению количества приемочных багов. 2022 вышел непростым, но победить приемочные баги у нас получилось — мы сократили их количество в пять (!!!) раз.
В январе 2022 у нас был один баг на сторю, а в январе 2023 — 0,2 бага на сторю. Повторю ранее приведенный график:

Первую половину года нас штормило — количество приемочных багов зашкаливающе высокое. На это были причины: активно внедрять описанные практики начали только с апреля. До этого анализировали ситуацию и формулировали инструменты исправления. Они принесли плоды пару месяцев спустя, когда окончательно укоренились и прижились. С середины года количество приемочных багов упало до стабильно низкого уровня.
В итоге скорость доставки задач увеличилась, а приятным бонусом стало снижение уровня нервотрепки при реализации задач, потому что спецификации стали проработанными, четкими и однозначными.
Кстати, в подкасте «Кем ты стал» обсуждали, почему нельзя написать программу без ошибок. А если у вас есть вопросы или свои классные техники — добро пожаловать в комментарии!
Комментарии (8)

johnfound
00.00.0000 00:00Хм, а я почему-то думал, что «таск» это мужской род. А выходит, что женский – «таска».

DubrovinQA Автор
00.00.0000 00:00ага, все так. но тут уж поэзия it'шного жаргона) до сих пор, кстати, не могу привыкнуть, что "баг" иногда называют "бага"
johnfound
00.00.0000 00:00+1Понятно. И уменьшительно-ласкательные формы лучше выглядят, когда из женского рода образуются. «тасечка» звучит лучше чем «таскунчик». :D

ruustamer
00.00.0000 00:00+1Как мы сократили количество приемочных багов? Стали меньше их заводить!
На самом деле классная статья, спасибо. Пойду закину в команду, как раз задумываемся над увеличением ttm.


azShoo
00.00.0000 00:002023 год, ребята из Тинькофф узнали, что оказывается тестирование требований - норм тема.
Кайф.
DubrovinQA Автор
00.00.0000 00:00Тут больше о том, как мы это структурировали и поставили на нормальный рабочий поток)
mironoffsky
История стара как мир. Как говорится, без внятного ТЗ - результат ХЗ.