
Здравствуйте, меня зовут Дмитрий Карловский и я.. автор множества микроскопических и самых шустрых в своём классе библиотек. Одна из них — $mol_compare_deep, умеющая сравнивать произвольные структуры, даже содержащие циклические ссылки. И сейчас я вам расскажу, как ей это удаётся.
Cперва, небольшая предыстория, почему эта библиотека вообще нам понадобилась для реализации реактивной системы.
Эквивалентные изменения
Порой значение меняется на эквивалентное. И тут есть разные подходы к отсечению вырожденных вычислений.
????Every: Реакция на каждое действие
????Identity: Сравнение по ссылке
????Equality: Структурное сравнение
????Reconcile: Структурная сверка
Dupes: ????Every
В библиотеках типа RxJS каждое значение является уникальным событием, что приводит к ненужному запуску реакций.
777 != 777
Чтобы этого не происходило, нужно писать дополнительный код, который часто забывают, и потом огребают.
Dupes: ????Identity
Многие библиотеки всё же умеют сравнивать значения. И если состояние не поменялось, то реакции не срабатывают. А если поменялось, даже на эквивалентное значение, то срабатывают.
777 == 777
[ 1, 2, 3 ] != [ 1, 2, 3 ]
Если мы нафильтровали новый массив, с тем же содержимым, то скорее всего нам не нужно запускать каскад вычислений. Но вручную уследить за всеми такими местами - мало реалистично.
Dupes: ????Equality
Наиболее продвинутые библиотеки, типа $mol_wire, делают глубокое сравнение нового и старого значения. В некоторых других, типа CellX, его можно включить в настройках.
777 == 777
[ 1, 2, 3 ] == [ 1, 2, 3 ]
[ 1, 2, 3 ] != [ 3, 2, 1 ]
Это позволяет отсекать лишние вычисления как можно раньше — в момент внесения изменений. А не в момент рендеринга заново сгенерированного VDOM в реальный DOM, как это часто происходит в React, чтобы узнать, что в доме‑то менять и нечего.
Глубокое сравнение — это, безусловно, сама по себе более дорогая операция, чем просто сравнение двух ссылок. Однако, рано или поздно, сравнить всё содержимое всё равно придётся. Но гораздо быстрее это сделать пока данные рядом, а не когда они разлетятся по тысяче компонент в процессе рендеринга.
Тем не менее, если данные поменялись, то полетят дальше по приложению и будут глубоко сравниваться снова и снова, что никуда не годится. Поэтому тут важно реализовывать кеширование результата глубокого сравнения для каждой пары сравниваемых объектов.
Dupes: ????Reconcile
Наконец, можно пойти ещё дальше, и не просто глубоко сравнивать значения, но и делать их сверку, чтобы сохранить ссылки на старые объекты, когда они эквивалентны новым.
const A = { foo: 1, bar: [] }
const B = { foo: 2, bar: [] }
reconcile( A, B )
assert( B.foo === 2 )
assert( B.bar === A.bar )
Как видите, A и B у нас тут отличаются, но свойство bar осталось таким как было. Это хорошо с точки зрения GC, ведь мы переиспользуем объекты, находящиеся в старом поколении сборщика мусора. А объект из молодого поколения при сверке был выборошен, что очень быстро.
Кроме того, когда в дальнейшем в компоненте, что рендерит bar, будет снова произведена его сверка, то произойдёт это крайне быстро, ведь старое и новое значения будут идентичны. С другой стороны, если объекты всё же будут отличаться, то повторная сверка снова пойдёт по всем внутренностям объекта. Тут опять же необходимо кеширование. Но..
Изменение полей нового объекта на значения из старого — это не всегда безопасная операция. Например, с DOM‑элементами такие финты проворачивать нельзя. В лучшем случае это не заработает, а в худшем вообще его сломает. В ряде случаев вы будете получать исключение при попытке изменить объект. Порой изменения будут попросту игнорироваться, а порой запускать сеттеры, делающие какие‑нибудь стрёмные дела.
К тому же, если объекты фактически идентичны, нам надо сначала их глубоко сравнить. И если они одинаковы, то вернуть старый, а если нет — начать менять новый. Ну либо сразу начать менять новый, чтобы потом выяснить, что мы поменяли все его свойства, так что вернуть надо старый.
Короче, данный подход не самый шустрый и надёжный, поэтому в $mol мы от него отказались в пользу глубокого сравнения с кешированием.
Когда реактивное состояние принимает новое значение, мы должны уведомить подписчиков об изменении. Но если изменение даёт эквивалентный результат, то можно ничего и не делать. Нам надо лишь понять: является ли изменение эквивалентным, или нет.
Например, если мы получили новый массив, но он поэлементно равен предыдущему, то даже если мы пересчитаем всё, зависящее от него, приложение, то для пользователя ничего не поменяется.
Получается нам надо уметь глубоко сравнивать новые данные и старые. Причём делать это быстро. Но тут на нашем пути может возникнуть ряд трудностей..
Некоторые объекты (например, Value Object) можно сравнивать структурно, другие же (например, DOM элементы или бизнес-сущности) - нельзя. Как их отличать?
Ну, стандартные типы (массивы, структуры, регулярки и тп) можно просто детектировать и сравнивать структурно.
С пользовательскими же чуть сложнее. По умолчанию не будем рисковать, а будем сравнивать их по ссылке. Но если в объекте объявлен метод Symbol.toPrimitive, то считаем, что это сериализуемый объект, а значит такие объекты можно сравнивать через сравнение их сериализованных представлений.
class Moment {
iso8601: string
timestamp: number
native: Date
[ Symbol.toPrimitive ]( mode: 'number' | 'string' | 'default' ) {
switch( mode ) {
case 'number': return this.timestamp
case 'string': return this.iso8601
case 'default': return this.iso8601
}
}
}
Если мы сравнили глубокие структуры и выяснили, что они в целом отличаются, то, когда будем их поддеревья передавать дальше, было бы опрометчиво сравнивать их снова и снова, ведь мы это уже сделали ранее. Поэтому результат глубокого сравнения пар объектов мы будем кешировать в двойных WeakMap, что обеспечит нам автоматическую очистку кеша по мере сборки объектов сборщиком мусора.
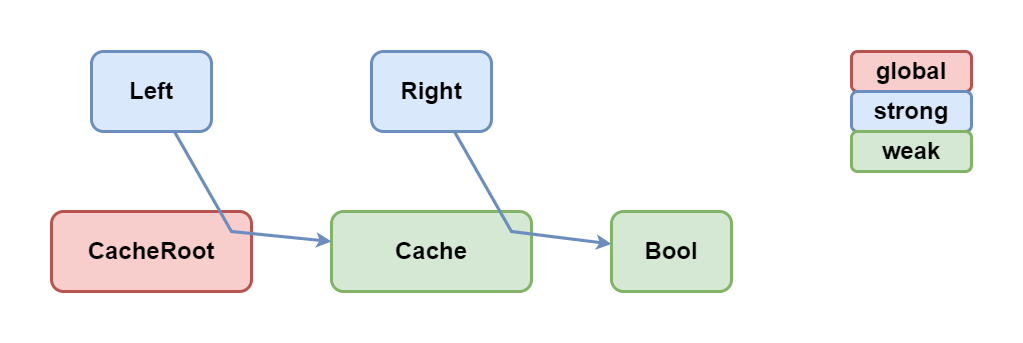
После сравнения, один из объектов Left и Right обычно выкидывается. В первом случае это освободит и кеш целиком, и все его данные, а значит при изменении значения, у нас ничего лишнего в памяти не останется. Во втором же случае освободятся только данные, а сам кеш останется для будущих сравнений, что предотвращает лишнюю аллокацию кешей при частом прилёте эквивалентных значений.
Наконец, в данных могут встретится циклические ссылки. Как минимум тут нельзя уходить в бесконечный цикл. А желательно правильно их сравнивать.
Например, следующие два объекта структурно эквивалентны:
const left = { id: 'leaf', kids: [] }
left.kids.push({ id: 'son', parent: left })
const right = { id: 'leaf', kids: [] }
right.kids.push({ id: 'son', parent: right })
Оказывается, поддержать циклические ссылки совсем не сложно, когда у нас уже есть кеш. Сперва пишем в него, что объекты эквивалентны, и погружаемся в глубь. Если снова наткнёмся на эту пару объектов, то возьмём значение из кеша и пойдём дальше. Если же где-то найдём отличия, то и в кеше потом поправим, что объекты всё-таки не эквивалентны.
В результате, у нас получилась библиотека $mol_compare_deep, размером в 1 килобайт, которая быстрее любых других, представленных в NPM:

Поиграться с ней можно в нашей JS-песочнице или сразу в своём проекте. Баги и респекты присылайте в тему про $mol на форуме Гипер Дев.

Комментарии (19)

artalar
00.00.0000 00:00+2
Зачем к свойству
rightобращаться через компьютед проперти аксес?
krulod
00.00.0000 00:00+2Тайпскрипт не понял, что тип right зависит от left, поэтому используется полуявный хак - опция
suppressImplicitAnyIndexErrors. Впрочем, она будет удалена в тс 5.5, поэтому такие вещи надо заменить на явныйas any
nin-jin Автор
00.00.0000 00:00Да, вместо простого
right['message']придётся писать( right as any ).message.


funca
У вас сравнение двух одинаковых множеств Set([1, 2]) и Set([2, 1]) даёт false. Интересно, какой была аргументация в пользу такого решения?
nin-jin Автор
Они не одинаковые - у них разный порядок итерирования.
funca
В математическом смысле порядок элементов для Set не важен. isEqual из lodash дает правильный результат true.
nin-jin Автор
Очень даже важен: https://ru.wikipedia.org/wiki/Линейно_упорядоченное_множество
Суть множества не в отсутствии порядка, а в отсутствии дубликатов.
aleksandy
(c) https://ru.wikipedia.org/wiki/Множество
А может и не быть, @funcaправ.
nin-jin Автор
https://developer.mozilla.org/ru/docs/Web/JavaScript/Reference/Global_Objects/Set
В JS Ordered Set. Короткое название вводит в заблуждение неокрепшие умы.
maximw
А где там сказано, что оно упорядоченное? Там только замечание о том, в какой последовательности можно итерировать элементы множества.
nin-jin Автор
Это замечание о том, как работает их итератор. Можете заглянуть в спецификацию языка, если не в курсе, что все объекты в JS упорядоченные.
funca
В JS у множества (Set) есть метод values(), который возвращает Последовательность (Sequency) элементов в том же порядке, в котором их туда добавляли. Фактически это преобразование объекта одного типа в объект другого. Будет-ли сравнение последовательностей эквивалентно сравнению множеств нужно было доказать прежде, чем писать код и тесты его производительности.
nin-jin Автор
Да что уж там, сперва надо доказать, что метод values() вообще существует, а то мало ли наврали в спецификации.
funca
Пожалуйста продолжайте, вас ни кто не ограничивает.
funca
Лучше тут https://ru.m.wikipedia.org/wiki/Множество в разделе "Отношения между множествами". Упрощённо, два множества равны если каждый элемент одного множества так же принадлежит и другому, и наоборот.
Линейно-упорядоченным (PoSet) множество становится если для него дополнительно задать операцию, определяющую частичный порядок (partial order) его элементов (меньше-или-равно). Проще говоря - функцию сравнения двух элементов. Определение равенства самих множеств это не меняет.
nin-jin Автор
А упорядоченное множество, которое в JS, - это кортеж из неупорядоченного множества и отношения порядка. И два упорядоченных множества равны, если равны в том числе и их отношения порядка.
DarthVictor
Я бы с вами согласился, но я сам реализовывал RLE на Node через простой Map, пользуясь порядком итерирования, так что подход @nin-jin может быть и надежнее. Возможно даже стоит регулировать поведение отдельным флагом.
krulod
https://t.me/artalog/740