
Привет, Хабр! Меня зовут Марина Петрова, я QA Lead в Cloud. В нашей QA-команде уже более 35 человек, а количество тестируемых продуктов превышает десяток. Мы пишем автоматические тесты для повышения качества продуктов и сокращения времени ручного тестирования. Для эффективной организации этого процесса требуются числовые индикаторы — метрики. Нам хотелось иметь инструмент, в котором аккумулируются данные о метриках в простом и понятном всем виде. Тогда мы предложили инициативу по созданию приложения для автоматического сбора и визуализации метрик покрытия автоматическими тестами.
В статье расскажу, какой путь мы прошли, чтобы измерить покрытие функциональности проектов автотестами.

Какие цели и задачи перед собой поставили
На начальном этапе у нас возникло множество вопросов. Какие метрики выбрать? С какой периодичностью их собирать? Как измерить величину покрытия тестами разного уровня разрабатываемых продуктов? Какими метриками мы можем пользоваться, чтобы оценить уровень доверия к качеству продукта? Где и как собирать метрики? В каком виде предоставлять эту информацию на регулярной основе членам команд и руководству?
При этом мы точно знали, что хотим:
сократить время работы QA-инженеров при планировании задач. Ранее каждый сотрудник тратил от одного до трех часов на оценку текущего покрытия системы, выявление «высокорисковых» сценариев, недостаточно покрытых автоматическими тестами, и саму постановку задач на автоматизацию тестирования;
унифицировать подход к планированию автоматизации и измерению покрытия во всех QA-командах компании, чтобы видеть общую картину и знать, сколько в продукте автотестов и что находится на проверке.
Отталкиваясь от этих соображений, в первом квартале 2022 года мы поставили перед собой следующие цели:
сформулировать и задокументировать методику подсчета покрытия для автоматических тестов всех уровней;
организовать сбор и хранение метрик покрытия продукта автоматическими тестами;
выявить зоны рисков — недостаточное покрытие автоматическими тестами сценариев приложения в целом и отдельных сервисов;
сократить время, затрачиваемое на планирование автоматизации тестирования;
визуализировать метрики и их динамику в простом и понятном всем виде для всех продуктов, имеющих автотесты.
Для достижения целей нужно было решить следующие задачи:
договориться о классификации автоматических тестов со всеми командами;
выбрать метрики покрытия для каждого типа тестов и обобщенные для проекта;
проанализировать достаточность имеющихся инструментов в компании для сбора и визуализации метрик, провести дополнительный анализ решений в OpenSource при необходимости;
описать методологию интеграции с выбранным инструментом;
использовать автоматически получаемые метрики в ежедневной работе и при планировании.
Какие инструменты используем для автоматизации и тестирования
Стек автоматизации в нашей QA-команде — это Pytest + Selenium/Playwright. Для тест-кейсов и отчетов по автотестам используем Allure TestOps, pipelines запускаем в GitLab.
Нам не хватало имеющихся инструментов для сбора и измерения покрытия. Конечно, для анализа результатов прогонов автотестов мы пользуемся дашбордами в Allure TestOps, но проблема в том, что в этом инструменте нет возможности создать кросс-командный дашборд и добавлять собственные метрики.
Какие метрики покрытия выбрали
Мы выбрали классификацию тестов на основе «классической» пирамиды тестирования: UNIT, API и E2E.
Следующий этап — выбор подходящих метрик покрытия для каждого сервиса в отдельности и каждого проекта в целом.
UNIT
Для unit-тестов стандартной метрикой покрытия является покрытие кода. Эту метрику мы и решили выгружать в наше приложение. В качестве обобщенной метрики договорились использовать медиану покрытия кода.
API
Для измерения покрытия API мы используем пакет swagger-coverage. Обязательным условием для успеха при его использовании является наличие спецификации в сервисах OpenAPI.
После ночного запуска всех API-тестов мы сохраняем отчеты по покрытию в артефакты pipelines GitLab CI. Ниже пример отчета одного из наших сервисов:

На основе данных отчетов мы решили собирать метрики по покрытию:
полное покрытие;
частичное покрытие;
непокрытые методы;
аналогичные суммарные метрики по всем API интерфейcам продукта.
Для метрик 1-3 оставалось решить вопрос с хранением данных, для 4 — научиться рассчитывать.
E2E
Для покрытия пользовательских сценариев выбрали функциональную модель. То есть QA-инженеры в каждом проекте составляют список критичных сценариев использования, создают такие тест-кейсы в Allure TestOps с тегом critical. Список критичных сценариев договорились обновлять при необходимости, но не реже чем один раз в квартал.
Если для критичного сценария уже был написан автоматический тест, то в коде достаточно было добавить для него соответствующий тег. Для нашего стека автоматизации это декоратор @pytest.mark.critical.
Далее в каждом проекте в Allure TestOps создали E2E critical Dashboards для визуализации покрытия с Pie Chart-виджетом со следующими параметрами:
Type = Test Case Pie Chart
Group by = By automation
Test cases query = tag is "critical"
Так мы достаточно просто и в автоматическом режиме получили метрику покрытия критичных E2E-сценариев автоматическими тестами. За счет разметки автотестов по функциональным блокам бонусом получили карту E2E-покрытия.

Измерять покрытие E2E будем по формуле = e2e automation test \ (e2e automation test + e2e manual test). Но проблема с кросс-продуктовым дашбордом на данном этапе осталась нерешенной.
Как разрабатывали инструмент
Мы обсудили с нашим руководителем отдела выбранные метрики и способы их измерения, показали MVP проекта, обсудили детали технической реализации. MVP был реализован на стеке Python, Django, Postgresql, Bootstrap.

В результате обсуждения получили «добро» на разработку и внедрение метрик покрытия на всю компанию. Создали страницу с планом работ по развитию дашборда на внутреннем портале компании, выбрали периодичность встреч для обсуждения результатов и принялись за работу.
Так получилось, что основные задачи по развитию приложения мы делали вдвоем с коллегой Максимом Алексеевым, старшим инженером тестирования. Нам обоим понравилось то, как удалось организовать процесс разработки. Оказалось, что в условиях ограниченности ресурсов, получается работать эффективнее и продуктивнее. У нас не было достаточно времени для работы над нашей идеей в рабочие часы, мы занимались этим в свое свободное время. На протяжении трех месяцев один раз в две недели мы встречались, чтобы зафиксировать результаты и запланировать следующие шаги. Затем реализовывали запланированное без обсуждения деталей исполнения: делали так, как считали правильным.
Параллельно с разработкой описывали, как работает дашборд, какие шаги нужно выполнить для интеграции с ним, делились результатами с коллегами, получали обратную связь и вносили корректировки.

Как собирали данные для расчета метрик
Для сбора метрик покрытия мы реализовали в приложении несколько API-методов. Подробнее о них будет ниже.

E2E
Информацию о количестве ручных и автоматизированных сценариев использования, как упоминалось ранее, мы получаем из Allure TestOps через allure-testops-api.
Таким образом, для сбора статистики E2E-покрытия по проекту QA-инженеру необходимо:
создать дашборд для критичных сценариев в Allure TestOps;
добавить widget в дашборд Allure TestOps для получения корректной информации о покрытии;
-
сохранить widget_id в дашборде. Для этого нужно отправить post-запрос на создание записи о widget-проекта;
Endpoint{COVERAGE_DASHBOARD_URL}/api/widget
Body:{ "project": "<Project name>", "widget_allure_id": <widget id> } -
сохранить ссылки на список критичных функциональный возможностей и на widget из Allure для ознакомления всем заинтересованным лицам;
EndpointPOST {COVERAGE_DASHBOARD_URL}/test_casesBody:{ "project": "<project name>", "wiki_ref": "wiki ref ex. wiki/pages/…", "allure_test_ops_ref": "allure project ref ex. {ALLURE_URL}/project/{pr_id}/dashboards/{widget_id}" } проверить корректность выполненных действий — на странице
{COVERAGE_DASHBOARD_URL}/e2eинформация по покрытию должна совпадать с данными из widget.
Для случая, когда виджет в Allure TestOps еще не создан, решили отображать общее число ручных и автоматических сценариев с пометкой, что данные о покрытии E2E сценариев отсутствуют.

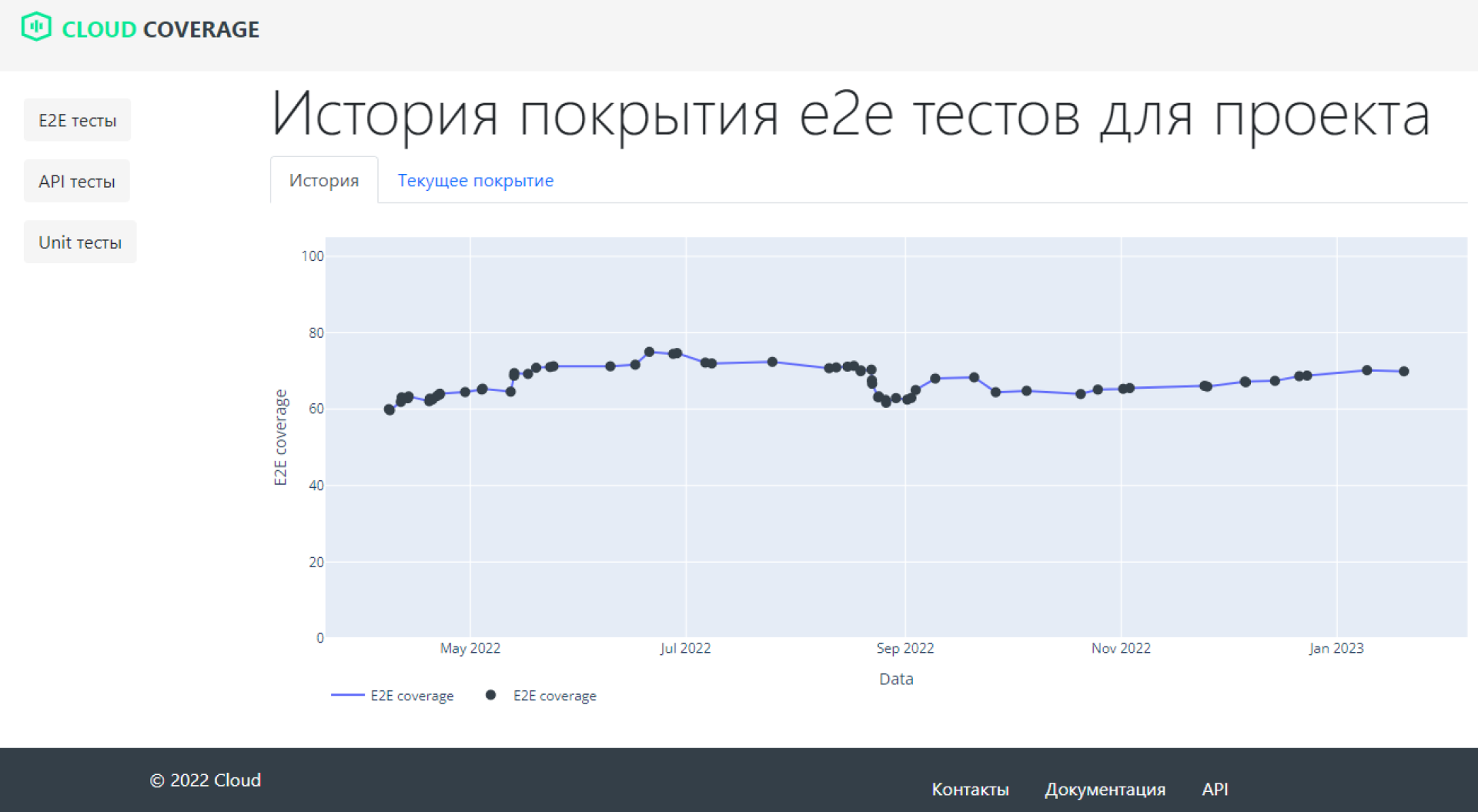
Также мы добавили визуальное отображение динамики покрытия.
API
Как упоминала выше, измерение покрытия Rest API выполняем с использованием swagger-coverage с дополнительным подсчетом суммарных метрик покрытия всех Rest API-сервисов проекта и по каждому сервису отдельно. Вначале мы реализовали хранение только суммарных метрик по Rest API, но быстро поняли, что бóльшую ценность имеет покрытие по каждому сервису отдельно.
Инженеру тестирования нужно было настроить в своем проекте по автотестам отправку данных о покрытии со следующим синтаксисом
Endpoint POST {COVERAGE_DASHBOARD_URL}/api/coverage
Body:
{
"project": "Project name 1",
"all_cnt": 932,
"actual_cnt": 912,
"full_cnt": 138,
"partial_cnt": 406,
"empty_cnt": 368,
"deprecated_cnt": 20,
"partial_coverage": 41.517,
"full_coverage": 17.132,
"empty_coverage": 41.351,
"services": [
{
"AICloud Service 1": {
"all": 31,
"full": 0,
"partial": 0,
"empty": 31
}
},
{
"AICloud Service 2": {
"all": 14,
"full": 2,
"partial": 2,
"empty": 10
}
},
….
}
]
}Для того чтобы каждая команда не пошла своим путем, мы написали:
класс-обертку для использования swagger-coverage с pytest-фреймворком;
генератор общего отчета о покрытии API-проекта, на основе отчетов о покрытии каждого сервиса в отдельности;
скрипт для отправки данных в наше приложение;
-
пример CI для выгрузки данных из pipeline в coverage dashboard:
coverage_dashboard: stage: coverage_dashboard image: name: $TESTS_IMAGE:$IMAGE_TAG entrypoint: [""] only: variables: - $SWAGGER_COVERAGE == "all" script: - python3 coverage_dashboard_uploader.py
После проделанной работы мы начали получать первые результаты по метрикам покрытия API.

UNIT
Для unit-тестов также был реализован отдельный интерфейс — метод для отправки покрытия {COVERAGE_DASHBOARD_URL}/unit/coverage
{
"project": "<Project name>",
"code_coverage": 50,
"service": "Service 2"
}
Как внедряли самописный инструмент, с какими трудностями столкнулись
Когда основная функциональность нашего инструмента была готова, мы рассказали о нем на внутреннем демо компании и начали активно помогать командам собирать метрики. В ходе этого процесса обнаружили несколько промахов.
Мы не учли особенности окружений запуска GitLab runners проектов. У некоторых из них возникла проблема сетевой связности с виртуальной машиной, где было развернуто приложение. Потребовалась помощь сетевых инженеров.
Необходимость измерения метрик покрытия была актуальна не для всех проектов из-за разницы в степени их зрелости, процессов тестирования и разработки. Но мы приходили во все команды с вопросом, почему их метрик нет в дашборде? Возможно, этим мы вгоняли QA-инженеров команд в стресс. Они объективно не могли обеспечить сбор таких метрик.
Не был учтен фактор времени и нагрузки на QA-инженеров. Внутри команд QA-инженеров все были проинформированы о необходимости выгружать метрики, но в их продуктовой команде были свои сроки и планы. Как итог за второй квартал 2022 года из 13-ти команд метрики E2E и API выгружали четыре команды, для unit-тестов — только три.
Мы не предложили вариантов измерения покрытия для сервисов с GRPC.
Не учли риски изменения API Allure TestOps — однажды после обновления Allure TestOps наш дашборд сломался.
Каких результатов достигли
Благодаря созданию приложения для автоматического сбора и визуализации метрик покрытия автоматическими тестами QA-инженеры в Cloud:
Сократили время планирования автоматизации тестирования примерно на 50%. Теперь мы планируем автоматизацию за 30 минут.
Знают процент покрытия каждого сервиса и его динамику. Известно также, падает покрытие или растет, и в какой период началось изменение покрытия.
Используют инструмент для кросс-командного взаимодействия. В QA-команде заметно улучшилась коммуникация и вовлеченность в процессы по улучшению качества. Теперь мы знаем, к кому нужно обратиться за помощью по автоматизации (конечно же к команде, у которой растет покрытие!).
Сняли с себя часть нагрузки по отчетности о результатах автоматизации и степени покрытия — все заинтересованные лица в любой момент времени могут открыть дашборд.
Снизили риски избыточного и недостаточного ручного тестирования.
Для руководителей появились свои очевидные плюсы:
Повысилась прозрачность и понятность состояния автоматизации тестирования на проекте.
Процесс автоматизации тестирования стал управляемым — при планировании спринта, квартальных и годовых целей команды QA-инженеров оперируют конкретными цифрами, которые каждый член команды может проверить лично без участия QA.
Планы
У нас была задача, мы предложили решение и реализовали его. Получили опыт взаимодействия с членами разных команд тестирования и, конечно же, сделали работающий инструмент — наш дашборд.
Сейчас мы выбираем дополнительные метрики по процессам тестирования и автоматизации в частности. Подключили Grafana для расширения возможностей подсчета метрик.
Нам интересно, какой путь проходят другие компании, какими инструментами и метриками пользуются. Делитесь вашим опытом в комментариях.