

Многие разработчики любят Python за простоту и удобство, но вот быстротой обработки данных этот язык программирования никогда не отличался. Во многом эти ограничения скорости связаны с его эталонной реализацией cPython, которая является однопоточной.
И хотя в Python есть встроенный модуль потоковой обработки, его использование даст нам только параллелизм. Это не поможет ускорить несколько задач, каждая из которых требует полной загрузки ЦП.
Есть у «змеиного языка» и собственный модуль многопроцессорности, который запускает несколько копий интерпретатора Python на отдельных ядрах и предоставляет примитивы для разделения задач между ядрами. Но для по-настоящему сложных задач, например, обработки больших наборов данных в машинном обучении, даже многопроцессорности недостаточно.
Когда требуется распределить задания не только между несколькими ядрами, но и между несколькими машинами, в игру вступают специальные библиотеки и фреймворки Python, реализующие параллельную обработку данных. Они позволяют взять существующее приложение Python и распределить нагрузку между несколькими ядрами, несколькими машинами или комбинировать оба варианта.
Ray
Фреймворк Ray, разработанный группой исследователей из Калифорнийского университета в Беркли, лежит в основе ряда популярных распределенных библиотек машинного обучения. Но его применение не ограничивается только задачами машинного обучения. С помощью Ray можно разбить и распределить по системам фактически любые задачи для Python.
Синтаксис Ray минимален, поэтому распараллелить существующие приложения можно без лишних усилий. Декоратор @ray.remote распределяет эту функцию по любым доступным узлам в кластере Ray с необязательными параметрами, указывающими, сколько процессоров, в том числе графических, нужно использовать.
Результаты каждой распределенной функции возвращаются в виде объектов Python, поэтому ими легко управлять и хранить, а объем копирования между узлами или внутри них сведен к минимуму. Последнее будет очень полезно, например, при работе с массивами NumPy.
Особенности Ray
Простые в компоновке примитивы фреймворка, а также богатый набор библиотек параллельного и распределенного вычисления позволяют разработчикам быстро масштабировать существующие приложения с помощью правки всего пары строк кода.
Собственный встроенный диспетчер кластеров может автоматически запускать ноды по мере необходимости на локальном оборудовании или на популярных облачных платформах.
Децентрализованный механизм планирования — свой планировщик задач работает на каждой машине.
Ray поддерживает десятки интеграций с популярными ML-проектами, такими как Scikit-Learn, FastAPI, XGBoost, PyTorch и TensorFlow, на протяжении всего жизненного цикла машинного обучения, что позволяет выбирать любимую библиотеку для ускорения и масштабирования.
Унифицированный и масштабируемый набор инструментов для регулирования рабочих нагрузок машинного обучения в таких областях, как распределенное обучение, настройка гиперпараметров, логические выводы и обслуживание в реальном времени.
Встроенная библиотека Ray Tune для поиска гиперпараметров и дополнительная tune-sklearn для их распределенной настройки.
В Ray нет встроенных примитивов для секционированных данных.
Поддержка GPU ограничена планированием и резервированием.
Область применения
Ray идеально подходит для легкого масштабирования рабочих нагрузок в приложениях на Python и распределенных системах искусственного интеллекта, включая проекты с машинным обучением (ML), глубоким обучением (DL) и обучением с подкреплением (RL).
Dask
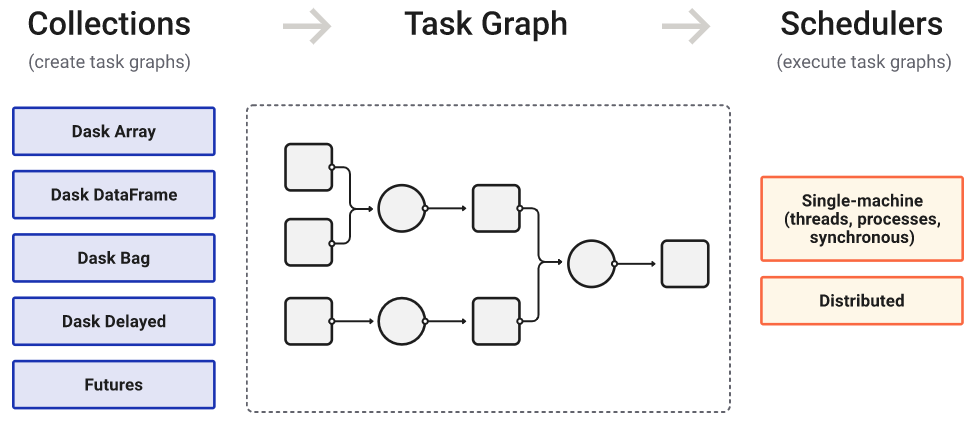
Это фреймворк для распределенных параллельных вычислений на Python с собственной системой планирования задач и поддержкой основных ML-проектов Python, включая NumPy, scikit-learn, PyTorch, XGBoost, Xarray, Prefect, RAPIDS.
Dask работает с параллельной обработкой данных двумя основными способами. Первый — это собственные компактные структуры данных с параллелизацией. По сути, Dask DataFrame создает свои версии массивов и списков NumPy или датафреймов Pandas, выполнение которых можно автоматически распространить по всему кластеру.
Второй способ — через низкоуровневые механизмы параллелизации, включая декораторы функций, которые распределяют задания по нодам и возвращают результаты синхронно (режим «immediate»), асинхронно (режим «lazy») или в смешанном режиме.
Особенности Dask
Dask может работать полностью асинхронно и взаимодействовать с другими приложениями с высокой степенью многопоточности. Хотя изначально фреймворк был построен на корутинах Tornado, в нем реализован уровень совместимости для сопрограмм AsyncIO.
Фреймворк использует централизованный планировщик, который обрабатывает все задачи для кластера.
Dask поддерживает шифрование и безопасную аутентификацию с использованием сертификатов TLS/SSL.
Продвинутая функция «Actors» (Actor — указатель на определяемый пользователем объект на удаленном воркере) позволяет фреймворку выполнять сложные распределенные вычисления с отслеживанием состояния в рабочем процессе.
Нет встроенной поддержки графического процессора. Для ускорения GPU использует набор библиотек RAPIDS.
Слабо реализована коммерческая поддержка.
Область применения
Фреймворк окажет незаменимую помощь при создании собственной системы параллельных вычислений с настраиваемой бизнес-логикой.
Bonobo

Это легкий и простой в использовании ETL (Extract-Transform-Load) фреймворк Python, который позволяет быстро разворачивать конвейеры и выполнять параллельное выполнение кода. Bonobo поддерживает широкий спектр источников данных, включая CSV, JSON, XML, XLS и SQL.
Платформа Bonobo разбивает каждый шаг ETL-конвейеров на объекты Python и связывает их вместе в графах нод. Атомарный дизайн помогает ограничить область применения каждого модуля и повышает удобство тестирования и обслуживания.
Особенности Bonobo
Главная и самая привлекательная особенность инструмента — максимальная простота использования. Благодаря этому, Bonobo так популярен у начинающих «пайтонистов».
Фреймворк содержит расширение Docker, которое позволяет запускать задания в контейнерах Docker.
Есть встроенный интерфейс командной строки (CLI).
Интеграция с пакетом Graphviz для визуализации графов заданий ETL.
Расширение SQLAlchemy добавляет в фреймворк богатые возможности, связанные с базами данных SQL.
Плагин Jupyter, входящий в основной пакет фреймворка, позволяет интегрировать его в функциональность Jupyter Notebookt.
Главное ограничение платформы Bonobo ETL — неспособность обрабатывать большие наборы данных, что затрудняет ее использование для более крупных проектов.
Область применения
Bonobo подойдет для написания первого ETL-конвейера во время изучения Python и методов ETL. Также фреймворк будет подспорьем для дата-сайентистов и бэкенд-разработчиков, которые хотят упростить работу по созданию конвейеров данных в небольших ETL-проектах на Python.
Hydra

Это среда Python с открытым исходным кодом, упрощающая разработку исследовательских и других сложных приложений. Название «Гидра» происходит от ее способности выполнять несколько одинаковых задач — очень похоже на Гидру с несколькими головами.
Ключевой особенностью Hydra является возможность динамически создавать иерархическую конфигурацию по композиции и переопределять ее через файлы конфигурации и командную строку. Во фреймворке существует несколько встроенных удобных функций, таких как поддержка ведения журнала, заполнение вкладок командной строки, которое позволяет легко узнать, как изменить конфигурацию вашего приложения в командной строке, и автоматическое сохранение моментального снимка конфигурации приложения в каталоге ведения журнала.
Особенности Hydra
Иерархическая конфигурация, компонуемая динамически из нескольких источников.
Конфигурацию можно указать или переопределить из командной строки.
Подключаемая архитектура позволяет быстро интегрировать фреймворк в имеющуюся инфраструктуру.
Динамическое завершение вкладок командной строки.
Фреймворк позволяет запускать приложение как локально, так и удаленно.
Запуск нескольких заданий с разными аргументами с помощью одной команды.
Дополнительная система ввода для обнаружения неправильных конфигураций.
Область применения
Функциональность Hydra охватывает разработку параллельных и распределенных систем, а также реализацию как классических, так и распределенных баз данных. Это позволяет эффективно использовать фреймворк для экспериментов с машинным обучением (ML), особенно в случае задач, связанных с глубоким обучением (DL).
Dispy

С помощью Dispy можно распределять по кластеру для параллельного выполнения как целые программы на Python, так и их отдельные функции. Фреймворк использует для сетевого взаимодействия многочисленные нативные инструменты, что позволяет работать одинаково быстро и эффективно на машинах с разными операционными системами — Linux, MacOS, Windows.
Синтаксис Dispy во многом напоминает устройство многопроцессорного приложения, только здесь, вместо пула процессов, создается кластер, который обрабатывает задания и возвращает результаты. Работу кластера Dispy можно гибко настраивать и четко контролировать. Например, можно возвращать предварительные или частично завершенные результаты, передавать файлы в рамках процесса распределения заданий и использовать SSL шифрование для безопасной передачи данных.
Особенности Dispy
Инструмент создан на основе pycos — независимого фреймворка для асинхронного, параллельного, распределенного сетевого программирования.
Поддерживается устранение сбоев на фронтеде и на бэкенде.
Вычисления (функции Python или автономные программы) и их зависимости (файлы, функции Python, классы, модули) распределяются по кластеру автоматически.
Вычислительные узлы могут находиться где угодно в сети — локально или удаленно. В целях безопасности можно использовать либо простую аутентификацию на основе хэша, либо SSL шифрование.
Возможность использовать динамическую доступность узлов — Dispy будет назначать в планировщике задания всякий раз, когда узел будет доступен для вычислений.
Область применения
Dispy хорошо подходит для создания и использования вычислительных кластеров, основанных на архитектурной концепции параллелизма на уровне данных (SIMD).
Pandaral·lel

Pandas — это быстрый, мощный, гибкий и простой в использовании инструмент для анализа и обработки данных с открытым исходным кодом, созданный на основе языка программирования Python. Основным его недостатком является тот факт, что фреймворк использует только одно ядро компьютера, даже если доступно несколько. Pandaral·lel, как следует из названия, — это инструмент, позволяющий параллельно выполнять задания Pandas на нескольких нодах, используя для их запуска несколько ядер на одном компьютере.
Основные операционные системы для фреймворка — MacOS и Linux. Хотя Pandaral·lel совместим и с Windows, он будет работать только из сеансов Python, запущенных в подсистеме Windows для Linux.
Особенности Pandaral·lel
Для параллелизации Pandas достаточно изменить одну строчку кода.
Прогресс каждого процесса отображается визуально с помощью индикаторной шкалы.
Использование Pandaral·lel для параллелизации позволяет ускорить выполнение процессов Pandas в 4 раза, по сравнению со стандартными операциями.
К недостатку инструмента можно отнести вдвое большее потребление оперативной памяти, по сравнению с обычным Pandas.
Область применения
Этот простой и эффективный инструмент подходит для параллельной обработки операций Pandas на всех доступных процессорах.
Ipyparallel

Ipyparallel (IPython Parallel) — это узкоспециализированная система многопроцессорной обработки и распределения задач, предназначенная для распараллеливания выполнения кода Jupyter Notebook в кластере. Проекты и команды, уже работающие в Jupyter, могут сразу использовать Ipyparallel.
Ipyparallel поддерживает множество подходов к распараллеливанию кода. Самый простой вариант — команда map, которая применяет выбранную функцию к каждому элементу в последовательности и равномерно распределяет задачу по доступным узлам. Для более сложных задач можно настроить отдельные функции так, чтобы они всегда выполнялись удаленно или параллельно.
Особенности Ipyparallel
Начиная с версии 4.0 фреймворк представляет собой отдельный пакет под названием «ipyparallel», а с версии 7 — устанавливаемое/подключаемое расширение для классического Jupyter Notebook и JupyterLab ≥ 3.0.
Подключить IPython Parallel в Jupyter Notebook можно на вкладке «IPython Clusters» на панели инструментов.
С помощью установки дополнительного модуля Python библиотеки mpi4py на Ipyparallel можно запускать код стандарта MPI (Message Passing Interface).
У Ipyparallel есть ряд собственных «магических команд», поддерживаемых Jupyter Notebook. Например, перед любым оператором Python можно вставить префикс %px, чтобы автоматически распараллелить команду на весь кластер.
Область применения
Фреймворк предназначен для управления кластерами параллельных процессов IPython, построенных на протоколе Jupyter.
Joblib

Joblib нацелен на повышение эффективности и решает две основные задачи — параллельное выполнение заданий и устранение ненужных повторных вычислений. Это делает Joblib подходящим для научных экспериментов, где воспроизводимость результатов являются абсолютно необходимым условием.
Синтаксис Joblib для распараллеливания достаточно прост — он представляет собой декоратор, который можно использовать для разделения заданий между процессорами или для кэширования результатов. Параллельные задания могут использовать потоки или процессы.
Функциональность Joblib включает хорошо оптимизированный кэш для обработки больших объектов Python, созданных вычислительными заданиями. Это не только помогает избежать повторных вычислений, но также позволяет приостанавливать и возобновлять длительные задания или восстанавливать выполнение задания после сбоя.
Особенности Joblib
Прозрачное и быстрое кэширование выходного значения на диске.
Вспомогательный класс joblib.Parallel сильно упрощает написание параллельных циклов for с использованием многопроцессорной обработки.
Встроенные методы joblib.dump и joblib.load (аналог формата сериализации объектов pickle) повышают эффективность работы с произвольными объектами Python, содержащими большие данные, в частности с большими массивами NumPy.
Области данных в кэше могут совместно использоваться несколькими процессами в одной системе с помощью метода numpy.memmap.
Отслеживание потока данных и промежуточных вычислений обеспечивает стабильную воспроизводимость вычислительного эксперимента.
Хорошая документированность с множеством практических примеров использования функций.
К недостаткам фреймворка относится отсутствие способа распределения заданий между несколькими отдельными компьютерами.
Область применения
Joblib — набор инструментов для упрощения конвейерной обработки данных в Python.
Фреймворк дает легкий способ добиться повышения производительности и воспроизводимости результатов при работе с большими данными и крупными объемами вычислений в таких областях, как научные исследования.
Pygrametl

Этот опенсорсный фреймворк Python, выпущенный под лицензией BSD, который предоставляет универсальный набор функций для разработки приложений ETL (Extract-Transform-Load).
Pygrametl содержит несколько классов для заполнения таблиц фактов и измерений (включая таблицы типа Snowflake и SCD), а также классы для извлечения данных из разных источников, классы для опционального определения потока ETL с помощью шагов, классы для распараллеливания и тестирования потоков ETL.
Особенности Pygrametl
Pygrametl предлагает новый подход к ETL-разработке, предоставляя структуру, которая абстрагирует доступ к базовым таблицам DW (data warehouse) и позволяет разработчику использовать всю мощь языка Python.
Фреймворк поддерживает как CPython, так и Jython, поэтому в созданной с его помощью ETL-программе можно использовать существующий код Java и драйверы JDBC.
Pygrametl поддерживает выполнение параллельных потоков ETL с использованием CPython только на платформах, которые запускают новые процессы с помощью системного вызова fork(). В CPython способ запуска процесса можно определить с помощью метода multiprocessing.get_start_method(). В Unix-подобных ОС fork() обычно используется по умолчанию или определяется тем же методом.
В архитектуре Pygrametl реализована прямая поддержка схем типа Snowflake, SCD (Медленно изменяющихся измерений) и других специализированных функций DW.
Область применения
Pygrametl широко используется в производственных вычислительных системах для таких секторов экономики, как здравоохранение, финансы и транспорт.
Apache Airflow

Это фреймворк Python с открытым исходным кодом, который позволяет создавать, планировать и отслеживать параллельно выполняемые рабочие процессы. Airflow можно использовать для создания проекта ETL или других типов конвейера данных.
Фреймворк основан на концепции направленного или ориентированного ациклического графа — DAG (Directed Acyclic Graph), которая позволяет запускать процессы параллельно, связывая несколько скриптов Python в граф зависимостей.
Особенности Apache Airflow
Все рабочие процессы в Airflow определены в чистом коде Python.
Для создания рабочих процессов можно использовать стандартные функции Python, включая форматы даты и времени для планирования и циклы для динамического создания задач.
Интерактивный пользовательский интерфейс облегчает отслеживание заданий, визуализируя зависимости, сбои и успешные выполнения рабочих процессов.
Apache Airflow не ограничивает объем конвейеров. Его можно использовать для создания моделей машинного обучения, передачи данных, управления инфраструктурой и многого другого.
К недостаткам Airflow можно отнести отсутствие версий конвейеров данных. Невозможно повторно развернуть удаленную задачу или DAG. Более того, фреймворк не сохраняет метаданные для удаленных заданий, поэтому отладка и управление данными особенно сложны.
Область применения
Платформа Apache Airflow отлично подойдет для команды дата-сайентистов, желающих лучше контролировать оркестровку пакетных рабочих процессов в Python приложениях с помощью написанных вручную сценариев.
Заключение
Область применения фреймворков Python с параллельной обработкой данных простирается от теоретических научных изысканий дата-сайенс до практических производственных задач в разных областях экономики. Везде, где нужно соединить удобство использования «змеиного языка» с повышенной производительностью, на помощь приходят многочисленные дополнительные фреймворки и библиотеки, как узкоспециализированные, так и универсальные.
Выбор подобных фреймворков Python достаточно велик, поэтому в этом обзоре мы привели лишь несколько наиболее ярких примеров таких технологических решений. Наверняка каждый читатель из активно практикующих питонистов сможет дополнить список своим излюбленным инструментом.
Комментарии (3)

durnoy
04.04.2023 09:19В статье описаны двенадцать фреймворков, и ещё два уже докинули в комментариях.
При таком количестве вариантов даже раздела "Область применения" помогают мало, к сожалению.
Интересно, можно ли составить граф выбора на основе вопросов о конкретной задаче.
Dark_Furia
Стоит добавить в рассмотрение polars
sc07kvm
И Faust