
Привет, меня зовут Артур Яковлев, я делаю голосовой перевод видео в Яндекс Браузере. Примерно с лета я работаю над тем, чтобы научить Браузер переводить с китайского на русский. Почему мы посчитали это важной и интересной задачей? Дело в том, что китайская часть интернета содержит значительное количество видеоконтента, который за пределами страны почти не смотрят.
Множество диалектов, влияющие на смысл тоны и грамматические нюансы — ряд особенностей китайского усложняют разработку распознавания речи. Сейчас я коротко расскажу читателям Хабра о трудностях языка и объясню, как мы их преодолели.
С чего мы начинали
Есть множество региональных языков и групп диалектов: кантонский, хакка, минь и другие. Они сильно отличаются, и их носители даже не всегда понимают друг друга. Самый распространенный вариант — севернокитайский язык. На Западе он известен как мандаринский. Им владеет почти миллиард человек, и это больше 70% населения Китая. Поэтому для перевода видео наша команда выбрала именно его. В нём примерно 400 основных слогов — и это без учёта тонов. Кстати, слоги не равны иероглифам, но об этом чуть позже.
Что мы сделали: пайплайн обучения мы отработали на множестве языков. Он отлажен для случаев, когда есть готовый качественный датасет. Для китайского готового датасета не было, так что пришлось собирать его.
Самый сложный этап — найти много размеченных данных с текстами и привести их в нужный вид. В случае китайского было важно разделять диалекты и проверять валидность данных. Вот как мы построили работу:
- Поскольку мы хотим переводить видео, то и учиться распознавать речь нужно на видео. Поэтому взяли несколько тысяч часов видео, для которых есть китайские субтитры.
- Отфильтровали по языку. Часто китайские субтитры можно встретить для роликов на английском языке. Используем классификатор, который знает несколько китайских диалектов.
- Достали из видео все куски с голосом на основе субтитров в VTT-формате, который содержит фразы со временем их начала и конца. Текст в субтитрах сам по себе довольно шумный – там могут быть цифры, даты, символы процентов и так далее. Данные нужно нормализовывать. Для этого использовали готовую библиотеку.
- Нарезали видео на чанки в соответствии с субтитрами.
- Отфильтровали видео по субтитрам. Проблема в том, что в субтитрах не всегда написана правда. Если субтитры отмечены как китайские, это не значит, что они действительно на китайском. Кроме того, в них бывают сдвинуты тайминги, они могут описывать происходящее на экране и т.д. Справиться с этим помогла модель с Hugging Face, обученная на мандаринском диалекте. С её помощью мы оценили субтитры и отобрали подходящие для обучения нашей модели.
- В результате получили набор видео с хорошими субтитрами, валидными для обучения акустической модели.
Иероглифическая, а не алфавитная письменность
Чтобы перевести видео, сначала нужно распознать речь и превратить её в текст — поэтому важно разбираться в письменности исходного языка. В китайском она совершенно не похожа на привычный русский или английский языки, ведь в нём нет алфавита.
Вместо него есть десятки тысяч иероглифов, из которых можно составлять слова и фразы — как из конструктора. Например, слово «компьютер» записывается двумя иероглифами: «электронный» и «мозг». Довольно логично! Каждый иероглиф читается как слог, при этом многие иероглифы произносятся одинаково, поэтому их число намного больше слогов (это называется омофонией и представляет отдельную особенность; дальше расскажу о ней подробнее). Впрочем, все 20 тысяч иероглифов мало кто знает наизусть — для нормального общения людям хватает и пары тысяч.
А ещё в китайском языке нет привычного для европейской письменности разделения на слова, а текст выглядит как сплошная последовательность иероглифов.
Что мы сделали: парадоксально, но система китайской письменности, которая порой ставит в тупик иностранцев, вообще не стала проблемой для обучения модели. Она использует словарь токенов — по сути, слогов. Если все европейские языки помещаются в 5000 токенов, то наш словарь для китайского — это 10 000 токенов. Разница только в объёме. Для токенизации используем распространённый алгоритм BPE. Размер словаря выбрали с учётом того, чтобы часто используемые комбинации иероглифов были объединены в один токен — это может помочь при декодировании и понимании контекста.
А вот отсутствие деления на слова немного усложнило нам жизнь. В одной части данных, которые мы использовали для обучения моделей, были пробелы между словами, в другой их не было. Помнив о том, что в китайской письменности нет деления на слова, мы просто выкинули везде пробелы, чтобы унифицировать датасеты. Это была ошибка, ведь наша инфраструктура опирается на пробелы, чтобы расставлять алайнменты — то есть, метки времени для фрагментов текста. В итоге ASR выдавала распознанный текст с неправильными метками. Мы решили проблему, применив на этапе предобработки данных библиотеку, которая расставила пробелы. Получилось условное разделение на «слова», которое помогло верно расставить алайнменты.
Тоны определяют смысл
Произношение — ключевая характеристика китайской речи. Дело в том, что слова меняют смысл в зависимости от того, как их произнести. Тон — это мелодический рисунок голоса. Выделяют четыре основных тона:
Первый тон — произносится ровно и высоко:

Второй тон — восходящий, со среднего до высокого регистра, голос повышается ближе к концу:
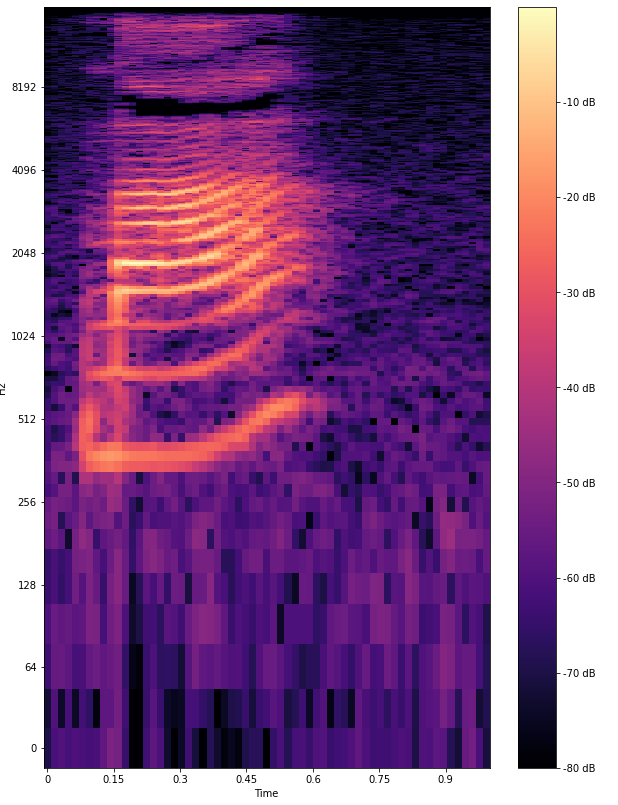
Третий тон — нисходяще-восходящий, сначала понижается с низкого регистра, затем быстро поднимается к верхнему регистру:

Четвёртый тон — нисходящий, быстро падает с высшей точки вниз.

Есть ещё нейтральный тон — точнее, отсутствие тона. Встречается в местах, где нет смыслового ударения.
Эти особенности сложно передать на письме, лучше послушать примеры. Хорошая новость в том, что нейросеть распознаёт различные тоны не хуже, чем это делают люди.
Что мы сделали: здесь вообще ничего дополнительного делать не пришлось. Модель сама научилась распознавать тоны по обучающим данным. Получается, что то, на что студенты-китаисты тратят кучу времени, модель сделала сама очень быстро: после сбора данных процесс обучения занял примерно месяц — за это время модель проанализировала столько данных, сколько человек не услышит и за 15-20 лет жизни в Китае.
Нужно хорошо понимать контекст
С одной стороны, в китайском простые правила нормализации: слова, в общем, не меняются в зависимости от лица, времени, вида, рода, числа или падежа. Это упростило подготовку данных по сравнению, например, с французским языком.
С другой стороны, при распознавании китайской речи важно учитывать контекст из-за обилия омофонов в языке. Омофоны — это слова, которые звучат одинаково, но пишутся по-разному и при этом обладают разным значением. Есть даже вполне содержательная поэма, состоящая из 92 слогов «ши». Омофоны представляют интересную задачу для распознавания, потому что одного произношения недостаточно — важен контекст.
Что мы сделали: понимание контекста не стало проблемой. Наша модель давно умеет учитывать предыдущий текст при распознавании — можно сказать, что мы всегда готовились понимать китайский.
Кроме того, помогло разбиение на BPE-токены. Например, иероглиф 谓 («сказать», произносится «вей») почти всегда встречается в комбинации с другими иероглифами: 可谓 («можно сказать», «кэ-вей») и 所谓 («так называемый», «суо-вей»). Такие комбинации различать между собой проще, чем сами токены, поскольку у них уникальное произношение. Использование BPE вместе с делением на «слова» позволяет выделить подобные комбинации на стадии подготовки данных.
Как мы доработали перевод
Пара слов о том, как работает перевод с китайского. Он устроен как последовательность двух переводов: сперва с китайского на английский, потом с английского на русский.
Сначала мы использовали нашу стандартную модель перевода. Отдавали в модель предложения на китайском и получали на русском. У такого подхода было два существенных недостатка. Во-первых, в отличие от нашей англо-русской модели, она не учитывала контекст. Во-вторых, модель не была адаптирована под видео: она училась на массиве всех данных и не выделяла среди них субтитры, которые как раз важны для перевода видео.
Когда мы заметили, что эти недостатки влияют на качество, то начали исправлять их. Например, с китайского на английский переводим по предложениям, а затем подключается англо-русская модель, которая хорошо понимает контекст и учитывает его при переводе. Вторую проблему решили, дообучив модель на релевантных для перевода видео данных, что позволило повысить качество.
Также пришлось учесть различия в пунктуации китайского и русского. Одна фраза на китайском языке может содержать несколько отдельных смысловых частей, которые человек переведёт в несколько предложений. Расстановка пунктуации по настоящим правилам сильно усложняет перевод, ведь для учёта контекста придётся отдельно разбивать на предложения уже готовые переводы с китайского на английский. Поэтому удачным решением мы посчитали своего рода «гибридный» пунктуатор: он расставляет знаки препинания, принятые в китайском, но выделяет смысловые части в отдельные предложения.
Такой пунктуатор мы получили с помощью существующей модели перевода с китайского. Она умеет переводить одно китайское предложение в несколько английских, чем мы и воспользовались: взяли большое количество китайских данных, перевели их на английский, а затем нашли соответствие пунктуации перевода и оригинального текста (т.н. выравнивание). Это соответствие позволило понять, где в китайских предложениях нужно заменить запятые на точки, чтобы добиться большей гранулярности в обучающих данных пунктуатора.
И вот результат:
Технология перевода видео во многом универсальна, даже сложности китайского не потребовали перепридумывания всей архитектуры. Как можно заметить, здесь я почти не говорил про корректировки в ML-моделях, и мы считаем, что отсутствие необходимости что-то серьёзно менять от языка к языку — это важный плюс.
Перевод с китайского доступен на YouTube. Чтобы всё заработало, перезапустите Яндекс Браузер. Дальше можно, например, посмотреть обзоры на новые устройства или познакомиться с китайской кухней. Чуть позже появится поддержка популярной китайской видеоплатформы Bilibili.
Комментарии (48)

LeToan
17.04.2023 07:19+11Севернокитайский диалект, который на английском называется mandarin, русским известен как путунхуа.

AlexWork22
17.04.2023 07:19+6Кстати, слоги не равны иероглифам, но об этом чуть позже.Не увидел дальше обьяснения почему это так.

cleverowl
17.04.2023 07:19Насколько я понял, слог — звучание, иероглиф — написание. Нескольким иероглифам может соответствовать одно и то же произношение, и, соответственно, слог тоже.

domix32
17.04.2023 07:19Думаю более вероятно ситуация, когда одному иероглифу соотвествует больше одного слога. Например, 楢 в японском может читаться двумя слогами na-ra. Подозреваю, что у китайского аналогичная ситуация.

cinatech
17.04.2023 07:19В японском два чтения иероглифа: исконно японское китайское - он. А в китайском просто много омофонов - одинаково звучащих,но разных по написанию иероглифов. https://youtu.be/pSRCzk61s_4
domix32
17.04.2023 07:19Речь была не про это, а про то что на один иероглиф в одном из чтений приходится по несколько слогов сразу, а не произношений. В каком оно чтении не сильно принципиально т.к. и в том и в другом бывают множественные слоги. Поэтому и написал что тот иероглиф может читаться так, а не всегда так читается.
cinatech
17.04.2023 07:19+2Я понял, о чем вы. Я изучал и китайский и японский. Да, в японском иероглиф может состоять из нескольких слогов, это как раз японское кунное прочтение, и есть онное - китайское, используемое в составных иероглифических словах. А вот в китайском языке все иероглифы (не путать словами, которые состоят из иероглифов) односложные. И на один слог может приходиться пара десятков иероглифов. В то же время чтение одного иероглифа разными слогами в рамках одного диалекта - явление редкое.
AlexWork22
17.04.2023 07:19+1В Китайском языке это не так, один иероглиф - один слог. И как раз произношение на один иероглиф может быть разным (явление не частое, но есть). Примеры: 谁,觉 и тд.
AlexWork22
17.04.2023 07:19По моему знанию, после пяти лет жизни в Китае и сдачи языкового экзамена на уровень HSK 5(тут и первого уровня будет достаточно), в моем понимании иероглиф это слог. То как он может читаться, это другой разговор, и сути не меняет. Вот мне и интересно было услышалть обьяснение, как это так, что иероглиф это не слог.

mas
17.04.2023 07:19Грубо говоря, слогов всего 400 (https://yoyochinese.com/chinese-learning-tools/Mandarin-Chinese-pronunciation-lesson/pinyin-chart-table), с тонами 1600, а иероглифов (т.е. разных слов или частей слов) -- десятки тысяч, 30-40-50 и более. Каждый иероглиф звучит как слог, т.е. на одно звучание -- множество иероглифов/смыслов. Страшная омофония, в тексте про это есть.
Если фразу можно понять, что иероглиф -- это не всегда слог, то да, неудачная фраза. Обычно так и есть, один слог. Не Япония, чай.


UtrobinMV
17.04.2023 07:19+7Напишите название сайтов где можно смотреть видео контент на китайском. В частности по Deep Learning. С переводом в яндекс браузере. Не в YouTube же. Так как он запрещен на территории китая. И нормальные видосы там не выкладываются.
vkam
17.04.2023 07:19bilibili должно быть.
UtrobinMV
17.04.2023 07:19Спасибо. Зашел на bilibili. Сайт вообще прикольный. Видео грузится быстро, китайского контента огромное количество. Но Яндекс переводчик видео к сожалению там пока не работает!!! Ждем когда ребята из Яндекс добавят переводчик к bilibili !!!!



AlexSpirit
17.04.2023 07:19Пользуюсь переводом видео с Ютьюба постоянно, но отсутсвие на андроид планшетах тёмной темы в браузере очень мешает.

Finterio
17.04.2023 07:19У меня на андроид телефоне есть яндекс браузер, и у меня в нём подключено дополнение "Care your Eyes", в котором по нажатию на тонкую верхнюю полоску включается темная тема
domix32
17.04.2023 07:19+4А, ну то есть видео подразумевалось смотреть в ЯБро. То-то я думаю я чо-то эффекта не почуял.
Ждём когда появится возможность проворачивать что-то такое


andreystashev
17.04.2023 07:19Было бы здорово иметь возможность переводить обратно с русского на английский? Это вообще планируется внедрять в ближайшее время?

ftdgoodluck
17.04.2023 07:19-4вы что, английский это же язык врага, вдруг ненароком им какую-нибудь гостайну переведут, и все

karimullin
17.04.2023 07:19+1Не хватает возможности запускать перевод видео в Яндекс Браузере для ТВ. Приходится совершать кучу лишних действий, транслируя с телефона.

tetelevm
17.04.2023 07:19+6А зачем перевод через английский, какая проблема в переводе кит->рус напрямую?
И оффтопом вопрос, Яндекс.Переводчик намного хуже в переводе, чем DeepL. Нет статей, почему так и в чём различие разных переводчиков?


Storkur
17.04.2023 07:19+2Спасибо большое за такой функционал!
А можно как то включить озвучивание видео на русском, в которых речь уже на русском? Просто у меня есть некоторые особенности со слуховым восприятием, а еще иногда просто с плохим качеством аудио дорожка. Переозвучка пригодилась бы людям с ограниченными возможностями.

artemerschow
17.04.2023 07:19+1У меня иногда так включалась переозвучка, когда спарсило несколько английских слов.
Yvlog
17.04.2023 07:19в обратную сторону, с русского на китайский, перевод видео будет по сложнее однако????
imjustwatching
Когда ваш браузер перестанет навязывать ваши сервисы и принудительно включаться со стартом компьютера и ставить туеву хучу ваших алис и прочего трэша, а еще перестанет следить за каждым кликом, возможно мы оценим все функции которые вы к тому времени введете. А так конечно очень интересно, молодцы.
SeregaSA73
+
И это лично для меня единственная причина почему на всех компах стоит Хром, у друзей кстати тоже, тк не хочу к ним бегать и удалять всякую хренотень.
Tempelfeld
Разница в том, что Хром предлагает гугловские сервисы? Вот честно, запустил Хром и Яндекс и разницы не заметил. Я понимаю, если бы Вы Firefox привели в пример (там, действительно, минималистично), но Хром?
kacetal
А что хром не навязывает сервисы гугла и не следит за каждым кликом?
Watashiwa
Т к. Я понимаю в моем случае нет он не ставит пока ещё что-то наподобие Алисы по умолчанию не создаёт два значка типа одного мало. Не запускается автоматом после перезагрузки. Да это все можно убрать и настроить, но не проще ли наоборот ничего не ставить, а уже кому надо доставить
morpheuz
Т.е. когда заходил на гугл не было сообщения, что браузер устарел, и нужно установить новый.
Или когда ставил adobe flash вместе ставился и хром, и куча фришного софта шла с довеском в виде хрома.
Кстати, хром точно так же авто-стартует в дефолтной установке.
И добавляет службу автоапдейта.
Watashiwa
Службы добавляют все и яндекс и хром и мозила(а некоторые вроде бы даже две). Но у меня хром не запускается сразу при входе в систему (речь именно про приложение), так что не знаю как вы ставите. А вот при чем тут флеш? Вы уж тогда и весь бесплатных софт назовите с которым яндекс ставился ;)
imjustwatching
Интересно какие сервисы гугл навязывает через хром? Всплывающим на всё лицо квадратом "Устанавити наш браузер, поиск, переводчик, наши карты, наш мессенджер, наш диск, наш менеджер браузеров"?
Hidden text
TheHangedKing
Прочитал комментарии и как будто попал в альтернативную реальность. Множество комментариев с отрицанием общеизвестных фактов от пользователей без публикаций и с парой комментов. Что это, новый уровень PR-службы компании, или новый уровень их целевой аудитории? Скорее, второе, но всё равно грустно.
BarakAdama
Простите, но на обоих ваших скриншотах нет Браузера.
Pavel_Asafov
Браузер нельзя настроить под ваши предпочтения?
ElonMusc
а зачем тратить свое дорогое время на это? (firefox)
Pavel_Asafov
Нужно курсы проходить что бы разобраться в этом или что? Можно один раз настроить (за промежуток времени в течение дня), а в будущих установках подтвреждать настройку персональных предпочтений вашей учётной записи.
orada
Пользуюсь браузером с тех пор как он вышел, и он намного удобнее хрома. А именно перевод фраз через выделение слова/предложений, быстрые кнопки для копирования ссылок, перевод на лету видеозаписей с ютуба, группы папок с вкладками, воспроизведение статей голосом и т.д. Хром визуально выглядит устаревшим. Да я не спорю что яндекс лезет со своей алисой, автозапуском, но есть возможность отключить это все зайди в настройки браузера и все. При этом я даже нашел неплохой баг в яндекс браузере с рендером цветов в figma, и этот баг из-за использования движка хрома, там он аналогичен)
ru1z
Сколько я помню браузеров с оцпиональными дополнениями, все свистододелки, особенно связанные с переводом, можно было очень легко подключить, если они были нужны. Особенность прибитых свистододелок в том, что их трудно отключить, если они вам не нужны. Мне нравится яндекс-браузер только тем, что он составляет некоторую конкуренцию хрому, в остальном он не впечатлил. Перевод видео, да еще многоголосый — интересно, но хитрозакрученно прибитый к браузеру — в этом исчезающе мало смысла. Хром на момент выхода выигрывал во многом своей скоростью, потом он раздулся собственными свистододелками и обратно обогнал "тормозиллу", а яндекс в желании обвешать улучшайзерами обгоняет хром.
Надоедает, что компании пытаются привязать пользователей какой-то мелкой опцией к своему браузеру и экосистеме (edge — хайпочатом и интеграцией с офисом, а хром — ютубом, хотя сейчас у хрома такое реже проявляется) и для этого напячивают комбайн как неро (burning rom). Если пользователь когда-нибудь захочет перейти на другой браузер по собственным причинам (в конце концов, в какой-то момент ушли от ie), то это бывает сложно.
imjustwatching
Помните передачу по MTV, тачку на прокачку? Так вот яндекс браузер это "Браузер на прокачку", взяли хромиум опенсорсный и запихнули туда все что можно запихнуть, мониторы в задние сиденья, колонки на весь багажник и тд. Навешивать в инсталлятор софтварный мусор, в надежде что юзер не заметит галочек или не будет в них разбираться, это грязная игра и не достойный подход к своему пользователю. Пользоваться такими продуктами, себя не уважать.
а еще основные юзеры это люди не особо глубоко разбирающиеся в компьютерах, пенсионеры и просто возрастные потребители интернета, и этот яндекс браузер тяжеленный с автовключением, убивает их систему напрочь, они приносят когда свои ноутбуки на ремонт или обслуживание, там из-за яндекса комп в зависшем состоянии минут по пять стоит, пока яндекс загрузится и всю дату собранную передаст на свои сервера чтоб рекламу им потом показывать персонализированную.