
 Привет, Хаброжители!
Привет, Хаброжители!API представляют собой контракты, которые определяют принципы взаимодействия приложений, сервисов и компонентов. Паттерны проектирования API — это набор лучших практик, спецификаций и стандартов, обеспечивающих простоту и надежность их использования для разработчиков. Книга объединяет и объясняет наиболее важные паттерны, используемые сообществом разработчиков API и экспертами Google.
Паттерны проектирования API определяют набор принципов для разработки внутренних и публичных API. Джей Джей Гивакс, будучи специалистом из Google, рассказывает о паттернах, которые обеспечат вашим API согласованность, масштабируемость и гибкость. Вы узнаете, как улучшить дизайн самых распространенных API и как действовать в сложных пограничных случаях. Понятные иллюстрации, актуальные примеры и подробные сценарии позволят тщательно разобраться в каждом паттерне.
Для кого эта книга
Эта книга для всех, кто уже разрабатывает веб-API или планирует заняться его разработкой, в особенности собираясь сделать его публичным. Будет хорошо, если читатели будут знать о некоторых форматах сериализации (например, JSON, Google Protocol Buffers или Apache Thrift) и распространенных парадигмах хранения данных (например, схемах реляционных баз данных), но эти знания вовсе не обязательны. Будет кстати и наличие опыта работы с HTTP и его методами (например, GET и POST), поскольку именно этот протокол был выбран для использования в примерах книги. Если в процессе разработки API вы столкнетесь со сложностями и подумаете: «С этим уже точно кто-то разобрался», — то эта книга для вас.
Копирование и перемещение
Несмотря на то что неизменяемыми считаются очень немногие ресурсы, зачастую встречаются определенные атрибуты, которые можно уверенно считать неизменными, в частности уникальный идентификатор ресурса. Но что, если мы хотим его переименовать? Как можно сделать это безопасно? А что, если нужно переместить ресурс от одного родителя к другому? А если мы хотим его дублировать? Далее мы познакомимся с безопасным способом выполнения этих операций, охватывающим и копирование (дублирование), и перемещение (изменение уникального идентификатора или смена родителя) ресурсов в API.
17.1. Зачем это нужно
В идеальном мире иерархические связи между ресурсами спроектированы наилучшим образом и неизменны. Самое же главное, что в этом магическом мире пользователи API никогда не совершают ошибок и не создают ресурсы в неправильных местах. И они определенно никогда не спохватываются, задним числом осознав допущенную оплошность. В этом мире никогда не возникает потребности в переименовании или перемещении ресурса в API, поскольку ни мы как разработчики API, ни наши пользователи как его потребители не допускаем ошибок в схеме расположения ресурсов и их иерархии.
Этот мир мы рассматривали в главе 6 и подробно обсуждали в подразделе 6.3.6. К сожалению, это не тот мир, в котором мы существуем, а значит, нужно учитывать вероятность, что однажды пользователю API потребуется возможность перемещать ресурс под другого родителя в иерархии или изменять его ID.
К тому же все усложняют вероятные сценарии, в которых пользователям требуется дублировать ресурсы, потенциально копируя их в другие участки иерархии. И хотя оба этих случая на первый взгляд кажутся довольно простыми, как и большинство тем в проектировании API, они порождают необходимость ответить на множество различных вопросов. Цель текущего паттерна — обеспечить потребителям API возможность переименовывать и копировать ресурсы по всей их иерархической структуре безопасным, стабильным и (чаще) простым способом.
17.2. Обзор
Для перемещения или переименования ресурса нельзя применять стандартный метод Update, поэтому лучше обратиться к пользовательским методам. К счастью, общий принцип работы этих методов копирования и перемещения довольно прост. Вот только дьявол, как обычно, кроется в деталях, таких как копирование ресурса ChatRoom и перемещение ресурсов Message между разными родительскими ресурсами ChatRoom (листинг 17.1).

В этом примере не отражены несколько важных вопросов. Для начала, при копировании/перемещении ресурса выбираете ли вы уникальный идентификатор или же это делает сервис, как при создании нового ресурса? Есть ли разница при осуществлении операций между родителями (где вы можете пожелать оставить прежним идентификатор, просто принадлежащий другому родителю) и их выполнении внутри одного родителя (где вам, предположительно, просто нужно изменить ID)?
Далее, когда вы копируете ресурс ChatRoom, копируются ли вместе с ним все принадлежащие ему ресурсы Message? Что, если к ним прилагаются объемные вложения? Копируются ли эти дополнительные данные? Причем вопросы на этом не заканчиваются. Нам еще нужно выяснить, как сделать так, чтобы копируемые/перемещаемые ресурсы не находились в работе у пользователей, а также разобраться, что делать со старыми идентификаторами и со всеми наследуемыми метаданными, такими как политика контроля доступа.
Коротко говоря, несмотря на то, что этот паттерн опирается лишь на специфичный пользовательский метод, одного определения данного метода здесь будет недостаточно. В следующем разделе мы углубимся во все эти вопросы, чтобы получить поверхность API, гарантирующую безопасное и стабильное копирование/перемещение ресурсов.
17.3. Реализация
Как мы видели в разделе 17.2, для копирования и перемещения ресурсов по иерархии API можно задействовать пользовательские методы. Однако мы не обратили внимания на некоторые важные нюансы этих методов и то, как они фактически работают. Начнем с очевидного: как нужно определять идентификатор копируемого/перемещаемого ресурса?
17.3.1. Идентификаторы
Как мы узнали в главе 6, обычно лучше оставлять выбор уникальных идентификаторов самому сервису API. Это означает, что при создании новых ресурсов мы можем указывать идентификатор родительского ресурса, но сами новые ресурсы будут получать ID, выходящий за рамки нашего контроля. И на то есть весомая причина: человек склонен выбирать для ресурсов весьма неудачные идентификаторы. То же самое происходит, когда дело касается копирования/перемещения ресурсов. В некотором смысле оба этих действия сродни созданию нового ресурса, выглядящего в точности аналогично существующему, с последующим (в случае перемещения) удалением исходного.
Но даже если созданный ресурс получает идентификатор, присваиваемый сервисом API, то каким он должен быть? В этом случае наиболее удобный вариант будет зависеть от нашего намерения. Если мы хотим переименовать ресурс, чтобы он имел новый ID, но остался на том же месте в иерархии, то более подходящим скорее окажется выбирать идентификатор вручную. Это особенно верно, если API допускает пользовательские ID, поскольку мы наверняка будем менять одно подходящее имя ресурса на другое (например, нечто вроде databases/database-prod в databases/database-prod-old). С другой стороны, если мы хотим переместить что-то с одной позиции в иерархии в другую, то наверняка окажется лучше, если новый ресурс будет иметь тот же идентификатор, но принадлежать другому родителю (например, при перемещении существующего ID chatRooms/1234/messages/abcd в chatRooms/5678/messages/abcd; обратите внимание на общую часть messages/abcd). И поскольку эти сценарии довольно заметно различаются, мы разберем их по отдельности.
Копирование
Выбор идентификатора для дублирующего ресурса оказывается довольно простой задачей. Независимо от того, копируете вы его в того же или другого родителя, метод Copy должен действовать идентично стандартному методу Create. То есть если в вашем API выбраны пользовательские идентификаторы, метод Copy должен также позволять пользователю указывать целевой ID для нового ресурса. Если же в сервисе поддерживаются лишь генерируемые им самим идентификаторы, то делать исключение и разрешать пользовательские здесь не нужно. (Если разрешить, то возникнет брешь, через которую любой сможет выбирать собственные идентификаторы, просто создавая ресурс, а затем копируя его в нужное место.)
В результате запрос на копирование ресурса будет принимать и целевого родителя (если этот тип ресурса имеет родителя), и, в случае разрешенных пользовательских идентификаторов, целевой ID (листинг 17.2).

Это может привести к неожиданным результатам. Например, если API не поддерживает пользовательские идентификаторы, то запрос на копирование любого высокоуровневого ресурса требует всего одного параметра: ID самого копируемого ресурса. В противном случае есть вероятность, что мы захотим скопировать ресурс в того же родителя. Тогда поле destinationParent будет совпадать с родителем ресурса, на который указывает поле id.
Кроме того, даже в случаях, когда API поддерживает пользовательские идентификаторы, при дублировании ресурса нам может потребоваться скопировать автоматически генерируемый ID. Для этого мы просто оставим поле destinationId пустым, обратившись таким образом к сервису с просьбой выбрать идентификатор за нас.
Наконец, когда пользовательские идентификаторы поддерживаются, есть вероятность, что целевой ID внутри целевого родителя может оказаться занят. В этом случае может возникнуть соблазн вернуться к идентификатору, генерируемому сервером, чтобы обеспечить успешное дублирование ресурса. Однако этого нужно избегать, поскольку такой подход нарушит пользовательское представление о расположении нового ресурса. Вместо этого сервис должен возвращать эквивалент HTTP-ошибки 409 Conflict и отменять операцию копирования.
Перемещение
Когда дело доходит до перемещения ресурсов, у нас есть два немного разных сценария. С одной стороны, пользователей может интересовать перемещение ресурса в другого родителя в иерархии, например, перемещение ресурса Message из одного ресурса ChatRoom в другой. В свою очередь, пользователи могут пожелать переименовать ресурс, технически переместив его в того же самого родителя, но с другим конечным ID. Кроме того, возможно, что нам потребуется проделывать и то и другое одновременно (перемещать и переименовывать). К тому же все усложняется необходимостью помнить, что переименование ресурсов имеет смысл, только если API поддерживает пользовательские идентификаторы.
Для обработки этих сценариев может показаться уместным снова задействовать отдельное поле, как в листинге 17.2, где у нас есть целевой родитель и целевой идентификатор. Однако в этом случае мы всегда знаем, каким именно будет итоговый идентификатор (в сравнении с методом Copy, когда мы можем опереться на ID, генерируемый сервером). Этот ID либо совпадает с исходным ресурсом, но имеет другого родителя, либо оказывается совершенно новым, выбранным нами. В результате мы можем использовать одно поле destinationID и ввести некоторые ограничения для значения этого поля, в зависимости от того, поддерживаются ли пользовательские идентификаторы. Если да, то допустмым будет любой полноценный идентификатор. Если же нет, то валидными новыми идентификаторами будут считаться лишь те, которые меняют только свою родительскую часть, остальную оставляя прежней.
Таким образом, мы получаем структуру запроса Move, который принимает только два поля: идентификатор перемещаемого ресурса и предполагаемое место его итогового размещения после завершения операции (листинг 17.3).

Как видите, для ресурсов верхнего уровня (не имеющих родителей) метод перемещения имеет смысл, только если API поддерживает пользовательские идентификаторы. Эта ситуация весьма отличается от метода копирования, который здесь по-прежнему окажется уместен. Проблема состоит в том, что перемещение решает две задачи: перенос ресурса в другого родителя и его переименование. Последнее имеет смысл только при наличии поддержки пользовательских ID. Первое же окажется уместным, только если у ресурса есть родитель. В случаях, когда ни одно из этих условий не выполняется, метод Move становится полностью бессмысленным и вообще не должен реализовываться.
Теперь, когда у нас есть представление о форме и структуре запросов на копирование и перемещение ресурсов, перейдем к обработке более сложных сценариев.
17.3.2. Дочерние ресурсы
До сих пор мы работали с условием, что каждый ресурс, который мы хотим переместить или скопировать, является полностью самодостаточным. По существу, мы исходили из того, что ресурс не содержит, помимо одной записи, никакой дополнительной информации, которую бы требовалось скопировать. Это допущение значительно упрощало работу, но, к сожалению, не всегда оказывается безопасным. Вместо этого нам нужно предположить, что с ресурсами будут связаны дополнительные данные, которые также потребуется скопировать или переместить. Как это обработать? Нужно ли вообще беспокоиться об этих лишних данных?
Коротким ответом будет «да». Проще говоря, внешние данные и связанные ресурсы (например, дочерние) редко присутствуют бесцельно. В результате копирование/перемещение ресурса без включения этих связанных данных наверняка приведет к неожиданному результату: новому целевому ресурсу, который будет работать не так, как исходный. А поскольку одной из основных целей хорошего API является предсказуемость, то исключительно важно обеспечить, чтобы копируемый или перемещаемый ресурс оказался максимально идентичен исходному. Как же этого добиться?
Для начала, будь то копирование или перемещение, необходимо включить все дочерние ресурсы. Например, это означает, что в случае копирования/перемещения ресурса ChatRoom все дочерние Message также должны быть скопированы/перемещены, получив новый родительский ID. Очевидно, что это предполагает намного больший объем работы, чем обновление одной строки. Более того, количество необходимых обновлений зависит от количества дочерних ресурсов. То есть логично ожидать, что копирование ресурса с несколькими дочерними ресурсами займет намного меньше времени, чем аналогичная операция с похожим ресурсом, имеющим множество потомков. В табл. 17.1 показан пример идентификаторов ресурсов до и после операции копирования/перемещения.
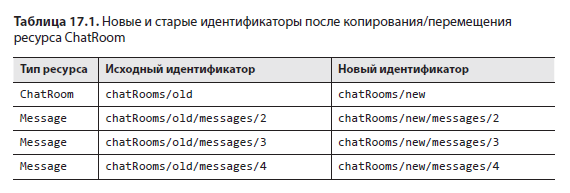
И хотя применительно к копированию на этом сложности заканчиваются, это не относится к перемещению ресурсов. В этом случае после завершения обновления всех ID мы по факту создали совершенно новую проблему: все прежние ссылки на эти ресурсы теперь недоступны, хотя сами ресурсы по-прежнему существуют. В следующем подразделе мы узнаем, как обрабатывать такие ссылки, будь то внутренние или внешние.
17.3.3. Связанные ресурсы
Хоть мы и решили, что все дочерние ресурсы должны копироваться/перемещаться вместе с целевым ресурсом, мы ничего не сказали о связанных ресурсах. Например, представим, что наш API чата с помощью ресурса MessageReviewReport предоставляет отчет о сообщениях, которые могут оказаться неподходящими. Этот ресурс сродни обращению в поддержку по поводу сообщения, которое было отмечено как неподходящее и должно быть рассмотрено. Он не обязательно должен быть потомком ресурса Message (или даже ресурса ChatRoom), но при этом должен ссылаться на соответствующий ресурс Message (листинг 17.4).

Существование этого ресурса (и тот факт, что его поле messageId является ссылкой на ресурс Message) вызывает два очевидных вопроса. Во-первых, должны ли при дублировании Message дублироваться и все ресурсы MessageReviewReport, ссылающиеся на исходное сообщение? Во-вторых, если ресурс Message перемещается, то должны ли также обновляться все MessageReviewReport, ссылающиеся на перемещаемый ресурс? Эти вопросы еще больше усложняются, если вспомнить, что копирование и перемещение ресурсов Message может быть вызвано не обязательным запросом конечного пользователя, нацеленного на ресурс Message, а являться результатом каскадирования запроса, нацеленного на родительский ресурс ChatRoom.
И неудивительно, что нет единого верного ответа о том, как лучше поступить во всех этих сценариях. Но мы начнем с самого простого и разберемся, как должны реагировать на перемещение ресурсов связанные с ними другие ресурсы.
Ссылочная целостность
Во многих реляционных базах данных есть возможность настроить систему так, чтобы в случае изменения определенных строк эти изменения могли каскадироваться и обновлять другие строки в БД. Это очень ценная, хоть и ресурсозатратная возможность, которая позволяет избежать получения в БД эквивалента ошибки сегментации при попытке разыменовать ставший недействительным указатель. Когда дело доходит до перемещения ресурсов внутри API, в идеале нам нужно стремиться к такому же результату.
К сожалению, это одна из особых сложностей, которая возникает при использовании пользовательского метода Move. Дело в том, что нам необходимо отслеживать не только все ресурсы, ссылающиеся на перемещаемый, но также все его дочерние ресурсы и родительский, обеспечивая параллельное обновление и их тоже. Нетрудно представить, что это оказывается невероятно сложным и является одной из многих причин, по которым переименовывать или перемещать ресурсы не рекомендуется.
Например, следование этому руководству будет означать, что если мы соберемся переместить ресурс Move, на который ссылается MessageReviewReport, то нам также потребуется обновить и сам MessageReviewReport. Более того, в случае перемещения ресурса ChatRoom, являющегося родителем этого Message с MessageReviewReport, нам бы пришлось проделать то же самое, потому что Message, будучи потомком ChatRoom, переместился бы вслед за ним.
Далее мы кратко разберем обработку связанных ресурсов в случае пользовательского метода Copy.
Дублирование связанных ресурсов
Перемещение определенно порождает немало проблем в отношении связанных ресурсов, но будет ли это верно и в случае копирования? Оказывается, здесь тоже не обходится без проблем, но в данном случае они носят иной характер. Вместо сложной технической проблемы перед нами встает непростое решение в плане дизайна. И причина тут в том, что необходимость копировать связанный ресурс вместе с целевым определяется обстоятельствами.
Например, наличие ресурса MessageReviewReport определенно важно, но при дублировании ресурса Message в точности дублировать отчет нам не нужно. Пожалуй, будет разумнее позволить MessageReviewReport ссылаться не на один ресурс Message, что позволит вместо копирования отчета просто добавить скопированный ресурс Message в его ссылочный список.
Другие ресурсы просто не должны дублироваться. Например, при копировании ресурса ChatRoom никогда не нужно копировать ресурсы User, перечисленные как его участники. В общем, суть в том, что если копирование одних ресурсов вместе с целевым будет иметь смысл, то копирование других — нет. Эта техническая задача уже куда более простая и во многом будет зависеть от предполагаемого поведения API.
Теперь, разобравшись с подробностями сохранения ссылочной целостности при работе с новыми пользовательскими методами, мы перейдем к рассмотрению случаев, в которых речь идет о ссылках, выходящих из-под нашего контроля.
Внешние ссылки
Несмотря на то что большинство ссылок на ресурсы API будут находиться внутри других ресурсов того же API, так будет не всегда. Возможно немало сценариев, в которых на ресурсы будут указывать ссылки из разных мест интернета, в частности при сохранении файлов или прочих неструктурированных данных. Это представляет довольно очевидную проблему, учитывая, что вся текущая глава посвящена перемещению ресурсов и повсеместному нарушению таких внешних ссылок. Допустим, у нас есть хранилище, отслеживающее файлы. Эти ресурсы File могут быть доступны по всему интернету, что подразумевает огромное количество ссылок (листинг 17.5). Что тут можно сделать?

Важно помнить, что интернет не является идеальным представлением ссылочной целостности. Мы зачастую сталкиваемся с ошибками 404 Not Found, поэтому будет не совсем честным просто взять внутренние требования API к ссылочной целостности и расширить их на всю мировую сеть. Очень редко при раскрытии ресурса для внешнего мира мы действительно готовы гарантировать пожизненное предоставление этого ресурса в неизменном виде. Как правило, ресурс предоставляется до тех пор, пока это имеет смысл. Суть в том, что раскрытые для интернета ресурсы зачастую предоставляются по мере возможностей и редко с пожизненной гарантией.
В этом случае наш ресурс File лучше будет отнести к аналогичному набору принципов и предоставлять до того момента, пока его не потребуется переместить. Это может случиться завтра ввиду срочного запроса от Департамента юстиции США или же в следующем году из-за неоправданного повышения стоимости хранения файла. Дело в том, что нам нужно изначально осознавать некритичность ссылочной целостности в API и фокусироваться на более насущных задачах.
17.3.4. Внешние данные
До сих пор все ресурсы, которые мы копировали/перемещали, являлись такими, которые предполагается хранить в реляционной базе данных или в плоскости управления. А как быть со сценариями, когда мы хотим скопировать/переместить ресурс, указывающий на сырой блок байтов, как в нашем ресурсе File из листинга 17.5? Нужно ли также копировать эти байты в хранилище?
Эта проблема хорошо изучена в области информатики и всплывает во многих языках программирования в виде выбора между копированием переменных по значению или по ссылке. Когда переменная копируется по значению, все внутренние данные дублируются и скопированный экземпляр оказывается полностью отделенным от исходного. В случае же копирования по ссылке внутренние данные остаются на прежнем месте и создается новая переменная, указывающая на эти исходные данные. В таком случае изменение данных одной переменной влечет за собой обновление и другой.
В листинге 17.6 показан пример псевдокода, который делает две копии (одну по значению, другую по ссылке) и затем обновляет получающиеся данные. Итоговые значения показаны на рис. 17.1. Как видите, несмотря на наличие трех переменных, у нас всего два списка, а изменения в переменной copy_by_reference также видимы в исходном списке.

При перемещении ресурсов, указывающих на подобные внешние данные, ответ будет прост: оставить внутренние данные как есть. То есть несмотря на то что мы можем переместить саму запись ресурса, данные должны оставаться нетронутыми. Например, переименование ресурса File должно вызвать изменение адреса этого ресурса, но внутренние байты перемещаться никуда не должны.
В случае копирования ресурсов ответ очевиден, но более сложен. Как правило, лучшим решением для этого типа внешних данных будет начать с копирования только по ссылке. После этого, если в будущем данные изменятся, нужно будет скопировать все внутренние данные и применить изменения, поскольку копирование всех байтов, когда достаточно скопировать ссылку, может оказаться излишним. Тем не менее здесь мы не получим отображения изменений скопированного ресурса в исходный, поэтому в случае обновления необходимо делать полную копию.
Эта стратегия, называемая копирование при записи, довольно распространена в системах хранения данных, и многие из них внутренне будут выполнять всю основную работу за вас. Иными словами, вы можете обойтись вызовом функции copy(), которая должным образом обработает всю семантику для создания полноценной копии значения только при дальнейшем изменении данных.
17.3.5. Наследуемые метаданные
Во многих API есть набор политик, или метаданных, которые дочерние ресурсы наследуют от родительского. Представим сценарий, в котором хотим контролировать длину сообщений в разных комнатах чата. Этот лимит длины для разных комнат может различаться, значит, он будет атрибутом ресурса ChatRoom, в конечном итоге применяемым к дочерним ресурсам Message (листинг 17.7).

Все это хорошо, но возникает путаница, когда ресурсы Message копируются из одного ресурса ChatRoom в другой. Наиболее распространенная проблема может возникнуть, когда эти разные наследованные ограничения начинают конфликтовать. Например, если Message, отвечающее требованиям своего текущего ресурса ChatRoom, копируется в другой ресурс ChatRoom, чьим требованиям уже не соответствует. Иными словами, что происходит, если мы хотим скопировать ресурс Message, содержащий 140 символов, в ChatRoom, где допускаются сообщения длиной лишь в 100 символов?
Один из вариантов — просто разрешить ресурсам нарушать правила и существовать внутри ChatRoom, несмотря на выход за установленные им рамки. И хотя технически это сработает, попутно возникнут другие сложности, поскольку стандартные методы Update в этом ресурсе будут давать сбой до тех пор, пока ресурс не впишется в правила своего родителя. Зачастую это может делать целевой ресурс, по сути, неизменяемым, внося путаницу и вызывая негодование у тех, кто заинтересован в корректировке прочих аспектов этого ресурса без изменения длины его содержимого.
Еще один вариант — обрезать или иным образом изменять входящий ресурс, чтобы он подчинялся правилам целевого родителя. И хотя технически это приемлемо, такое поведение может оказаться неожиданным для пользователей, которые не знают о требованиях целевого ресурса. В частности, в подобных случаях безвозвратного уничтожения данных такое решение с «принудительным вписыванием в требования» нарушает практические рекомендации избегать подобных решений является их необратимый характер.
Более разумным вариантом будет просто отвергать входящие ресурсы и отменять операции копирования/перемещения ввиду нарушения установленных правил. Это даст пользователям возможность решать, какие действия предпринять, чтобы операция была успешной: менять ограничение длины, указанное в ресурсе ChatRoom, либо обрезать/удалять ресурсы Message, нарушающие это ограничение, перед копированием/перемещением данных.
Это касается и случаев, когда копирование активируется ввиду того, что ресурс является потомком ресурса, связанного с тем, над которым проводится операция. В подобных сценариях любой сбой проверки или проблема, вызванная наследуемыми от целевого родителя метаданными, должны приводить к провалу всей операции, четко обозначая причину неудачи. Тогда у пользователя будет возможность изучить результаты и решить, отменить поставленную задачу или же повторить операцию после того, как обозначенная проблема будет исправлена.
17.3.6. Атомарность
На протяжении главы мы неоднократно убедились, что методы Copy и Move могут быть намного более сложными и ресурсозатратными, чем кажутся. Если в некоторых случаях они оказываются довольно безобидными (например, копирование ресурса без связанных или дочерних ресурсов), то в других могут подразумевать копирование и обновление сотен и даже тысяч других ресурсов в API. Это создает довольно серьезную проблему, поскольку в подобных ситуациях редко бывает так, чтобы операции копирования/перемещения происходили при отсутствии других пользователей API, изменяющих внутренние ресурсы. Как же обеспечить, чтобы эти операции завершались успешно при всей волатильности набора данных? Более того, если в ходе выполнения возникает ошибка, важно иметь возможность отменить работу, проделанную к этому моменту. Если коротко, то нам нужно обеспечить, чтобы и операция Move, и операция Copy происходили в контексте транзакции.
Интересно здесь то, что на уровне слоя хранения данных операции копирования и перемещения работают по-разному. При копировании мы в основном совершаем запросы для считывания данных, после чего создаем в хранилище на основе этих записей новые записи. В случае же перемещения мы в основном обновляем существующие записи в хранилище, изменяем идентификаторы для перемещения ресурсов с одного места в другое и обновляем существующие ресурсы, которые могут ссылаться на только что измененные. И хотя идеальное решение в обоих случаях одно, проблемы, возникающие в процессе, несколько различаются, в результате чего разумнее будет решать эти сценарии по-разному.
Копирование
Когда мы говорим об атомарности операции копирования ресурса (а также его дочерних и связанных ресурсов), то подразумеваем согласованность данных. То есть нам нужно обеспечить точное соответствие итоговых данных в новом месте исходным, существовавшим на момент начала операции, состояние которых может быть зафиксировано так называемым моментальным снимком. Если ваш API построен на основе хранилища, поддерживающего моментальные снимки или подобные транзакции, то эта задача значительно упрощается. При считывании данных можно просто указать временную метку снимка или идентификатор ревизии, после чего уже копировать эти данные в новое расположение или выполнять всю операцию внутри одной транзакции базы данных. Тогда, даже если к тому времени что-то изменится, это не вызовет никаких проблем.
Если же вам такая роскошь недоступна, есть два других варианта. Во-первых, можно просто признать, что это невозможно, и любые копируемые данные будут представлять их слепок за некий отрезок времени, а не последовательный одномоментный снимок. Это определенно неудобно и потенциально может запутывать, особенно в случае изменчивых наборов данных. Тем не менее это может оказаться единственным доступным вариантом, если учесть технологические ограничения и требования к времени работы.
Во-вторых, можно заблокировать данные для записи либо на уровне API (отключив все вызовы API, изменяющие данные), либо на уровне БД (запретив все обновления данных). И хотя такое решение не всегда окажется действенным, это своеобразный жесткий метод, который обеспечит согласованность во время операций, поскольку гарантирует сохранение данных ровно в том виде, в каком они были на момент копирования. Делается это как раз за счет блокировки и запрета изменений на время операции.
Как правило, такой вариант не рекомендуется, поскольку он, по сути, раскрывает простой способ для атаки сервиса API, при котором достаточно отправлять множество операций копирования. В итоге, если ваша система хранения не поддерживает моментальные снимки или транзакционную семантику, это станет еще одной причиной отказаться от поддержки копирования ресурсов в API.
Перемещение
В отличие от копирования, перемещение данных намного больше зависит от обновления ресурсов, в связи с чем перед нами возникают другие задачи. На первый взгляд может показаться, что у нас нет серьезных трудностей, но по факту получается, что согласованность данных все еще остается проблемой. Чтобы понять почему, представьте, что у нас есть MessageReviewReport, указывающий на только что перемещенное Message. В этом случае нужно обновить MessageReviewReport, чтобы он указывал на новое расположение ресурса Message. Но что, если кто-то тем временем изменил MessageReviewReport и теперь он указывает на другое сообщение? Обычно нам нужно быть уверенными, что связанные ресурсы не менялись с того момента, как мы решили, нужно ли их изменить, перенаправив на перемещенный ресурс.
Для этого у нас есть способ, аналогичный случаю с операцией копирования. Первым и лучшим вариантом здесь будет использовать последовательный снимок или транзакцию БД, чтобы гарантировать выполнение работы относительно согласованного представления данных. Если так сделать не получается, то можно заблокировать базу данных или API для записи, обеспечив согласованность данных на время операции перемещения. Как уже говорилось, это опасная тактика, но иногда она может стать необходимым злом.
Наконец, можно просто проигнорировать проблему и уповать на лучшее. В отличие от операции копирования, игнорирование проблемы при перемещении приведет к намного худшим последствиям, чем просто размазывание данных по времени. Если мы не попытаемся получить последовательное представление данных во время перемещения, то можем столкнуться с риском отмены изменений, внесенных предыдущими обновлениями. Например, если MessageReviewReport отмечен как требующий обновления ввиду перемещения и кто-то тем временем изменит цель этого ресурса, то очень вероятно, что операция перемещения перезапишет это обновление, как если бы оно и не происходило. И хотя такой вариант может не вызвать катастрофы в каждом API, он определенно окажется неудачной практикой и его следует по возможности избегать.
17.3.7. Итоговое определение API
Как мы видели, само определение API далеко не такое сложное, как его поведение, особенно когда дело доходит до обработки наследуемых метаданных, дочерних и связанных ресурсов, а также прочих аспектов, относящихся к ссылочной целостности. Пора обобщить все рассмотренное на данный момент. В листинге 17.8 приводится заключительное определение API, который допускает копирование ресурсов ChatRoom (с поддержкой пользовательских идентификаторов) и перемещение ресурсов Message между родителями.
Листинг 17.8. Итоговое определение API
abstract class ChatRoomApi {
@post("/{id=chatRooms/*}:copy")
CopyChatRoom(req: CopyChatRoomRequest): ChatRoom;
@post("/{id=chatRooms/*/messages/*}:move")
MoveMessage(req: MoveMessageRequest): Message;
}
interface ChatRoom {
id: string;
title: string;
// ...
}
interface Message {
id: string;
content: string;
// ...
}
interface CopyChatRoomRequest {
id: string;
destinationParent: string;
}
interface MoveMessage {
id: string;
destinationId: string;
}17.4. Компромиссы
Надеюсь, после того как вы увидели всю сложность поддержки операций копирования и перемещения, у вас возникнет устойчивое желание избегать их везде, где это возможно. И хотя поначалу они кажутся простыми, выясняется, что правильная реализация поведенческих требований и ограничений может оказаться исключительно сложной. К тому же все ухудшается возможными печальными последствиями, приводящими к потере или повреждению данных.
Тем не менее копирование и перемещение различаются как по сложности реализации, так и по своей значимости в API. Во многих случаях копирование ресурсов может являться критическим элементом функциональности. Перемещение же, наоборот, зачастую оказывается необходимым только в результате ошибки или неудачного расположения ресурсов. В итоге, несмотря на то, что поддержка метода Copy может оказаться весьма полезной даже для очень хороших API, при желании реализовать метод Move сначала желательно еще раз переоценить расположение ресурсов. Зачастую оказывается, что необходимость перемещать ресурсы между родителями (или переименовывать их) вызвана неудачным выбором идентификаторов ресурсов или использованием связи «родитель — потомок» там, где должна быть ссылочная связь.
Наконец, важно отметить: несмотря на то что реализация операций копирования и перемещения может быть затруднительной, путь наименьшего сопротивления в данном случае с гораздо большей вероятностью приведет к печальным последствиям в будущем.
17.5. Упражнения
1. Должны ли при копировании ресурса копироваться и все его дочерние ресурсы? Касается ли это ресурсов, ссылающихся на него?
2. Как сохранить ссылочную целостность за пределами нашего API? Должны ли мы ее гарантировать?
3. Как в процессе копирования/перемещения данных сделать так, чтобы итоговые данные оказались истинной копией, а не размазанными по времени данными ввиду их параллельного изменения другими пользователями API?
4. Представьте, что перемещаете ресурс от одного родителя к другому, но у них установлены разные политики безопасности и контроля доступа. Какая из этих политик должна применяться к перемещаемому ресурсу: старая или новая?
Резюме
- Как бы нам ни хотелось потребовать постоянства ресурсов, очень вероятно, что пользователям понадобится копировать или перемещать ресурсы в API.
- Вместо того чтобы реализовывать копирование/перемещение с помощью стандартных методов (Create и Update), для этого следует применять пользовательские методы Copy и Move.
- Операции копирования и перемещения также должны включать выполнение той же операции для дочерних ресурсов. Тем не менее это поведение необходимо рассматривать индивидуально, а ссылки на перемещаемые ресурсы поддерживать в актуальном виде.
- Когда ресурсы обращаются к внешним данным, методы API должны прояснять, является ли дублируемый ресурс копией по ссылке или по значению (либо копируется при записи).
- Пользовательские методы Copy и Move должны быть максимально атомарными, если учитывать ограничения внутренней системы хранения.
Об авторе
Джей Джей Гивакс трудится инженером ПО в Google, специализируясь на платежных системах, облачной инфраструктуре и проектировании API. Он также является автором книги Google Cloud Platform in Action и сооснователем AIP.dev, запущенного в Google общеотраслевого ресурса, который посвящен сотрудничеству в сфере разработки стандартов построения API. Живет в Сингапуре со своей женой Ка-эль и сыном Лукой.
Более подробно с книгой можно ознакомиться на сайте издательства:
» Оглавление
» Отрывок
По факту оплаты бумажной версии книги на e-mail высылается электронная книга.
Для Хаброжителей скидка 25% по купону — API