
В этой статье я хотел бы рассказать как решил создать свой первый проект.
В течении пары лет я с переменным успехом в свободном режиме изучал японский язык и постоянно пытался применять подход с погружением в языковую среду. Так я, к примеру, добавил японский в раскладки клавиатуры, смотрел простые видео и подкасты, пытался читать легкие тексты.
Но японский язык (также как и китайский и, частично, корейский) имеет довольно высокий входной барьер для чтения, потому что нужно не только выучить два алфавита, но и запомнить как минимум несколько сотен кандзи (300-500).
Постоянная проблема с переключением от контента на вкладку словаря, чтобы найти один неизвестный или забытый кандзи, тратила время и сильно сбивала настрой. При этом поиск по кандзи в таких словарях обычно идет по радикалам или количеству строк, так что иногда найти какую то мелочь там реально долго.
Я обнаружил несколько крутых ресурсов, скажем Yomichan, который распознает текст под курсором мыши и предоставляют перевод и аннотацию из подгруженный словарей.
К сожалению, ни один из бесплатных вариантов не использовал OCR, чтобы можно было проверить любую картинку, панель манги или субтитры на остановленном видео, прямо из той же вкладки. Поэтому я решил попробовать создать нечто подобное :)
ScanLingua (имя, кстати, предложено chatGPT).
Я выбрал формат chrome extension и попытался применить то, что усвоил на нескольких курсах JS и React, и попробовал разные подходы, так что оно не сильно последовательное, но этот проект в том числе и для портфолио, в общем демонстрируем все что можем.
Структура проекта
Расширение состоит из двух основных частей: servise_worker and content_script, которые являются отдельными React приложениями.
servise_worker отвечает за manifest, fetch запросы и рендер основного popup расширения, а content_script рулит тем что происходит внутри активного таба (overlay и его логика, popup с результатами).
При этом content_script собран одним файлом в servise_worker/public.
Приложения обмениваются необходимыми данными через chrome messaging API с уникальными ID:
// content_script
async function requestTranslation () {
const requestId = getRandomInt(100000)
const response = await chrome.runtime.sendMessage({type: "request-translation", requestId});
const res = await new Promise((resolve, reject) => {
requests.set(requestId, resolve)
setTimeout(reject, 60*1000) //60sec
})
return res
}
// service_worker
chrome.runtime.onMessage.addListener(gotMessage)
async function gotMessage(request, sendResponse) {
if (request.type == "request-translation") {
const rawTranslation = await translateZone(visionText)
const translation = await unEscape(rawTranslation)
await sendTranslation(request.requestId, translation)
}
}
async function sendTranslation(requestId, translation) {
const [tab] = await chrome.tabs.query({active: true, lastFocusedWindow: true});
const response = await chrome.tabs.sendMessage(tab.id, {type: "your-translation", requestId, translation});
} Active tab overlay и canvas
Для реализации функционала по выделению части active tab, я начал с создания основного overlay div и пяти детей (top, bottom, right, left, zone).
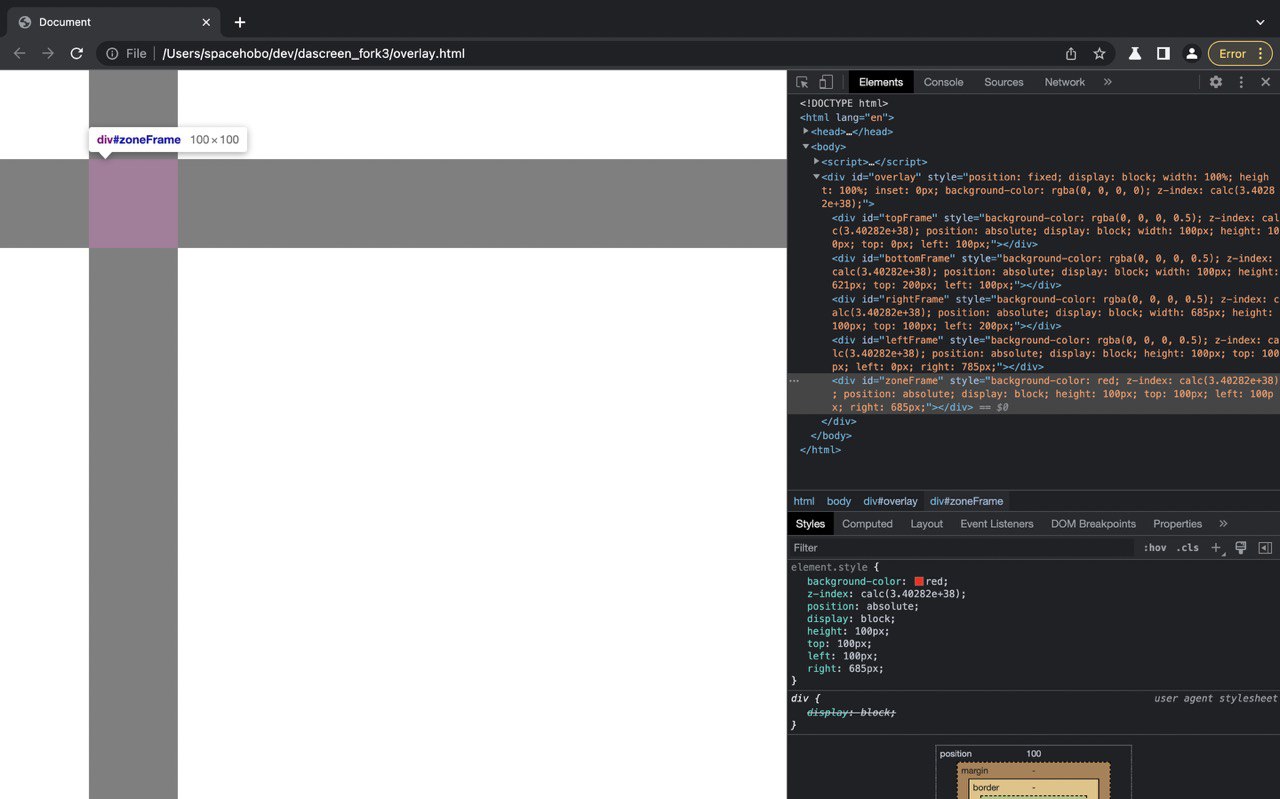
А затем передал им координаты mousedown и mousemove (x1, y1, x2, y2) чтобы зона менялась динамически. Чтобы кропнуть выделенную зону используется captureVisibleTab в котором затем рисуется OffscreenCanvas по имеющимися координатам.
Поначалу я просто сконвертировал полученные данные в base64 и опробовал OCR API, но результат выглядел так себе:

Зона убежала в сторону + добавился зум. И вот так я не сразу, но узнал о devicePixelRatio, а также то, что на моем ноутбуке он не 1, а 2. В целом хорошо что наткнулся на это рано, иначе просто вылезло бы позже. Добавил проверку и поправку на ratio и зона встала на место.
Стили
Основной проблемой со стилизацией была необходимость изолировать стиль всплывающего окна от стиля активного таба в который оно внедряется. В целом по выбор был между iFrame и ручным оверрайдом конфликтующих стилей.
Учитывая что всплывающее окно будет только с одной кнопкой и текстом, я решил обойтись оверрайдом + реализовал CSS-in-JS с помощью React Styled Components так как по требованиям к структуре расширения content_script должен быть собран в один .js файл.
Использованные API
Для OCR и перевода ScanLingua использует Google vision и translation API.
Эти API не бесплатные, но vision дает 1000 бесплатных запросов, а translation 500 000 бесплатных символов перевода в месяц, чего вполне достаточно для частного использования. Пользователю необходимо сгенерировать API ключ и посматривать за лимитами (ссылки на инструкцию по созданию ключа можно найти в репозитории, ссылки в расширении и на сайте проекта). Чтобы помочь пользователю отслеживать использование ключа на домашней вкладке расширения предусмотрен простой счетчик.
Для предоставления аннотации я использовал бесплатный открытый словарь Jotoba (Jotoba API бесплатное, поэтому его доступность не гарантируется)
Что дальше?
Расширять функционал (добавить аннотацию для китайского и корейского языков, настроить интеграцию с Anki), править логику и исправлять ошибки, UI.
Расширение еще сырое, но в целом уже юзабельное. Proof of concept release размещен в магазине:
Репозиторий:
Также накидал небольшой адаптивный product page проекта:
Буду рад отзывам и комментариям!
Комментарии (4)

developerxyz
20.04.2023 19:18+1Альтернативный путь решения - manga_ocr в фоне https://github.com/kha-white/manga-ocr
Скопировать скриншот в буфер обмена, затем в буфере обмена OCR-нутый японский текст. Вместе с yomichan и достаточно хорошим железом работает хорошо, потому что yomichan умеет захватывать текст из буфера
Для yomichan может быть полезно использовать одночзычные словари (но, видимо, не на самом раннем этапе), более подробно про подход написано на https://learnjapanese.moe
SpaceHobo Автор
20.04.2023 19:18К manga_ocr тоже присматриваюсь, вопрос выбора настройки для пользователя. Хотелось бы коробку, а здесь уже вложения в железо. Его бы через WebGPU, но пока рано, да и скилы пока только нарабатываю.

janvarev
20.04.2023 19:18Есть довольно-таки прекрасная Елочка или Маверик для переводов (поддерживают внутренний OCR + переводчики)
Под Маверик я даже адаптер писал для встраивания перевода манги в свою графическую программу.
UPD: Если нужен локальный (а не клауд) сервис для OCR + распознавание + перевод - можете попробовать мой FastAPI сервис для Маверика.
KseniaVor
Классно! Вы молодец, я тоже изучала Японский язык.