

Всем привет. Меня зовут Путилин Дмитрий (Добрый Кот) Telegram.
От коллектива FR-Solutions : Продолжаем серию статей о K8S.
В этой статье расскажем об архитектурных концептах развертывания kubernetes кластеров.
Затронем как легаси методы, так и новые практики, такие как cluster-api и k8s in k8s.
В прошлой статье рассказывали о том, как собирается кластер без использования генераторов конфигов типа kubeadm.
2014 Да будет КУБ
В начале был куб, суровый и первобытный.
Изначально первые кубы были похожи на уже существующие инсталляции, однако главным отличием было - потребность развертывания их вручном режиме.
Все последующие примеры имеют одинаковый набор компонентов при первоначальной установке - 5 бинарных элементов (api, scheduler, controller, proxy, etcd), после чего требуется создать сертификаты, настроить конфигурационные файлы с сервисами, выполнить настройку sysctl и modprobe, и запустить службу с помощью команды systemctl start.
Сам процесс установки выглядит довольно простым, однако в то время, когда мало людей знало о k8s, это было вызовом.
2015 Kubespray
В конце 2015 года, каждый пытался написать свой собственный инструмент автоматизации для этой рутинной задачи на Ansible или Puppet. Однако в 2015 году, группа единомышленников выпустила первый релиз инструмента kubespray. Он был основан на ansible и был настолько успешен, что до сегодняшнего дня люди продолжают использовать его.
Идея была максимально простой - перевести легаси процесс в форму Ansible кода и максимально автоматизировать его. Проект развивался быстро и принес важные нововведения, включая:
Переход на static pods
Возможность развертывания и обновления аддонов с помощью единого инструмента.
Возможность обновления сертификатов с помощью ansible-playbook play.yaml.
Появилась возможность использования комбинации Terraform и Kubespray, которая позволяет заказать управляемые узлы в облаке и настроить их с помощью единого флоу.
2016 Kubeadm
Также одновременно с Kubespray началась разработка инструмента под названием Kubeadm, который был ориентирован на унификацию и простоту, не давая возможности выходить за рамки заложенных ограничений, но при этом предоставляя достаточную гибкость для развертывания необходимой инсталляции.
По моему субъективному мнению, данный инструмент стал популярен только примерно 3-4 года назад и только начал набирать свою аудиторию.
Некоторые функции, которые делают Kubeadm привлекательным для пользователей, включают:
Простота установки и настройки кластера Kubernetes
Унифицированный подход к установке Kubernetes на различные ОС и платформы
Поддержка различных сетевых плагинов
Автоматическое обнаружение сетевых интерфейсов
Возможность настройки контроллеров планировщика и узлов данных в соответствии с требованиями пользователя
Легкое добавление и удаление узлов кластера
Использование кубернетес-совместимых сетевых плагинов, таких как Calico, Weave и Flannel, для управления сетевыми настройками кластера.
Эти функции делают Kubeadm удобным и гибким инструментом для установки и управления кластерами Kubernetes.
Минусом данного инструмента является то, что для его использования необходима предварительная настройка узла:
Первоначальная конфигурация sysctl и modprobe.
Сервис kubelet с настройками.
Необходимо загрузить исполняемые файлы kubeadm и kubelet.
Создание базового конфигурационного файла для kubeadm.
2018 Cluster-API
Концепция данного инструмента еще только набирает обороты, о ней расскажем подробнее.
Cluster-API является инструментом для автоматического создания, управления и масштабирования Kubernetes кластеров, основанных на инфраструктуре облачных провайдеров. Он был разработан с целью обеспечения единого и унифицированного подхода к управлению Kubernetes кластерами на разных облачных провайдерах.
Cluster-API был ориентирован на облачную инфраструктуру с самого начала, и первые провайдеры были разработаны для AWS и GCP. Однако с течением времени были добавлены и другие провайдеры, такие как VMware vSphere, OpenStack и Azure.
Основная идея Cluster-API заключается в том, чтобы взять идеи из Terraform и Kubeadm и переосмыслить их в новом контексте. Cluster-API позволяет создавать и управлять кластерами с помощью простых K8S примитивов. Он также предоставляет унифицированный интерфейс для работы с различными провайдерами, что делает его более гибким и удобным для использования в различных сценариях.
В этой статье была рассмотрена история создания кластера с использованием Terraform, что представляет первый уровень K8S IN K8S. Главная идея статьи заключается в том, что для создания кластера необходимо использовать несколько ресурсов через Terraform. Некоторые из этих ресурсов уже есть в базовом наборе Kubernetes, а другие требуют создания через CRD + Operator.
* Обратите внимание что я специально пишу Operator а не Cluster-API т.к данный подход можно реализовать любым удобным вам способом умея писать операторы.
Terraform vs Operator
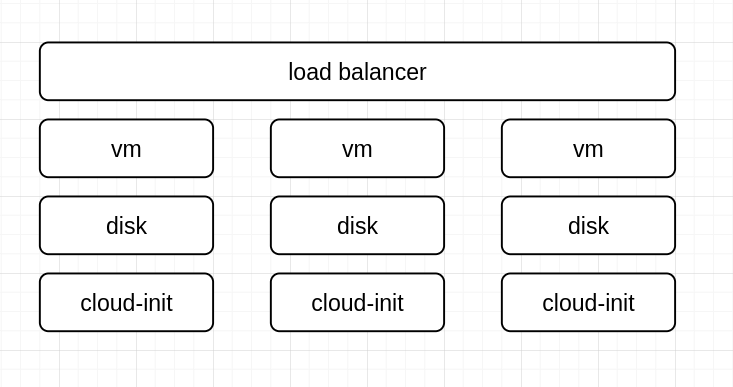
Конечные ресурсы, которые нас интересуют, выглядят следующим образом, и теперь мы можем представить их в виде K8S ресурсов:
Load Balancer это resource Service Type LoadBalancer
-
VM это CRD который будет описывать:
MachineClass (Базовый шаблон машины)
MechineSet (логически как ReplicaSet)
MachineDeployment (Логически как Deployment)
Machine (логически как POD)
Cloud INIT можно также представить в виде кастомного ресурса и модифицировать его на основе дополнительных аргументов, которые обычно указываются в базовом конфигурационном файле kubeadm.
Поскольку для работы Cluster-API требуется уже существующий кластер, мы используем любой удобный для нас способ создания первичного кластера. (Первый уровень)
Далее мы добавляем базовую функциональность, необходимую для кластера, созданного с помощью подхода Cluster-API. (Пример приведен для Yandex Cloud)
* Чистым Cluster-API показать не сможем т.к нет на данный момент провайдера для Yandex Cloud, в котором обычно разрабатываем.
Сетевой плагин Cilium
Yandex Cloud Controller (для создания service type LB и организации нативной маршрутизации)
Yandex CSI Controller (для создания внешних дисков под etcd)
Yandex Machine Controller (для создания виртуальных машин)
Machine Config Operator (для настройки узлов DAY2) *В разработке
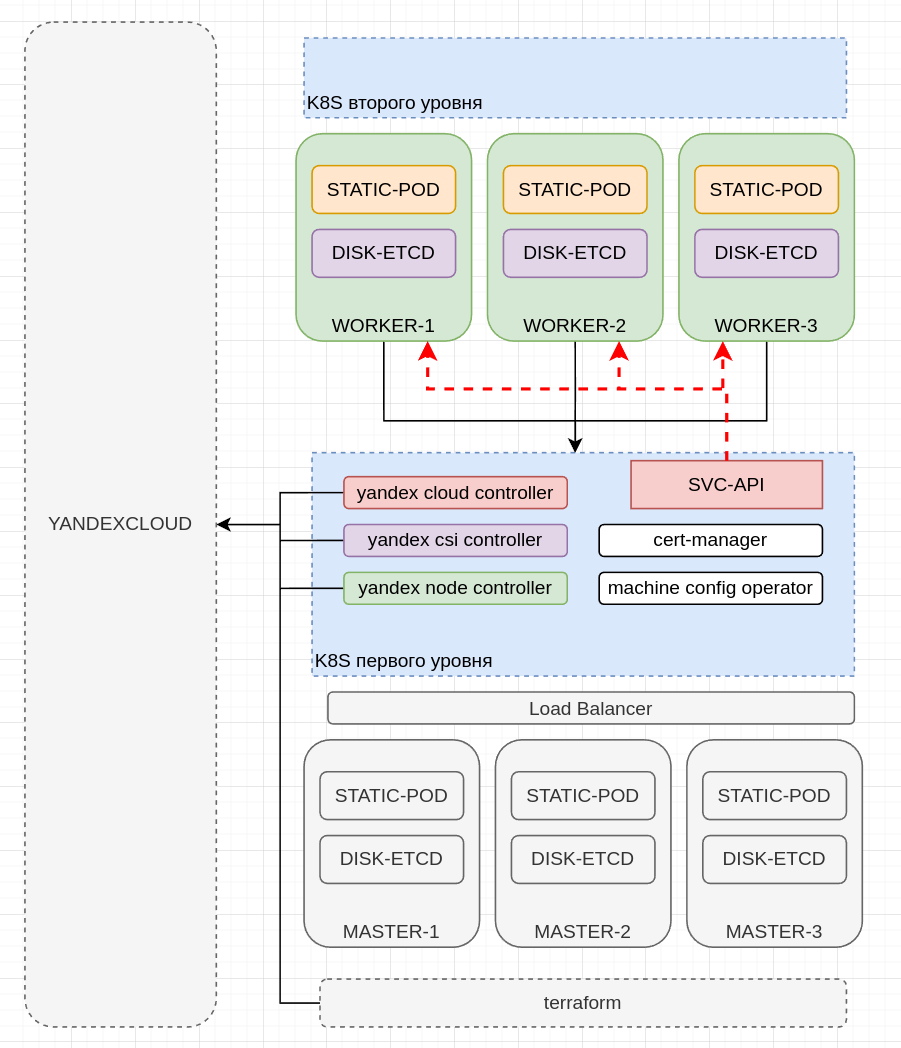
Как можно заметить из приведенной выше схемы, ресурсы, созданные через Terraform, и ресурсы, созданные Cluster API подходом, не имеют различий. Все инструменты запрашивают одинаковые ресурсы и работают с API таким же образом. Единственное отличие заключается в унификации подхода.
Мы можем использовать одни и те же ресурсы для развертывания кластеров в любом облаке, используя единый подход, и нам нужно только добавлять специальные провайдеры (операторы), которые будут имплементировать конфигурацию для каждого облака.
Основные возможности, которые предоставляет подход Cluster-API, включают в себя:
Автоматизированное развертывание кластеров Kubernetes с использованием декларативных описаний в виде YAML-файлов.
Унификация процесса создания кластеров на различных облачных провайдерах и физических серверах с помощью общих API и универсальных ресурсов.
Возможность масштабирования и управления кластерами Kubernetes с помощью операторов, которые предоставляют дополнительную функциональность для работы с кластерами, такую как автоматическое масштабирование, бэкапы, мониторинг и т.д.
Централизованный контроль над кластерами и их конфигурацией, что позволяет легко управлять множеством кластеров в различных средах.
Возможность интеграции с другими инструментами и сервисами, GitOps и CI/CD пайплайны, что обеспечивает еще большую автоматизацию и упрощение управления кластерами Kubernetes.
Функциональность Cluster-API значительно расширилась благодаря ряду умных решений и хитростей, которые позволили ему выйти вперед в развитии.
Благодаря тому, что оператор добавляет все созданные узлы в легаси-кластер в качестве воркеров, мы можем использовать привилегии IAM от Kubernetes. Ранее нам приходилось передавать конфигурационные файлы и сертификаты для статических подов через инструменты Day2, такие как Ansible и Puppet. Теперь мы можем указывать ConfigMap и Secret в спецификации пода, откуда нужно извлечь конфигурацию. Это позволяет установить Cert-Manager в Kubernetes и выдавать сертификаты для кластера через него, поддерживая их в актуальном состоянии.
Для тех, кто беспокоится о том, что кластер первого уровня может упасть и доступ к секретам и конфигурационным картам будет потерян, всегда есть возможность примонтировать файлы на файловую систему хоста и хранить их там. Это позволяет сохранить доступ к этой информации, даже если кластер Kubernetes первого уровня перестанет функционировать.
*В нашем случае в клиентской инфраструктуре мы создаем только один кластер через терраформ, т.к нужен первичный кластер с которого начнется вся история.
Минусы решения:
Cluster-API подход не лишен недостатков. Один из главных минусов - это стоимость и привязка кластеров к выделенным воркерам, т.к для создания каждого кластера выделяется отдельная пачка узлов под control plane. В данном случае потребуется хорошо настроенный вертикальный автоскейлинг, что бы поспевать за увеличением нагрузки на control plane. Но в любом случае на больших масштабах будете замечать, что утилизация мастер узлов под CP утилизируется недостаточно, а ресурсы при этом резервируются в приличном кол-ве, что увеличивает ценник инфраструктуры
2017 Kubernetes in Kubernetes
Один из первых удачных примеров использования концепции Kubernetes in Kubernetes был представлен в конце 2016 года или в начале 2017 года в рамках проекта Tanzu от компании VMware. Также существовали стенды от сообщества CoreOS.
Многие люди до сегодняшнего дня смотрят с опаской на концепцию Kubernetes in Kubernetes, так как не понимают, как эта технология работает и как ее использовать.
На портале Habr в 2021 году уже были опубликованы статьи, посвященные данной тематике, которые демонстрируют, как быстро и легко можно развернуть кластер Kubernetes всего за 30 секунд. Заострять внимание на технических деталях не буду, укажу только суть. Ксли будет интересно прочитайте статью выше.
Отличие от Cluster API минимально, разница только в том, что на воркер через cloud ini мы не помещаем статик поды, а размещаем всю нагрузку в отдельных неймспейсах в виде деплойментов. Все остальное мы разворачиваем как обычное приложение в Kubernetes.
В Kubernetes кластере второго уровня мы создали деплойменты компонентов Kubernetes в подовой подсети и создали адрес для внешнего доступа и управления кластером через сервис типа LB.
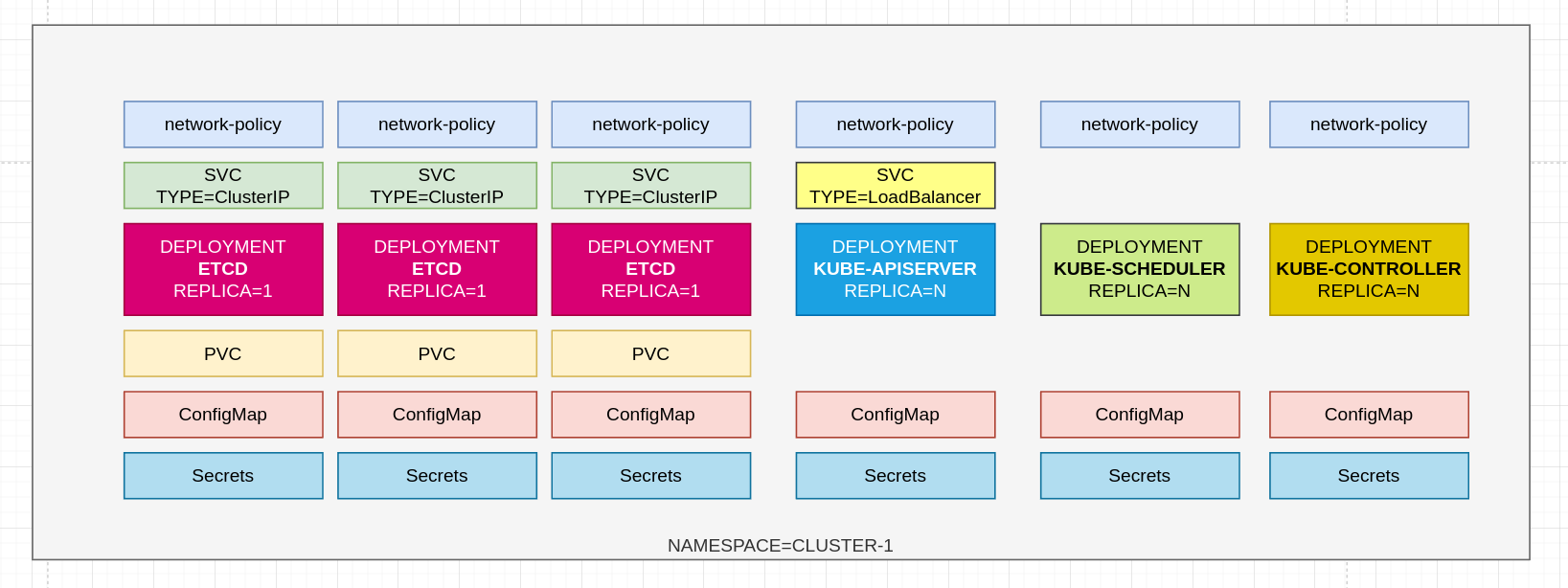
Выше представлена схема организации компонентов в неймспейсе. Стоит уточнить, что для деплоя etcd можно использовать два варианта: StatefulSet (STS) и Deployment. STS имеет существенный минус, который заключается в том, что при падении ноды реплика не переезжает без пенделя т.к он привязывается к конкретной ноде и не может удостовериться, что приклад на ноде со статусом NotReady не работает. В свою очередь, у Deployment есть другая проблема - он гибко переезжает на другие узлы при падении ноды, но не имеет возможности гибко управлять выделенными DNS-записями и привязками PV к конкретным подам. Все же, можно использовать некоторые ухищрения и реализовать функционал STS через Deployments.
*Проблему STS можно решить данным инструменом.
Чтобы реализовать функционал StatefulSet через Deployments, мы создаем три отдельных Deployments с одной репликой каждый, затем связываем их с соответствующими сервисами, которые имеют статические имена. Далее, создаем три Persistent Volume (PV) и связываем их с каждым из Deployments и наконец, мы устанавливаем стратегию обновления в "recreate".
Данная конфигурация, показала отличные результаты в плане отказоустойчивости и масштабируемости. При таком подходе вы можете управлять профилем нагрузки на узлах через афинити, селокторы и т.п и гибко масштабировать кластер, не привязываясь к конкретным нодам. Это позволяет более гибко управлять нагрузкой и оптимизировать ее
распределение.
Минусы решения:
Недоступность API кластера уровня ниже приводит к недоступности функционала восстановления подов.
Вывод
История про три уровня K8S in K8S это история про баланс ценника скорости и отказоустойчивости.
Как и для каждого отказоустойчивого решения необходимо учитывать множество факторов, таких как наличие кластера с несколькими центрами обработки данных, равный объем ресурсов для каждого ДЦ, чтобы уменьшить влияние отказа ДЦ на работу системы в
целом, и многое другое. Поэтому перед тем, как приступить к созданию подобного решения, необходимо тщательно обдумать все нюансы и принять необходимые меры для инимизации возможных рисков.
Для дев окружения K8S третьего уровня прекрасное решение, поднял поработал удалил или потушил.
Для опорных кластеров инфраструктуры мы используем кластера 2-го уровня.
Контакты
Благодарим вас за прочтение статьи до конца, надеемся, что она оказалась для вас полезной. Мы будем рады, если вы подключитесь к нашему телеграм-каналу и зададите нам вопросы.
telegram community: https://t.me/fraima_ru
telegram me: https://t.me/Dobry_kot
Altaev
«завернули рыбу в рыбу, чтобы Рыба в рыбе Рыба; Повествование: рЫба, Р-ба, робА,РЫБА; Вывод: мяч!» Неплохой материал, вычитывайте его, пожалуйста!