

Когда-то давно идея хранить данные в виде таблиц не была мейнстримом. Вспомним, как ей удалось за короткое время отодвинуть все прочие концепции на второй план.
Начало
То, что мы называем сейчас базами данных, появилось практически вместе с компьютерами. И тогда же начались поиски наиболее рациональных способов работы с данными. Первая идея, которая была опробована, заключалась в том, чтобы упорядочить данные в виде иерархической структуры. Я заметил, что люди вообще любят иерархию. Кроме того, такой способ хранения соответствует нашему чувственному опыту. Вот у нас есть шкафчик, в шкафчике полка, на полке ящик, в ящике папка и т.д. Так появились иерархические базы данных. Они и сейчас с нами. Откройте проводник в Windows и вы увидите нечто подобное. Кроме того, у IBM например, есть современная база данных (для краткости я буду пользоваться этим словосочетанием вместо более длинного «система управления базами данных») DB2 или IBM DB2. Но есть, и поныне здравствует, также база данных под номером 1, IBM DB1. Она еще называется IBM IMS (Information Management System). И это классическая иерархическая база данных.
Концептуально систему хранения данных в иерархической базе можно было бы представить так:
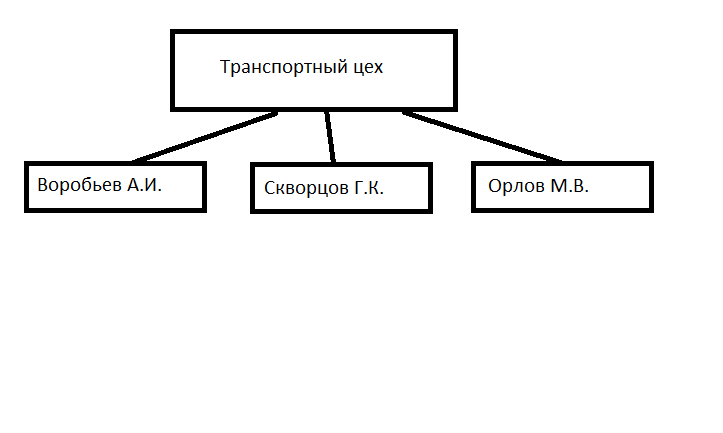
Что интересно, если принять во внимание техническую реализацию, то схема примет немного другой вид:
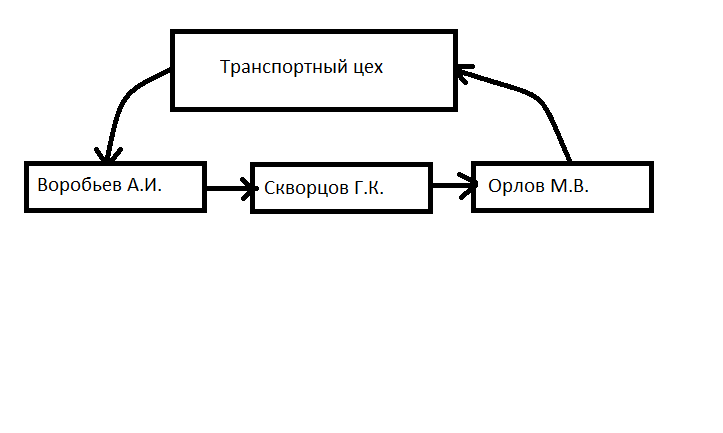
Элемент данных "Транспортный цех" имеет ссылку типа "потомок" на элемент данных "Воробьев А.И." Элемент данных "Воробьев А.И." имеет ссылку типа "брат" на элемент данных "Скворцов Г.К." Элемент данных "Скворцов Г.К." ссылку такого же типа на элемент данных "Орлов М.В.". Наконец, элемент данных "Орлов М.В." ссылается на "предка", элемент данных "Транспортный цех".
Соответственно, для иерархической модели могут быть определены операции:
перейти от предка к первому потомку
перейти к следующему потомку
перейти от потомка к предку
У иерархической модели достаточно быстро обнаружился недостаток. Только что мы рассмотрели иерархию Подразделение - Сотрудники. Но у нас может обнаружиться потребность и в другой иерархии. Например, такой:
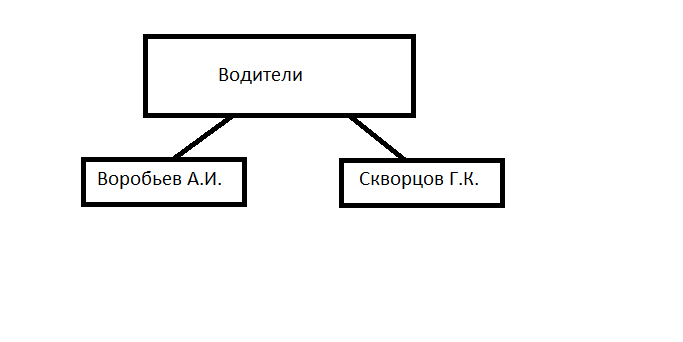
Можно, конечно, хранить обе иерархии в одной базе. Но тогда, как видно из примера, нам в частности придется хранить дубли элементов данных "Воробьев А.И" и "Скворцов Г.К." Это и сейчас считается крайне нежелательным, а в те времена, когда боролись за каждый байт памяти, и подавно.
И тогда была придумана модель, расширяющая иерархическую. Она получила название сетевой. Идея тут довольно проста. Надо только разрешить элементу данных иметь не одну связь, а несколько.
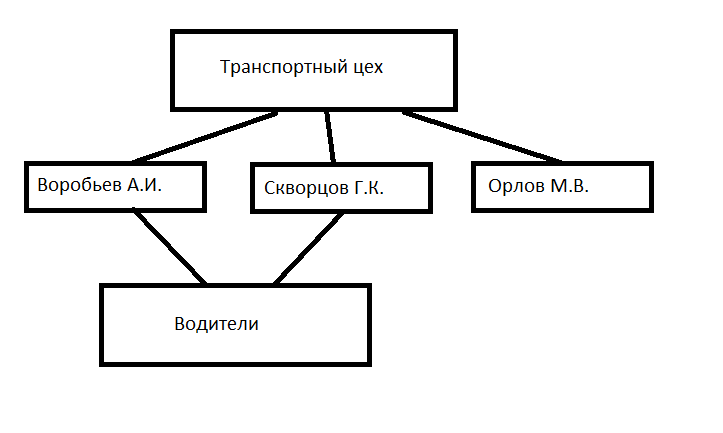
Такая организация данных уже отдаляется от чувственного опыта. В самом деле, в физическом мире не может одно и то же одновременно лежать в двух и более местах. Зато сетевая модель позволяла строить сколь угодно сложные схемы хранения данных. И для своего времени это был прорыв. В рамках созданной незадолго до этого организации CODASYL энтузиасты приготовились развивать эту прекрасную концепцию.
Поединок
Но тут пришли другие ребята и стали объяснять, что все это не правильно. А правильно хранить данные вот так, в таблицах:
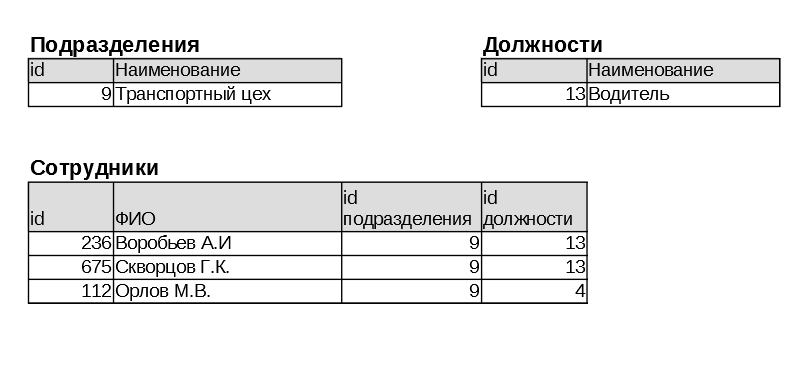
Сейчас такой способ хранения данных считается чем-то само собой разумеющимся. Но тогда это воспринималось как какой-то изврат. И где здесь, простите, черточки, т.е. связи. Что здесь к чему относится сразу и не поймешь. И, главное, зачем это нужно, если мы уже придумали совершенную модель?
Сторонники реляционной модели, а она называлась именно так, говорили, что вы там со своими переходами от предка к потомкам и обратно вынуждены на каждый чих "крутить циклы", читай программировать. А мы тут придумали язык запросов, который позволит всем и каждому вкусить прелести владения технологией баз данных. Даже непрограммистам, и в первую очередь им. Надо сказать, тут они немного промахнулись. Некоторое время спустя выяснилось, что язык запросов SQL слишком сложен для непрограммистов. Инструментом для обычных людей он не стал. Зато на долгие годы стал обязательным элементом в арсенале чуть ли не любого программиста.
Спор тем временем разгорался и дело дошло до "драки". Было решено "автоматизировать ларек". Я не шучу. Стороны договорились, что каждая представит на всеобщее обозрение свой вариант базы данных для управления небольшим магазином.
"Реляционщики" справились довольно быстро, хотя и со второй итерации. "Сетевики" долго скрипели и пыхтели, наконец выдали что-то гораздо более сложное. Так в итоге оно еще и не работало. Сторонники сетевой модели были посрамлены, и с этих пор начался закат сетевой модели и торжество реляционной.
Эпизод яркий, но разумеется дело было не в том, что кто-то кого-то победил. Появление реляционной модели совпало с определенным переломным моментом. Вначале стоимость рабочего времени компьютеров была чудовищной. По сравнению с ней, стоимость работы программиста была пренебрежимо малой величиной. Сколько там люди будут корпеть над программой, не важно. Важно, чтобы она памяти поменьше занимала и крутилась быстрее. Но развитие компьютерной техники не стояло на месте. Зарплаты программистов, кстати, тоже. К моменту появления реляционной модели ситуация полностью перевернулась. Теперь уже час работы программиста оказался многократно дороже, чем час работы компьютера. И сторонники реляционной модели с их амбицией довести управление базой данных до уровня обычного человека оказались весьма кстати. Пусть им и не удалось в полной мере воплотить свои мечты, но все-таки созданные ими модель данных и язык запросов позволили в разы сократить время разработки. Это и послужило причиной триумфа реляционных баз данных.
Заключение
С тех пор прошло примерно полвека, но реляционные базы данных вместе с языком SQL и поныне с нами. И, похоже, что останутся с нами если не навсегда, то еще как минимум на полвека. Связано это с тем, что идея создать язык управления базами данных доступный непрограммистам, в наше время неожиданно обрела второе дыхание. Но это тема отдельного разговора.
В конце статьи хочу порекомендовать вам бесплатный вебинар на котором эксперты OTUS покажут как настроить доступ между базами через расширение postgres_fdw и логическую репликацию.
Комментарии (13)

netricks
25.04.2023 11:57-9Здесь могла бы быть реклама mongodb. Но мне лениво её писать. Считайте, что здесь был вдохновляющий пост о том, почему лист и словарь — это хорошо и лиспого, а sql и реляционные базы — флуктуация вероятности в божественном замысле

klimkinMD
25.04.2023 11:57-1"Жаль... Жаль, что нам так и не удалось послушать начальника транспортного цеха."
К сожалению, -- опять, сплошная реклама!
Учитывая то, что иерархические СУБД поддерживали тип данных в узле "массив структур" (т. е. реализовать реляционную структуру не проблема) история про соревнование двух команд -- маркетинговый ход.
Выскажу мнение: на заре эры персональных компьютеров реализовать для них РСУБД оказалось значительно легче (особенности хранения, "простота" модели...) и количество специалистов и кода для персональных компьютеров выросло лавинообразно. ЛЕГАСИ, вот что стало причиной и, возможно, снижение уровня специалистов (энтузиастов, на начальном этапе).


unreal_undead2
25.04.2023 11:57Инструментом для обычных людей он не стал. Зато на долгие годы стал обязательным элементом в арсенале чуть ли не любого программиста.
Скорее появилась отдельная профессия - "дата-инженер".

Myclass
25.04.2023 11:57У меня такое ощущение, что вы в историю с соревнованием скомковали лет 20. Сетевые базы данных повились в 50-годах, в 60-х в среде COBOL создались концепты баз данных в виде схем. А в начале 1970-х появились реляционные модели данных, благодаря работам Эдгара Кодда. Кодд ввёл в оборот термин OLAP и написал 12 законов аналитической обработки данных. В его честь названа одна из нормальных форм 1NF. И только в начале 80-х реляционная модель начала входить в моду.
Т.е. вы как-бы литературно в один исторический момент поместили и динозавров и людей. Литературно - можно. Потому чо такие истории всегда возникают на стыке новых технологий, когда создатель новой технологии "доказывает" право на существование и дальнейшее финансирование в его "бэби".
Но вот что бросается в глаза в вашем тексте, так это отсутствие какого-нибудь обьяснения сетевых баз данных. Ведь из двух рисунков ну вообще не понять в чём сложность обслуживания таких систем, и какое упрощение в этом в реляционых базах?
PS. Также интересно, что все создатели как сетевых, схемных, так и реляционных баз данных получили премию Тьюринга.
skymal4ik
Как-то очень коротко и ни слова про nosql, json, колоночные бд…
Кстати, узнал бы поподробнее про спор и магазин, где можно почитать?
exwill Автор
Спор упоминается в википедии
https://ru.wikipedia.org/wiki/Сетевая_модель_данных
Детальный разбор есть в статье Кодда 1975 года
https://dl.acm.org/doi/10.1145/800297.811529