
Статья написана в рамках моего личного блога о тестировании и QA: https://t.me/qanva_blog
При изучении техники тест‑дизайна «доменный анализ», я столкнулся с тем, что многие авторы описывают ее по‑своему, что вполне логично. Перелопатить много разных статей об одном и том же, чтобы найти подходящее изложение материала и в конце концов понять желаемое — естественный процесс обучения. Но в случае доменного анализа, я заметил расхождение: кто‑то описывает данную технику сложно, а кто‑то ограничивается простой позицией — «это просто работа с классами эквивалентности и граничными значениями».
Определение доменного анализа
У данной техники тест‑дизайна много названий: «доменный анализ», «анализ классов эквивалентности», «доменное тестирование», «анализ эквивалентного разбиения», «тестирование областей определения», «domain analysis».
Это, чтобы вы не растерялись на собесе =)
Прежде, чем штудировать источники информации, давайте посмотрим, что можно вытащить из различных определений понятия «Доменный анализ»:
Доменный анализ — методика разработки тестов, относящаяся к методу черного ящика, использующаяся для определения действенных и эффективных тестовых сценариев в случаях, когда множественные параметры могут или должны быть протестированы одновременно. — ISTQB
Доменный анализ — техника, которая основана на разбиении диапазона возможных значений переменной (или переменных) на поддиапазоны (или, иначе, домены), с последующим выбором одного или нескольких значений из каждого домена для тестирования. — из статьи Антона Алексеева «Кто такие тест‑дизайнеры и зачем они нужны»
Доменный анализ — это техника, которая может применяться для определения эффективных и действенных тест‑кейсов, когда несколько переменных могут или должны тестироваться вместе — Ли Копланд «A Practitioner's Guide to Software Test Design«
Доменный анализ — техника создания эффективных и результативных тест‑кейсов в случае, когда несколько переменных могут или должны быть протестированы одновременно. — Святослав Куликов «Тестирование программного обеспечения»
Для себя я вынес следующее:
данная техника позволяет сократить кол‑во тестов, не теряя при этом в эффективности тестового покрытия;
так как, некоторые переменные могут и должны тестироваться вместе, то следует проанализировать зависимости между этими переменными, пахнет комбинаторикой и попарным тестированием;
чтобы объединить множество значений, необходимо выделить определенную область, называемую доменом;
так, как из подобласти значений мы выбираем только определенных представителей, то тут пахнет классами эквивалентности и граничными значениями.
Сформулировать свое полное определение попытаемся в конце =)
Что такое “домен”?
В большинстве источников игнорируют это понятие и сразу идут в бой с примерами использования техники. Для меня это было проблемно, так как ни сразу понятно, что конкретно нужно объединять в область значений и где здесь сам «домен».
Для примера возьмем сайт создания блокнота по описанию пользователя. На нем есть такая форма:

Домен, в данном случае, это сама форма с ее полями, так как поля формы относятся к одной части функционала и объеденины общей логикой. Мы не будем тестировать каждое поле по отдельности, а заполнив каждое отдельное поле подобранным, определенным образом, значением, нажмем кнопку «Создать блокнот«.
То есть «домен» — это логически связанные между собой шаги/переменные/объекты, в рамках одного функционала: форма авторизации, форма регистрации, оформление заказа в интернет магазине, заполнение данных о пользователе, конвертирование различных форматов файла на разных ОС, окно редактирования изображения, отдельная зона игровой локации, инвентарь персонажа, окно крафта конкретной вещи из инвентаря персонажа и т. д.
Хочу заметить, так понятие «домен» понимаю лично я. И в данной статье буду опираться на него.
Но, что интересно: как правило, в других источниках «доменом» называют конкретный параметр. Например, в форме авторизации, поле ввода логина мы можем ввести определенный текст. В данном случае текст(строка) — домен. Далее, строку логически делят на поддомены: латиница, кириллица, символьная строка, длинная строка, короткая строка..все это классы эквивалентности. И далее выбирают определенных представителей из диапазона эквивалентности, а также граничные значения.
Мне кажется что «домен» это про объединение параметров общей логикой и про множественность параметров, а не про отдельные параметры.
Моя логика следующая: логически объединяем набор параметров ( домен ) > каждый параметр( поддомен) разбиваем на классы эквивалентности > выбираем представителей из каждого класса эквивалентности:

Алгоритм использования техники
Для успешного использования техники, в разных источниках, в совокупности прослеживаются следующие шаги:
Выбор домена.
Анализ входных параметров (поддомены).
Разбиение входных параметров на классы эквивалентности.
Выбор представителей классов эквивалентности и граничных значений для каждого поддомена.
Анализ взаимосвязанных параметров и объединение их с помощью комбинаторики/попарного тестирования.
Создание тестов на основе полученных данных о входных значениях.
Анализ выходных параметров.
Разбиение выходных параметров на классы эквивалентности.
Выбор представителей классов эквивалентности и граничных значений для выходных параметров.
Определение входных параметров для проверки представителей выходных значений.
Дополнение тестов на основе полученных данных о выходных значениях.
Объединение тестов.
Анализ входных параметров
Как мы можем заметить, мы постоянно анализируем наши параметры и пытаемся найти связи их друг другом, какие-то ограничения и риски.
Выделяем входные параметры:
Поле ФИО:
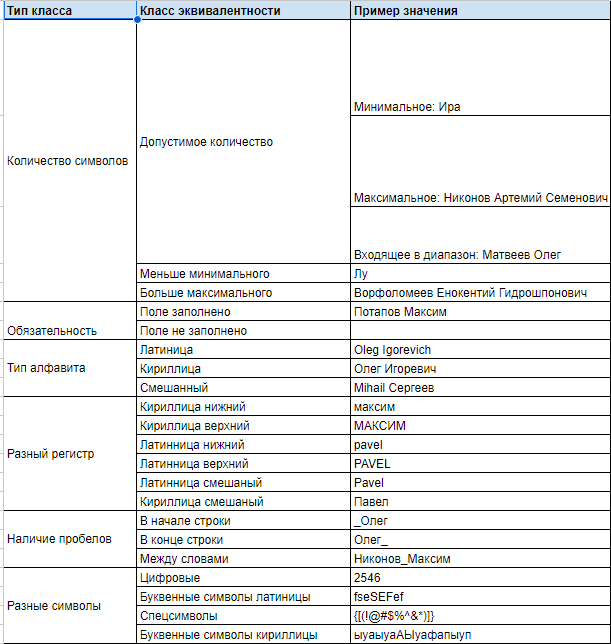
Количество символов <= 25 и >=3 (если введены данные)
Необязательно к заполнению, если заполнено поле Описание
Принимает на вход латинские буквы и буквы кириллицы
Не принимает на вход символы и числа, кроме пробела “_”
Пробел нельзя ставить в начале строки и в конце строки
Поле Описание:
Количество символов <=120, если формат = А5
Количество символов <=200, если формат = А4
Количество символов >=3 (если введены данные)
Необязательно к заполнению
Принимает на вход латинские буквы и буквы кириллицы
Не принимает на вход символы, кроме пробела “_”, запятой “,”, восклицательного знака “!”, точки “.”, дефиса “-”
Принимает на вход числа, если они стоят не в начале и не в конце строки
Поле Количество страниц:
Значение количества страниц >=250 и <=1000
Значение должно быть целым числом
Поле принимает только числовое значение
Если формат выбран А4 , то значение <=500
Количество символов для ввода >=3 и <=4
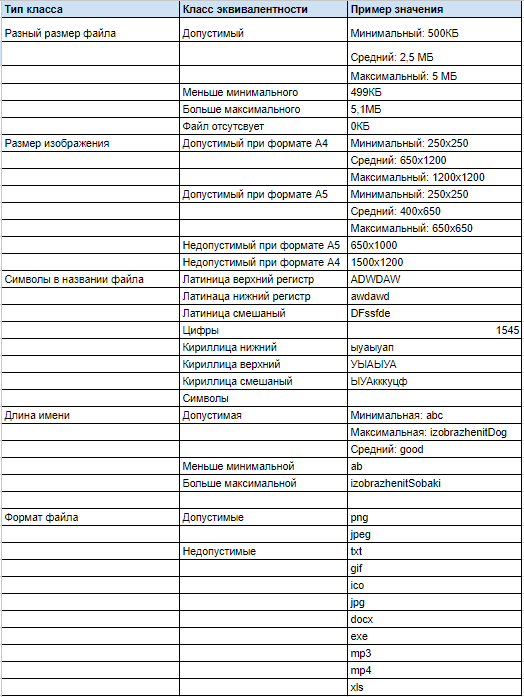
Загрузить изображение:
Доступные форматы файла .png , .jpeg
Размер файла от 500КБ до 5МБ
Минимальный размер изображения >= 250x250px
Если формат А5, то размер изображения <=650x650px
Если формат А4, то размер изображения <=1200х1200px
Имя файла не должно содержать символы и буквы кириллицы
Длина имени файла <=15 и >=3 символов
Имя файла содержит латинские буквы и цифры
Необязательное поле
Применение уже знакомых техник тест дизайна
Итак, поддомен для нас это совокупность всех возможных значений переменной. Перед нами стоит задача выделить подобласти для каждого параметра, все элементы которых предположительно приводят к одинаковому результату выполнения программы для сокращения количества тестов. Как минимум мы можем разбить на две подобласти — валидные и невалидные значения.
Эту задачу как раз прекрасно решает техника разбиения на классы эквивалентности.
Если диапазон значений упорядочен, то выделяем внутренние интервалы и точки перехода: слева от диапазона и справа от диапазона — невалидные значения, сам диапазон — валидные значения.
Если диапазон значений не упорядочен, то выполнить разбиение согласно логике, согласно рискам, согласно частоте использования значений. Например, буквы можно разбить на латиницу и кириллицу, а их в свою очередь дробить на верхний регистр и нижний регистр.
Также необходимо убедиться, что границы области заданы верно, в чем нам поможет анализ граничных значений.
Но данную технику не всегда можно применить, так как существуют упорядоченные и неупорядоченные классы эквивалентности, и в неупорядоченных нет способа выделить граничные значения, которые с большей вероятности могут привести к возникновению сбоя. В таком случае можно попробовать разбить неупорядоченный класс эквивалентности на подклассы и взять по значению из каждого. Например, множество символов с клавиатуры: класс эквивалентности — символы с клавиатуры, подклассы: числовые символы, специальные символы на разных раскладках, буквенные символы на разных раскладках, сочетания двух клавиш, сочетания трех клавиш.
При использовании граничных значений, важно помнить, что данная техника не ограничивается числовыми границами диапазонов. Также существуют:
Временные границы: ограничение на выбор даты в прошлом, ограничение на выбор даты в будущем, таймеры и т.д.
Технические границы: ограничение оперативной памяти, ограничение физической памяти на жестком диске, ограничения на типы данных для ввода, ограничение на загрузку некоторых форматов файлов, ограничения на размеры изображений и т.д.
Границы итераций: ограничение на ввод пароля, ограничение на повторное использование части функционала и т.д.
Границы окружения: ограничение на использование символов в именах файлов на разных ОС.
и т.д.
Также важно выделение особых точек:
значения на которые программа не реагирует;
наиболее часто встречающиеся;
специфичные значения, которые определяются предметной областью;
0 и null;
дефолтные значения / значения по умолчанию.
В этом поможет спецификация и коллеги, которые лучше разбираются в продукте — аналитики, разработчики, да и просто другие тестировщики, дольше вас работающие на проекте.
Проанализировав входные параметры, мы получили следующие данные:
Значения входных данных для поля ФИО - ссылка на таблицу
Значения входных данных для поля Описание - ссылка на таблицу
Значения входных данных для поля Количество страниц - ссылка на таблицу
Значения входных данных для поля Загрузка изображения - ссылка на таблицу
{kind=link}
{kind=link}
{kind=link}

Объединение тестов
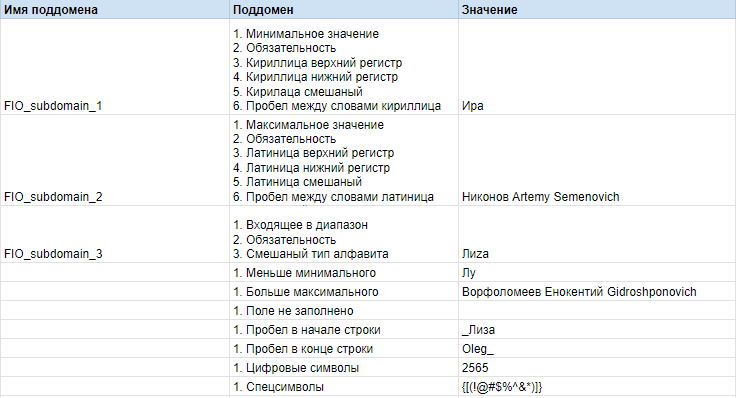
Не будем забывать, что суть доменного анализа не только в выборе показательных значений параметров, но и в одновременной проверке множества позитивных условий одновременно. Таким образом из набора позитивных значений различных классов эквивалентностей формируем поддомены:
Описание поддомена для поля ФИО - ссылка на таблицу
Описание поддомена для поля Описание - ссылка на таблицу
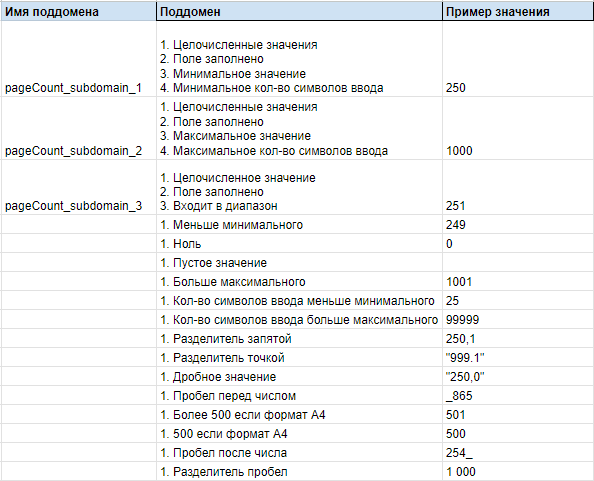
Описание поддомена для поля Количество страниц - ссылка на таблицу
Описание поддомена для поля файла изображения - ссылка на таблицу
{kind=link}
{kind=link}
{kind=link}

Имена поддоменов заданы для удобства их использования в будущем.
Суть доменного тестирования в объединении множества позитивных независимых значений для более эффективного выбора тестовых значений и построения меньшего количества тестов, не теряя при этом в тестовом покрытии. Именно поэтому мы объединяли позитивные значения параметров одного поддомена в одно тестовое значение.
Значения считаются независимыми, если значение одного класса эквивалентности не влияет на диапазон валидных значений другого класса эквивалентности.
Но следует понимать, что такое объединение увеличивает время локализации ошибки, при обнаружении бага.
В таком случае, поможет алгоритм похожий на бинарный поиск:
Поделить упавшее значение на 2
Если оба значения не проходят, то каждое нужно ещё раз поделить на 2
Если в одном значении ошибка пропала, то оставшиеся делим на 4
Тем не менее даже с этим алгоритмом, не стоит комбинировать более восьми значений или параметров.
Теперь, по тому же принципу, мы можем объединить позитивные независимые значения разных поддоменов в один позитивный тест, и так для всех представителей всех поддоменов — ссылка на таблицу
Значение поддомена считается независимым, если оно не влияет на диапазон валидных значений другого поддомена.

В получившейся таблице намерено скрыты негативные тесты, которые объединять мы не имеем право, так как это приводит к непониманию какое именно негативное значение привело к ошибке. Негативные проверки удобнее будет выписать отдельно.
Для меня удобнее выписать получившиеся тесты в отдельную таблицу да да еще одна таблица горизонтально — начало таблицы и конец таблицы.
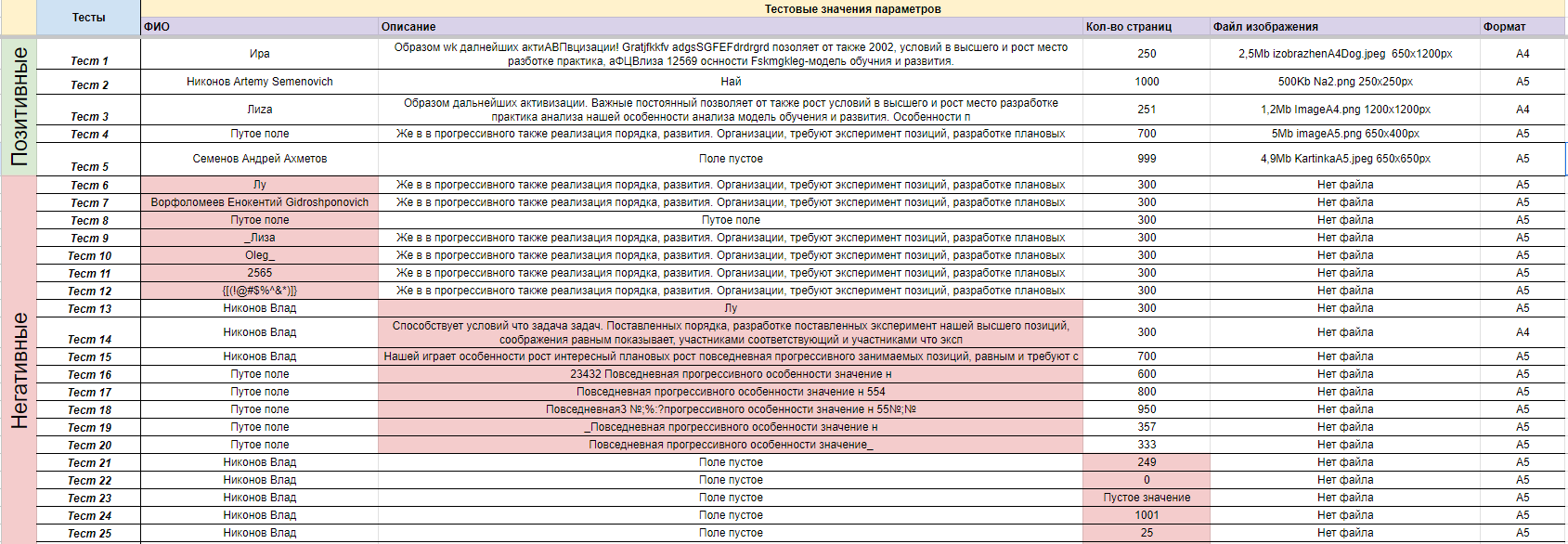{kind=link}
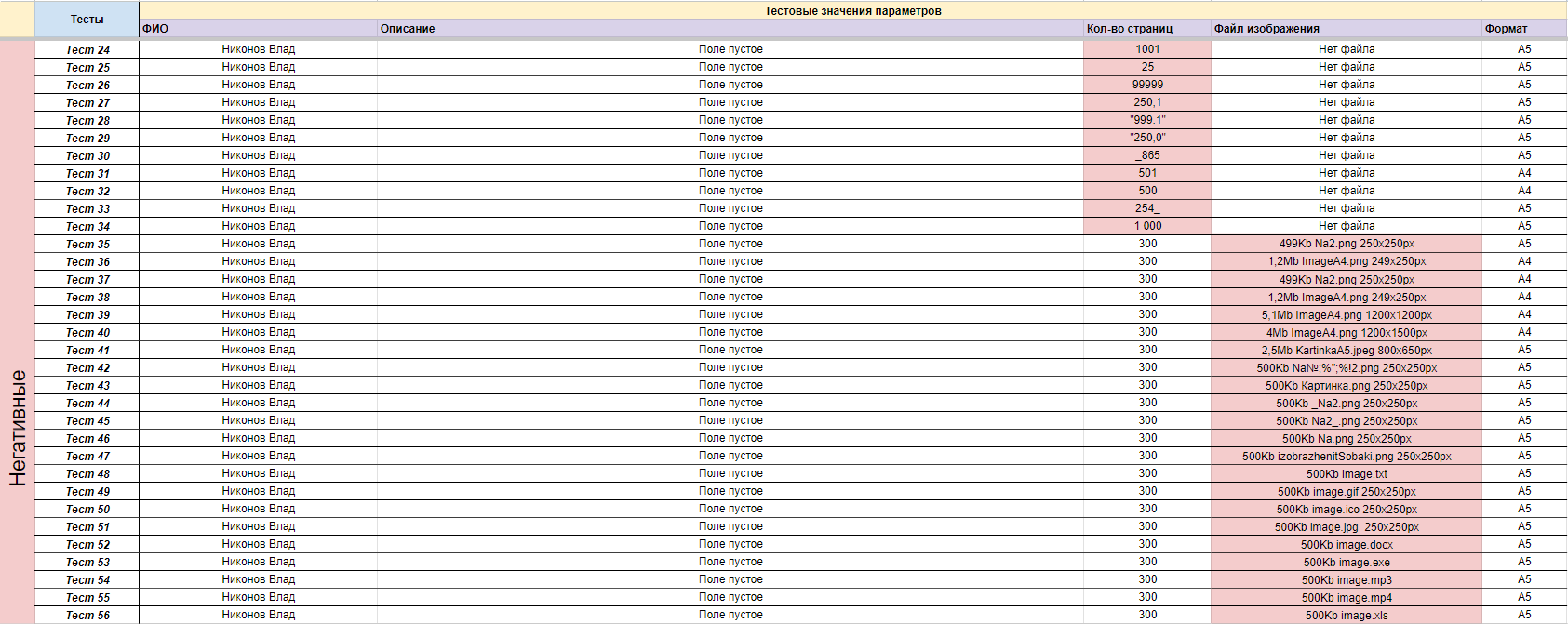{kind=link}

В итоге, мы пришли к 5 позитивным тестам и 51 негативному. На данном примере мы наблюдаем сокращение количества проверяемых значений без потери эффективности тестирования.
Анализ выходных параметров
В используемом мной примере, я намерено опускаю анализ выходных параметров. После заполнения необходимых полей, просто жмем на кнопку «Создать блокнот» и представим, что нас перебрасывает на страничку с надписью «Прекрасный блокнот получился! Наш менеджер с вами свяжется!». Анализировать тут особо нечего.
Тем не менее это важный этап, на котором вы сможете найти тестовые входящие значения для различных выходных данных.
Сами выходные данные мы никак не вводим и не можем повлиять на них напрямую, но зато мы можем повлиять на них путем различных комбинаций значений входных данных.
Часто приводят следующий пример — есть программа сложения двух целых чисел:

Если начать анализировать какие значения может принимать выходной параметр, то на ум приходит следующее:
0 + 0 = 0 - минимальный результат равен нулю;
1 + 1 = 2 - результат может быть длиной один символ;
1 + 10 = 11 - результат может быть длиной два символа;
99 + 99 = 208 - максимальный результат может быть равен 208 и максимальная длина результата 3 символа;
Результат не может быть отрицательным числом, так как поля ввода не принимают отрицательные целые числа.
Можно дальше развивать мысль, но давайте просто выделим:
класс эквивалентности “Допустимые значения выходного параметра” - [0, 208]
класс эквивалентности “Допустимая длина результата” - 1, 2, 3
Выделим представителей: 0 , 1, 99, 208
Эти представители будут ожидаемым результатом в тесте и чтобы его добиться, на вход мы выбираем следующие тестовые значения входных данных:

А далее мы уже смотрим, входят ли эти значения в выбранные при анализе входных данных или необходимо обновить. В данном примере мы ограничились рассуждениями о данных, но это не должно ограничивать вас в мышлении.
В нашем случае с формой создания блокнота, после клика на кнопку «Создать блокнот«, вполне могло всплывать модальное окно с расчитаной стоимостью собранного блокнота, где мы бы анализировали сумму в зависимости от выбранных значений. Или, к примеру, открывалась бы другая форма с динамическими полями, где в зависимости от выбранных нами значений, предлагались другие возможности кастомизации блокнота и мы бы анализировали зависимости и условия.
Важно было передать суть, а дальше вы уже сами.
Заключение
Доменное тестирование это не совсем отдельная техника тест‑дизайна, а комбинация различных техник: классы эквивалентности, граничные значения, комбинаторика и попарное тестирование (зависимости), тестирование на основе рисков, предугадывание ошибок, таблицы похожие на «таблицы принятия решений» и даже белый ящик (когда вы анализируете значения переменных).
Доменный анализ только формализует все перечисленные техники и результат применения будет тем эффективнее, чем лучше вы разбираетесь в тест‑дизайне и чем опытнее вы специалист.
Именно поэтому, в комментариях к различным статьям и видосам можно увидеть радостные и удивленные откровения людей по типу: «О, а я так и делаю! Не знал, что это называется доменный анализ!».
Ну и на последок, попробуем сформулировать определение своими словами:
Доменный анализ — это методика разработки тестов, позволяющая сократить тестовый набор без потери эффективности тестового покрытия, путем применения различных техник тест‑дизайна, направленных на сокращение данных, а также на анализ, систематизацию и обобщение входных и выходных параметров.
На всякий случай, вот вам ссылка не на скрины таблиц а на гугл таблицу.