
Сначала я хотел назвать эту заметку «Редактор связей? Это очень просто». Именно так называл свои прекрасные книжки Евгений Айсберг: «Радио? Это очень просто!», «Телевидение? Это очень просто!» Но поскольку я уже использовал эту шутку в статье о планировщике Windows, чтобы не повторяться, теперь использую любимую формулу многих журналистов: «Вся правда о…».
На самом деле никакую ужасную правду о редакторе связей раскрывать не требуется. Для программистов старшего поколения эта заметка вообще вряд ли будет интересна, поскольку в ней описываются банальные вещи. Но я, к сожалению, неоднократно сталкивался с самыми дикими представлениями о работе, например, компилятора или того же редактора связей у молодого поколения работников ИТ. И я их даже не обвиняю. На фоне чудовищного потока информации в современном программировании заставлять кого-то еще шарить по книгам и сайтам, чтобы разобраться, как именно работает утилита, внутрь которой они никогда не полезут – это даже не этично.
Другое дело я, который сопровождает и даже по мере сил развивает средства программирования. Приходится разбираться и с работой редактора связей, а, значит, как говорится, мне и карты в руки. Попробую кратко и на пальцах объяснить назначение и работу этого программного инструмента. И не просто объяснить, а привести примеры из конкретной реализации. Иначе абстрактные рассуждения плохо воспринимаются. Сам не люблю лекторов, которым кажется, что им достаточно поводить пальцем в воздухе, чтобы аудитория все поняла с полуслова. Так не бывает.
Итак, редактор связей, он же «линкер». Не могу принять бездумные англицизмы типа «линкер», «парсер». У нас хорошая собственная школа программирования развивается с 50-х. Поэтому не стыдно использовать и отечественные термины. Правда, название, устоявшееся в нашей литературе, «редактор связей» тоже не в полной мере отражает назначение этого инструмента. Что-нибудь вроде «достраиватель адресов» тем более не звучит. Поэтому пусть уж здесь будет старый, еще советский термин «редактор связей», чем безликий «сборщик» или «объединитель».
Думаю, основная цель этой утилиты большинству понятна и без дополнительных разъяснений: собрать из отдельных модулей единую выполняемую программу. Это практически неизбежный этап для всех компилируемых языков. Напомню, что сам термин «компиляция» пришел в программирование от литературных критиков и означал использование «чужого» (дословно «компилятор» - это «грабитель»), т.е. использование заранее готовых фрагментов. Поэтому даже простейшую программу типа «Hello world» приходится объединять с модулями из системной библиотеки, например, с модулем печати.
Однако, модули не просто «склеиваются» (это можно сделать даже стандартной командой «copy»), а специальным образом преобразуются. Основной объем таких преобразований занимает коррекция адресов в кодах будущей программы. Ведь когда компилятор обрабатывает очередной модуль, он же не знает, например, какими будут адреса вызовов нужных функций из других модулей. Даже еще хуже – он не знает, каким будет в программе адреса, например, текстовых констант в этом же модуле. И поэтому назначает им адреса относительно условного нуля для этого модуля. И только когда вся программа будет целиком собрана в памяти, только тогда станет ясно, какой реально окажется адрес у каждой текстовой константы. Но к этому моменту компилятор уже не работает и все это приходится определять и корректировать (т.е. «редактировать») уже редактору связей.
Таким образом, редактор связей составляет конечную единую программу по существу за два «прохода». Сначала он «примеряет» модули будущей программы в памяти и, дойдя до конца всего списка модулей, составляет собственную таблицу адресов всех объектов, которые попались ему в объединяемых модулях. Но не просто «примеряет», а еще сортирует: команды к командам, данные к данным, объединяя их в сегменты и секции. Чаще всего все команды слепляются в один сегмент с названием «CODE», а все данные - в один сегмент с названием «DATA». Внутри сегмента адресация сквозная. Но, например, каждая глобальная переменная может занимать отдельный сегмент со своим собственным именем. И даже, если в каждом модуле описана эта глобальная переменная, редактор связи создаст лишь один такой сегмент на всю программу. Затем сегменты объединяются в «секции» - это уже образы участков памяти при выполнении программы.
На втором проходе повторяются почти эти же действия, но поскольку все адреса теперь стали известны, можно проводить корректировку кодов и получать наконец готовые команды.
Собрать программу из модулей за один просмотр не получится, так как нужный адрес может встретиться только в конце последнего из списка модулей.
Исходными данными для редактора связей являются результаты работы компилятора в виде т.н. объектных модулей. Например, «мой» компилятор выдает результат в формате OMF (спецификация 121748). Этот формат появился, наверное, лет 50 назад. Вся информация в соответствии с этим форматом разбивается на «записи» длиной не более 1024 байт. Интересно, что каждая запись защищена контрольной суммой размером в байт. Я могу понять, когда пакет, передающийся по сети, защищен специальными кодами от возможных искажений при передаче, но здесь-то от кого защита? Может быть, это отголосок ненадежной памяти и дисков? С другой стороны, если вместо объектного модуля случайно подать в редактор связей бессмысленные нули и единицы, он тут же выдаст ошибку «неверная контрольная сумма такой-то записи». Получается дополнительная защита от ошибок.
Различных типов записей в OMF много, но главный объем составляют всего лишь два типа с аббревиатурами LEDATA (Logical Enumerated Data Record) и FIXUPP (Fixup Previous). Они так всегда и следуют парами друг за другом. Первая запись из каждой пары представляет собой «сыр с дырками». Это сгенерированные компилятором команды. Однако у части этих команд адресная часть осталась недостроенной. Вторая запись из каждой пары как раз и содержит указания, где в предыдущей записи расположены адресные «дырки» и как и каким адресом их следует закрыть.
Редактор связей читает из объектного файла очередную LEDATA и пишет ее в память (в образ будущей программы) обычно вплотную к предыдущей LEDATA. Затем читает соответствующий FIXUPP, расшифровывает его, достает требуемые значения (например, адреса указанных функций из другого модуля) и во всех указанных местах в LEDATA прибавляет эти значения к тем байтам, которые уже содержат указанные места. В результате адреса в кодах программы становятся «правильными».
Обычно к очередному адресу одновременно прибавляется еще и некоторое базовое значение, например, 400000h, учитывающее адрес загрузки в память всей будущей программы. Формально в FIXUPP кодируется не только какой адрес взять и куда его записать, но и как его учитывать: сложить только младшие байты с имеющимися в команде, только старшие байты, сложить сегмент и смещение и т.п. Сейчас все это не имеет смысла, поскольку используется только одна «сплошная» модель адресации памяти, но во времена MS DOS это было актуально.
Информация внутри FIXUPP очень компактна. Во-первых, для указания места внутри предыдущей LEDATA достаточно лишь 10 бит, поскольку длина записи не превышает килобайта. А, во-вторых, в начале объектного модуля записывается еще специальный отдельный FIXUPP, аналог макрорасширения. Он указывает номер варианта обработки адреса. Поскольку некоторые варианты встречаются чаще всего, далее во всех остальных FIXUPP вместо полного варианта настройки становится возможным указывать только номер этого варианта.
Для лучшего понимания я продемонстрирую это на простейшем примере. Помните, в статье о константах-«матрешках» я искал вложенные друг в друга текстовые строки? Возьмем тот же самый пример.
test:proc main;
put('!Hello world!','Hello world');
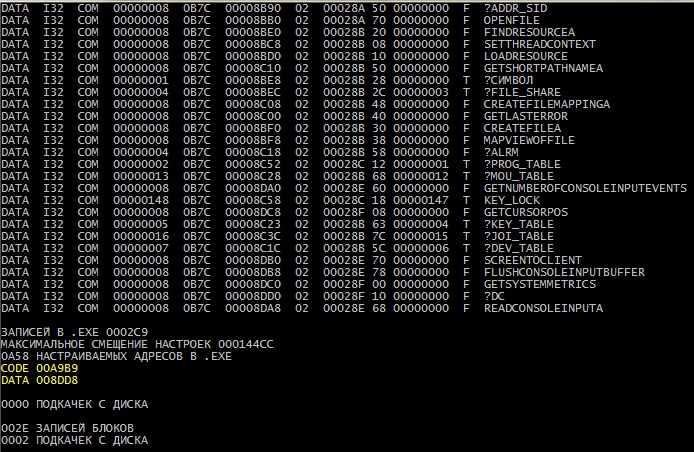
end test;На рис.1. показано, в какие команды перевел этот текст компилятор. Красным я подчеркнул те 9 мест внутри команд, где адреса остались недостроенными. В большинстве этих мест вместо адресов просто нули. Но текстовые константы имеют не нулевой адрес, а отсчитанный компилятором «от начала» модуля (адреса E4 и E5)

А вот на рис. 2. приведен фрагмент объектного модуля в формате OMF после компиляции. Все коды, приведенные на рис. 1, поместились в одну LEDATA. В начале этой записи стоит 01 – это т.н. сегмент команд с именем CODE. Затем следуют четыре нуля – это смещение команд относительно начала модуля. И только затем следует первый байт кодов B8, который внутри FIXUPP для этой LEDATA имеет «адрес» 00. Именно отсюда начинается отсчет смещения для идущей следом записи FIXUPP.

Адреса мест внутри LEDATA, указанные в FIXUPP, где следует достроить адреса, я тоже подчеркнул красным. Старшие два бита каждого такого адреса записаны в младших двух битах предыдущего байта. В данном случае они все нулевые.
Байт режима адресации 86, который следует сразу за адресом места, означает, что нужно достать и записать в указанное место адрес внешней функции с номером из списка 21 (?START), 14 (?SYSPS), 1B (?SLCTP), 20 (?QIOOP), 22 (?STOPX). А два места с адресами 15 и 21, это адреса данных, а не команд, что закодировано байтом режима адресации 9D. Вот почти и вся настройка адресов.
Обратите внимание на две следующие записи LEDATA на рис.2. Это текстовые константы. Настраивать адреса в них не надо, поэтому никаких FIXUPP здесь нет. В этих записях сначала идет 02 – это сегмент с именем DATA, затем следуют адреса этих констант от условного нуля модуля. Это адреса 000000E4h и 000000E5h. При обработке этих записей редактор связей сначала поместит первую константу в образе будущей программы по адресу E4, а следом не дрогнувшей рукой прямо поверх нее другую константу с адреса E5. В результате в программе окажется все-таки один единственный экземпляр строки, содержащий обе константы одну в другой. Как видите, редактор связей может не только настраивать адреса, но и выполнять некоторые другие полезные действия.
Например, последняя запись с именем MODEND указывает редактору связей, с какой команды следует начинать выполнение всей программы. Кстати, это не обязательно первая команда в EXE-файле. И все это формирует тоже редактор связей.
В результате его работы коды команд программы приобретают окончательный вид, приведенный на рис. 3. (это уже вывод из встроенного отладчика) :

Редактор связей может реализовывать и более экзотические вещи, например оверлеи. Оверлеи – это фрагменты программы, которые в процессе выполнения программы читаются из файлов на одно и то же место в памяти (предполагается, что одновременно в памяти они не нужны) и, тем самым, память экономят. С точки зрения редактора связей, для каждого оверлея требуется всего лишь начинать отсчет адресов, так сказать, заново, а не последовательно от начала до конца, как в обычной программе.
И в заключение еще об одном, может быть не совсем очевидном использовании редактора связей. Сейчас часто принято выдавать результат работы компилятора не сразу в виде объектного модуля, а в виде текста на языке ассемблера. Затем автоматически запускается транслятор с ассемблера, который из этого текста и формирует уже «настоящий» объектный код, тот самый, который потом будет обрабатываться редактором связей.
Одним из преимуществ такого подхода объявляется отсутствие необходимости двух или более «проходов» компилятора для обработки ссылок вперед. В самом деле, если в исходном тексте программы попадается «далекая» ссылка вперед, то как же формировать, например, переход к метке, если сама метка еще не встретилась в тексте программы? Ведь запись типа LEDATA уже сформирована, а адрес перехода так и неизвестен. Конечно, можно просмотреть компилятором программу два раза и составить полную таблицу всех адресов меток. В случае же трансляции на язык ассемблера такой переход вперед – это проблема уже транслятора с ассемблера, а не компилятора с языка высокого уровня. Правда, классический транслятор с ассемблера сам просматривает исходный текст тоже два раза: первый раз для определения длин команд и расчета адресов меток, а второй – для собственно генерации команд. Но, повторю, этот способ не требует от компилятора двух просмотров вместо одного.
Так вот, для переходов вперед по неизвестному пока адресу и компилятор не обязательно должен иметь два прохода. Ведь можно же заказать редактору связей такую отложенную достройку адреса. Т.е. компилятор в конце обработки всего модуля (когда он уже имеет полную таблицу адресов всех меток) формирует еще отдельные FIXUPP и по сути фиктивные нулевые LEDATA. Эти короткие LEDATA загружаются в нужное место образа модуля, а затем как обычно настраивается каждая своим парным FIXUPP, содержащим теперь известный адрес метки. Тогда сначала редактор связей обработает все обычные пары LEDATA+FIXUPP, а затем «поверх» обработанного еще и эти отдельные дополнительные FIXUPP для формирования адресов ссылок вперед, т.е. выполнит роль второго прохода компилятора. Между прочим, так использовать редактор связей еще и гораздо быстрее и проще, чем запускать отдельно транслятор с ассемблера и затем два раза посимвольно обрабатывать весь текст программы на ассемблере.