
Когда на iOS возникает вопрос о какой‑то оффлайн работе, часто разработчики обращают свой взор на CoreData — фреймворк, который управляет хранением данных в приложении. Он представляет собой слой абстракции над персистентным хранилищем, представляющую данные в виде «Сущность — Атрибут — Значение». Подразумевается, что CoreData сама занимается организацией таблиц, индексацией, оптимизацией запросов и всем, с чем обычно сталкиваются проектировщики баз данных. Также фреймворк предлагает много не менее полезных функций, таких как упрощенную интеграцию с iCloud, кроссплатформенность в рамках платформ Apple, lazy загрузку данных, отдельные оптимизации для таблиц и коллекций в виде NSFetchedResultsController. В идеальном мире использование CoreData сводилось бы к нахождению необходимых объектов, их изменению и вызову метода сохранения без головной боли.
Однако, фреймворк имеет высокий порог входа и много неочевидных моментов, которые обязательно всплывут при масштабировании приложения. Но насколько можно приблизиться к тому идеальному миру, обрисованному ранее? В этой статье я поделюсь своим опытом работы с CoreData, и предложу решение, упрощающее работу с ней практически до вызова одного универсального метода для базовых нужд изменения и сохранения данных, попутно рассказав, какие фишки CoreData рассматривались как вариант достижения этой цели.
Предполагается, что вы разбираетесь в основах фреймворка - контекстах, моделях, persistent контейнерах.
Если не разбираетесь, то рекомендуем перед изучением статьи сперва ознакомиться с материалами канала Kodeco. Или можете изучить книгу objc.io на соответствующую тему, но там настолько полный материал, что данная статья будет уже скорее всего будет не нужна)
Зачем в приложении используется CoreData
Базовое приложение — трекер задач, поддерживающий полную оффлайн работу и механизмы синхронизации при подключении к сети. Синхронизация работает по принципу получения свежих данных с бекенда, по которым высчитывается разница с локальным хранилищем и сохраняется в БД. Отсюда появилась потребность работать с большими объемами информации независимо друг от друга, например обработка задач независимо от прикрепленных к ним файлов и в каком проекте они содержатся.
В приложении 9 сущностей, в каждой из которых в среднем по 10 полей. Причем такие сущности, как задачи внутри проекта могут находиться в БД в приличных количествах, соответственно работа с ними может занимать заметное время.
В схеме БД.xcdatamodeld нет ни одного отношения между очевидно логически связуемыми сущностями, как, например, между проектом и списком задач внутри. В проекте существовал только родной viewContext у persistentContainer. Все операции и логика строились на том, что сохранение информации происходит синхронно, и после фетча, изменения и сохранения информации можно работать уже с актуальными данными буквально на следующей строке кода. И это действительно работало до момента пока не начало лагать, так как очень сильно загружало main поток задачами по сохранению информации. В приложении появилась острая потребность вынести код добавления, изменения и сохранения информации в фон.
Цель
Устроить работу с CoreData таким образом, чтобы минимизировать фризы при работе с данными и сделать единое удобное API для изменения и сохранения данных.
Для достижения цели я выделил несколько ключевых моментов:
Чтение должно происходить из main очереди для достижения отзывчивого и актуального UI.
Запись, изменение и сохранение информации должно производиться вне main очереди.
Необходимо иметь понимание, когда операция записи закончила свое выполнение и в БД все готово к выполнению дальнейших действий с актуальными данными.
Запись должна происходить синхронно друг за другом, чтобы избежать крешей и неконсистентности данных.
Решение должно предоставлять удобное понятное API для взаимодействия.
Решение должно быть щадящее для новичков и, насколько это возможно, защищено от выстрелов в ногу.
Дочерние контексты
Начнем с выноса в фон записи и сохранения. Первое рекомендуемое от Apple решение — дочерние контексты. Использование дочерних контекстов можно рассматривать как использование различных транзакций. Суть в том, что дочерний контекст при сохранении отсылает свои изменения в родительский контекст. Будем использовать viewContext у persistentContainer в качестве контекста для чтения — readContext.
Попробуем создать фоновый контекст, указав его как дочерний контекст readContext. Создадим метод, который примет на вход блок работы с контекстом, где будет происходить запись. Вызовем его, затем сохраним контекст:
func enqueueBackgroundWriteBlock(block: (NSManagedObjectContext) -> Void) {
let backgroundContext = NSManagedObjectContext(concurrencyType: .privateQueueConcurrencyType)
context.parent = readContext
block(context)
do {
try context.save()
} catch {
context.rollback()
}
}Казалось бы, вот и решение. Но у подхода есть две проблемы. Первая: по ходу работы начали возникать merge‑конфликты, которые оказались не самыми тривиальными и требовали ручного разрешения. Вторая: child‑контекст хоть и выполняет операции на background очереди, при сохранении коммитит информацию в readContext, что при больших объемах данных может снова приводить к фризам и дорогостоящим операциям на main очереди. Потратив на борьбу с этими недостатками приличное количество времени, перечитал документацию внимательнее и нашел метод на NSPersistentContainer — newBackgroundContext().
По документации (перевод на русский близко к тексту):
Вызов этого метода заставляет NSPersistentContainer создать и вернуть новый NSManagedObjectContext с concurrencyType, выставленной в privateQueueConcurrencyType. Этот контекст будет ассоциирован напрямую с NSPersistentStoreCoordinator, также настроен на отслеживание NSManagedObjectContextDidSave автоматически.
Этот метод действительно решает одну из проблем — merge‑конфликты ушли. Однако контекст все еще тащит информацию через readContext и как следствие через main очередь, поэтому child/parent подход в моем случае не подошел. Как вывод, со ссылкой на прекрасную книгу objc.io по CoreData, использование parent/child контекстов я предпочитаю скорее избегать, в частности из‑за проблем со скоростью работы.
Решение проблемы с синхронизацией контекстов
Как Apple и написали, для решения вопроса нужно ассоциировать контекст с NSPersistentStoreCoordinator и отслеживать его сохранение. Предлагаю сделать это самим:
func enqueueBackgroundWriteBlock(
block: @escaping (_ writeContext: NSManagedObjectContext) -> Void,
receiveCompletionOn queue: DispatchQueue = .main,
completion: (() -> Void)? = nil
) {
let context = NSManagedObjectContext(concurrencyType: .privateQueueConcurrencyType)
context.persistentStoreCoordinator = self?.persistentContainer.persistentStoreCoordinator
context.mergePolicy = NSMergePolicy.mergeByPropertyObjectTrump
observeChanges(in: context, receiveCompletionOn: queue, completion: completion)
context.performAndWait {
block(context)
do {
try context.save()
} catch {
context.rollback()
}
}
}
private func observeChanges(
in context: NSManagedObjectContext,
receiveCompletionOn queue: DispatchQueue = .main,
completion: (() -> Void)? = nil
) {
NotificationCenter
.default
.addObserver(
forName: .NSManagedObjectContextDidSave,
object: context,
queue: nil
) { [weak self] notification in
self?.readContext.perform {
self?.readContext.mergeChanges(fromContextDidSave: notification)
queue.async {
completion?()
}
}
}
}
Разберем что происходит:
Внутри метода enqueueBackgroundWritingTask на вход передаем блок работы с фоновым контекстом, очередь, на которой хотим принять completion, и собственно сам completion, который оповестит нас о том, что запись завершилась и в основном контексте актуальная информация.
Внутри метода мануально создается фоновый контекст NSManagedObjectContext(concurrencyType:.privateQueueConcurrencyType).
Строчкой далее контексту указывается persistentStoreCoordinator, используемый в приложении. Он же стоит у readContext — таким образом мы направили два разных контекста на одно и то же хранилище информации.
Так как и фоновый и основной контексты читают и пишут в один источник, конечно, возникают мердж‑конфликты. Разрешение мердж‑конфликтов мануально — своя отдельная забава, но в общем случае по моему мнению достаточно указать обоим контекстам NSMergePolicy.mergeByPropertyObjectTrump.
Таким образом при возникновении конфликтов приоритизируется информация в сторе, а сравнивается информация по полям объекта. Это означает, что при возникновении конфликта из объекта будет выкинута не вся информация, а только конфликтная.
После этого мы вызываем метод observeChanges, который подписывается на уведомление NSManagedObjectContextDidSave для нашего фонового контекста. Когда он будет сохранен, внутри блока perform вызывается метод mergeChanges, после которого уверенно можно сказать, что операция завершена и можно вызывать completion.
Далее на контексте вызывается performAndWait, которая синхронно дождется выполнения переданного блока, после вызова которого делается save или rollback.
Мы близко к желаемому результату, но остался один неразрешенный вопрос.
Проблема с очередями
CoreData потоконебезопасна. Конкретнее — NSManagedObjectContext может работать только на том потоке, на котором он был создан. Поэтому все фоновые операции записи должны быть созданы и работать в рамках одной синхронной очереди. При большом желании операции можно распараллелить используя NSManagedObjectID:
NSManagedObjectID это универсальный идентификатор для NSManagedObject, который обеспечивает базис для уникальной идентификации в CoreData. NSManagedObjectID идентифицирует один объект как между контекстами внутри приложения, так и между несколькими приложениями (в распределенных системах). Как первичный ключ в базе данных, идентификатор содержит информацию, необходимую для уникального описания объекта в постоянном хранилище, не раскрывая детали.
Из вышесказанного можно сделать вывод, что CoreData уникально идентифицирует каждый объект, и мы можем получить доступ к этому ID, перебрасывать его между очередями и выстроить на этом безопасное взаимодействие. Для получения объекта ID, на NSManagedObject вызывается objectId, а для получения объекта из ID на другой очереди, у контекста этой очереди нужно вызвать context.object(with: NSManagedObjectID). Однако, у этого механизма есть особенность:
Существуют два вида Object ID. Когда создается NSManagedObject, CoreData назначает ему временный ID; только если объект записан в постоянное хранилище, CoreData назначает объекту постоянный ID.
Проверить, временный ли перед вами ID, можно через isTemporaryID на NSManagedObjectID. В моем случае достаточно синхронного выполнения на одной очереди.
Финальное решение
Теперь, когда мы обсудили все нюансы, поговорим про конечное решение.
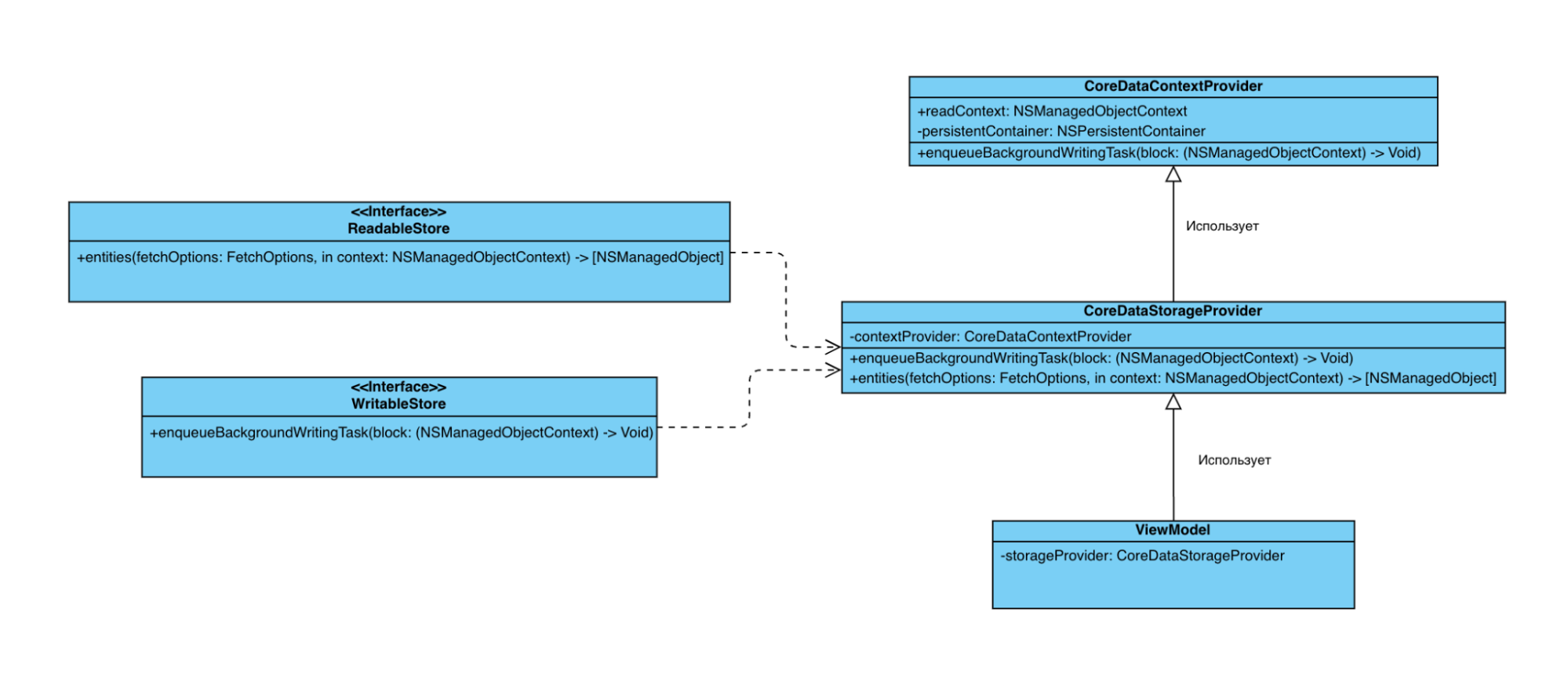
CoreDataContextProvider будет хранить контекст для чтения и persistentContainer и предоставлять доступ к тому самому методу фоновой таски на запись. В свою очередь, CoreDataStorageProvider будет иметь доступ к ContextProvider, и будет предоставлять наружу методы фетча информации и вызова метода записи. ViewModel будет использовать именно StorageProvider.
Как сделать CoreDataStorageProvider, я думаю, вопросов не будет, так как там составляется fetchRequest, и прокидывается вызов метода записи.
Поэтому обратим внимание на реализацию CoreDataStorageProvider: тут уже знакомая нам реализация, только уже с той самой очередью, о которой мы говорили в конце пункта выше.
Создаем ReadContext для чтения из основной очереди. Указываем ему mergePolicy = NSMergePolicy.mergeByPropertyObjectTrump, приоритизируя тем самым данные в сторе.
lazy var readContext: NSManagedObjectContext = {
let viewContext = self.persistentContainer.viewContext
viewContext.mergePolicy = NSMergePolicy.mergeByPropertyObjectTrump
return viewContext
}()Проблему с очередями решим через OperationQueue и addOperation:
private let operationQueue: OperationQueue = {
let queue = OperationQueue()
queue.maxConcurrentOperationCount = 1
return queue
}()Ну и знакомый нам уже метод enqueueBackgroundWriteBlock выглядит так же, но теперь мы добавляем таски на очередь:
func enqueueBackgroundWriteBlock(
block: @escaping (_ writeContext: NSManagedObjectContext) -> Void,
receiveCompletionOn queue: DispatchQueue = .main,
completion: (() -> Void)? = nil
) {
operationQueue.addOperation() { [weak self] in
let context = NSManagedObjectContext(concurrencyType: .privateQueueConcurrencyType)
context.persistentStoreCoordinator = self?.persistentContainer.persistentStoreCoordinator
context.mergePolicy = NSMergePolicy.mergeByPropertyObjectTrump
self?.observeChanges(in: context, receiveCompletionOn: queue, completion: completion)
context.performAndWait {
block(context)
context.saveOrRollback()
}
}
}Готово!
Из возможных доработок (как раз секция от выстрела в ногу), можно создать подкласс NSManagedObjectContext отдельно для записи c fileprivate init, чтобы его мог инициализировать только сам ContextProvider, а использовать любой желающий. Тем самым можно выстроить такой фасад, который будет принимать для внутренней работы с данными исключительно WritingContext, который в свою очередь может быть создан только внутри enqueueBackgroundWriteBlock. Таким образом новички будут хоть чем‑то ограждены от жонглирования контекстами.
Также я предпочитаю сделать реактивную обертку для этого метода, пример для RxSwift:
extension Reactive where Base == CoreDataContextProvider {
func enqueueBackgroundWriteBlock(
block: @escaping (_ writeContext: NSManagedObjectContext) -> Void
) -> Single<Void> {
Single.create { single in
base.enqueueBackgroundWriteBlock(block: block) {
single(.success(()))
}
return Disposables.create()
}
}
}Этот подход достойно показал себя уже на двух проектах CleverPumpkin с тяжелой оффлайн работой, поэтому я лишь могу рекомендовать его к использованию.
На этом у меня все, спасибо за прочтение, буду рад услышать ваши мнения и предложения в комментариях!