
Синтез изображений из текста прошел долгий путь от появления DALL-E до Stable Diffusion. Несколько дней назад был открыт код большой (4.3 млрд параметров) модели для генерации изображений, которая привлекла внимание своим новым подходом к генерации - DeepFloyd IF. В этой статье я кратко рассмотрю архитектуру модели, ее возможности и приведу примеры ее работы. Кроме того, я поделюсь ссылками на онлайн-демо на платформе Replicate для лёгкого запуска без нужды устанавливать нейросеть на свой компьютер.

Архитектура
IF - это трехступенчатая модель, состоящая из кодера замороженного текста и трех каскадных модулей диффузии пикселей. Кодировщик замороженного текста основан на T5, который извлекает текстовые эмбеддинги из входных подсказок. Затем эти эмбеддинги поступают в архитектуру UNet, которая была усовершенствована перекрестным вниманием.
Подход DeepFloyd очень похож на подход Google в своём Imagen.
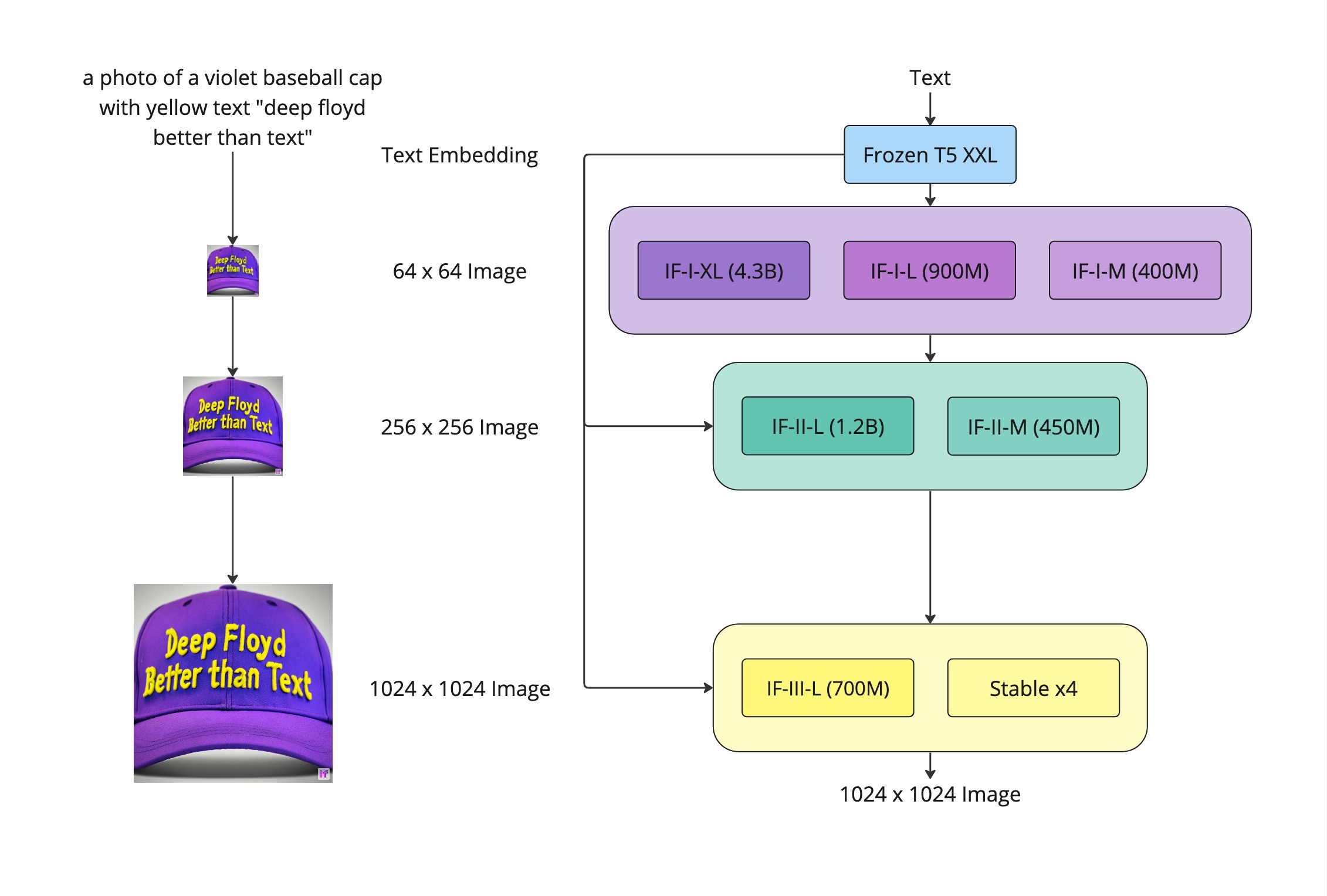
Модель состоит из трех основных элементов:
Базовая модель: На этом этапе генерируется изображение размером 64x64 px на основе текстовой подсказки. (В демо используется IF-I-XL)
Первая модель суперразрешения: Она увеличивает базовое изображение до 256x256 px, добавляя больше деталей. (В демо используется IF-II-L)
Вторая модель суперразрешения: На этом последнем этапе изображение увеличивается до высокого разрешения 1024x1024 px. (В демо используется Stable X4)
Модульный подход позволяет добиться высокой эффективности и впечатляющей производительности, превосходя текущие современные модели. IF достигает оценки FID 6,66 на наборе данных COCO, что гораздо выше, чем у DALL-E-2 (10.39), Stable Diffusion (15.5) и даже чем у Imagen (7.27).
Для запуска самого максимального набора моделей (IF-I-XL; IF-II-L; Stable X4) может понадобиться 24 ГБ видеопамяти. При использовании разгрузки на CPU - 14 ГБ.
Примеры работы
Image of a dog in a sunglasses

An image of a forest in a snowstorm (16:9)

A painting of a cat

Онлайн демонстрации
Вы можете воспользоваться демонстрацией, которую я создал и запустил на Replicate под работой Nvidia A100. Репозиторий: https://github.com/0x7o/IF-replicate

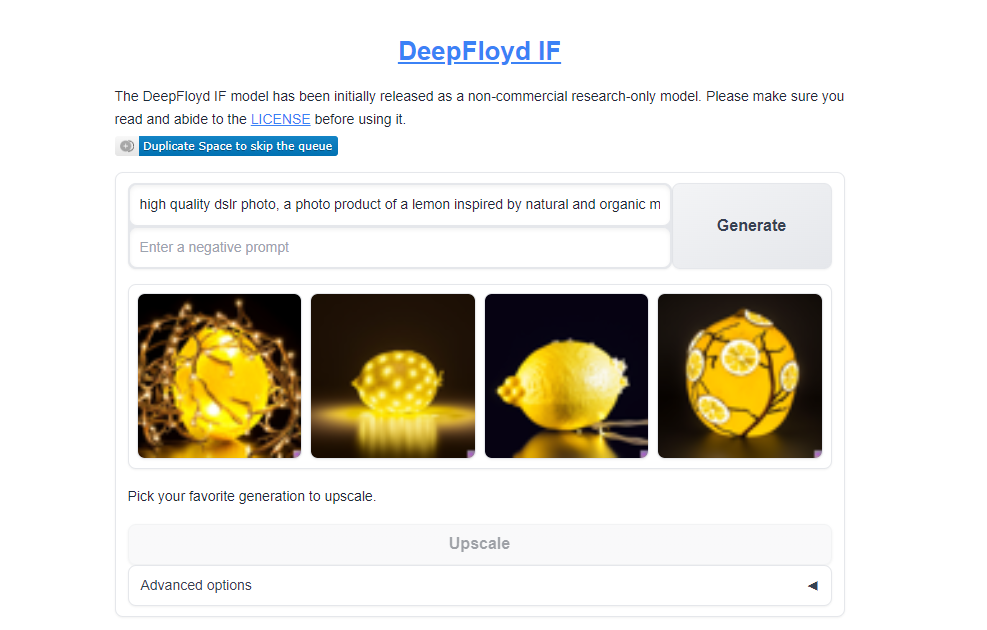
Вы также можете использовать официальную демонстрацию на HuggingFace Spaces, но там гораздо меньше параметров для настройки генерации.
Заключение
DeepFloyd IF - это ещё один шаг в области синтеза изображения из текста, устанавливающий новые стандарты. С дальнейшим развитием этой области мы можем ожидать еще более мощных и творческих моделей.
Официальный репозиторий - https://github.com/deep-floyd/IF
Официальная демонстрация - https://huggingface.co/spaces/DeepFloyd/IF
Демонстрация на Replicate - https://replicate.com/0x7o/if-v1.0
Код демонстрации - https://github.com/0x7o/IF-replicate
Что думаете Вы?