
В первой части мы проводили обучение сети FNN с одним скрытым слоем (различные количества нейронов в скрытом слое и различные размеры батчей) для распознавания изображения рукописных цифр набора MNIST. Применяли все стандартное - штатный adam, categorical_crossentropy, relu, softmax, и примерно к 40 эпохам график точности уже становился плоским.
Как было указано, непосредственно для распознавания изображений лучше применять не FNN (Нейронные сети прямого распространения), а CNN (Сверточные нейронные сети), в том числе многослойные и предобученные, и целью данной статьи не является попытка превысить на FNN точность распознавания на CNN. В данной статье мы исследуем, меняется ли существенно точность при изменении количества нейронов скрытого слоя и при изменении размера батча, или это случайный разброс вызванный рандомностью инициации весов и рандомностью формирования каждого батча.
Разные количества нейронов, разные размеры батчей
Приведем обобщающие графики точности при различных количествах нейронов скрытого слоя и различных размерах батчей на 40 эпохах.
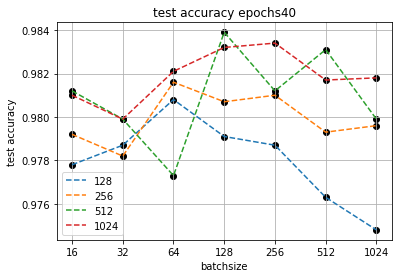


Видно, что для большинства соотношений точность на тестовой выборке располагается вокруг 98.1%, от 97.8% до 98.4%. При этом видно, что чем больше количество нейронов, тем в целом точность выше, но не всегда. Так в большинстве случаев при одинаковом размере батча точность увеличивается по мере увеличения количества нейронов, однако пара (512, 128) дает самый лучший результат, даже лучше, чем (1024, 128) и лучше, чем все представленные соотношения с количеством нейронов 1024. И наоборот, пара (512, 64) дает худший результат для данного размера батча, даже хуже, чем (256, 64) и (128, 64).
Как известно, обучение сети проходит достаточно вариативно, так как в большинстве случаев инициация весов происходит рандомно и формирование каждого батча происходит рандомно, поэтому каждый запуск обучения может давать разные результаты даже с одними и теми же гиперпараметрами.
Такая ситуация приводит к вопросу, показывают ли приведенные графики тенденции и закономерности, или это просто случайный разброс, вызванный упомянутыми рандомностями.
Смотрим на разброс
Касательно рандомных и фиксированных инициаций весов уже была опубликована отдельная статья, и был сделан вывод о том,что в случае FNN c одним скрытым слоем рандомная инициация дает те же результаты, что и фиксированные, или даже лучше.
Приведем некоторые графики из упомянутой статьи.


С одной стороны, мы вполне можем продолжать применять рандомную инициацию, зная, что применение фиксированных инициаций не повышает точность.
С другой стороны, видно, что независимо от способа инициации, даже при при одном и том же соотношении количества нейронов и размера батча точность уже может колебаться примерно в интервале несколько десятых процента, и даже с фиксированными инициациями, а это может означать, что попадания точности в интервал 0.978-0.984 может в действительности и не говорить ни о какой зависимости точности от количества нейронов скрытого слоя и от размера батча, а быть просто разбросом, вызванным рандомностью формирования каждого батча.
Продолжим изучать вариативность и обучим сеть по 10 раз с фиксированным количеством нейронов и фиксированным размером батча.


Графики подтверждают, что при фиксированном количестве нейронов и фиксированном размере батча точность может колебаться на несколько десятых процента. На одном видим примерно 0,25%, а на втором почти 0,8%.
Объединяем графики
Сделаем по несколько повторов с фиксированным количеством нейронов и фиксированным размером батча, и объединим на одном графике повторы с разным количеством нейронов и одним размером батча.
Количества нейронов: 128-192-256-384-512-768-1024
Размеры батча: 64-128.


Хорошо видно, что при размере батча 128 точность расходится, но расходится примерно на один интервал (примерно 0,3%), и в целом весь этот интервал почти полностью, за исключением редких выбросов, повышается по мере увеличения количества нейронов от 128 до 1024. Лучший результат получен при самом большом количестве нейронов - 1024, а ближайшие "призовые" места получены также для 1024 и соседнего 768.
При размере батча 64 точность ожидаемо расходится чуть больше, до 0,5%, но при этом также весь интервал в целом, за исключением редких выбросов, повышается по мере увеличения количества нейронов от 128 до 1024. Как и в случае с размером батча 128, лучший результат получен при самом большом количестве нейронов - 1024, а ближайшие "призовые" места получены также для 1024 и соседнего 768.
Выводы
Получили, что, действительно, при запуске с одними и теми же количествами нейронов скрытого слоя и размерами батчей точность может отличаться на несколько десятых процента, но при этом весь интервал точности в целом, за исключением редких выбросов, повышается по мере увеличения количества нейронов от 128 до 1024. Лучшие результаты стабильно получаются при максимальном значении количества нейронов, в данном случае при 1024.
Что касается зависимости от размеров батча, то при одном и том же количестве нейронов результаты при разных размерах батчей могут пересекаться. С одной стороны, результаты с батчем 128 компактней, поиск как бы обходит больше неглубоких локальных минимумов, то есть в целом батч 128 может дать более компактные, более стабильные и более высокие результаты, чем с батчем 64. С другой стороны, результаты с батчем 64 тоже достаточно стабильны, но при этом более разбросаны, и некоторые запуски могут давать более лучшие индивидуальные результаты, чем с батчем 128.
В целом, общий вывод повторяется:
Для лучшего результата обобщающей способности и точности на тестовой выборке целесообразно брать количество нейронов скрытого слоя "побольше" (насколько позволяют вычислительные мощности и время) и следить, чтобы сеть не переобучалась. При этом целесообразно запускать обучение несколько раз с различными размерами батчей (например, 32-64-128), и большинство запусков могут ложиться в единый общий интервал в несколько десятых процента, но некоторые отдельные запуски могут давать индивидуальные лучшие результаты.
Примечания
Если замечены грубые ошибки, которые могут существенно изменить результаты и выводы эксперимента, то прошу указать в комментариях. И, наоборот, если в целом рассуждения и ход эксперимента видятся корректными, то также прошу указать в комментариях.