
Логирование — один из трех столпов observability в распределенных системах. Мы видим, как растут популярные продукты с открытым исходным кодом (например, ELK-стек) и зрелые коммерческие продукты (например, Splunk) для ведения логирования в больших масштабах. Однако в такой сложной системе, как Kubernetes, логирование остается серьезной проблемой. Она усугубляется с ростом данных и широким внедрением контейнерной системы.
В этой статье мы рассмотрим различные типы логов Kubernetes, необходимые для observability, а также подходы к сбору, объединению и анализу этих логов в Kubernetes. Затем мы представим решение с открытым исходным кодом, использующее fluentd и fluentbit, чтобы упростить ведение логов.

Типы логов Kubernetes
Логи приложений
Логи приложений нам нужны для устранения неполадок или просто для мониторинга их активности. Все механизмы контейнеров (например, Docker, containerd, cri-o) поддерживают какой-либо из механизмов логирования: например, stdout/stderr или запись в файл.
Мы также можем сгруппировать логи из инструментов Kubernetes, таких как входные контроллеры, средства автомасштабирования кластера или менеджер сертификатов, в эту категорию.
Логи компонентов Kubernetes
Помимо оркестрируемого приложения, Kubernetes также создает логи из своих компонентов, таких как etcd, kube-apiserver, kube-scheduler, kube-proxy и kubelet. Если узел поддерживает systemd, среды выполнения kubelet и контейнера записывают в journald. В противном случае системные компоненты записывают .log файлы в /var/logкаталог узла.
События Kubernetes
Каждое событие Kubernetes (например, планирование модуля, удаление модуля) — это объект API Kubernetes, записываемый сервером API. Эти логи содержат важную информацию об изменениях состояния ресурсов Kubernetes.
Логи аудита Kubernetes
Kubernetes также предоставляет логи аудита для каждого запроса к серверу API, если он включен. Каждый запрос связан с предопределенным этапом: RequestReceived, ResponseStarted, ResponseComplete, и Panic генерирует событие аудита. Затем это событие обрабатывается в соответствии с политикой аудита, в которой подробно описаны уровни аудита, включая None, Metadata, Request и RequestResponse
Подходы к ведению логов в Kubernetes
Как правило, в Kubernetes есть два основных способа обработки логов:
Ведение логов на stdout/stderr и использование агента ведения логов для агрегирования/пересылки во внешнюю систему.
Использование sidecar для отправки логов во внешнюю систему.
В первом случае kubelet отвечает за запись логов контейнера на /var/log/containers базовый узел. Обратите внимание, что Kubernetes не предоставляет встроенного механизма ротации логов, но файлы логов удаляются с узла при удалении из него контейнера. Затем агент ведения логов отвечает за сбор этих логов и отправку их агрегатору, такому как Splunk, Sumo Logic и ELK.
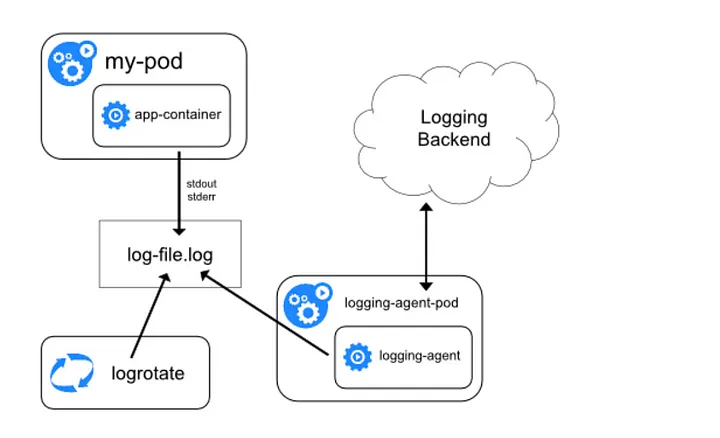
Кроме того, вместе с приложением можно развернуть дополнительный контейнер для сбора логов из приложения. Этот sidecar может читать из потока, файла, сокета или журнала и отправлять в инструмент агрегирования логов для дальнейшего анализа и хранения.

Наконец, код приложения можно переконфигурировать для отправки логов непосредственно в какой-либо сервер ведения логов, но этот шаблон не является распространенным, поскольку он изменяет поведение кода.
Инструменты логирования Kubernetes
Поскольку Kubernetes по умолчанию не предоставляет возможности объединения логов, агенты логов часто разворачивают на уровне кластера для сбора, объединения и отправки логов на центральный сервер.
Fluentd & Fluent Bit
И Fluentd, и Fluent Bit являются агрегаторами и переадресаторами логов производственного уровня, размещенными Cloud Native Computing Foundation (CNCF). Fluentd был первоначальным проектом, направленным на решение задач агрегации и пересылки логов в масштабе, а Fluent Bit был добавлен позже как облегченная версия Fluentd с аналогичными целями. Каждый проект можно использовать автономно в роли агрегатора или экспедитора. Также можно комбинировать оба развертывания, как мы увидим позже в модели Fluent Operator.
ELK/EFK
Еще одним популярным инструментом с открытым исходным кодом является стек ELK (Elasticsearch, Logstash и Kibana):
Elasticsearch: индексирует файлы логов для анализа.
Kibana: инструмент визуализации
Logstash: агрегатор логов
Beats: пересылка логов
Иногда Logstash/Beats заменяется Fluentd или Fluent Bit для создания стека EFK.
Stackdriver / CloudWatch
При работе в общедоступном облаке (например, GKE, EKS) также можно использовать собственное решение для логов каждого поставщика. GKE по умолчанию поддерживает Stackdriver. На EKS развернут набор демонов Fluentd, настроенный на передачу логов в Cloudwatch.
Коммерческие варианты
Наконец, есть общепризнанные коммерческие инструменты от Splunk, Sumo Logic, Datadog и других, каждый из которых имеет собственные агенты ведения логов.
Fluent Operator
Fluent Bit Operator (будет переименован в Fluent Operator) — это оператор ведения логов Kubernetes, разработанный командой KubeSphere и переданный в дар сообществу Fluent. Fluent Operator сочетает в себе преимущества fluentbit (легкий) и fluentd (богатая экосистема плагинов) для сбора логов с каждого узла с помощью набора демонов fluentbit, который затем перенаправляется в fluentd для агрегирования и пересылки в свои приемники, такие как elasticsearch, kafka, loki, s3, splunk. , или другой инструмент анализа логов.
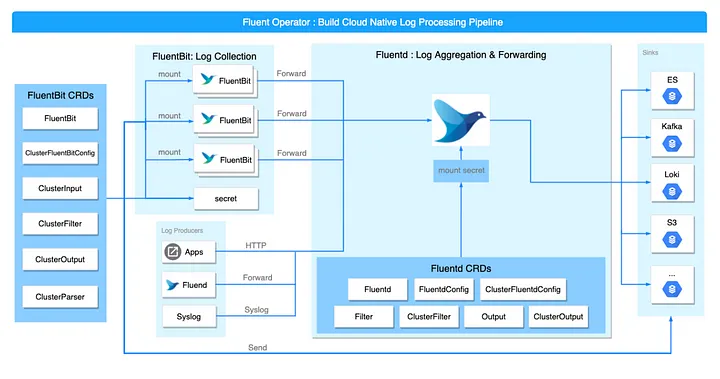
Fluent Operator состоит из следующих пользовательских ресурсов:
FluentBit. Определяет набор демонов Fluent Bit и его конфигурации.
FluentBitConfig. Определяет плагины ввода/фильтрации/вывода и создает окончательную конфигурацию в секрете.
Input. Определяет входные разделы конфигурации.
Parser. Определяет разделы конфигурации парсера.
Filter. Определяет разделы конфигурации фильтра.
Output. Определяет разделы выходной конфигурации.
Использование оператора имеет несколько преимуществ для управления каждым из этих компонентов по отдельности:
Пользовательский образ Fluent Bit от KubeSphere поддерживает динамическую перезагрузку конфигурации без перезагрузки модулей Fluent Bit.
Связь между Fluent Bit и Fluentd управляется удобными для человека входными и выходными CRD вместо файлов конфигурации внутри каждого компонента.
Плагины ввода/фильтрации/вывода легче выбирать с помощью меток Kubernetes.
Обработка логов Kubernetes в KubeSphere
KubeSphere использует Fluent Operator для сбора и обработки логов Kubernetes. Чтобы включить ведение логов, просто установите для поля ведения лога значение true:
logging:
enabled: trueЗатем на панели инструментов вы сможете проверить компоненты ведения лога:

Чтобы собирать события Kubernetes, установите events для поля значение true.
events:
enabled: trueЗатем вы можете использовать функцию Event Search из Toolbox для поиска в логах событий:

Аналогично для логов аудита установите auditing для поля значение true.
auditing:
enabled: trueЗатем вы можете использовать функцию Auditing Operating из Toolbox:

Заключение
От логов приложений до логов аудита — существует множество источников логов, которые необходимо собирать и анализировать в Kubernetes. В этой статье мы рассмотрели распространенные шаблоны ведения логов (т. е. stdout, sidecar), а также популярные инструменты для сбора и агрегирования этих логов. Наконец, мы также увидели, как Fluent Operator используется в KubeSphere для упрощения процесса установки.
Внедрение надлежащей инфраструктуры ведения логов в масштабе — непростой процесс. Используйте встроенную интеграцию с Fluent Operator в KubeSphere, чтобы сосредоточиться на ключевых выводах, которые появляются в ваших логах, а не изобретать велосипед для решения сложной проблемы.
Если вы хотите прокачаться в observability и взять под контроль состояние системы, приходите на курс «SRE: Observability», который стартует 24 июля. Ознакомиться с программой и записаться можно на нашем сайте ???? https://slurm.club/43VJNRc
DennisAnaniev
А как же Promtail и Loki?