

Привет, Хабр! Сейчас мы вам расскажем, как в начале прошлого года радикально пересмотрели подход к использованию Airflow в Tele2. Если не хочется читать, можно послушать и посмотреть наше выступление с докладом по теме.
Контрибьютили:
Михаил Солодягин, DevOps-инженер, эксперт по внедрению
Сергей Юнк, DevOps-инженер, руководитель группы по внедрению
Вадим Суханов, руководитель группы разработки
Предыстория
Пара слов об Airflow — это open source инструмент для создания, оркестрации и мониторинга потоков операций по обработке данных, написанный на Python. Процессы описываются в виде операторов, которые объединяются в направленные ациклические графы, DAG-и. В нашей компании Airflow используется в основном аналитиками и дата-инженерами для запуска регулярных процессов по перегрузке данных и запуска различных расчётов.

Начинали мы с Production Airflow версии 1.10.12 в одном экземпляре, развёрнутом при помощи docker-compose на выделенной виртуальной машине. Рабочая нагрузка — 50–60 DAGов с частотой запуска от раза в 10 минут до раза в час плюс несколько DAGов с запуском раз в месяц.
За основу мы взяли довольно известный образ от Puckel, который впоследствии модифицировали дополнительными библиотеками и драйверами, а затем перевели на CentOS.

Что касается тестовой среды, схема будет такой же, только на одной виртуалке поднято сразу 4 инстанса Airflow. Хранение кода и деплой осуществлялись силами gitlab и gitlab CI, при этом деплой был в виде zip-архива, а коммуникация по стендам осуществлялась в Slack.
Когда количество пользователей Airflow в компании увеличилось, мы столкнулись с тем, что тестовых стендов стало не хватать. Для решения проблемы в моменте была придумана система «букинга» стендов через Slack: когда кому-то был нужен стенд, он объявлял об этом в специальном чате, и если стенд оказывался не занят, человек занимал его, а после окончания использования писал о том, что стенд освободился.
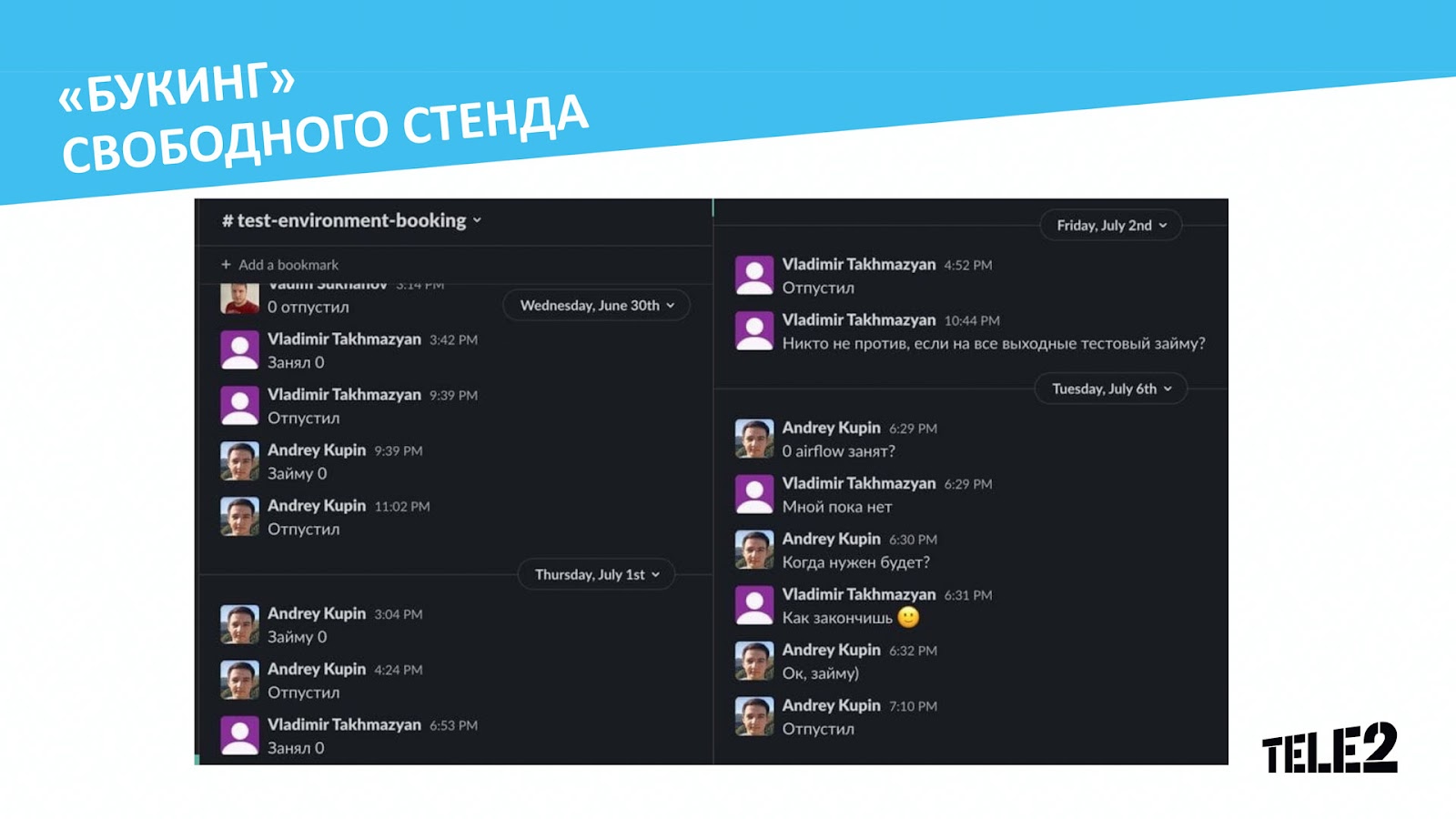
Помимо проблемы доступности стенда, в первоначальной схеме были и другие слабые места:
Для работы DAG’ов необходим набор так называемых секретов. Обычно это логины и пароли, адреса подключений или же переменные, содержимое которых хотелось бы скрыть от посторонних глаз. Изначально airflow предполагает хранение секретов в своей БД, а это значит, что данных, которые есть на стенде А, могло не оказаться на стенде Б.
Под каждый новый стенд приходилось запрашивать ресурсы и специалиста, который его бы для нас поднял.
При этом такой новый стенд висел мёртвым грузом в периоды затишья, а вычислительные ресурсы у нас не бесконечные.
А ещё мы сталкивались с ситуациями, когда стенд мог кто-нибудь сломать. При этом продиагностировать ситуацию самостоятельно было не всегда возможно.

Задача
Нужное нам решение должно было закрыть все описанные выше проблемы и при этом содержать в себе следующие хотелки наших пользователей:
Временное хранилище для DAGов, куда складывалась бы промежуточная информация во время исполнения задач DAGа и которое удалялось бы после завершения.
Возможность экспериментировать с различными версиями и набором библиотек и версиями самого Airflow без опасения сломать стенд.
Возможность быстрой смены Executor’ов Airflow.
Разграничение прав и доступов пользователей.
Вдобавок ко всему, нам необходимо было self-hosted решение.
Сначала в качестве возможных решений мы думали в следующих направлениях.
Статические стенды под каждого разработчика. Этот вариант был очень заманчив — отсрочить проблему и увеличить количество стендов до максимума, под каждого из сотрудников. Но тут же мы столкнулись с проблемой: многие члены нашей команды ведут разработку сразу двух и более фич, тестирование которых лучше всего проводить отдельно друг от друга. То есть даже в этом случае стендов будет недостаточно, да и никаких проблем, кроме изолированности стендов, этот подход не решает.
Автоматизация деплоя стендов через Ansible. Инструмент в компании известный, многие умеют с ним работать, есть готовые модули и роли. Но большинство проблем остаются нерешёнными: необходимо придумывать алгоритм, который бы освобождал занятые стендом ресурсы, когда тот уже не нужен; никак не решена проблема с логами, с доставкой секретов; к тому же хотелки клиентов остаются за бортом.
Уход от Airflow в пользу чего-то модного и молодёжного. Будучи реалистами, мы понимали: велика вероятность того, что другое решение будет содержать свои подводные камни, о которых узнать мы сможем только во время переезда + потеряем все уже существующие наработки. А это большие потери по времени.

Когда эти варианты были отметены, стали смотреть, как другие компании реализуют Airflow с точки зрения инфраструктуры. Наиболее эффективными нам показались облачные решения — такие, как у Astronomer и Google Cloud Composer. SaaS-подход решал практически все проблемы и казался нам silver bullet в нашей ситуации, однако хотелось разворачивать его на своих мощностях, с возможностью докрутить недостающие фичи и полностью на нашей поддержке. «Ну и чем мы хуже?» — подумали мы, засучили рукава и стали продумывать архитектуру нашего нового проекта.
Архитектура
Требования к используемым решениям были следующие:
компоненты должны быть преимущественно open-source;
по возможности иметь нативную поддержку со стороны Airflow;
быть простыми в обслуживании.
Инфраструктурным сердцем для SaaS-решения стал Kubernetes, на который, как нам казалось, будет просто переехать.

Для логов мы решили использовать Elasticsearch (позднее заменён на S3). Во-первых, потому что данное решение уже используется в компании; во-вторых, у Airflow есть готовый провайдер, который позволяет их оттуда читать. А после нашего Pull Request в проект — даже по порядку.
Сервисная БД — PostgreSQL. Для нас было непринципиально, где и как она будет существовать, так как ни пользователей, ни секреты хранить мы в ней не собирались. Поэтому пустая база разворачивается вместе с helm-поставкой, что достаточно удобно для нас.
В качестве хранилища DAGов и промежуточного хранилища для них мы используем механизм K8s Persistent Volume и данные volume’ы храним на Ceph.
Авторизация пользователей осуществляется через LDAP. Так как большинство сервисов в нашей компании используют Active Directory для авторизации, это было самым разумным решением.
В качестве мониторинга был выбран Prometheus, благо Airflow позволяет собирать огромное количество метрик. При помощи протокола StatsD мы посылаем их на развёрнутый у нас StatsD-экспортер, где преобразовываем в prometheus-like формат.

Секреты
Оставался вопрос, как мы будем хранить наши секреты. Для успешного решения проблем нам нужны:
1. Изолированность. На статичных стендах работало много людей, и каждый раз приходилось перепроверять, не перезаписал ли кто-то нужный тебе connection и работает ли стенд в принципе.
2. Наследуемость. Никто не хотел пересобирать свой набор «ходок» и по тысяче раз выяснять пароль от того или иного ресурса. Очевидно, что у команды полно командных секретов, которые накапливались годами и менять которые «под себя» не требуется.
3. Безопасность. Ситуация, при которой любой пользователь Airflow может получить доступ к списку продуктивных секретов, не устраивала никого.
Идею с тем, чтобы забирать секреты в обход встроенных в Airflow методов, мы сразу отмели: это потребовало бы переработки наших DAGов. Да и к тому же хотелось чего-то поддерживаемого производителем и иногда даже обновляемого. И, к нашему счастью, подобное решение нашлось — Hashicorp Vault.
Разработку Secrets Backend мы начали ещё для версии 1.10, поэтому листинги кода провайдера могут несколько отличаться от того, что присутствует в актуальной версии. Но кардинально сути это не меняет.
Казалось, что решение подходит нам сразу out of the box. При вызове get_connection() или get_variable() по указанному в конфигурации пути с указанным там же токеном провайдер ходит в каталог connections или variables на vault и ищет секрет с нужным id. Остаётся реализовать наследование секретов.

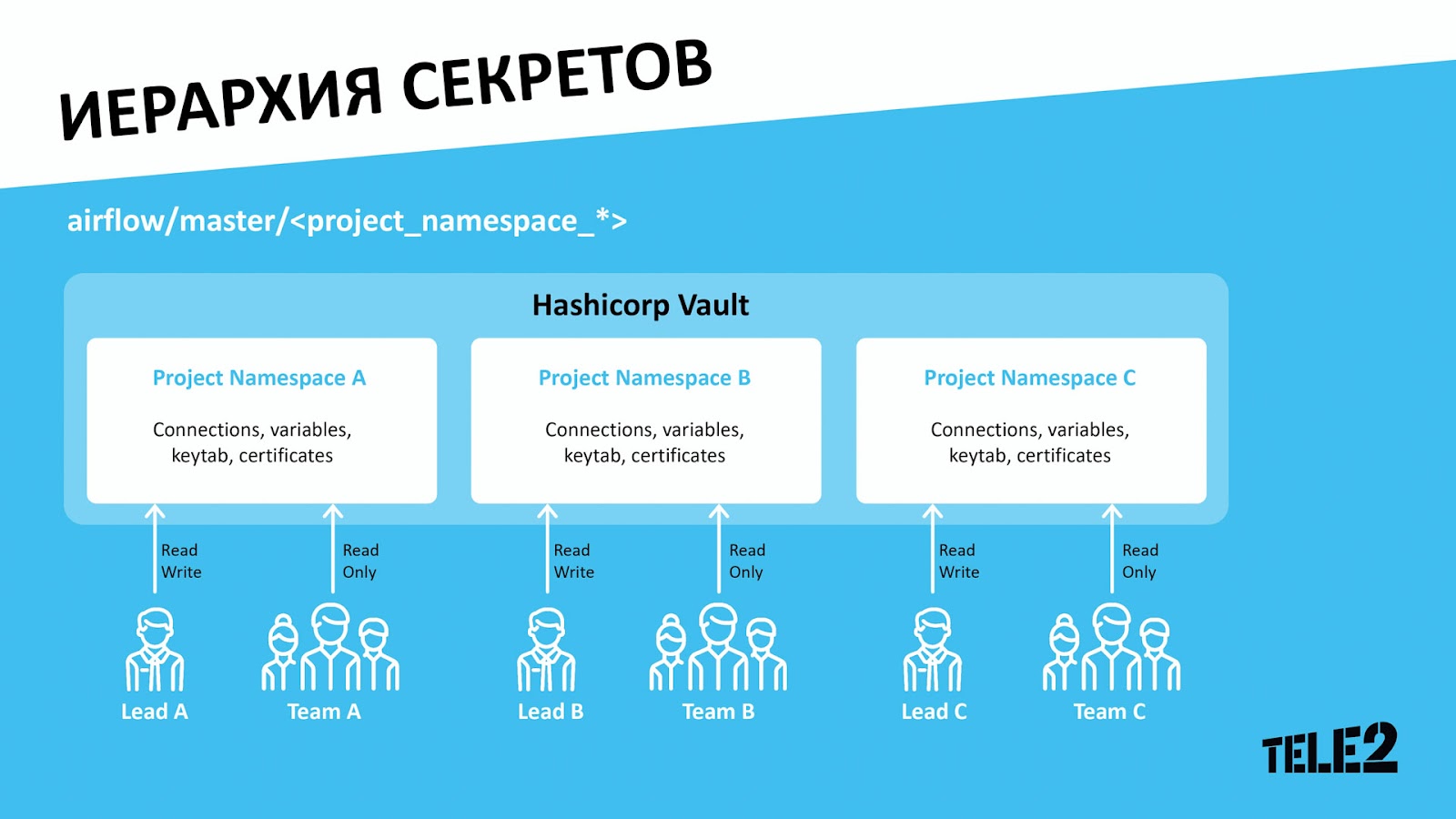
Сперва мы начали со схемы, где у каждого проекта своё пространство секретов: над определённым проектом в gitlab работает определённый отдел разработчиков, и они имеют тот самый накопленный годами пул общих секретов. Такие пространства мы решили хранить в виде airflow/master/название_проекта/ — это путь каталога в vault, и его мы называем проектным пространством хранения секретов. Рядовые разработчики имеют только Read-права на данное пространство, что позволяет им легко посмотреть, куда ведёт та или иная ходка, — изменить её они не могут. Права на изменения выдаются Team Leader’ам, и такой момент устроил всех.
Чтобы пользователь стенда мог подставить свой секрет, мы выделим ему своё пространство по принципу airflow/имя_пользователя / название_проекта. Это пространство будет иметь приоритет над проектным, и если Airflow находит в пользовательском пространстве SecretA, то выбирается именно он, даже если в проектном пространстве также присутствует SecretA. Но, если в пользовательском пространстве данного секрета нет, он будет взят из проектного.
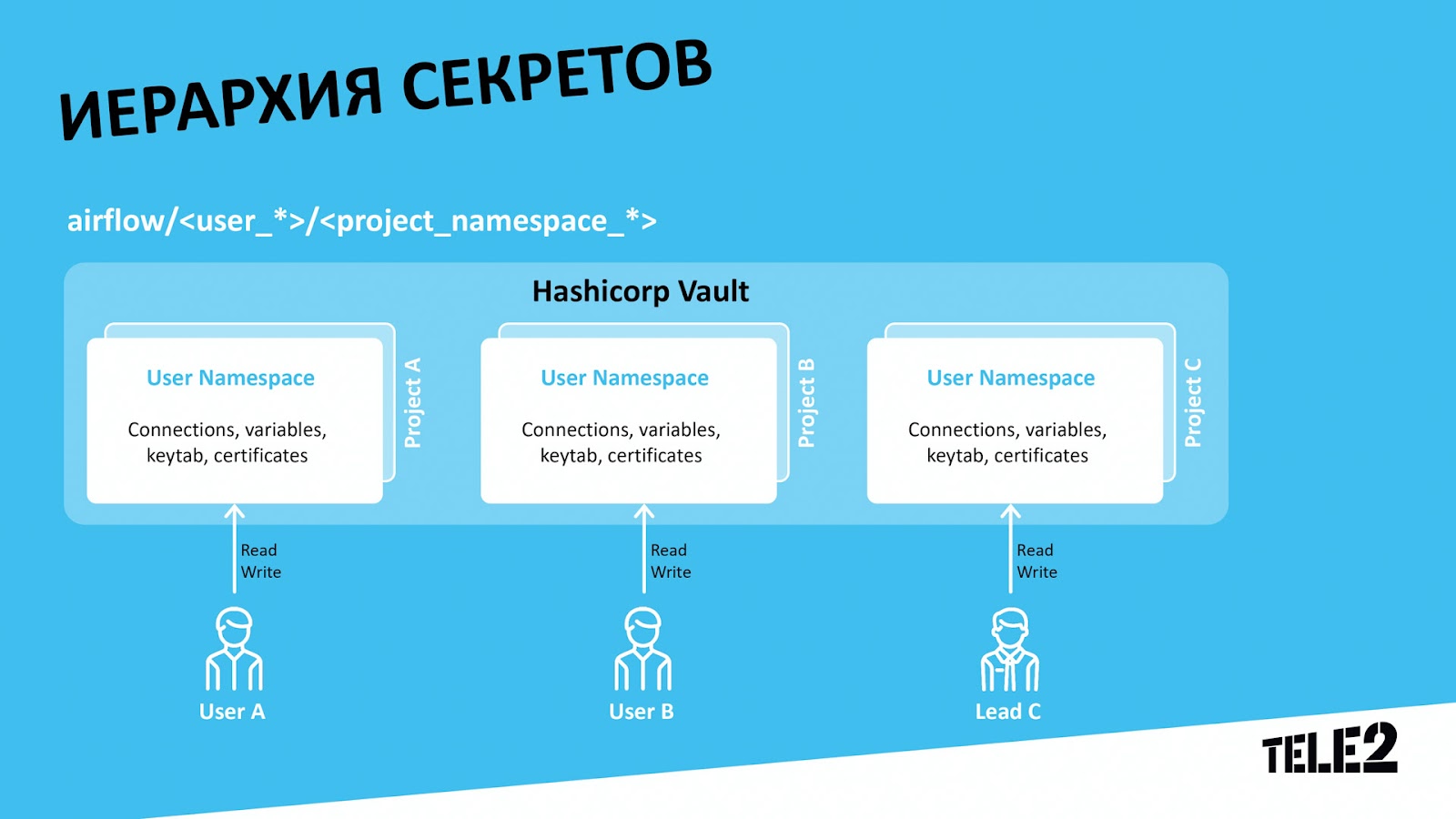
По умолчанию, впрочем, провайдер идёт только по одному пути, строго заданному в конфигурации. Как же нам тогда быть? Как заставить стенд понимать, какому конкретному пользователю он принадлежит? Мы решили этот вопрос так: кто стенд поднимает, тот им и владеет, а учитывая, что в компании доменная авторизация почти на всех сервисах, мы легко можем забрать имя пользователя при деплое и перенести его на наш под Airflow в качестве переменной окружения.

Затем, путём элементарной доработки исходного кода, мы заставляем Vault Backend провайдера ходить сперва на пользовательское пространство и в случае, если там он ничего не нашёл, идти в общее проектное пространство и забирать секрет уже оттуда.
Также Vault очень сильно выручил нас с добавлением небольших секретных файлов, вроде ssh-ключей или keytab’ов, которые мы, по понятным причинам, не хотели хранить в виде configmap’ов или volume’ов в K8s, потому что это шло вразрез с принципами безопасного хранения и SaaS в целом.
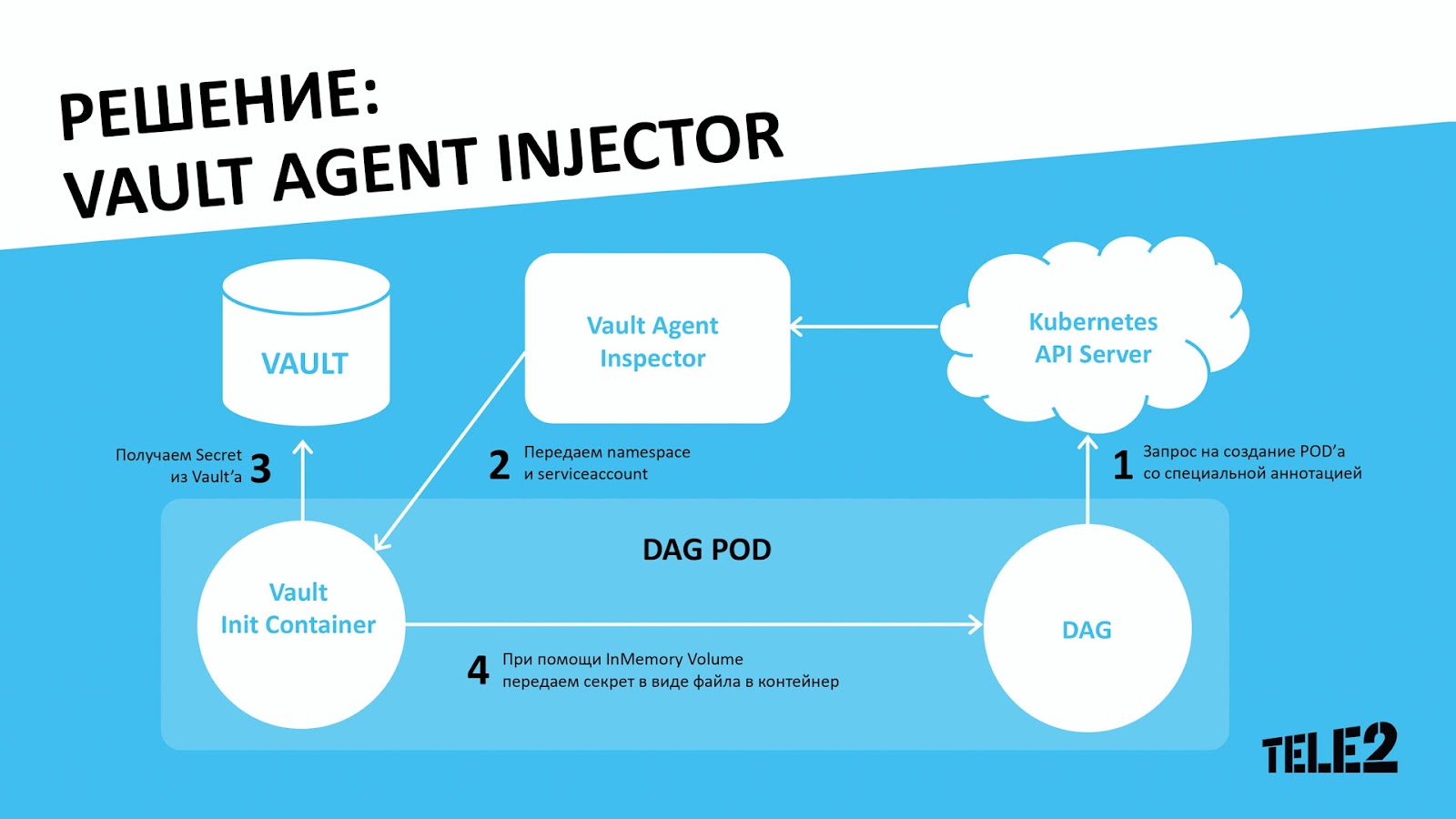
При помощи Vault Agent Injector мы можем добавить init-container, который сходит в Vault, заберёт необходимый секрет и прокинет его как файл в наш образ. И для этого нам всего лишь необходимо при создании пода через K8s_pod_operator просто указать необходимую аннотацию.

Gitlab CI и поветочный деплой
Когда мы определились с большей частью компонентов нашего SaaS, оставалось придумать, как его доставлять до конечного пользователя. В первую очередь отталкивались от того, что разработчики привыкли сами раскатывать новые версии своих DAGов и images до статических стендов, и выбор пал на GitLab CI.
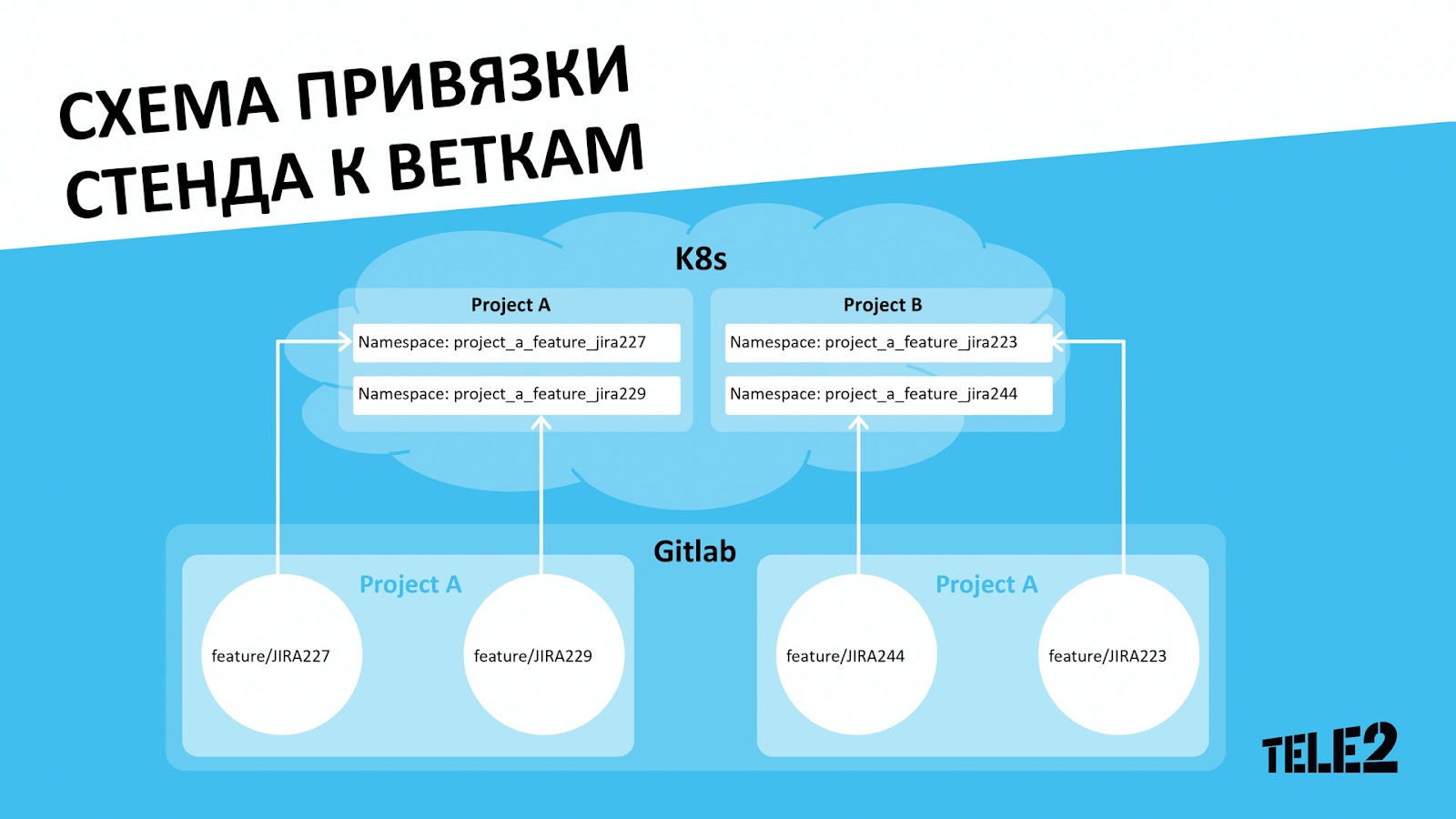
Ещё в самом начале команда решила, что гораздо удобнее делать стенды не под конкретного пользователя, а под ветку в гите, так как периодически возникают задачи, в рамках которых требуется минимум изменений, но проверка может занимать значительное время, и pull таких задач может уходить в одного разработчика/аналитика. Также есть задачи proof-of-concept, которые делаются и тестируются в фоновом режиме.

Стенд представляет из себя неймспейс в K8s, в котором развёрнута официальная helm-поставка Airflow. Решение показалось нам достаточно простым и лаконичным, плюс оно содержало все необходимые шаблоны для разворачивания вариантов как с Kubernetes, так и с Celery Executor’ом. В тот момент, когда мы начинали разработку, чарт ещё не был оптимизирован для версий старше 1.10.12, но при помощи определённых доработок он вполне успешно и по сей день разворачивает нам новые релизы. Например, мы добавили параметр Vault-аннотаций для всех deployment’ов и statefulset’ов, чтобы образы Airflow изначально поднимались с нужными нам секретами из коробки, шаблонизировали template worker pod’а для K8s executor’а, добавили kinit для прокинутых внутрь keytab’ов при старте пода, чтобы это не приходилось делать через DAGи, и ещё несколько мелких и не очень изменений.

Процесс деплоя происходит следующим образом. При коммите собирается артефакт с DAGами, после чего пользователь в gitlab-ci pipeline имеет выбор из трёх кнопок: создать стенд с Celery Executor’ом, создать стенд с Kubernetes Executor’ом или же скопировать на имеющийся стенд свои DAGи.

Ранее мы собирали все наши yaml-конфигурации и DAG-генератор в один zip-архив, после чего передавали его на под с Airflow в папку с DAGами. Если внутри папки уже находился предыдущий архив, он перезаписывался. Это вызывало целый ряд логических проблем, поэтому мы ушли от хранения DAGов в архиве и перешли на вариант с симлинками в директорию с распакованными DAGами.

Технически мы всё так же собираем zip-архив, копируем его на под (в нашем случае в /opt/airflow/dags/), однако сразу же распаковываем его в директорию /opt/airflow/dags/ с timestamp’ом релиза в названии. В директории находится симлинк current (на который и смотрит airflow scheduler), папка с прошлым релизом, на который он нацелен, и с позапрошлым релизом. Мы переключаем симлинк current с прошлого релиза на текущий и удаляем из папки всё содержимое, кроме непосредственно current, текущего и прошлого релизов. Этим решением убиваем двух зайцев: первый — это уверенность в том, что file_processor отработает по старому дескриптору на файле в папке с прошлым релизом, и никто ничего из-под него не выдёргивает; второй — получаем лёгкую возможность сделать rollback неудачного релиза, просто переключив симлинк.

Мониторинг и логи
Логи на момент разработки собирались в Elasticsearch (сейчас в S3) при помощи fluentd, а после вычитывались Airflow при помощи Elasticsearch provider.

Для отправки и хранения метрик стендов мы воспользовались классической связкой: Airflow нативно отправляет метрики в формате StatsD на шлюз, в качестве которого выступает StatsD Exporter, на лету преобразовывающий их в формат Prometheus. Затем происходит scrape данных метрик и их отправка в хранилище.
И пожалуй, единственная проблема, которая у нас возникла при использовании данного решения, — это рандомные дырки в метриках по процессингу DAGов. Баг мы в результате нашли, и фикс законтрибьютили https://github.com/apache/airflow/issues/17513

После того, как мы разделались с получением и доставкой метрик, пришла пора визуализации. Но, зайдя на grafana.com, мы не обнаружили ни одного готового дашборда по метрикам Airflow, отображающего нужные нам показатели… Поэтому тут действовали с нуля и считаем, что вышло неплохо!
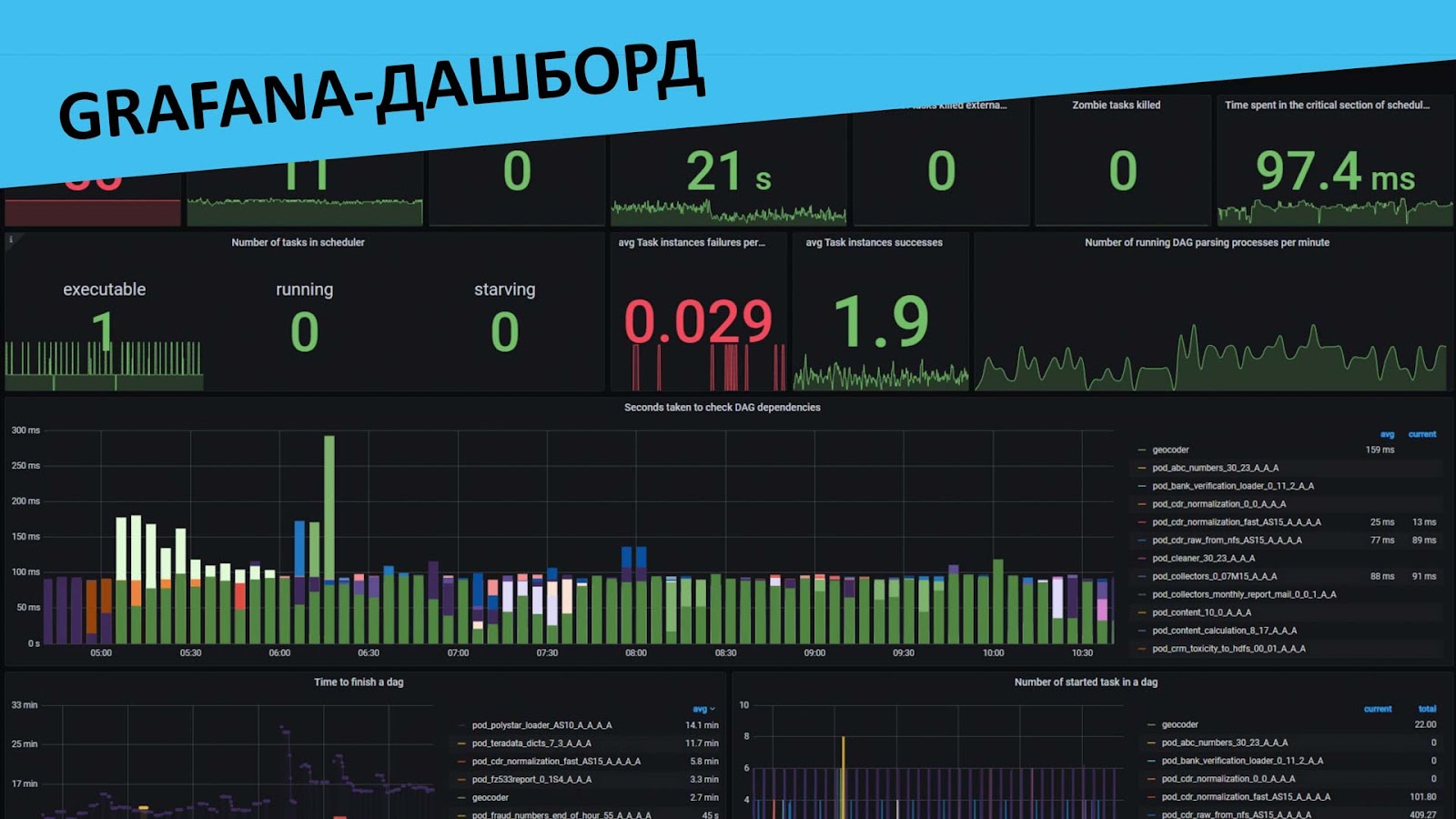
Помимо визуальной картины происходящего метрики также помогли нам выстроить весьма успешный алертинг, который оперативно сообщает о тех или иных проблемах с DAGами, вдобавок к этому при помощи api мы успешно отслеживаем те DAGи, которые остались в queued, но не ушли на исполнение по тем или иным причинам, а также реализовали конечность времени жизни инстанса.

Наш проект предполагает, что множество команд будут деплоить множество же тестовых стендов, ведь каждая ветка разрабатываемого ими проекта может иметь свой стенд. И перед нами встаёт новая задача: как эффективно управлять этими стендами, чтобы после использования они не оставались висеть на железе мёртвым грузом. Тогда мы придумали концепцию «протухания» стенда.
В качестве признака «протухания» мы выбрали метрику в виде времени последнего запуска DAG’a. Таким образом появилось первое правило: любой тестовый стенд живёт не более 25 часов после того, как на нём не осталось DAGов в статусе Running.
Но в работе возможна ситуация, когда разработчик поставил свой DAG на расписание и забыл об этом, в результате чего тест запускается ежедневно и не даёт стенду удалиться. На этот случай было введено второе правило: любой тестовый стенд живёт не более 7 дней, независимо от исполняющихся на нём процессов.
Так как Airflow является мультикомпонентным приложением и все компоненты хранятся в выделенном Namespace, мы пришли к выводу, что для освобождения ресурсов лучшим выходом будет удаление Namespace, в котором он существует.
Для этой задачи такие инструменты, как Liveness probe и readiness probe, не подходят. По этой причине мы используем Kubernetes CronJob, представляющий из себя небольшой контейнер, отправляющий каждые 5 минут запросы к Prometheus для анализа метрик жизненного цикла стенда. В случае, если выполняется одно из условий, указанных выше, то CronJob обращается к API K8s — и весь Namespace удаляется. Такой подход обеспечивает эффективное высвобождение ресурсов и не создаёт проблем разработчикам.

Говоря об освобождении ресурсов, нельзя не упомянуть о нашей реализации временных хранилищ. В этом нам сильно помог выбор K8s в качестве основной платформы для SaaS.
Сразу после запуска DAG’a, в признаках которого указан данный функционал, создаётся Persistance Volume, подключаемый к каждой таске dagrun’a. После успешного или безуспешного исполнения dagrun’а, Airflow посылает callback на API K8s — и Persistance Volume удаляется, освобождая ресурсы хранилища.
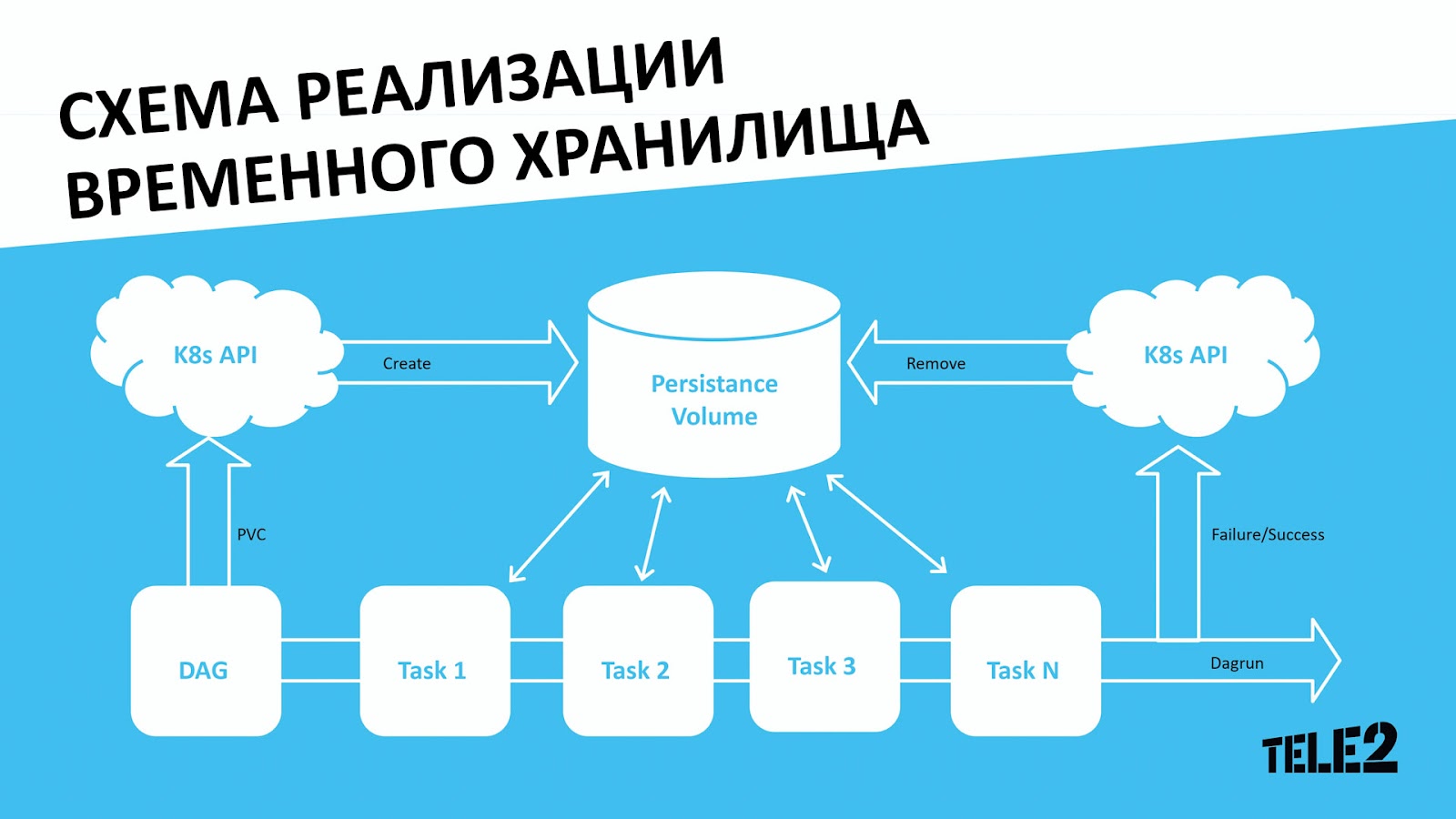
Таким образом, мы получаем временное хранилище для любой задачи без необходимости модифицирования DAG’a, добавления новых тасок и опасности переполнения хранилища. Так мы, конечно, думали, пока не столкнулись с рядом проблем и подводных камней при переезде.
Подводные камни и проблемы
Нам потребовалось доработать штатный K8sPodOperator, заменив DockerOperator, а именно:
Реализовать механику передачи конфигов для спарк-приложений, которые запускаются из отдельного докер-контейнера;
Реализовать поддержку временных хранилищ при помощи PVC.

При вызове DockerOperator и K8sPodOperator все параметры у нас передаются через переменные окружения. В случае со Spark мы передаём ещё дополнительный конфиг, который пробрасывается в само приложение.
В данном примере как раз typesafe_config и будет являться тем дополнительным конфигом, и его в переменную окружения мы передаём в виде base64encoded-строки. Кодирование происходит в самом операторе, что позволяет в конфиге использовать макросы Airflow.
Вторая доработка — это добавление создания вольюмов. Если в описание DAGа добавлены параметры для создания pvc, то в этом случае при запуске кубер-оператора будет создаваться pv, который будет удаляться через коллбеки на DAGе on_success_callback и on_failure_callback.

Но тут нас ждал подвох: при тестировании решения с коллбеками мы наблюдали от нескольких десятков до нескольких сотен неудалённых pv за произвольные промежутки времени, при этом явной корреляции ни с чем мы не наблюдали.

Что происходило:
Процессы, обрабатывающие файлы и исполняющие коллбеки, помещаются в одну и ту же переменную _processors, которая имеет тип dict, где ключом является filepath файла с DAGом.
В процессе получения файлов в директории исполняется функция set_file_paths, которая прибивает процессы по файлам, которых не существует в директории.
Вспоминаем, что у нас всё лежало в рамках одного zip-архива, и мы переопределяли fileloc, в котором хранится путь до файла с DAGом, на путь до yaml-файла, чтобы его можно было смотреть в UI.

На выходе мы ловили моменты, когда в очередь прилетал запрос на исполнение коллбека, он помещался в дикт, где ключом был путь до yaml-файла, и затем происходил рефреш директории с DAGами, в которой лежал 1 zip-архив, и наши коллбеки прибивались в процессе исполнения или вовсе не успевая отработать.
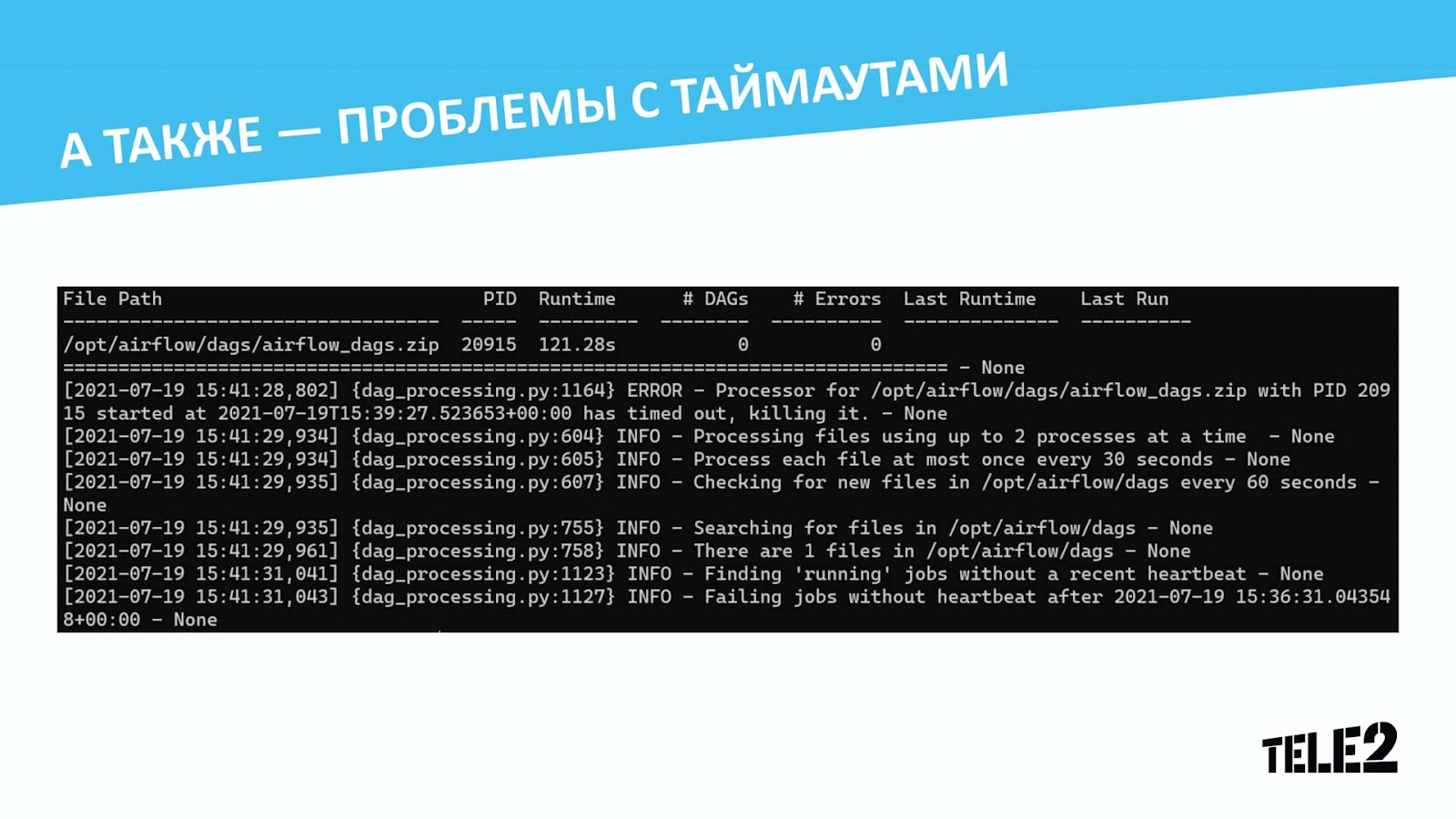
Но наши проблемы не закончились на этом, и с ростом количества DAGов их процессинг перестал укладываться в таймаут, а распараллелить средствами Airflow не было возможности, так как генератор находился в одном файле. Мы пробовали увеличить интервалы для процессинга, но с каждым новым DAGом мы всякий раз начинали упираться в таймаут. При этом иногда ещё беспокоили ошибки с несуществующими коннектами — и в этом случае падала индексация всех DAGов разом.

Поэтому возникшие проблемы мы решили на уровне пайплайна сборки артефактов для деплоя, то есть для каждого yaml-конфига мы начали генерить py-файл с генератором. Так нам ничего не пришлось делать в рамках самого генератора — мы получили независимый парсинг всех DAGов. Это дало нам возможность параллельно парсить DAGи, и проблемы с одним DAGом не влияли на остальные.

Ко всему прочему кардинально выросла отзывчивость интерфейса. Впоследствии мы нашли причину долгого процессинга DAGов и поправили её, ещё ускорив процессинг.
Демонстрация
Результаты проекта Airflow SaaS
Перечислим преимущества, которые мы получили в ходе реализации проекта:
Централизованное хранилище логов.
Все логи Airflow SaaS хранятся в S3, мы можем гибко настраивать глубину хранения и имеем единую PoV.Версионированность Connections и Variables.
Видим, кто, когда и что поменял в тесте или проде, да ещё и безопасность на высоте!Пользователь сам выбирает версию Airflow и набор библиотек.
Есть обязательный набор пакетов — остальное на выбор пользователя. Указал желаемое в CI — через пару минут готовый инстанс.K8s-executor сократил затраты ресурсов.
Для работы не требуется Redis, Worker, Flower.Полная изоляция пользователей.
Пользователи никак не могут помешать друг другу благодаря ресурсным квотам, LDAP-авторизации и «эталонным» секретам.Масштабируемость проекта ограничена лишь ресурсами.
10 «продов» и 75 «тестов»? Не вопрос, только дайте RAM :)Ресурсы больше не простаивают.
Если нет большой нагрузки или огромной кучи «теста», то ресурсы эффективно используются другими сервисами в рамках k8s.Администрирование.
Благодаря автоматизации и подходу IaaC большинство «админских» задач решаются быстро и «по кнопке».Отказоустойчивость Production.
Падение нескольких физических серверов k8s никак не сказывается на процессах.

Благодаря новой инфраструктурной платформе и автоматизации нам удалось сократить время подготовки стенда с человеко-часа до полутора минут. Хотя у нас уже есть идеи, как сделать деплой ещё быстрее.
Мы стали экономить и переиспользовать ресурсы, которые ранее зачастую просто обогревали ДЦ. Общий пул зарезервированных ресурсов сократился в 3 раза по CPU и более чем в 5 раз по RAM.
За счёт всех изменений TTM сократился более чем на час!
Ранее процесс тестирования новых пакетов в составе Airflow или новых версий самого Airflow занимал недели, а иногда и месяцы. Теперь это занимает несколько дней.
Поддержка решения требует от нуля до одного человеко-часа в месяц, если мы не занимаемся внедрением новых фич.
Весь путь переезда на новую архитектуру — от идеи до описанного результата — занял около двух месяцев. Во многом это стало возможным благодаря открытой и незабюрократизированной атмосфере в Tele2, которая позволяет сосредоточиться на задаче. Отдельный респект руководству, которое быстро оценило значимость проекта и выделило необходимые на разработку ресурсы.
P. S. Многое из того, что мы реализовали своими силами, было добавлено разработчиками в новые версии Airflow (хочется думать, что в том числе благодаря нашим контрибьютам), так почему же нам просто не обновиться? Ответ простой: получившаяся конфигурация долгое время удовлетворяла запросы заинтересованных команд, а переезд на новую версию потребовал бы дополнительных ресурсов для отладки логики и багов, поэтому не представляется целесообразным. Но ничто не стоит на месте, и в планах у нас переезд на Airflow 2.6, так что скоро сможем рассказать и про него, а заодно про дагогенератор, переход на S3 и обновления в мониторинге.