
В go нет исключений. Разработчики, начинающие знакомиться с go, часто не знают как лучше всего обработать ошибку, как её отобразить в логах и что с ней делать дальше.
Попробуем рассмотреть все варианты, которые можно встретить в проектах на golang в 2023 году.
Статья больше рассчитана на начинающих разработчиков. Но, надеюсь, и разработчики с опытом сочтут этот обзор полезным и будут более осознанно выбирать стратегию обработки ошибок для своих проектов.
Стандартная библиотека
Основная идея
Начнем обзор с методов работы с ошибками, которые предлагает стандартная библиотека.
В стандартной библиотеке ошибка - это интерфейс с одним методом, который возвращает строку:
type error interface {
Error() string
}Лучше всего подход к ошибкам, который предполагается в стандартной библиотеке можно описать цитатой:
ошибка должна рассказывать историю
Из этого следует несколько простых правил:
сообщение об ошибке должно быть максимально подробным
сообщение об ошибке должно содержать весь контекст для расследования причин ошибки
сообщение должно однозначно характеризовать место возникновения ошибки
Такой интерфейс абсолютно бесполезен, если в зависимости от возникшей ошибки нужно изменять логику работы.
Распространённый пример:
row, err := db.Select("SELECT * FROM dump_data")
if err != nil {
return err
}Большинство драйверов возвращают ошибку sql.ErrNoRows, в случае, когда результат запроса пустой. Как дать знать вызывающему коду, что произошла ошибка sql.ErrNoRows и при этом добавить информацию о месте возникновения ошибки?
Для этого существует функция fmt.Errorf, которая позволяет создавать новую ошибку и с помощью глагола %w добавлять в новую ошибку ссылку на причину. А после мы можем в цепочке ошибок (связанном списке) найти интересующую нас ошибку.
// внутри метода по работе с БД
if err != nil {
if errors.Is(err, sql.errNoRows) {
// меняем ошибку на ошибку из нашего приложения, чтобы слои выше не зависили от пакета sql
// где domain.ErrNotFound = errors.New("not found")
return fmt.Errorf("data not found: %w", domain.ErrNotFound)
}
return fmt.Errorf("get data failed: %w", err)
}
// ------------
// в коде, вызывающем метод по работе с БД
if err != nil {
if errors.Is(err, domain.ErrNotFound) {
return nil, nil // ради примера возвращаем ничего
}
return err
}Проблемы роста
C ростом кодовой базы писать неповторяющиеся сообщения об ошибках становится всё труднее и труднее, да и контекста в ошибках становится больше.
Чтобы однозначно определить место возникновение ошибки, мы можем добавить в ошибку уникальный идентификатор. Например, имя метода, в котором ошибка возникла.
return fmt.Errorf("GetData: error load data is occurred: %w", err)Вроде проблему идентификации места возникновения ошибки мы как-то решили. Но когда кодовая база реально большая, хочется еще бы знать путь вызова, а то не всегда быстро удаеться понять каким путём пошел поток выполнения.
Решение в лоб - будем оборачивать ошибку на каждом уровне.
func DoSomething() error {
// что-то, что приводит к ошибке
if err != nil {
return fmt.Errorf("DoSomething: get data failed %w", err)
}
}
func GetData() (string, error) {
// что-то, что приводит к ошибке
if err != nil {
return "", fmt.Errorf("GetData: get data %w", err)
}
}обычно в go текст ошибки принято писать с маленькой буквы, но в примере выше точно повторяется название метода
Цена скорости
Такая конструкция выглядит, честно говоря, так себе. Нужно постоянно думать о тексте ошибки, не забывать переименовывать при переименовании метода...и т.д.
Почему разработчики go сделали так неудобно? Неужели нельзя было сделать хотя бы нормальный стек-трейс?
Ответ прост - из-за производительности. Операция размотки (получение стека вызовов) стека в go достаточно дорогая (посмотреть подробнее). Поэтому решение собирать / не собирать стектрейс оставили разработчикам.
Приведу бенчмарки из репозитория https://github.com/joomcode/errorx :
name |
runs |
ns/op |
note |
|---|---|---|---|
BenchmarkSimpleError10 |
20000000 |
57.2 |
simple error, 10 frames deep |
BenchmarkErrorxError10 |
10000000 |
138 |
same with errorx error |
BenchmarkStackTraceErrorxError10 |
1000000 |
1601 |
same with collected stack trace |
BenchmarkSimpleError100 |
3000000 |
421 |
simple error, 100 frames deep |
BenchmarkErrorxError100 |
3000000 |
507 |
same with errorx error |
BenchmarkStackTraceErrorxError100 |
300000 |
4450 |
same with collected stack trace |
BenchmarkStackTraceNaiveError100-8 |
2000 |
588135 |
same with naive debug.Stack() error implementation |
BenchmarkSimpleErrorPrint100 |
2000000 |
617 |
simple error, 100 frames deep, format output |
BenchmarkErrorxErrorPrint100 |
2000000 |
935 |
same with errorx error |
BenchmarkStackTraceErrorxErrorPrint100 |
30000 |
58965 |
same with collected stack trace |
BenchmarkStackTraceNaiveErrorPrint100-8 |
2000 |
599155 |
same with naive debug.Stack() error implementation |
По бенчмаркам видно, что сбор стека занимает ~1 мс в среднем при глубине вызова в 100. Цифра приличная, если рядышком у вас нет вызовов базы данных по 100-200 мс.
Кстати, пакет https://github.com/joomcode/errorx позволяет не писать имя вызываемой функции самому.
Когда скорость не важна
Итак, мы разобрались почему разработчики go выбрали вышеописанный подход к работе с ошибками.
Как мы можем упростить себе жизнь, если считаем что 1 мс на сбор стека для нас приемлимо?
Логгирование по месту
Перед тем как начать описывать один из самых популярных подходов в io-bound приложениях давайте разберемся, а где нам нужен стек.
io-bound. определение
IO-bound приложения - приложения, в которых время выполнения io-операций, таких как вызов другого сервера по сети или операция с файлами сильно больше чем скорость работы кода.
Стек нам нужен прежде всего для расследования инцидентов. А первое место, куда мы смотрим при расследовании - логи.
Вот в логах мы и хотим найти стек, а также всю информацию, что происходило в момент инцидента.
Отсюда и идея подхода: а давайте писать всё, что нужно, сразу в лог, а ошибкой пользоваться как маркером, что что-то пошло не так и иногда проверять тип ошибки.
И, к счастью, один из самых популярных логгеров zap умеет добавлять стек-трейс в ошибку.
if err != nil {
// zap.L() - получение логгера по умолчанию
zap.L().Error(
zap.String("msg", "get data failed"),
zap.Error(err),
)
return err
}А еще мы можем сразу добавить в логи максимальное кол-во контекста:
каким пользователем был выполнен запрос
какой запрос был выполнен
какие были права пользователя в момент выполнения запроса и т.д.
При использовании этого подхода нужно принять одно решение: как передавать логгер в место возникновения ошибки.
Существует несколько вариантов:
глобальный логгер
+ везде доступен
- нет доступа к информации из верхних слоев
- придется всегда описывать добавление всего контекста
if err != nil {
zap.L().With(zap.String("request_id", ctx.Value(requestID))).Error(err)
}логгер, как зависимость
добавляем логгер как параметр при инициализации компонента
+ можем добавить в логгер дополнительную информацию для всех вызовов компонента
+ нет скрытого поведения
- нет доступа к информации из верхних слоев
- придется всегда описывать добавление всего контекста
// c - экземпляр компонента приложения
if err != nil {
c.log.With(zap.String("request_id", ctx.Value(requestID))).Error(err)
}логгер через контекст
+ можем добавить в логгер информацию из верхних слоев (см.zap.With)
+ контекст собираем по мере выполнения вызова
- нужно быть аккуратным с передачей ссылочных типов через контекст
// у разных пакетов разная стратегия обработки случая,
// когда логгера в контексте не оказалось
log := zapctx.FromCtx(ctx)
if err != nil {
log.With(zap.String("request_id", ctx.Value(requestID))).Error(err)
}О логгере в контексте замолвим слово
Одно из правил использования контекста гласит:
context.Value() should NEVER be used for values that are not created and destroyed during the lifetime of the request.
Логгер зачастую глобальная переменная, которая инициализируется при старте приложения и через контекст её передавать не рекомендуется.
Однако, в случае zap при вызове метода With мы получаем не сам логгер, а обертку над логгером, которая хранит переиспользуемые поля и только ссылается на ядро логгера, которое непосредственно работает с вводом/выводом. Тем самым время жизни zap.With - время выполнения запроса и мы не получаем проблем с конкурентностью.
Собственный тип ошибок
Еще один подход, который может быть использован для сбора максимально полного контекст ошибки - это собственный тип ошибок.
Наш собственный тип ошибок может хранить максимально полную информацию. А записывать информацию из ошибки в лог мы можем в одной точке, на самом верхнем слое.
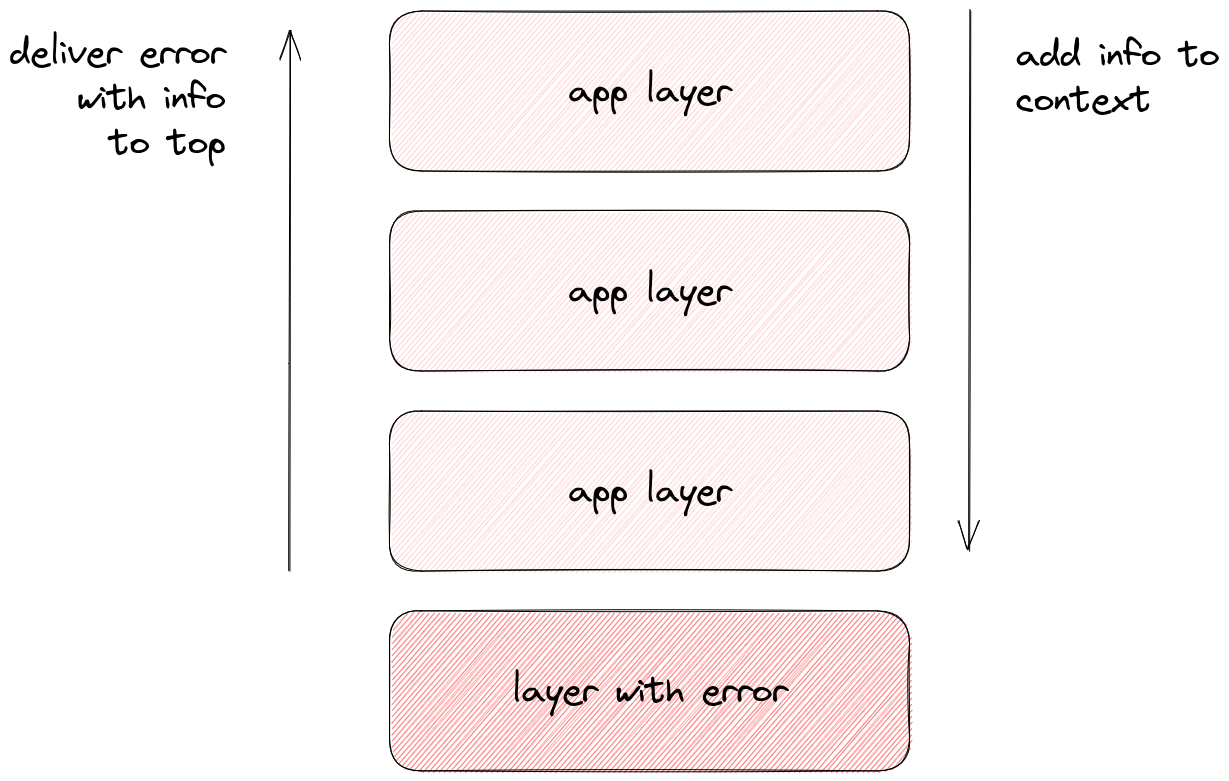
Чтобы создать ошибку со всей информацией о происходящем информацию нужно сначала собрать. А собирать её можно в контексте! Тем самым через контекст мы доставляем информацию о запросе в место возникновения ошибки, а потом ошибку с собранной информацией поднимаем на верхний слой приложения, где она будет обработана.
Приведем пример:
// exerrors - пакет, реализующий этот подход.
ctx = exerrors.WithFields(
ctx,
exerrors.Field("user_id", "123"),
)
exerrors.NewCtx(ctx, "my own msg %s: %w", "any", err)
zap.L().Errorf(err, exerrors.ZapFields(err)...)Такой подход распространён меньше, т.к. для каждого входного адаптера приложения (простите за термины из гексагональной архитектуры), например http, kafka-consumer'а нужно будет писать свой обработчик ошибок. В предыдущем подходе мы логику обработки ошибки писали единожды - в месте возникновения.
Плюс этого подхода в том, что он более привычен разработчикам, пришедшим из других языков.
Библиотек для этого метода почти нет. Оставлю ссылочку на свою реализацию.
Комментарии (24)

mrobespierre
04.07.2023 13:12+2Спасибо за статью. Начали за здравие, а потом...
"Чтобы создать ошибку со всей информацией..." контекст конечно не нужен. Нужно перечитывать вот это снова, и снова, и снова...

GreyCheshire Автор
04.07.2023 13:12+1Предположим ошибка возникает в репозитории при запросе какой-то сущности. Какая информация была бы полезна? ID сущности, возможно какие-то фильтры, если есть. Отлично, это есть всё в параметрах метода. Для этого добра можно создать свой тип ошибки.
А как в месте возникновения ошибки получить request-id, user-id и т.д.? Те переменные, которые совсем не нужны в параметрах функции репозитория, но которые важны? Пробросить их через контекст один из вариантов. И это нужно только в том случае, когда мы на верхних слоях не оборачиваем ошибку. Если оборачиваем, то можем информацию добавить и там.

micronull
04.07.2023 13:12А как в месте возникновения ошибки получить request-id, user-id и т.д.?
В тексте ошибки лучше расширить контекст, чтоб было понятней где именно она произошла, а значения параметров засунуть в лог, где их можно легко отыскать, например в ELK, и полноценно работать с ними.

Borz
04.07.2023 13:12IMHO, контекст лучше обогащать теми же RequestID, UserID и прочими параметрами сразу по факту их появления, а не когда надо в лог закинуть
micronull
04.07.2023 13:12А можно обогатить и закинуть в лог. Если параметров много, то лучше в лог, а в контекст ошибки закинуть только
request_id, например. Это ускорит поиски логов к тому же.Borz
04.07.2023 13:12в лог можно уже из контекста вытащить
micronull
04.07.2023 13:12Под контекстом подразумевается не
context.Context, а текст ошибки.Например
fmt.Errorf("send request by process_id %s: %w", pid, %w)В лог имеется ввиду, добавить в виде параметров, например:
log.Info("some", zap.String("foo", bar))
mrobespierre
04.07.2023 13:12+1А как в месте возникновения ошибки получить request-id, user-id и т.д.? Те переменные, которые совсем не нужны в параметрах функции репозитория, но которые важны?
Не знаю. Я ошибку никогда не обрабатываю в месте возникновения, я передаю её наверх, прям самый верх, "где всё началось". А там обычно доступна вообще вся информация. А репозиторий в итоге занимается только своим делом, не знает, кто и как в нём смотрит.

lanseg
04.07.2023 13:12+1А мне настолько не нравятся эти исключения, что пришлось даже написать реализацию Optional, чтобы избавить себя от вечного "if err != nil { return nil, err }.
Жалко ещё, что нет нормальных дженериков, но, наверное, конструкция языка их не подразумевает

dsh2dsh
04.07.2023 13:12пришлось даже написать реализацию Optional
О! А можно посмотреть? А то мне тоже приходилось своё на эту тему писать, хотелось бы полюбопытствовать, какие ещё варианты на эту тему есть.

demoth
04.07.2023 13:12+1Приведу бенчмарки из репозитория https://github.com/joomcode/errorx:
Тут из-за двоеточия ссылка получается невалидной.
По бенчмаркам видно, что сбор стека занимает ~1 мс в среднем при глубине вызова в 100. Цифра приличная, если рядышком у вас нет вызовов базы данных по 100-200 мс.
По таблице кажется, что худший случай это 0.5мс для наивной реализации. В случае эффективной реализации получается ~4мкс (BenchmarkStackTraceErrorxError100), что уже сложнее сравнивать с IO, мне кажется.
micronull
04.07.2023 13:12-1Недавно как раз записал видео про обработку ошибок в Golang, может кому-то будет полезно)

miga
04.07.2023 13:12+3nit: в тексте ошибки лучше писать что вы делали, а не то, что сломалось, потому что потом после нескольких обертываний получится длинная простыня стенаний: "failed X: error doing Y: cannot Z: ….”
А то что это ошибка в принципе понятно из логлевела, например.

unreal_undead2
04.07.2023 13:12+1В go нет исключений. Разработчики, начинающие знакомиться с go, часто не знают как лучше всего обработать ошибку
И как они раньше на голом C писали...

nightlord189
04.07.2023 13:12-2Почему разработчики go сделали так неудобно? Неужели нельзя было сделать хотя бы нормальный стек-трейс?
Я обычно делаю fmt.Errorf и какое-то описание перед тем как вернуть ошибку выше. Тогда получается что-то такое: "get user error: read id from db error: init db error: something not found". И этой строки в большинстве случаев уже достаточно, чтобы понять, как по цепочке возвращалась ошибка и где именно она произошла, стектрейс необязателен.
GreyCheshire Автор
04.07.2023 13:12Да достаточно, когда сервис маленький. Когда сервис большой и народу в команде много, то люди начинают повторять текст ошибки, за этим приходится следить.
Кроме того по логам или сентри становится невозможно построить аналитику по наиболее частотным ошибкам
dsh2dsh
Вот это вот смешно. Особенно, если учесть, что на самом верхнем уровне, в результате получения ошибки, будет или выход из приложения, или вообще паника. Конечно, скорость тут очень важна.
GreyCheshire Автор
Не для всех приложений. Выход из приложения будет только в случае простеньких cli утилит. А паника, если ошибся разработчик и нужно срочно бежать и править багу (если вы, конечно, не БД где иногда кидают панику, чтобы пропустить все if'ы).
dsh2dsh
Для большинства, я бы сказал. Вы же сами пишете:
И что приложение или сервис в этом случае будут делать? Скорее всего выведут в лог/консоль и сделают
os.Exit()илиpanic(), в зависимости от конкретных требований. Вот об этом и был мой комментарий.GreyCheshire Автор
В большинстве приложений ошибку пробросят на верх в слой контроллеров (если мы про какой-то сервер) и там отдадут клиенту
dsh2dsh
Ну господи, суть-то от этого не меняется. В чем разница в этом контексте с
os.Exit? Что же Вы так буквально понимаете. В обоих случаях работа сервиса прекращается. В одном случае управление будет передано обратно системе, а в другом случае - вышестоящему серверу. Смысл моего комментария в том, что возникновение ошибки - это не штатная ситуация. Т.е. это ситуация, которая возникает гораздо реже, чем не возникает. Т.е. чаще всего такая ситуация не возникает. И в этом случает аргументировать отсутствие стека скоростью - ну такая себе отговорка. Вот о чём был мой комментарий.Вообще, это уже просто комментарий вслух, непоследовательность - это отличительная черта Go. Вот такое у меня мнение сложилось в процессе его использования и в процессе раскапывания issues в их репозитории на github. Те, кто его делал и делает, не заморачивались и не заморачиваются продумыванием наперёд. Такое вот ИМХО.
cat_chi
Нет. И в предыдущем комментарии это сказано прямым текстом
Во многих случаях – вполне штатная. В примере вашего оппонента с клиент-серверным взаимодействием, например.
То есть вы не поняли, о чём пишет ваш оппонент, а непоследовательный – Go :) Ну ладно, ладно... Впрочем, конкретно с этим тезисом я согласен. В Go хватает откровенно странных решений
micronull
Дело конечно же не в скорости. Go это компиляция десятилетнего опыта полученного при создании предшествующих ему технологий и языков программирования, задолго до появления исключений.
Однако не все приложения будут завершаться паникой. Например RestAPI сервис вернёт 500-ю ошибку, запишет в лог и трейс.
cupraer
https://en.wikipedia.org/wiki/UNIVAC_I — 1951 год, первая обработка пробрасываемых исключений.
Go — по признанию самого Пайка — это язык для свеженанятых дурачков, чтобы они не попортили существующую базу кода. Вот прямая цитата:
Не нужно пытаться оправдать плохой дизайн историческими мотивами.