

В первой части этой статьи вы найдете рассказ об эволюции метрик качества машинного перевода, а также об основных традиционных метриках. В Части 2 перейдем к нейросетевым метрикам. Начнем с референсных метрик, расчет которых требует референса – эталонного перевода, обычно выполненного человеком.
С безреференсными нейросетевыми метриками познакомимся уже в Части 3 статьи, там же посмотрим на сравнительную эффективность разных метрик.
Для нейросетевых метрик объектом сравнения выступают не слова, а их эмбеддинги, поэтому для начала пару слов об этом понятии.
Понятие «эмбеддинг»
Эмбеддинг (embedding) – это векторное представление слова, то есть кодировка слова через набор чисел, получаемая на выходе из специальных моделей, анализирующих словоупотребление в больших наборах текстов.
Данный подход был представлен Mikolov et al. в 2013 в работе Distributed Representations of Words and Phrases and their Compositionality. Алгоритм получения эмбеддингов, представленный Mikolov et al., известен как Word2Vec.
Впоследствии был создан ряд других алгортимов для получения эмбеддингов, например: GloVe, fastText, doc2vec, ELMo, BERT.
Под катом – пара видео для понимания сути эмбеддингов.
Видео о понятии «эмбеддинг» от Эндрю Ына:
Видео о свойствах эмбеддингов – от него же (Эндрю Ын крут!):
Референсные нейросетевые метрики
После появления эмбеддингов стали возникать метрики, которые оценивают уже не лексическое, а семантическое сходство машинного перевода с эталонным (грубо говоря, не совпадение слов, а совпадение смыслов).
Все метрики, сравнивающие эмбеддинги, можно считать нейросетевыми, поскольку сами эмбеддинги получают в результате обучения различных моделей.
Общая логика развития нейросетевых метрик изложена в Части 1 этой статьи. Здесь рассмотрим наиболее известные из референсных нейросетевых метрик.
WMD
WMD (Word Mover’s Distance) – метрика, предложенная Kusner et al. в 2015 для оценки семантической близости текстов. Расчет этой метрики основан на оценке близости эмбеддингов слов, полученных при помощи алгоритма Word2Vec.
Близость двух предложений – сгенерированного моделью и эталонного – оценивается при помощи Earth mover’s distance (EMD) для эмбеддингов слов, составляющих эти предложения. Вычисление EMD тесно связано с решением оптимизационной транспортной задачи.
ReVal
ReVal (Gupta et al., 2015) считается первой нейросетевой метрикой, предложенной непосредственно для оценки качества машинного перевода.
Вычисление данной метрики выполняется с использованием рекуррентной (отсюда и название метрики) нейросетевой модели LSTM, а также вектора слов GloVe.
ReVal существенно лучше коррелирует с человеческими оценками качества перевода, чем традиционные метрики, но хуже, чем более поздние нейросетевые метрики.
BERTScore
BERTScore – метрика, предложенная Zhang et al. в 2019 для оценки качества генерируемого текста. Основана на оценке близости контекстных эмбеддингов, полученных из предобученной нейросетевой модели BERT.
Для расчета BERTScore близость двух предложений – сгенерированного моделью и эталонного – оценивается как сумма косинусных подобий между эмбеддингами слов, составляющих эти предложения.
Под катом – видео о BERTScore.
Подробнее о BERTScore
YiSi
YiSi – это метрика оценки качества машинного перевода с гибкой архитектурой, предложенная Chi-Kiu Lo в 2019. YiSi может оценивать как базовую общую близость машинного и человеческого переводов, так и принимать в оценку анализ поверхностных семантических структур (опционально).
Как и для BERTScore, расчет базовой близости в YiSi основан на оценке косинусных подобий между эмбеддингами, полученными из модели BERT.
Семантические парсеры, используемые авторами YiSi – это mate-tools (Bjorkelund et al., 2009) и mateplus (Roth and Woodsend, 2014).

BLEURT
BLEURT (Bilingual Evaluation Understudy with Representations from Transformers) – еще одна метрика на базе embeddings из BERT, предложенная Sellam et al. в 2020 для оценки качества генерации текста.
Для целей расчета BLEURT модель BERT была дообучена на:
cинтетическом датасете в виде пар предложений из Wikipedia;
открытом наборе переводов и присвоенных им человеком рейтингов из WMT Metrics Shared Task.
Расчет метрики BLEURT выполняется нейросетевыми методами.

Prism
Prism (Probability is the metric) – метрика качества машинного перевода, предложенная Thompson, Post в 2020 на базе их собственной мультиязычной модели-трансформера Prism.
Авторы отметили сходство задачи оценки близости машинного перевода к эталонному и задачи оценки вероятности парафраза. В качестве оценки принята вероятность такого парафраза, при котором эталонному переводу (выполненному человеком) соответствовал бы текст машинного перевода.
Учитывая данный подход, для обучения модели не потребовалось использовать человеческие оценки качества перевода.

COMET
COMET (Crosslingual Optimized Metric for Evaluation of Translation) – метрика, предложенная Rei et al. в 2020 на базе собственной модели и целого фреймворка для тренировки других моделей оценки качества перевода.
COMET использует в качестве энкодера мультиязычную модель XLM-RoBERTa, поверх которой добавлены дополнительные слои, на выходе которых – оценка качества перевода. Модель принимает на вход не только машинный перевод (hypothesis) и эталон (reference), но и переводимый текст-первоисточник (source).
Модель обучена на триплетах данных hypothesis-source-reference, а также рейтингах перевода, данные человеком (из WMT, как и для BLEURT). Обучение выполнено путем минимизации среднеквадратического отклонения (Mean Squared Loss, MSE) оценок, данных моделью, от истинных рейтингов перевода.

UniTE
UniTE (Unified Translation Evaluation) – метрика, предложенная Wan et al. в 2022 на базе собственной модели. Как и COMET, UniTE использует энкодер XLM-RoBERTa, c дополнительными слоями.
Архитектура UniTE предусматривает возможность подать на вход одну из следующих комбинаций: 1) машинный перевод и эталонный перевод, 2) машинный перевод и первоисточник, 3) все три вида данных.
В отличие от COMET, где энкодинг каждого из входов выполняется отдельно, в UniTE reference, prediction и source кодируются совместно, и уже в виде единой структуры поступают в расчет оценки качества перевода. В версии UniTE-MRA задействован механизм внимания.
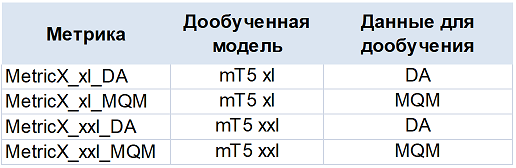
MetricX
Эта серия метрик официально не задокументирована, однако была представлена для тестирования в рамках WMT Metrics Shared Task и показала себя достаточно хорошо. Данная серия стала результатом дообучения нескольких версий большой языковой модели mT5 на разнообразных данных о человеческой оценке качества перевода (о типах данных DA – direct assessment и MQM – Multidimensional Quality Metrics – подробнее расскажу в Части 3 этой статьи).
Заключение
Мы рассмотрели наиболее известные референсные нейросетевые метрики. Они, как правило, лучше коррелируют с человеческой оценкой качества перевода, чем традиционные, однако имеют и свои недостатки. В первую очередь, это необъяснимость тех или иных оценок, поскольку нейросетевые расчеты выполняется по принципу «черного ящика». Также отметим более высокие, по сравнению с традиционными метриками, требования к вычислительным ресурсам.
Есть и еще один класс нейросетевых метрик, заслуживающий отдельного рассмотрения. Это безреференсные метрики, расчет которых не требует эталонного перевода, выполненного человеком. Этому классу метрик будет посвящена Часть 3 нашей статьи. Также в Части 3 мы, наконец, узнаем, какова сравнительная эффективность различных традиционных и нейросетевых метрик.