

Технологии распознавания печатного текста появились около 30 лет назад, существенно облегчив жизнь и ускорив многие бизнес-процессы. В то же время распознавание курсива оказалось куда более сложной задачей, которую удалось решить лишь благодаря развитию нейросетей.
В этом посте рассказываем о собственной технологии Content AI — распознавании русского рукописного текста, которая уже вошла в новую версию нашего продукта ContentCapture — универсальную платформу для интеллектуальной обработки информации.

Почему так долго
Еще в 90-х наши технологии научились распознавать рукопечатный текст и постепенно охватили большой набор языков. С рукописным текстом все оказалось намного сложнее. Решения, подходящие для распознавания печатного и рукопечатного текстов, недостаточно корректно работали на рукописном. Проблема заключалась в том, что классические методы, в которых распознается каждый символ отдельно, плохо применимы к произвольному рукописному тексту, т.к. машине (да и порой и человеку) сложно понять, где начинается один символ и заканчивается другой. Нужно было найти другой подход.
Кроме того, мир не был готов к распознаванию рукописного текста и технически: обучение современных сетей требовало таких вычислительных мощностей и объемов памяти, о которых еще 10 лет назад можно было только мечтать. А менее требовательные решения с точки зрения затрат на обучение и работу не смогли показать хороший результат.
Помимо роста мощностей, решающее значение оказала эволюция архитектур нейросетей. К примеру, развитие рекуррентных нейросетей (прежде всего LSTM) позволило впервые добиться практически приемлемого распознавания рукописного текста. Затем широко прогремела архитектура Трансформер, да и в целом в сфере нейросетей произошло много всего интересного. Однако продакшн поспевает за таким стремительным развитием с заметным отставанием, поэтому, например, у нас распознавание английского и немецкого рукописного появилось только в 2022 году.
Зачем распознавать рукописный текст
Функция распознавания текста — в целом очень полезная штука, которая помогла не только оцифровать многочисленные архивы, но и заметно улучшить, ускорить и автоматизировать многие бизнес-процессы: одобрение кредита за 3 часа, ответ техподдержки в течение 10 минут или денежные переводы за 2 секунды. Распознавание рукописного текста — еще одна ступень в этом направлении, которая откроет новые возможности в реализации полезных фич для бизнеса и пользователей.
К примеру, во многих документах, используемых в документообороте компаний, или паспортах до сих пор встречаются поля с рукописным текстом — адрес прописки, личные данные, даты в договоре на какие-либо услуги. И распознаются они заметно хуже печатной или рукопечатной информации. Для тех же банков, которые ежедневно обрабатывают тысячи паспортов и различных документов, наличие такой функции поможет заметно ускорить многие процессы и в целом улучшить качество обслуживания клиентов.

Особенности распознавания курсива
Курсив удалось «взломать» благодаря смене модели распознавания: перейдя от посимвольного распознавания текста к пониманию контекста вокруг символа. Иными словами, рукописный текст распознается на уровне отдельных слов, их небольших групп или фрагментов. Кстати, изначально такое End-to-end распознавание появилось в наших технологиях для распознавания печатного текста для некоторых непростых языков (например, арабского).
Сложность обучения модели для распознавания рукописного текста заключалась в требовании большого количества данных, поскольку вариантов рукописного написания — широкое разнообразие — сотни тысяч текстовых фрагментов в 1-3 слова. Также требуется больше времени на разметку корпуса текстов или наличие готовых датасетов с лицензией, разрешающей коммерческое использование.
Еще один важный нюанс — для достижения хорошего результата распознавание и языковая модель должны быть плотно интегрированы, поскольку во многих случаях выбор между вариантами результата распознавания может быть определен только из языкового контекста.
Как мы боролись за русский курсив
С начала текущего года команда Content AI плотно занялась разработкой технологии по распознаванию русского рукописного текста.
Изначально мы решили протестировать ту же архитектуру нейросети, которая уже успешно применялась для распознавания английского рукописного. Результат получился приемлемым для использования в ряде сценариев, но все-таки содержал немалое количество ошибок, поэтому технология особо бы не ускорила работу пользователя по сравнению с ручным вводом данных.
Тогда решено было перейти на более современную архитектуру, заодно сменив фреймворк NeoML на PyTorch. И с таким подходом нам удалось добиться существенно лучших результатов.
В нашей технологии используется архитектура типа энкодер-декодер. В качестве энкодера — Visual Transformer, в качестве декодера — хитрая система, работающая как ансамбль трансформеров, которые шарят веса друг друга.
Модель обучалась на разных типах документов, в которых есть специальные поля для заполнения информации от руки: документы, удостоверяющие личность, платежные поручения, накладные, путевые листы, европротоколы при ДТП и пр. Кроме того, модель обучена числам, датам, суммам, адресам, именам собственным, знает знаки препинания и сокращения.
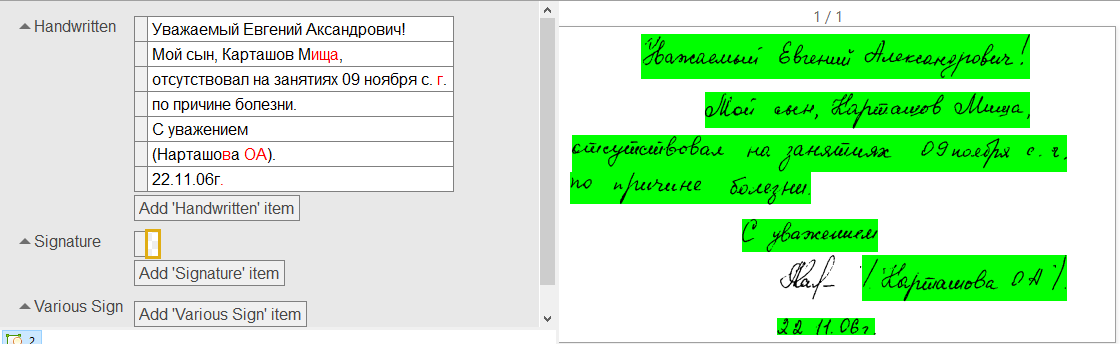
Схематично распознавание русского рукописного можно описать так.
Технология в целом построена на распознавании небольших фрагментов текста, длиной до 30 символов. Сначала сеть семантической сегментации находит в документе фрагменты рукописного текста и линки между ними. Затем каждый фрагмент поступает на вход обученной нами нейросети для распознавания.
На выходе выдается таблица вероятностей, в которой указано, с какой вероятностью в конкретном месте находится именно этот распознанный символ. Далее эта таблица обрабатывается теми же алгоритмами, что используются при распознавании печатного текста, и выдается финальный вариант распознанного текста. Если технология не уверена в распознавании каких-то символов, то на выходе подсветит их красным цветом, чтобы пользователь смог указать корректный вариант.
В целом количество неуверенных распознаваний должно свестись к минимуму из-за встроенного в нейросеть механизма внимания (Attention), который работает на локальном контексте (на уровне одного фрагмента). К примеру, в скане есть фрагмент «кто в лес, кто», где предлог «в» затерт. По контексту сеть безошибочно поймет, что имеется в виду, и выдаст при распознавании верный вариант. Без этого механизма нейросеть выдала бы что-нибудь в духе «кто 88 лет, кто».
Также мы обучили нейросеть распознавать «мусорные фрагменты». Иными словами, если попробовать распознать закорючки или фон вокруг слова, то нейросеть не будет пытаться подобрать для них приемлемый существующий в языке аналог, а выдаст пустую строку.
Качество распознавания
Показатель качества распознавания рукописного текста сильно зависит от типа документа и разборчивости почерка. К примеру, если сравнить качество распознавания двух первых страниц паспорта, то оно может быть разным, т.к. на первом развороте, как правило, данные написаны каллиграфическим почерком, а на втором, поле с пропиской, — как получится. По этой причине процент качества посимвольного распознавания русского рукописного нашей технологией в определенных типах документов мы обозначили в пределах 85-95%.

Если говорить о более конкретных цифрах, то тест на датасете рукописного текста от лаборатории ШИФТ ЦФТ на Kaggle показал качество распознавания нашей модели в 78,0% пословного распознавания и 95,1% посимвольного распознавания.
Кстати, помимо разработки технологии для распознавания русского рукописного, мы также по аналогии усовершенствовали предыдущую модель распознавания английского рукописного текста (он тоже поддерживается в ContentCapture). Тесты говорят сами за себя: если раньше word accuracy составлял 83,7%, то сейчас — 89,6%.
Что дальше
На ближайшую перспективу, помимо работы с обратной связью от клиентов, мы видим два направления развития технологии. И возьмемся за них, если получим соответствующие запросы от бизнес-сообщества.
Первое. Улучшение выделения строк для многострочных текстов. Сейчас технология может распознать многострочные тексты, однако разделение на отдельные строки выполняется полностью корректно в случае большого межстрочного интервала и ровного построчного написания текста, тогда как на практике во многих рукописных текстах строки слипаются, а текст пишется под наклоном.
Второе. Поддержка смешанного распознавания текста для русского и английского языков, например, «автомобиль Lexus». Сейчас каждая отдельная строка распознается только одним выбранным пользователем языком, поэтому если в документе встречаются два языка, то пользователю необходимо вручную переключить способ распознавания.
Комментарии (22)

klirichek
24.07.2023 12:50+1Можно к "тотальному диктанту" сделать сторонний проект - сканируем все диктанты участников. Образцовый текст диктанта есть!
(можно очень вскользь просмотреть глазами, или даже не просматривать, а сразу обучать модель. Можно в анкету участника вставить текст согласия на обработку диктанта машинными методами).А ещё (на тему примеров) вспоминаю одноклассницу Лену Мишину. (как была фамилия подписана в тетрадках представляете, да?)

ContentAI_Team Автор
24.07.2023 12:50+1Решили поэкспериментировать с именем вашей одноклассницы. Вот что вышло:

klirichek
24.07.2023 12:50Лена хорошо училась! Писала, как в классической прописи. Поэтому самый похожий - первый вариант, только у него Л и М не "по прописи". По факту она выписывала букву М, потом семь абсолютно одинаковых крючков, и в конце "на".


da-nie
24.07.2023 12:50А метрики 18-19 веков тоже может прочесть? :)

Mitya78
24.07.2023 12:50Такие документы обычно заполняли хорошим почерком. Приноровиться надо.
da-nie
24.07.2023 12:50Увы, нет. Такие документы часто заполняют таким почерком, что непонятно ничего.
Вот, например, метрика 1769 года. Написана скорописью. И тут ещё можно даже прочесть. А бывает, что можно только догадаться, что написано. :)
А вот, например, из ревизской сказки 1762 года.

Тут написано:
А именно
Во дворе я Леон Петров сын Трунов.
У меня жена Ульяна Антонова дочь тридцати лет. Взята Полатовского уезда села Фощеватого у однодворца Никонова (?).
У меня дети рождённые после ревизии:
Семион.
Мирон.
Никита.
Сестра родная девка Марфа четырнадцати лет.
В бывшую ревизию написан в тайном (?) отделе (?) села здесь (?) Иваном Труновым.
И вот фиг разберёшь, правильно я прочёл слова с "?" или нет.
Akon32
24.07.2023 12:50Шрифт несовременный, грамматика с ошибками (или тоже несовременная). Заучить начертание букв - и дело пойдёт.
da-nie
24.07.2023 12:50+1Ах, если бы… Каждый писец писал по-своему.
Вот примеры написания:
А ещё, часть букв пропускается часто. Или вообще над словами написана, как в ревизской сказке выше.
Akon32
24.07.2023 12:50Чуть ли не половина букв имеют греческие начертания, интересно.
Я когда-то писал в конспектах "д" как "Δ" для быстрой записи, оказывается, всё придумано раньше)
ContentAI_Team Автор
24.07.2023 12:50Мы не ставили перед собой такой цели, поэтому можем предположить, что сейчас с такими текстами работать будет плохо, хотя бы потому что это специфические документы, и сеть их никогда не видела. При этом техническая возможность доучить сеть конечно есть.
Напишите нам в личку, если перед вами стоит такая задача, обсудим вопрос более предметно :)




niccolo2019
24.07.2023 12:50Товарищи из КонтентИИ/Абби — вы в FineReader/FinePDF до ума не довели распознавание/исправление/сохранение (возможности пакетного исправления типичных ошибок распознавания незнакомых слов нет, последняя версия из-за структуры пакета на куче ядер и SSD в режиме постраничного исправления/перераспознавания/правки работает медленнее старой версии на XP с HDD, версии не поддерживают импорт пакетов старых версий с исправленными вручную результатами распознавания (это примерно как если бы ворды 2007-2021 не поддерживали doc), планов развития продуктов нет, продукты бросаются, а потом пользователи посылаются в пешее эротическое, из-за того, что версии больше 3 лет уже, бумажные анонсы которые не доходят до выпуска и т.д. и т.п.
Предлагаете верить вашим сказкам (красивым демкам) тут, учитывая всё то разнообразие человеческих почерков, которые встречаются? Смешно и наивно... Даже в рамках одной организации при смене ручных составителей документации, где это практикуется, будут возникать большие проблемы.....
И я так понимаю, что ограничена эта вещь пока чисто определённым набором стандартных документов, написанных узким кругом людей, более/менее правильным рукописным почерком.... Поле с пропиской в паспортах - это образец по сравнению со старыми метрическими записями, да и с учётом наличия географической информации о населённых пунктах, можно сказать вообще не является проблемой.....
Еще одной проблемой станет практическая трудность коммерциализации, т.к. сегодня с рукописными документами сталкиваются единицы, и часто это попытки углубиться в генеалогию....ContentAI_Team Автор
24.07.2023 12:50ContentReader — одно из лучших решений для редактирования PDF и OCR на рынке, как по набору возможностей, так и по качеству их реализации. Конечно, всегда есть к чему стремиться, и ошибки по ходу разработки в том числе и мы, конечно, совершали.
Что касается рукописного текста: замеры качества распознавания, на которые мы полагаемся, проведены на выборке из разнообразных рукописных документов, которые написаны разными людьми, разным почерком. Решение ContentCapture, в которое встроено распознавание рукописного, служит для автоматизации ввода данных из потока документов, и результаты, про которые мы говорим, это то, что можно ожидать на таком потоке.
niccolo2019
24.07.2023 12:50ContentReader — одно из лучших решений? Да вы смеетесь. Хотя наверное нет... Вспоминая анонсы Finereader, Lingvo - там в каждой версии всё становилось лучше на десятки процентов, правда, что лучше, где лучше так никто и не понял...
Скажите, сколько лет вы занимались приведением в нормальный вид различных PDF? Какого типа, на каких языках, с какими проблемами и целями?
В этом деле нет лучших программ. Есть программы, в которых какая-то полезная функция реализована лучше...
Если бы лучшая программа была - все другие бы уже умерли....
Я недавно направил вам пример - попробуйте привести в нормальный вид True PDF Медицинский словарь Dorlands, 32 изд.
(добиться правильного распознавания буллетов, делящих слова на слоги и делающие невозможным поиск, апострофов в транскрипциях и примерах, которые почему-то в любом режиме (извлечения текста или распознавания картинки, распознаются верхнеиндексными нулями),
разобраться, почему между текстом разного формата и цвета часть абзацев непонятно с чего заменяется на разрывы строки и т.д. и т.п., места не хватит перечислять)
Ваши разработчики откроют для себя много нового о том, что раньше им казалось лучшим....Я так понимаю поиск/замена по кругу, а не отдельно вперёд/назад, поддержка регвыров/оформления текста и пакетной замены несловарных слов/типичных ошибок настолько трудны для реализации, что за 30 лет «развития» программы так и не были реализованы?
Сохранение блоков при обработке картинок в редакторе вы соизволили сделать частично (только для простейших операций редактирования изображений) ТОЛЬКО В 16 версии, после указания на это с выхода 9!!!! версии.
(Если раньше она вам была не нужна, после того как начиная с 9 версии ластик уехал в редактор изображений (««««грамотнейшее»»»» решение) - ВЫ ПРОСТО СОВСЕМ НЕ ПОЛЬЗУЕТЕСЬ ПРОГРАММОЙ ДЛЯ РЕАЛЬНОЙ РАБОТЫ, А ВАШИ ТЕСТ ПАТТЕРНЫ ДАВНО И БЕЗНАДЁЖНО УСТАРЕЛИ).
И мне даже интересно, как, не имея опыта в использовании своей программы, не используя её постоянно для решения РАЗНООБРАЗНЫХ задач: а) вы можете правильно её оценить б) вы можете её улучшать?Касательно качества реализации - сравните свои опции подготовки/обработки/сохранения сканов/pdf своих поделок, типа встроенного граф. редактора FinePDF с возможностями SkanKromsator.
Я как-то знатно удивился недавно, решив добавить текст в 40 МБ PDF, сделанный в кромсаторе.... FR15 стал моим чемпионом - 600 МБ - вот это КАЧЕСТВО РЕАЛИЗАЦИИ. Уважаю.
В данном случае вы, видимо, как и Филиппов в Карнавальной ночи про звёздочки коньяка, считаете, что больше - это лучше. Разочарую вас - это не так.Касательно русских PDF с кривым маппингом - тоже не вижу у вас адекватного решения, когда нужно на 100% сохранить оригинальный текст со вставками греческого, латиницы, Symbols, а не разрушить это всё распознаванием.
Вроде компания то ли русская, то ли с русскими корнями - а проблема так и не решена, хотя по релизам одни сплошные улучшения.....Несовместимость версий вниз даже по РУЧНОЙ РАБОТЕ - наложению блоков - это вообще как?
Удивляюсь, что никто из корпоративных заказчиков с зоопарком версий FR до сих пор не настучал вам по голове.Что касается рукописного текста:
Какие типы документов в вашем обучающем датасете? (Школьные тетради, паспорта, ТЕХНИЧЕСКИЕ конспекты со вставками латиницы и греческого, личные/судебные дела, врачебные выписки с латинскими вставками)
Сколько конкретно видов почерка/человек? (10-20-10000)
На каких языках?С Леной Мишиной результат приятно удивляет, хотя Леня и Мишина - это ваш хвалёный ИИ сочетает мужское имя и женскую фамилию?
Касательно генеалогической информации - Огромнейший пласт этой информации по западным районам Российской империи был оцифрован, частично распознан или перенабран вручную американскими мормонами и выложен на сайте https://www.familysearch.org
А сколько еще неоцифрованного в наших архивах - трудно представить.

andreishe
24.07.2023 12:50Кроме того, мир не был готов к распознаванию рукописного текста и технически: обучение современных сетей требовало таких вычислительных мощностей и объемов памяти, о которых еще 10 лет назад можно было только мечтать.
Да ладно, 10 лет назад распознавание рукописного текста на конвертах для чтения адресов во всю дурь использовалось на американской почте.

Wesha
24.07.2023 12:50распознавание рукописного текста на конвертах для чтения адресов во всю дурь использовалось на американской почте.
Неафроамериканцы тогда недорого ценились.

Zara6502
24.07.2023 12:50в 1999-2001 году примерно был в Минске в командировке, общался с одним программистом, с которым мы в основном говорили про Wavelet, но он показывал еще свои наработки по распознаванию рукописного ввода, который например сейчас в смартфонах есть и весьма неплохой. А позже, году в 2007 я на КПК Acer N50 ставил софтину, что-то типа записной книжки, русского ввода она не умела, но вот на английский весьма бодро реагировала и распознавала влёт. Какие там у XScale мощности были? Ну и 2007 это уже эпоха AMD x64 и оптеронов, у нас в банке блейды стояли по 4 ляма баксов. Так что техника в 2013 была куда более производительнее, не знаю откуда авторы 10 лет взяли как отметку, там уже правил балом Ivy Bridge, который и сегодня живее всех живых.
ContentAI_Team Автор
24.07.2023 12:50А 30 лет назад, когда только пошли первые ПК, появились первые OCR для печатного текста :)
Здесь главный вопрос в качестве (эта оговорка есть дальше по тексту), которое даже для печатного текста до сих пор улучшается.
А про американскую почту есть любопытная статья, где в том числе рассказывается про качество распознавания: https://habr.com/ru/companies/timeweb/articles/709240/
Zara6502
у меня есть рукописи родственника, пытался сам печатать, получается по странице в неделю, пока отложил в долгий ящик. отсюда вопрос - о чем именно представленном на вашем сайте вы говорите и есть ли модели оплаты чтобы я за 100 страниц не снимал последние штаны и не продавал почку?
ContentAI_Team Автор
К сожалению, пока технология работает только внутри нашего продукта ContentCapture, который предназначен для потоковой обработки документов в масштабах организации. Распознавать произвольные рукописные тексты наша нейросеть умеет, но пока в массовые продукты такая фича не вошла.
Zara6502
если что я не умею ставить минусы, спасибо за ответ.
SchwarzFuchs
Могу посоветовать самостоятельно переобучить ru модель для Tesseract. Там тоже LSTM нейросеть в новых (4+) версиях и она неплохо справляется с рукописным текстом. По моему опыту, около трёх размеченных страниц текста (если мы говорим об А4) в совокупности с аугментацией полученных данных будет достаточно для приемлемых результатов.