

Создание хорошего конвейера данных, который способен на конструирование признаков (feature engineering), обучение и формирование прогнозов на основе ваших данных, может оказаться довольно сложной задачей. Может, но это совсем не обязательно. В этой статье проведу вас по этому процессу шаг за шагом.
Для обучения и прогнозирования непосредственно в нашей базе данных, будем использовать BigQuery ML. Затем я покажу вам, как мы можем использовать такой инструмент, как DBT, для создания конвейера данных, который конструирует признаки, обучает модель, делает прогнозы, и все это без необходимости извлечения данных из нашей базы данных.
Без лишних отлагательств, давайте разбираться!
Настройка BigQuery
Первый шаг — перейти в Google Cloud Console, создать новый проект и дать ему имя. Мы назовем наш проект dbtbigquery.

На этом этапе вы уже можете выполнять запросы. Google даже предоставляет набор общедоступных датасетов, которые перечислены в разделе bigquery-public-data. Если вы кликните на первую базу данных, austin_311, затем на таблицу внутри датасета, а затем на Query, Google откроет в вашем редакторе заготовку под этот запрос.

Просто нужно указать столбцы, которые вы хотите запросить. Если вы измените приведенный выше запрос на SELECT * FROM bigquery-public-data.austin_311.311_service_requests LIMIT 100;, а затем кликните по синей кнопке Run, то выполните свой первый запрос.
Загрузка датасета и знакомство с Google ML
Итак, мы познакомились с Google BigQuery. Следующим шагом будет загрузка какой-нибудь выборки данных в BigQuery и запуск процесса машинного обучения. В этой статье будем использовать выборку данных с пользовательскими событиями (user event data).

Мы можем вызвать mixpanel датасета и оттуда создать новую таблицу.

Введите в появившуюся форму следующую информацию.
В разделе
Select Drive URIвам нужно указать следующий URL.

Затем в строке c проектом (Project) кликните BROWSE и выберите проект (если он еще не выбран), для которого вы хотите создать датасет.

Наконец, внесите следующие изменения в раздел с параметрами схемы (Schema).

Чтобы схема была сгенерирована автоматически, вам следует поставить флажок в раздел Auto detect и скипнуть одну строку в заголовке. Кликните Create Table. Если вы кликнете по только что созданной таблице, вы должны увидеть что-то вроде этого:

Наконец, вы можете просмотреть некоторые данные, выполнив SELECT *, чтобы получить представление о данных.

Конструирование признаков
Теперь, когда наши данные уже загружены в BigQuery, следующим шагом будет преобразование этих данных в формат, пригодный для машинного обучения. Если вы еще раз взгляните на этот датасет, увидите, что он представляет собой данные различных пользователей, представленных distinct_id, каждый из которых совершает разные действия, такие как посещение страницы регистрации (signup page), страницы учебной программы (curriculum) или нажатие кнопки “подать заявку” (apply).

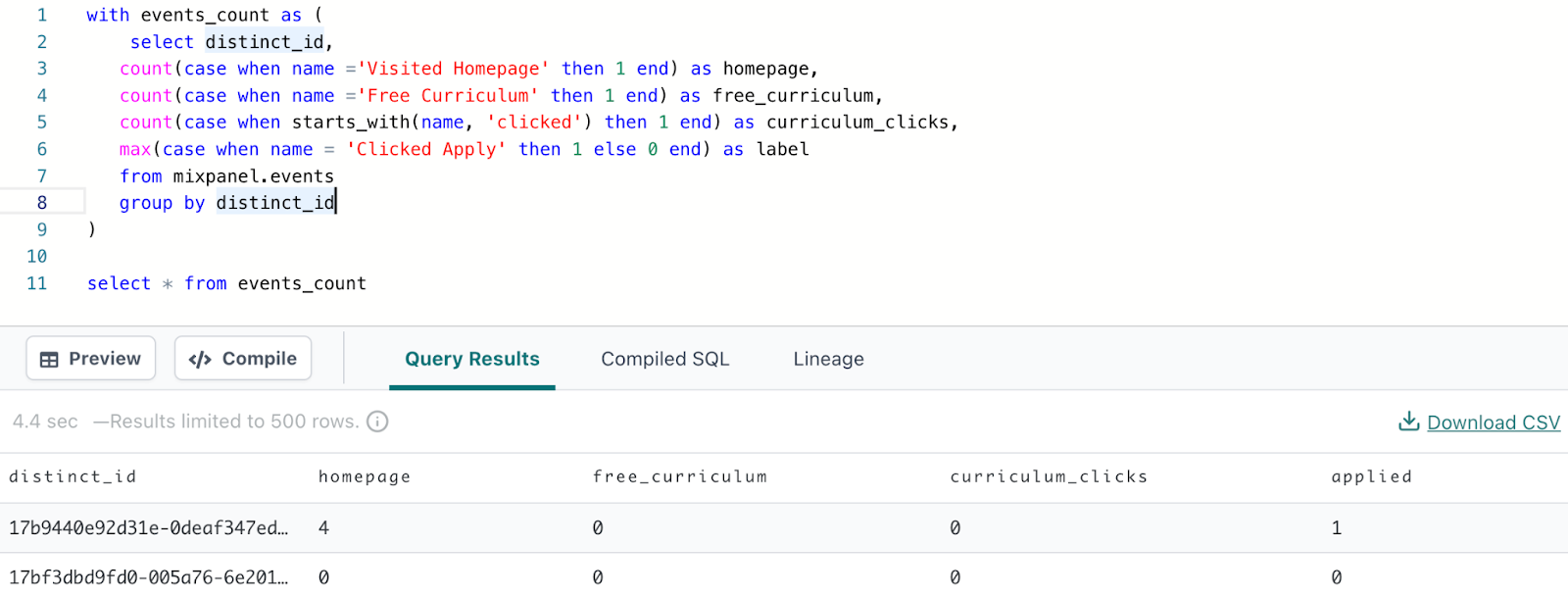
Что мы можем сделать, так это преобразовать наши данные к виду, когда каждый пользователь будет представлен одной строкой, а столбцы показывали, сколько раз каждый пользователь выполнял определенные действия (в основном посещение разных страниц). Сделать это можно с помощью следующего запроса:
select distinct_id,
count(case when name ='Visited Homepage' then 1 end) as homepage,
count(case when name ='Free Curriculum' then 1 end) as free_curriculum,
count(case when starts_with(name, 'clicked') then 1 end) as curriculum_clicks,
max(case when name = 'Clicked Apply' then 1 else 0 end) as applied
from mixpanel.events
group by distinct_idВ результате получим следующую таблицу:

Мы использовали имя столбца, содержащее название события, которое выполнил пользователь, чтобы подсчитать, сколько раз пользователь посещал главную страницу (homepage), страницу бесплатной учебной программы (free curriculum) или кликал по учебной программе (curriculum clicks).
Значения в столбцах homepage, free_curriculum и curriculum_clicks послужат в качестве входных данными для нашего алгоритма машинного обучения. И мы будем использовать эти входные данные, чтобы предсказать, нажмет ли абитуриент на кнопку “подать заявку”.
Поскольку нас не волнует, сколько раз абитуриент кликает, чтобы подать заявку — нас интересует только, подали ли они заявку или нет, — мы используем max() вместо count, так как max будет получен, если пользователь кликнет по “подать заявку” (apply) в любом из событий, и 0 в противном случае.
Называем входные данные для алгоритма машинного обучения нашими признаками (features), а элемент, который мы пытаемся предсказать, является целью (target).
Построение модели машинного обучения
Проделав достаточную работу по конструированию признаков, мы наконец можем приступить к обучению модели, которая предсказывает, нажмет ли абитуриент на кнопку “apply”. Есть несколько причин, по которым кто-либо захотел бы этим заниматься:
Предсказание вероятности того, что кто-то нажмет кнопку “подать заявку”, может помочь нам определить потенциальных клиентов, с которыми следовало бы связаться. Чем больше вероятность того, что они подадут заявку, тем больше вероятность того, что они купят полный курс.
Мы можем видеть, какие функции наиболее важны для человека, подающего заявку, потенциально указывая на определенные веб-страницы, которые повышают вероятность того, что человек в итоге подаст заявку. Это может помочь направить усилия маркетинга.
Получить более глубокое представление о том, как использовать BigQuery ML, вы можете изучив это руководство по линейной регрессии. Глядя на раздел Create Model, вы увидите следующее:

Давайте разберем этот фрагмент кода, начав с оператора select. Оператор select определяет все входные данные, нужные нашей модели машинного обучения. Мы выбираем все столбцы в таблице bigquery-public-data.ml_datasets.pengins. Затем мы определяем в операторе CREATE MODEL модель, которую хотим создать. Создаем модель под названием penguins_model, беря за основу датасет bqml_tutorial. Затем в разделе OPTIONS мы должны указать тип модели как модель линейной регрессии и указать столбец с меткой (то есть столбец, который мы пытаемся предсказать) как body_mass столбец.
Итак, если вы делали все в соответствии с этим руководством, то это будет выглядеть следующим образом:
Примечание:
Приведенное ниже выражение еще не будет работать.
CREATE OR REPLACE MODEL `mixpanel.events_model` OPTIONS (model_type='logistic_reg', input_label_cols=['label']) AS SELECT homepage, free_curriculum, curriculum_clicks, label FROM `dbtbigquery-345218.mixpanel.event_features`
Нам не нужно выбирать distinct_id, так как id пользователя не является релевантным для прогнозирования того, нажмет ли кто-нибудь на кнопку подачи заявки на участие в программе. Далее в CREATE MODEL нам нужно создать events_model в датасете mixpanel. Обратите внимание, что мы изменили model_type на logistic_reg, так как это задача классификации, и еще мы указали input_label_cols как label, потому что это столбец, который мы пытаемся предсказать.
Но есть одна загвоздка, которая заключается в том, что мы еще не создали таблицу, в которой есть все эти столбцы homepage, free_curriculum, curriculum_clicks, а также label. До сих пор мы только выполнили оператор select, чтобы получить эти столбцы. Итак, давайте создадим таблицу с необходимыми столбцами — и именно для этого мы будем использовать DBT.
Настройка DBT
DBT в нашем конвейере машинного обучения можно использовать несколькими способами. Во-первых, он позволит нам организовать наши SQL-запросы в подключенный к SQL кодовый репозиторий. Во-вторых, с его помощью можно построить конвейер, который в случае получения новых данных сначала проведет конструирование признаков, затем обучит модель и мы, наконец, сможем делать прогнозы на основе этих данных. Эти преимущества станут очевидны, когда мы увидим все это в действии.
DBT будет запускать SQL команды на нашей аналитической базе данных, поэтому первым шагом будет регистрация в DBT и подключение его к вашей базе данных BigQuery.

И здесь нам нужно кликнуть New Project

Далее нам нужно будет ввести имя проекта mixpanel_dbt и выбрать хранилище данных BigQuery. Вам будет предложено ввести учетные данные, чтобы проект DBT мог подключиться к вашей базе данных BigQuery.
Самый простой способ подключить базу данных — использовать специальный JSON-файл (Upload a Service Account JSON File).

Чтобы создать этот файл, вам нужно вернуться в свою учетную запись BigQuery и выполнить следующие действия:
Перейдите в раздел IAM & Admin > Service Accounts или просто перейдите по этой ссылке.
> Учетная запись сервиса (service account) используется для авторизации систем в вашей учетной записи BigQuery — здесь этой системой является DBT.

Здесь вам нужно установить имя учетной записи сервиса как
user-dbt, а затем нажатьCreate and Continue.
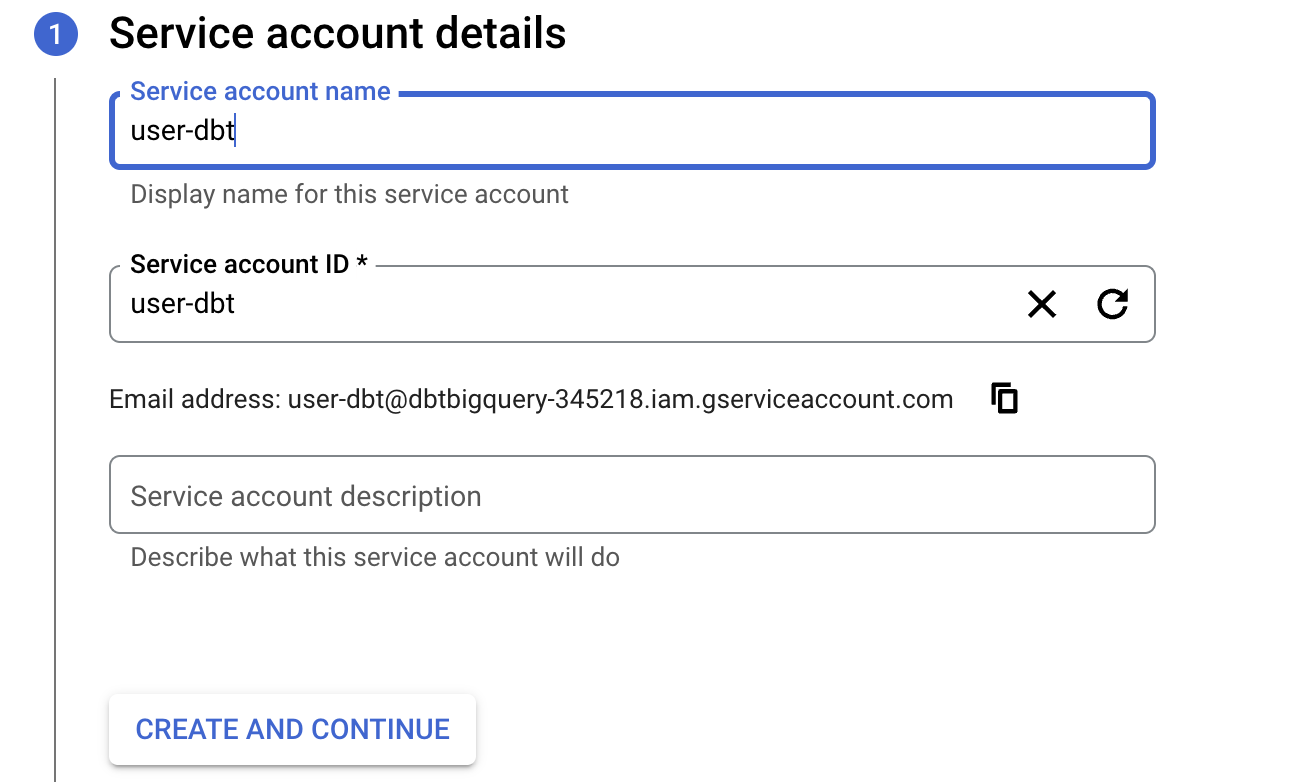
Далее Google предложит вам добавить роли. Введите
BigQuery Job User,BigQuery UserиBigQuery Data Editor.

Теперь, когда мы создали учетную запись сервиса с административными правами доступа к базе данных BigQuery, следующим шагом будет создание учетных данных (service account credentials), чтобы мы могли авторизовать DBT для подключения к нашей базе данных. Выберите учетную запись сервиса, затем перейдите на вкладку Keys и нажмите Add Key, а затем Create New Key.


При нажатии Create New Key будет создан новый JSON-файл с необходимыми учетными данными. Его надо будет загрузить в DBT.

Вернитесь в DBT, кликните по Upload a Service Account JSON File и выберите только что созданный файл.
Когда файл будет загружен, нажмите зеленую кнопку Test в правом верхнем углу, чтобы проверить, что теперь DBT может подключиться к вашей базе данных.

Когда вы убедитесь, что соединение состоялось, нажмите Continue.
Последним шагом является добавление репозитория. Для этого вам может потребоваться повторно выбрать проект в раскрывающемся списке вверху, а затем нажать Continue.

Вы можете подключить свой репозиторий к Github, но использовать репозиторий управляемый DBT немного проще, поэтому в этом руководстве мы будем использовать этот вариант. Мы назовем репозиторий mixpanel_dbt, как и наш проект.

Как только мы нажмем кнопку Create, все будет готово! Пришло время реализовать SQL-команды в DBT. Чтобы начать достаточно просто нажать на кнопку Start Developing.

Разработка с DBT
Нажмите зеленую кнопку Initialize project в левом верхнем углу. Там вы увидите, как запросить базу данных, создав новый файл и добавив запрос, подобный следующему:
Финальную версию репозитория, можно увидеть здесь.
Затем, кликнув по кнопке Preview, вы должны увидеть, что мы подключены к нашей базе данных BigQuery.

Теперь просто повторим шаги, которые мы уже выполняли с помощью BigQuery.
Создадим новый файл под названием user_events в папке models и добавим следующий запрос:
Теперь с DBT вы можете легко превратить запрос, подобный приведенному выше, в новую таблицу или представление, вызвав в командной строке в самом низу DBT run, и нажав зеленую кнопку Enter в правом нижнем углу.

DBT откроет консоль и, если вы нажмете на вкладку со сведениями (details), то увидите, что DBT только что создал новую таблицу в BigQuery ML с новой схемой, которая начинается с dbt_.

Если вы перейдете к консоли BigQuery, обнаружите, что было создано новое представление.
В документации DBT есть хороший разбор различий между представлением и таблицей.

Обратите внимание, что имя таблицы — user_events. DBT смотрит на имя вашего файла user_events.sql, чтобы на его основе определить имя созданного представления.
Помните, что цель этой таблицы состоит в том, чтобы выполнить конструирование признаков для использования в вашей модели машинного обучения. Создайте для своей модели новый файл с именем log_model.sql в папке models.
Теперь нам нужно, чтобы наша модель машинного обучения ссылалась на представление user_events, которое мы только что создали. Лучший способ сослаться на другую таблицу DBT — использовать функцию ref. Вы найдете это в своем файле log_model.
На данный момент для вашего файла log_model просто выберите * из таблицы user_events с помощью следующего запроса:

Если вы перейдете на вкладку Lineage, вы увидите, что одним из преимуществ этого является то, что мы установили, что log_model зависит от модели user_events. Другими словами, если вы хотите создать log_model, DBT будет знать, что ему сначала нужно проверить, были ли внесены какие-либо изменения в модель user_events, так как он будет использовать user_events в качестве входных данных.
Конечно, на самом деле мы хотим передать user_events в нашу модель Google ML. И для этого будем использовать пакет DBT под названием dbt_ml.
Как упоминалось в хабе DBT, вы можете установить этот пакет, добавив следующее в файл packages.yml.
packages:
packages:
- package: kristeligt-dagblad/dbt_ml
version: 0.5.1Затем в командной строке DBT запустить dbt deps.

После установки пакета следуйте инструкциям на соответствующем github, добавив следующее в файл dbt_project.yml в вашем репозитории DBT.
on-run-start:
- '{% do adapter.create_schema(api.Relation.create(target.project, "ml_model_audit")) %}'
- "{{ dbt_ml.create_model_audit_table() }}"
models:
dbt_ml_example:
materialized: view
vars:
"dbt_ml:audit_schema": "ml_model_audit"
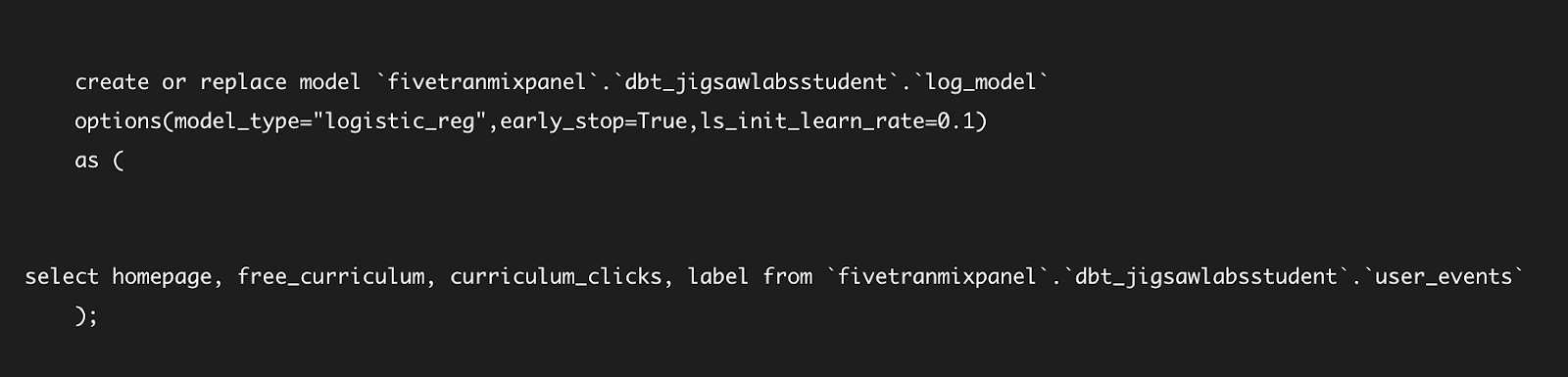
"dbt_ml:audit_table": "ml_models"Продолжая работу с документацией в dbt_ml github, измените файл log_model.sql на следующий.
{{
config(
materialized='model',
ml_config={
'model_type': 'logistic_reg',
'early_stop': true,
'ls_init_learn_rate': 2,
}
)
}}
select homepage, free_curriculum, curriculum_clicks, label from {{ ref('user_events') }}Запустите log_model, введя dbt run –select log_model, который запустит зависимость log_model от user_events, за которой следует log_model.
Если вы посмотрите на детали DBT run, увидите, что он сгенерировал и запустил SQL для создания модели BigQuery, точно так же, как мы ранее делали это непосредственно в BigQuery ML.
Вы можете делать прогнозы на основе этой обученной модели в отдельном файле predictions.sql, добавляя следующее:

В нашем случае получим соответствующие столбцы homepage, free_curriculum и curriculum clicks из user_events, которые будут сохранены в CTE с именем predict_features, а затем будет использовано dbt_ml.predict, чтобы наша log_model предсказывала данные из CTE predict_features.
Примечание: существует проблема как с обучением, так и с прогнозированием на одних и тех же данных user_events. Если вы хотите увидеть исправленную версию, пожалуйста, загляните в репозиторий на github.
Этот DBT конвейер сначала конструирует признаки при создании таблицы user_events, затем обучает log_model, а затем делает прогнозы на основе этой обученной модели.
Вызовите dbt run –select predictions в командной строке и оттуда перейдите к BigQuery, чтобы просмотреть прогнозы.

Вы можете там увидеть не только прогнозы, но и вероятность, связанную с каждым прогнозом. Например, для первой записи DBT предсказывает, что с вероятностью 0.93 наблюдение получит метку 0.
Преимущества DBT
Таким нехитрым образом вы использовали DBT для построения конвейера данных, который выполняет конструирование признаков, использует полученное представление для обучения, а затем делает прогнозы на основе этих данных. Каковы преимущества использования DBT?
DBT позволяет нам определить зависимости для каждого шага, чтобы сформировать нужную последовательность этих шагов. Сохранение последовательности особенно полезно, поскольку со временем поступает больше данных и их необходимо обрабатывать конвейером. Во-вторых, DBT помещает весь ваш код в организованный репозиторий, которым можно поделиться с другими разработчиками. DBT имеет другие функции для улучшения конвейеров данных, такие как тесты для обеспечения качества данных и кода, а также встроенное планирование, чтобы эти шаги можно было выполнять на регулярной основе.
В соответствующем репозитории DBT конвейер включает в себя обучение и тестирование данных. Преимущества использования такого инструмента, как DBT, еще более выражены.

Заключение
Сегодня мы разобрались, как создать конвейер машинного обучения с помощью DBT и BigQuery, который предсказывает, какие пользователи с наибольшей вероятностью подадут заявку на участие в нашей учебной программе. Это позволит нам направить нашу команду по продажам напрямую к нашим основным потенциальным клиентам, а также позволит нам определить, какие события побуждают посетителей подавать заявки на участие в программе. С помощью BigQuery ML мы избавились от хлопот с перемещением данных из нашей базы данных, а с помощью DBT мы разработали конвейер, который выполняет конструирование признаков, обучает модель, а затем генерирует прогнозы.
Перевод статьи подготовлен в преддверии старта курса MLOps. На странице курса вы можете подробно ознакомиться с программой, а также зарегистрироваться на бесплатный вебинар.