
Механизм компрессии CFS и его особенности
Привет, Хабр! Меня зовут Антон Дорошкевич, я сертифицированный эксперт по PostgreSQL и архитектор многокластерных систем 1С. Это мой первый гостевой пост в блоге компании Postgres Professional. Многие мои выступления на PGConf.Russia были тепло приняты аудиторией в частности, в этом году доклад о тонкостях эксплуатации 1С и PostgreSQL вошёл в тройку лучших презентаций конференции. Сегодня мне хотелось бы рассказать о том, как сжатие данных на уровне блоков (страниц) влияет на работу баз 1С.
Механизмы сжатия на уровне блоков разработаны и успешно используются в таких СУБД, как MS SQL Server, Oracle, MySQL. В PostgreSQL сжатие на уровне страниц почему-то не было реализовано; лишь сравнительно недавно оно появилось в Postgres Pro Enterprise. Этот механизм называется CFS (Compressed File System, но файловой системой он не является, поэтому далее будет использоваться сокращение CFS).
Почему 1С?
В 99% случаев моя работа с PostgreSQL связана с базами 1С. Они очень специфичны: всего в одной 1С базе может быть несколько тысяч таблиц и десятки тысяч индексов.
Ещё в мире 1С на тестовых серверах и серверах разработки могут располагаться десятки и сотни баз 1С. Число таблиц и индексов в них разрастается до «неприличных» миллионных значений отношений (это, грубо говоря, все индексы и таблицы).
Не сильно ошибусь, если скажу, что 99% всех запросов 1С явно или неявно используют временные таблицы. Иногда объём такой таблицы может достигать нескольких гигабайт. Соответственно, установить подходящее значение параметра temp_buffers для формирования таблицы в оперативной памяти не представляется реальным. (Мы используем ОС Linux.)
Хорошая новость в том, что временные таблицы 1С чаще всего содержат отлично сжимаемые данные. Их сжатие благотворно действует на быстродействие системы в целом и ничему не вредит.
Как начать работать со сжатием*
*пока эта функциональность доступна только в Postgres Pro Enterprise
Настраивается сжатие достаточно просто, всего за пару шагов (см. пункты списка ниже).
Однако, прежде чем начать, неплохо было бы оценить, какой эффект от сжатия будет именно на ваших данных. У CFS есть готовая функция для этого: cfs_estimate(). Например, выполнив select * from cfs_estimate('_accrgat01576') мы получим результат 6,6. То есть, по предварительной оценке, наша таблица будет сжата в 6,6 раза.
1. Создаём отдельное табличное пространство, указав, что там будет использоваться сжатие:
CREATE TABLESPACE cfs_data LOCATION '/data/cfs' WITH (compression=true);
a. По умолчанию используется алгоритм сжатия zstd, но поддерживаются и другие алгоритмы, а именно: pglz, zlib и lz4.
b. Если вы хотите использовать алгоритм сжатия, отличный от zstd, например, lz4, то команда создания табличного пространства будет выглядеть так:
CREATE TABLESPACE cfs_data LOCATION '/data/cfs' WITH (compression=’lz4’);
2. Чтобы расположить базу и все её данные в ранее созданном табличном пространстве, нужно при создании базы явно указать табличное пространство:
CREATE DATABASE DB1 WITH OWNER = postgres ENCODING = 'UTF8' TABLESPACE = cfs_data LC_COLLATE = 'ru_RU.UTF-8' LC_CTYPE = 'ru_RU.UTF-8' CONNECTION LIMIT = -1
3. Так же в настройках Postgres Pro Enterprise можно управлять некоторыми параметрами поведения механизма сжатия, подробнее об этом можно прочитать в документации: https://postgrespro.ru/docs/enterprise/15/runtime-config-cfs. Но три следующих параметра заслуживают отдельного внимания:
a. cfs_gc_delay по умолчанию выставлен в 0, но это серьёзно увеличивает нагрузку на диск при большом количестве отношений, поэтому лучше установить для этого параметра значение в несколько долей секунды, чтобы дать дискам «продышаться».
b. cfs_gc_period похож на cfs_gc_delay; разница в том, что cfs_gc_delay — это пауза после каждой дефрагментации файла, а cfs_gc_period — это пауза между итерациями сборки мусора. По умолчанию она равна 5 секундам. Для SSD и NVME это вполне приемлемо, но RAID-массивы из обычных SATA и SAS могут плохо отнестись к такой нагрузке. Для них потребуется увеличить паузу после сборки мусора до нескольких десятков секунд.
c. cfs_compress_temp_relations специфичен именно для работы 1С — он обеспечивает сжатие временных таблиц.
Как устроен механизм сжатия в Postgres Pro Enterprise?
Postgres Pro Enterprise использует блочную организацию файлов отношений (таблиц, индексов, последовательностей).
По умолчанию все блоки одинакового размера — 8 КБ. На диске они тоже располагаются
в фиксированных позициях по порядку:

CFS сохраняет логический размер блока в памяти, но на диск пишет их сжатыми непосредственно друг за другом без выравнивания:

При этом, если блок обновляется, то он не переписывается по месту, а дописывается в конец файла:

Возникает проблема: если блоки расположены на произвольных местах и не по порядку, то как быстро их находить и читать? Для выполнения этой задачи существует файл отображения, имеющий расширение `.cfm`. В нём хранятся указатели на актуальные позиции блоков:
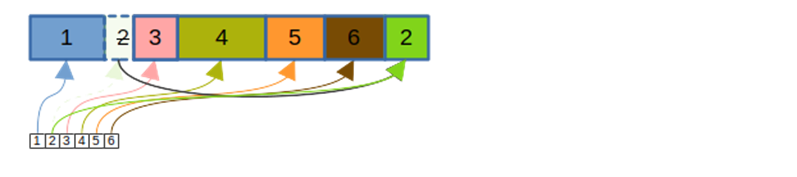
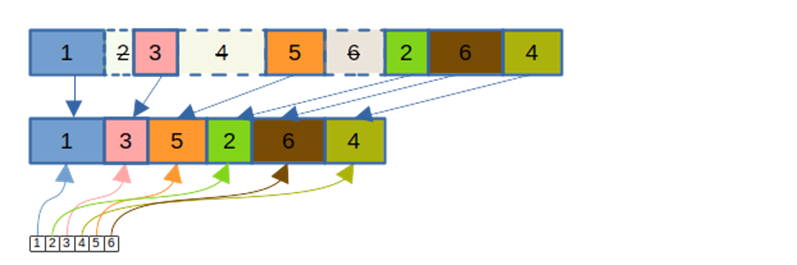
Если в файле было обновлено много блоков, в нём появляется много неиспользуемого места (как на позиции блока 2 на картинке выше). Чтобы вернуть неиспользуемое место файловой системе, используется процесс компактификации: «живые» блоки копируются в новый файл, файлы данных подменяются, файл отображения корректируется:
Плюсы от сжатия, которые понятны без тестирования на реальных базах:
Экономия места на диске «боевого» сервера, серверов репликации, серверов разработки и тестирования. В среднем база 1С сжимается в объёме в 5 раз. Сжатие достаточно сильно зависит от типа данных — если не хранить в базе фото, видео и бинарные архивы, то коэффициент будет ещё выше.
Экономия места при резервном копировании каталога кластера Postgres Pro Enterprise (не путать с pg_dump), например, с помощью pg_probackup (об особенностях работы с этой утилитой – далее в этой статье).
В некоторых сценариях сжатие даёт и увеличение скорости выполнения запросов.
Причём не только в ситуации, когда с диска поднимается большой объём данных для огромного отчёта. Тут всё логично: мы поднимаем в среднем в 5 раз меньше данных, а значит, в 5 раз снижаем нагрузку на диск, незначительно (на единицы процентов) увеличивая нагрузку на CPU. Также стоит упомянуть и сценарий многопоточной работы с небольшой выборкой данных из большой таблицы.
Казалось бы, похожего эффекта можно добиться от секционирования таблицы, например, по периоду, но проблема в том, что Платформа 1С не поддерживает секционирование СУБД, поэтому не каждый администратор БД соглашается на такое решение.
Результаты применения CFS на «боевых» серверах для работы в 1С
Количественные характеристики развёртывания:
6 кластеров Postgres Pro Enterprise;
971 база данных, примерно по 150 баз 1С на кластер;
oколо 4 000 пользователей одновременно.
График объёма баз данных до и после перехода на CFS (алгоритм сжатия по умолчанию zstd, так как на момент перехода ещё не было вариантов выбора алгоритмов):
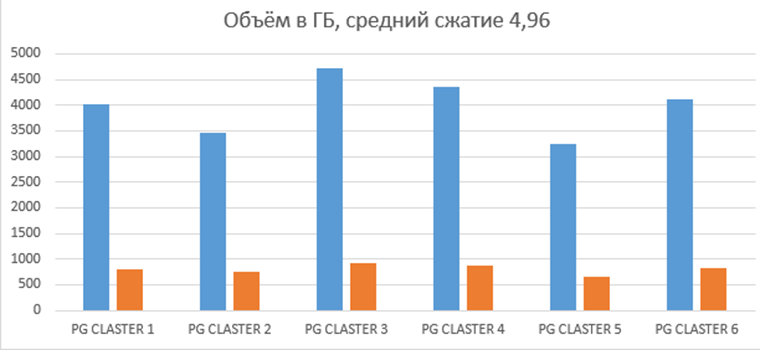
График количества долго выполняющихся запросов по данным Технологического журнала (далее — ТехЖурнал) Платформы 1С.
О методике сбора статистики стоит сказать немного подробнее. ТехЖурнал 1С настроен на сбор запросов, время выполнения которых превышает 0,1 сек:
<event>
<eq property="name" value="DBPOSTGRS"/>
<gt property="durationus" value="100000"/>
</event>
Данные для теста собирались в течение месяца; сначала был месяц работы на несжатых данных, затем ещё месяц — на сжатых. Чтобы легко определить, какой тип запросов стал вести себя по-другому, график разбит на несколько столбцов по диапазонам длительности запросов:

Как видно из графика, долго выполняющихся запросов стало значительно меньше, в остальном поведение системы почти не изменилось.
График изменения нагрузки CPU не покажет изменений выше 1,5% и близок к погрешности измерений, поэтому его в данной статье приводить не будем.
Особенности работы СУБД Postgres Pro Enterprise при использовании CFS
Приятно, что почти никаких особенностей нет! Всё работает прозрачно для приложений, использующих СУБД, в том числе и для 1С. При реструктуризации таблиц в 1С ничего не рушится. Также совершенно прозрачно можно использовать обновлённый механизм реструктуризации 1С.
Но всё-таки добавлю пару маленьких ложек дёгтя в большую бочку мёда CFS:
1. В старых версиях функция подсчёта объёма, занимаемого базой данных, pg_database_size с CFS работала некорректно, сжатая база могла казаться в десятки раз больше несжатой. Это происходило из-за того, что файл отражений CFS сразу создавался размером 1МБ даже на пустое отношение. Согласно коллегам из Postgres Professional, это поведение функции будет устранено в ближайших релизах Postgres Pro Enterprise 11.21.1, 12.16.1, 13.12.1, 14.9.1, 15.4.1. Пользователям более ранних версий рекомендую обновление до этих, как только они выйдут.
Мной была написана небольшая функция на PL/Python, которая показывает реально занимаемое базой место на диске (функция не претендует на идеальность и приведена только в качестве примера, а использовать её или нет, решать вам):
CREATE OR REPLACE FUNCTION public.sizecfs(
start_path character varying,
name_db character varying)
RETURNS bigint AS
$BODY$
import os
total_size = 0
full_path = ''
e = plpy.execute("SELECT oid::varchar FROM pg_database WHERE datname='" + name_db + "'")
full_path = start_path+e[0]['oid']
if (os.path.exists(full_path)):
for dirpath, dirnames, filenames in os.walk(full_path):
for f in filenames:
fp = os.path.join(dirpath, f)
total_size += os.stat(fp).st_blocks * os.stat(fp).st_blksize
return round(total_size / 8)
else:
return None
$BODY$
LANGUAGE plpython3u VOLATILE
COST 100;
ALTER FUNCTION public.sizecfs(character varying, character varying)
OWNER TO postgres;2. Утилита резервного копирования pg_probackup версии 2.5 и младше не поддерживала работу с CFS во всех режимах создания резервной копии. Начиная с версии 2.6, CFS полностью поддерживается в pg_probackup с режимами PTRACK, PAGE, DELTA. Подробнее о различиях между версиями 2.5 и 2.6 можно почитать в новости на сайте Postgres Professional.
Вместо заключения
Очень надеюсь, что возможность постраничного сжатия на уровне СУБД вас заинтересовала своей простотой, прозрачностью в использовании и скоростью. При тестировании СУБД Postgres Pro Enterprise механизм CFS точно не стоит обходить вниманием.
P.S. В этом посте я намеренно не затрагивал тему файловой системы ZFS, так как это совсем другая история, хоть и для схожей потребности.
Комментарии (9)


elephanthathi
21.08.2023 11:22живем мы не в мире розовых поней. всё упирается в бюджеты. диски для БД и СХД - сукадорогие.
уменьшение объема занимаемого места БД, без снижения производительности - это уже восторг.
дали бы возможность выбирать включение/выключение сжатия по типу данных, или по отдельным таблицам...
randur
21.08.2023 11:22+2Тут возникает вопрос стоимости лицензий. Есть подозрение, что на разницу стоимости лицензий между Postgres и Postgres Pro Enterprise можно купить очень много дисков.


Roman2dot0
21.08.2023 11:22+2Тут не хватает сравнения того, насколько меняется производительность + сравнения с фс с сжатием, те же btrfs, zfs.
У меня есть БД на обеих, в зависимости от того, что пишется уровень компресии составляет для
btrfs: lzo ~2 (тип данных, пусть будет 1), zstd-3 ~4 (на тех же данных 1), zstd-9 ~9 (на логоподобных).
zfs: lz4 2.3 (на 1), zstd-3 ~4 (на 1).

LaRN
21.08.2023 11:22А индексы тоже сжимается или только данные в таблицах?
Ну и наверное есть повышенное требование на оперативную память, ведь поднять в память кусок таблицы и распаковать займёт теперь в 5 раз больше места, или это не так?
Как распаковка данных влияет на требования к cpu, теперь же кроме джойнов нужно ещё и распаковку выполнять, особенно сильно должно в много пользовательского системе влиять, делали ли такие замеры?

AntonDor Автор
21.08.2023 11:22Сжимается всё, и индексы в том числе
Повышенный расход памяти не зафиксирован
По поводу cpu в статье отразил, что на уровне погрешности измерений 1,5% рост нагрузки
Замеры делались на системе с 500+ одновременно работающих пользователей
l0ser140
Из графика видно, что мы ускорили 250 медленных запросов, замедлив миллион относительно быстрых.