
В современных микросервисных архитектурах регулярно встречаются потребности в кешах, индексах полнотекстового поиска, репликах, а также в реактивном взаимодействии компонентов. Решать все эти задачи по отдельности — тот ещё вызов, но оказывается все эти задачи могут быть решены одним механизмом, и имя ему: Change Data Capture.
Меня зовут Тимофей Брунько, я разработчик Yandex Cloud. В этой статье я расскажу о том, как в теории и на практике работает CDC — Change Data Capture, или буквально «захват изменения данных», — и как наш сервис Yandex Data Transfer с поддержкой формата Debezium помогает пользователям решать задачи поставки данных, связанные с CDC. В конце статьи покажу реальные кейсы. Поехали.
Что такое Change Data Capture
— Наглядный пример Change Data Capture
Когда полезен Change Data Capture
1. Реактивное взаимодействие между компонентами инфраструктуры
2. Паттерны построения микросервисной архитектуры
Возможные способы реализации CDC
— Историческая справка и обзор CDC-инструментов
Debezium — самая популярная реализация CDC
Как Yandex Data Transfer пришёл к CDC
Как реализован CDC в Yandex Data Transfer
Реальные кейсы использования CDC через Yandex Data Transfer
Итоги и полезные ссылки
Change Data Capture (CDC, «захват изменения данных») — это набор шаблонов разработки программного обеспечения, который позволяет организовать реактивную инфраструктуру, упростить микросервисную архитектуру, а также распилить монолит на микросервисы.
Как правило, во всех подобных сценариях речь идёт о том, что у вас есть OLTP-база данных. С помощью CDC вы получаете последовательность событий о добавлении, изменении и удалении строк и обрабатываете их — таким образом база данных преобразуется в event-driven систему.
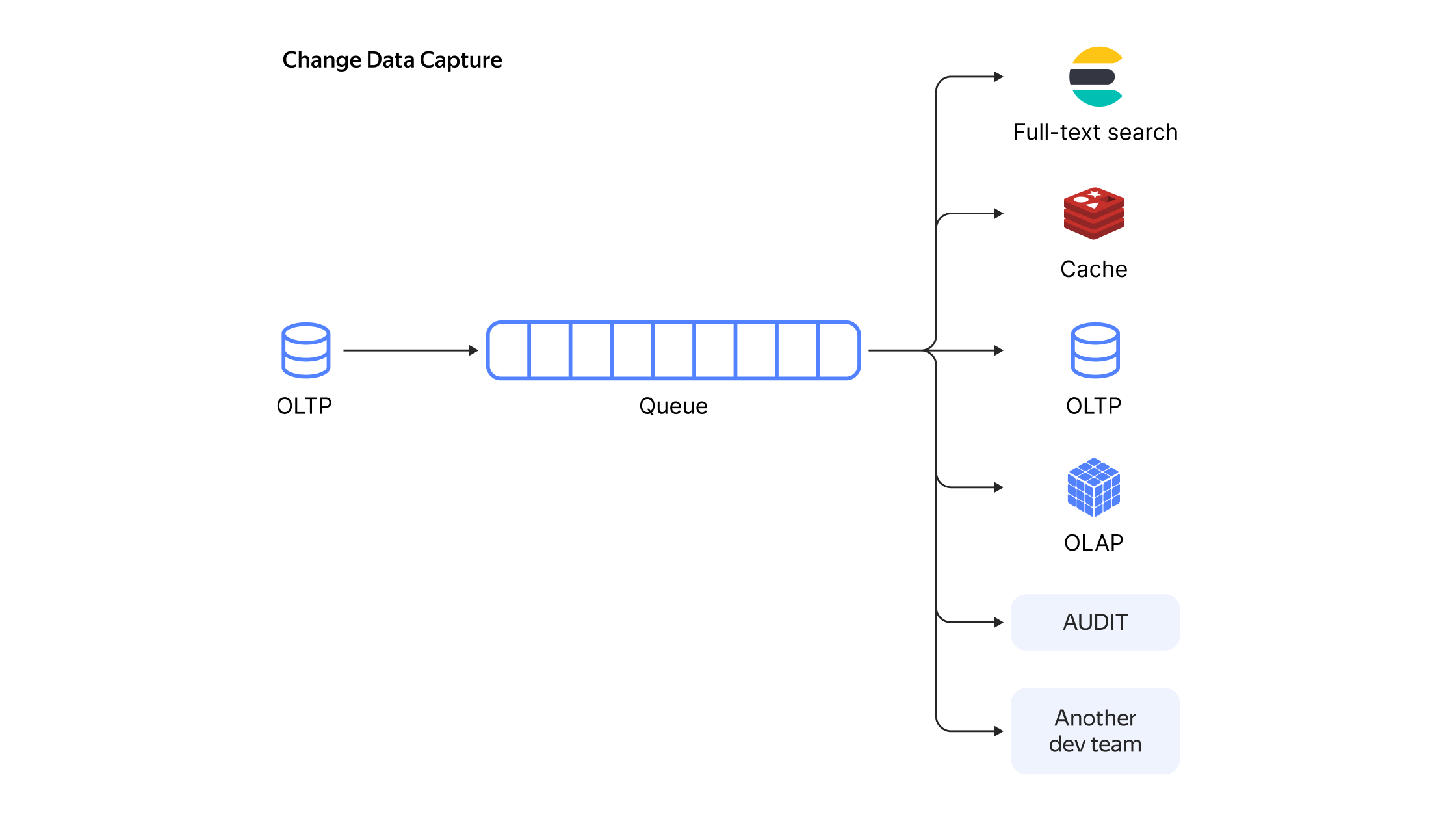
Типовая схема использования Change Data Capture
Правильно приготовленный CDC позволяет добиться реакции на событие за время, измеряемое долями секунды. Поэтому CDC часто используют, если необходимо в режиме реального времени анализировать часть данных, которая вынесена во внешние системы.
Как видим из примера, CDC-события обладают следующими свойствами:
Способность СDC быстро и эффективно перемещать данные небольшими порциями делает его полезным, когда нужно в режиме реального времени реагировать на изменения в базе-источнике. Можно выделить два основных направления, в которых применяется CDC:
Ниже рассмотрим оба направления.
В современных архитектурах часто работают не со всей базой данных, а с её частью, и обычно CDC применяется к конкретным таблицам. Имея последовательность модифицирующих таблицу событий, можно получить асинхронную реплику таблицы. А поскольку события уже отделились от базы-источника в независимом от базы формате, базой-приёмником может выступать что угодно: OLTP/OLAP/Cache/Full-Text Search.
Если всё правильно приготовить, можно получить, например, кеш с минимальными задержками без необходимости внесения изменений в бизнес-логику сервисов. Посмотрим, как это работает на конкретных примерах репликации.
Репликация в Data Warehouse (DWH). Применяя поток изменений к DWH, можно получить асинхронную реплику вашей боевой OLTP-базы. Это решает сразу несколько проблем:
Например, вы можете автоматически получить асинхронную реплику боевого PostgreSQL в ClickHouse, Elasticsearch/OpenSearch или S3.
Пример с поставкой репликационного потока из MySQL в ClickHouse
Обновление или инвалидация кешей. Применяя поток изменений к кешу, можно получить прямиком из боевой OLTP-базы автоматически обновляемый кеш (опционально агрегированный/трансформированный). В качестве практического примера могу привести проект RedisCDC для Redis. Это распределённая платформа, которая упрощает поставку CDC-потока в Redis.
Отгрузка данных в движок полнотекстового поиска Elasticsearch/OpenSearch/Solr. Отправляя нужную часть потока изменений в движок полнотекстового поиска, можно получить автоматически обновляемый индекс полнотекстового поиска.
Пример поставки репликационного потока из MySQL в Elasticsearch
Репликация в такую же транзакционную БД. Имея поток изменений в базе, можно получить асинхронную логическую реплику, например для dev-стенда разработчиков. А поскольку, как правило, события передаются в логическом виде, можно попутно произвести с ними логические преобразования. Например, колонки с одними чувствительными данными исключить из реплики, а другие чувствительные данные зашифровать.
Репликация в другую транзакционную БД. Если по каким-нибудь причинам вы хотите получить реплику ваших данных в другой БД: например, прод в MySQL, а данные нужны в PostgreSQL, или наоборот, — это тоже можно реализовать при помощи CDC. Такая реплика может понадобиться, например, из-за каких-либо ограничений инструментов.
Пример поставки из MySQL в PostgreSQL
Полный аудит происходящего в базе. CDC даёт возможность проводить полный аудит происходящего в базе. Сохраняя события об изменениях в базе «как есть» в какое-либо хранилище, вы можете получить аудитные логи всего происходящего с вашей боевой базой. А при обработке потока сообщений, вы можете получить аудит в реальном времени.
Пример со сценарием такого аудита
Отгрузка потока сообщений другим командам. Отгружая события в очередь, можно нотифицировать другие команды о наступивших событиях. Более системно этот подход рассматривается в блоке о микросервисных паттернах, но отгружать коллегам события можно и без всяких паттернов.
Отказоустойчивость. Если у вас кросс-датацентровая очередь, отгружая CDC в очередь, вы можете дублировать читателей в двух разных дата-центрах и обеспечить таким образом гарантию DC-1 (на случай отключения одного дата-центра).
Снижение нагрузки на мастер транзакционной БД. CDC позволяет снизить нагрузку на мастер транзакционной БД или сервис, если речь про базу микросервиса. Сериализация CDC-потока в очереди позволяет множеству приёмников работать с информацией мастера, нагрузив его лишь один раз. Можно включить все вышеперечисленные приёмники, ещё и умножить их на два: по копии в каждом дата-центре, при этом нагрузка на мастер не изменится — все они будут лишь читать очередь сообщений.
СDC — это подход, который позволяет одновременно использовать несколько паттернов микросервисной архитектуры. С точки зрения паттернов проектирования микросервисов, CDC позволяет одновременно осуществлять и реактивную обработку событий одних микросервисов другими, и decoupling (отсоединение) микросервисов, и помогать распиливать монолиты на микросервисы. На тонких нюансах отличия паттернов останавливаться не буду, но для интересующихся — в конце поделюсь списком полезных ссылок по этой теме.
Паттерн outbox. Паттерн outbox (aka Application events) предписывает объединять изменения стейта с отправкой нотификаций другим сервисам. Это достижимо либо через сохранение сообщений на отправку в соседних таблицах в той же транзакции (см. transactional outbox), либо через последующую отправку сообщений через CDC.
Если складывать CDC-поток в очередь, то как побочный эффект получается event sourcing с domain-событиями на шине в виде Apache Kafka и взаимодействие сервисов через Kafka. Это позволяет отчасти осуществить decoupling микросервисов: сервисы перестают куда-то ходить кого-то оповещать. Те, кому нужно получать события, сами подписываются на события, а сервис работает только с собственной базой. Кроме того, из бесплатных плюшек получаем: отсутствие необходимости в service discovery (механизме обнаружения сервисов), воспроизводимость, а также возможность легко и просто весь поток складывать, например, в Elasticsearch.
Паттерн CQRS. Command and Query Responsibility Segregation (CQRS) — паттерн, в котором приложение условно разделяется на часть, модифицирующую стейт, и на часть, читающую стейт. CDC позволяет направить часть, модифицирующую стейт, через очередь в другую базу, из которой будет производиться чтение.
Паттерн Strangler. Strangler — это паттерн распиливания монолита на микросервисы. Правильно приготовленный CDC полностью прозрачен для унаследованного приложения и не требует никаких изменений в унаследованной модели данных, что сильно облегчает декомпозицию монолита и делает внедрение в монолит максимально неинвазивным.
В теории существует три способа реализации CDC: временны́е метки на строках, триггеры на таблицах и логическая репликация. В этом блоке расскажу об этих способах, их достоинствах и недостатках.
Например, у вас может быть такая таблица в БД, где существует специально выделенная колонка (допустим, под названием updated_at), которая бы заполнялась при каждом insert/update значением now().
Тогда вы можете регулярно извлекать поллингом новые или изменённые строки нехитрым запросом:
Правда, в такой базовой схеме вы не сможете отличить insert от update и не сможете получать нотификации об удалениях строк. Усложняя схему, можно научиться и отличать insert от update (например, ввести поле created_at), и получать удаление строк (к примеру, заменить удаления выставлением флага is_deleted).
Плюсы подхода:
Минусы подхода:
Существуют модификации этого подхода, которые позволяют убрать некоторые недостатки за счёт усложнения схемы, но суть не меняется. Вот что можно добавить:
В этом случае вы заводите специальную таблицу с историей и настраиваете триггеры, которые срабатывают при изменении или удалении строк.
Плюсы подхода:
Минусы подхода:
Каждая база данных для обеспечения гарантий ACID содержит Write-Ahead Log — лог изменений, закодированный в бинарном формате: в PostgreSQL это называется wal, в MySQL — binlog, в Oracle — redo-log, в MongoDB — oplog, в MSSQL — transaction log.
По сути такой лог уже содержит то, что нам нужно, остаётся только раскодировать его и отправить в очередь сообщений.
Правда, иногда появляются внезапные ограничения. Например, в случае PostgreSQL этот подход не дружит с pg_repack.
Плюсы подхода:
Минусы подхода:
На просторах GitHub я нашел лишь один проект (и тот малоизвестный), который реализовывал бы CDC не через декодирование wal-лога, а через версии на строках. На современном рынке CDC-решений значительную часть занимает проект Debezium, основанный на декодировании wal-лога. Так что рассмотрим его подробнее.
Debezium сегодня является стандартом де-факто в мире CDC. Он появился в 2015 году силами разработчиков из Red Hat и сейчас поддерживает 9 популярных источников: MySQL, MongoDB, PostgreSQL, Oracle, MSSQL, Db2, Cassandra, Vitess, Google Spanner. Изначально инструмент был только Kafka-коннектором, но в 2020-м появился проект Debezium Server, который умеет отправлять события во все популярные очереди.
Проект написан на Java, исходники лежат на GitHub под свободной лицензией Apache 2.0, в основном проекте 447 контрибьюторов.
Debezium поддерживает три формата сериализации событий: json (default), avro и protobuf. Сериализаторы модульны и параметризованы, и можно как настроить любой из существующих сериализаторов, так и написать свой. Поддерживаются интеграции с различными Schema registry. Также поддерживаются трансформации, интеграция с мониторингами, есть UI.
А ещё Debezium выдаёт формат данных, единый для всех БД. Таким образом, научившись обрабатывать дебезиумные потоки из MySQL, вы практически тем же кодом можете обрабатывать дебезиумные потоки и из любых других поддерживаемых Debezium баз данных.
В общем, проект уже достаточно зрелый, чтобы быть надёжным решением, но всё ещё быстро развивается, богат на фичи и интеграции, с обилием материалов и документации. Предоставляются удобные Docker-контейнеры с Debezium, которые позволяют ставить эксперименты за считанные минуты, к тому же есть замечательный официальный репозиторий с демо-примерами.
Yandex Data Transfer появился как сервис миграции баз данных в облако. Когда пользователям необходимо заехать в облачную базу данных (managed database), как правило, у них уже есть база данных на железе (on-premise) и нужно мигрировать эти данные в облако.
Data Transfer решает задачу следующим образом: сначала переносится снапшот базы данных, после чего к базе-приёмнику применяются все изменения, произошедшие на базе-источнике с момента взятия снапшота. В итоге в облаке получается асинхронная реплика базы данных, остаётся только отключить пишущую нагрузку на базу-источник, подождать несколько секунд, пока реплика догонит мастера, и включить нагрузку уже на базу в облаке.
Таким образом можно мигрировать в облако с минимальным даунтаймом.
Со временем помимо задачи миграции сервис начал использоваться для переливания данных между разными БД, например, из транзакционной в аналитическую, а также между очередями сообщений и между базами данных и очередями. Если свести все поддерживаемые варианты трансфера в одну матрицу, видно, что Data Transfer сразу умеет работать и со снапшотами, и с репликационными потоками данных, горизонтально масштабируясь и шардируясь.
В терминологии сервиса есть две основных сущности:
После того как трансфер создан, его можно активировать разово, или же можно настроить активацию по расписанию. В случае снапшота таблицы переливаются, и затем трансфер деактивируется сам. В случае репликации запускается бесконечный процесс переноса новых данных из источника в приёмник.
Data Transfer написан на Go, работает как решение cloud-native — есть контрол-плейн, отвечающий за API и управление дата-плейнами, а на активацию пользовательских трансферов создаются дата-плейны в рантаймах. Например, среди поддержанных рантаймов есть Kubernetes (k8s) — т.е. на этом рантайме на активацию трансфера в k8s запускаются поды. Таким образом, это самостоятельный сервис, работающий поверх некоторого рантайма: помимо Kubernetes поддерживаются Yandex Cloud Instance Groups, YT и локальный рантайм. Data Transfer на активации трансфера создаст в рантайме виртуалки в нужном количестве и начнёт переливку данных. В несколько кликов можно настроить поставку данных на гигабайты в секунду.
Сервис уже несколько лет успешно эксплуатируется внутри Яндекса в боевых продакшнах с солидными объёмами данных. Вдобавок к тому, что сервис изначально горизонтально масштабируемый, мы научились параллелиться везде, где это возможно, и сейчас во внутренней инфраструктуре бежит почти две тысячи потоков данных, перенося гигабайты в секунду.
Помимо этого мы реализовали наиболее часто запрашиваемые ETL-преобразования, и возможности ETL в дальнейшем будут только расширяться. Настраивать можно как через удобный UI, так и через API и Terraform.
Всё это привело к тому, что Data Transfer стал универсальным сервисом переноса данных из любого источника в любой приёмник (с возможностями ETL-процессинга): как снапшотов, так и потоков данных — и пользователи помимо применения сервиса по прямому назначению придумали массу неочевидных способов использования. CDC является лишь одним способом применения сервиса Data Transfer из множества.
Поскольку Yandex Data Transfer с момента создания получал репликационный поток на уровне логической репликации, естественным шагом было научиться отдавать это пользователям. Именно это превращало Data Transfer в CDC-решение, работающее через обработку wal-лога.
Реализовывать отгрузку событий логической репликации в очередь мы начали по пользовательским запросам, и было принято решение порождать события в формате Debezium, чтобы мы могли стать drop-in replacement для Debezium. Так можно было бы в настроенном пайплайне подменить один CDC-продукт другим, и пайплайн остался бы рабочим. Таким образом и мы бы получили полезные интеграции, и в мире не появилось бы нового формата данных.
Соответственно нужно было сделать конвертеры из наших внутренних объектов в сериализованный Debezium-формат и покрыть это миллионом тестов, что мы и сделали.
На данный момент в Data Transfer сериализатор реализован для PostgreSQL и MySQL-источников, а недавно появилась поддержка YDB-источника. Теперь вы можете в несколько кликов настроить поставку CDC из ваших таблиц YDB в Apache Kafka и в YDS в формате Debezium.
Вскоре после поддержки YDB появилась и поддержка Schema Registry, что на порядок уменьшает объёмы передаваемых данных и даёт дополнительные плюшки. В планах получить ещё больше интеграций с различными опенсорс-сервисами.
Таким образом, для MySQL и PostgreSQL получился drop-in replacement для Debezium. Из крупных отличий: Data Transfer умеет переживать переезд мастера PostgreSQL (ситуация, когда реплика становится мастером) при включенном плагине pg_tm_aux, а также сервис умеет переносить user-defined types в PostgreSQL.
Также в Data Transfer реализовали возможность организовывать query-based CDC — в документации это называется «инкрементальные таблицы», а на внутреннем сленге мы этот режим исторически называем «доливочки».
Недавно у нас вышел вебинар по использованию Data Transfer в нетривиальных кейсах.
Расскажу про популярные пользовательские кейсы.
В статье мы рассмотрели Change Data Capture со всех сторон: история возникновения, теория, сценарии применения, опенсорс-практика, корпоративная практика и реальные пользовательские истории.
Чтобы узнать о CDC больше, смотрите вебинар, читайте статью Мартина Клеппмана, экспериментируйте с Debezium и Yandex Data Transfer.
Отмечу, что Yandex Data Transfer — бесплатный сервис в Yandex Cloud.
Приходите пользоваться, оставляйте фидбек и фичареквесты.
Что ещё почитать по рассмотренным темам
Меня зовут Тимофей Брунько, я разработчик Yandex Cloud. В этой статье я расскажу о том, как в теории и на практике работает CDC — Change Data Capture, или буквально «захват изменения данных», — и как наш сервис Yandex Data Transfer с поддержкой формата Debezium помогает пользователям решать задачи поставки данных, связанные с CDC. В конце статьи покажу реальные кейсы. Поехали.
О чём поговорим
Что такое Change Data Capture
— Наглядный пример Change Data Capture
Когда полезен Change Data Capture
1. Реактивное взаимодействие между компонентами инфраструктуры
2. Паттерны построения микросервисной архитектуры
Возможные способы реализации CDC
— Историческая справка и обзор CDC-инструментов
Debezium — самая популярная реализация CDC
Как Yandex Data Transfer пришёл к CDC
Как реализован CDC в Yandex Data Transfer
Реальные кейсы использования CDC через Yandex Data Transfer
Итоги и полезные ссылки
Что такое Change Data Capture (CDC)
Change Data Capture (CDC, «захват изменения данных») — это набор шаблонов разработки программного обеспечения, который позволяет организовать реактивную инфраструктуру, упростить микросервисную архитектуру, а также распилить монолит на микросервисы.
Как правило, во всех подобных сценариях речь идёт о том, что у вас есть OLTP-база данных. С помощью CDC вы получаете последовательность событий о добавлении, изменении и удалении строк и обрабатываете их — таким образом база данных преобразуется в event-driven систему.
Типовая схема использования Change Data Capture
Правильно приготовленный CDC позволяет добиться реакции на событие за время, измеряемое долями секунды. Поэтому CDC часто используют, если необходимо в режиме реального времени анализировать часть данных, которая вынесена во внешние системы.
Наглядный пример Change Data Capture
Ниже приведены примеры SQL-команд для базы данных PostgreSQL и CDC-события, которые они создают. Для иллюстративного примера не так важен формат или протокол. В этой нотации «op» — это operation, которая может быть «c» — create(insert), «u» — update, «d» — delete.
|
|
|
|
|
|
Как видим из примера, CDC-события обладают следующими свойствами:
- Специфика базы данных исчезает в CDC-потоке (на практике сводится практически к нулю, но некоторые вещи всё же можно получить).
- Любая команда превращается в набор изменённых строк, где есть новое состояние. В зависимости от настроек, можно получить и предыдущее состояние.
Когда полезен СDС
Способность СDC быстро и эффективно перемещать данные небольшими порциями делает его полезным, когда нужно в режиме реального времени реагировать на изменения в базе-источнике. Можно выделить два основных направления, в которых применяется CDC:
- это организация реактивного взаимодействия между компонентами инфраструктуры;
- реализация различных паттернов построения микросервисной архитектуры.
Ниже рассмотрим оба направления.
1. Реактивное взаимодействие между компонентами инфраструктуры
В современных архитектурах часто работают не со всей базой данных, а с её частью, и обычно CDC применяется к конкретным таблицам. Имея последовательность модифицирующих таблицу событий, можно получить асинхронную реплику таблицы. А поскольку события уже отделились от базы-источника в независимом от базы формате, базой-приёмником может выступать что угодно: OLTP/OLAP/Cache/Full-Text Search.
Если всё правильно приготовить, можно получить, например, кеш с минимальными задержками без необходимости внесения изменений в бизнес-логику сервисов. Посмотрим, как это работает на конкретных примерах репликации.
Репликация в Data Warehouse (DWH). Применяя поток изменений к DWH, можно получить асинхронную реплику вашей боевой OLTP-базы. Это решает сразу несколько проблем:
- позволяет аналитикам не влиять на боевую OLTP-базу,
- решает вопрос передачи данных из транзакционной базы в аналитическую,
- позволяет аналитикам работать на аналитических базах.
Например, вы можете автоматически получить асинхронную реплику боевого PostgreSQL в ClickHouse, Elasticsearch/OpenSearch или S3.
Пример с поставкой репликационного потока из MySQL в ClickHouse
Обновление или инвалидация кешей. Применяя поток изменений к кешу, можно получить прямиком из боевой OLTP-базы автоматически обновляемый кеш (опционально агрегированный/трансформированный). В качестве практического примера могу привести проект RedisCDC для Redis. Это распределённая платформа, которая упрощает поставку CDC-потока в Redis.
Отгрузка данных в движок полнотекстового поиска Elasticsearch/OpenSearch/Solr. Отправляя нужную часть потока изменений в движок полнотекстового поиска, можно получить автоматически обновляемый индекс полнотекстового поиска.
Пример поставки репликационного потока из MySQL в Elasticsearch
Репликация в такую же транзакционную БД. Имея поток изменений в базе, можно получить асинхронную логическую реплику, например для dev-стенда разработчиков. А поскольку, как правило, события передаются в логическом виде, можно попутно произвести с ними логические преобразования. Например, колонки с одними чувствительными данными исключить из реплики, а другие чувствительные данные зашифровать.
Репликация в другую транзакционную БД. Если по каким-нибудь причинам вы хотите получить реплику ваших данных в другой БД: например, прод в MySQL, а данные нужны в PostgreSQL, или наоборот, — это тоже можно реализовать при помощи CDC. Такая реплика может понадобиться, например, из-за каких-либо ограничений инструментов.
Пример поставки из MySQL в PostgreSQL
Полный аудит происходящего в базе. CDC даёт возможность проводить полный аудит происходящего в базе. Сохраняя события об изменениях в базе «как есть» в какое-либо хранилище, вы можете получить аудитные логи всего происходящего с вашей боевой базой. А при обработке потока сообщений, вы можете получить аудит в реальном времени.
Пример со сценарием такого аудита
Отгрузка потока сообщений другим командам. Отгружая события в очередь, можно нотифицировать другие команды о наступивших событиях. Более системно этот подход рассматривается в блоке о микросервисных паттернах, но отгружать коллегам события можно и без всяких паттернов.
Отказоустойчивость. Если у вас кросс-датацентровая очередь, отгружая CDC в очередь, вы можете дублировать читателей в двух разных дата-центрах и обеспечить таким образом гарантию DC-1 (на случай отключения одного дата-центра).
Снижение нагрузки на мастер транзакционной БД. CDC позволяет снизить нагрузку на мастер транзакционной БД или сервис, если речь про базу микросервиса. Сериализация CDC-потока в очереди позволяет множеству приёмников работать с информацией мастера, нагрузив его лишь один раз. Можно включить все вышеперечисленные приёмники, ещё и умножить их на два: по копии в каждом дата-центре, при этом нагрузка на мастер не изменится — все они будут лишь читать очередь сообщений.
2. Паттерны построения микросервисной архитектуры
СDC — это подход, который позволяет одновременно использовать несколько паттернов микросервисной архитектуры. С точки зрения паттернов проектирования микросервисов, CDC позволяет одновременно осуществлять и реактивную обработку событий одних микросервисов другими, и decoupling (отсоединение) микросервисов, и помогать распиливать монолиты на микросервисы. На тонких нюансах отличия паттернов останавливаться не буду, но для интересующихся — в конце поделюсь списком полезных ссылок по этой теме.
Паттерн outbox. Паттерн outbox (aka Application events) предписывает объединять изменения стейта с отправкой нотификаций другим сервисам. Это достижимо либо через сохранение сообщений на отправку в соседних таблицах в той же транзакции (см. transactional outbox), либо через последующую отправку сообщений через CDC.
Если складывать CDC-поток в очередь, то как побочный эффект получается event sourcing с domain-событиями на шине в виде Apache Kafka и взаимодействие сервисов через Kafka. Это позволяет отчасти осуществить decoupling микросервисов: сервисы перестают куда-то ходить кого-то оповещать. Те, кому нужно получать события, сами подписываются на события, а сервис работает только с собственной базой. Кроме того, из бесплатных плюшек получаем: отсутствие необходимости в service discovery (механизме обнаружения сервисов), воспроизводимость, а также возможность легко и просто весь поток складывать, например, в Elasticsearch.
Паттерн CQRS. Command and Query Responsibility Segregation (CQRS) — паттерн, в котором приложение условно разделяется на часть, модифицирующую стейт, и на часть, читающую стейт. CDC позволяет направить часть, модифицирующую стейт, через очередь в другую базу, из которой будет производиться чтение.
Паттерн Strangler. Strangler — это паттерн распиливания монолита на микросервисы. Правильно приготовленный CDC полностью прозрачен для унаследованного приложения и не требует никаких изменений в унаследованной модели данных, что сильно облегчает декомпозицию монолита и делает внедрение в монолит максимально неинвазивным.
Возможные способы реализации CDC
В теории существует три способа реализации CDC: временны́е метки на строках, триггеры на таблицах и логическая репликация. В этом блоке расскажу об этих способах, их достоинствах и недостатках.
1. Временные метки на строках (aka Query-based CDC)
Например, у вас может быть такая таблица в БД, где существует специально выделенная колонка (допустим, под названием updated_at), которая бы заполнялась при каждом insert/update значением now().
Тогда вы можете регулярно извлекать поллингом новые или изменённые строки нехитрым запросом:
SELECT ... FROM my_table WHERE updated_at>saved_val;Правда, в такой базовой схеме вы не сможете отличить insert от update и не сможете получать нотификации об удалениях строк. Усложняя схему, можно научиться и отличать insert от update (например, ввести поле created_at), и получать удаление строк (к примеру, заменить удаления выставлением флага is_deleted).
Плюсы подхода:
- он работает;
- он не хранит историю изменений отдельно (как это делает вариант с триггерами, о котором речь пойдет ниже).
Минусы подхода:
- у этого подхода существуют неочевидные требования к взаимодействию приложения с базой данных;
- требуется внедрение в схему таблицы и в бизнес-логику (нужно где-то хранить временну́ю метку);
- это поллинг, нужен внешний процесс с регулярными запросами, который замедляет базу данных;
- в простых реализациях не позволяет получать события удаления строк.
Существуют модификации этого подхода, которые позволяют убрать некоторые недостатки за счёт усложнения схемы, но суть не меняется. Вот что можно добавить:
- номера версий в строках;
- индикаторы состояния в строках;
- время / версия / статус в строках.
2. Триггеры на таблицах
В этом случае вы заводите специальную таблицу с историей и настраиваете триггеры, которые срабатывают при изменении или удалении строк.
Плюсы подхода:
- он работает;
- изменения захватываются мгновенно и позволяют получить процессинг в реальном времени;
- триггеры могут захватывать все типы событий, включая удаление;
- триггеры могут добавлять полезные метаданные.
Минусы подхода:
- триггеры нагружают и замедляют базу;
- триггеры вносят изменения в базу данных;
- требуется внешний процесс вычитывания истории изменений;
- создание и мейнтейнинг триггеров может быть сложной задачей, особенно учитывая эволюцию схем.
3. Логическая репликация (работа с wal — Write-Ahead Log)
Каждая база данных для обеспечения гарантий ACID содержит Write-Ahead Log — лог изменений, закодированный в бинарном формате: в PostgreSQL это называется wal, в MySQL — binlog, в Oracle — redo-log, в MongoDB — oplog, в MSSQL — transaction log.
По сути такой лог уже содержит то, что нам нужно, остаётся только раскодировать его и отправить в очередь сообщений.
Правда, иногда появляются внезапные ограничения. Например, в случае PostgreSQL этот подход не дружит с pg_repack.
Плюсы подхода:
- процессинг получается в реальном времени;
- захватываются все типы изменений: и insert, и update, и delete;
- это не требует дополнительного механизма хранения данных, как в случае с триггерами, например; все данные хранятся в wal-логе;
- в основном это не поллинг, поэтому не создает ощутимой дополнительной нагрузки на базу. Все что нужно — это последовательно читать wal с диска, декодировать его и отдавать. Обычно это не ощутимо.
Минусы подхода:
- зачастую требуется отдельная роль;
- на очень старых версиях баз данных этого механизма может не быть;
- если неправильно настроить репликацию (например, не ограничить рост wal'a), то в случае, когда читатель перестает читать лог, wal начинает расти и может занять весь диск, переведя базу в read-only режим. Поэтому настраивайте отстрел репликационных слотов в PostgreSQL по лимиту.
Исторический обзор: как CDC-инструменты и подходы развивались на практике
Широкую известность CDC получил после фундаментальной статьи Мартина Клеппмана 23 апреля 2015 года "Bottled Water: Real-time integration of PostgreSQL and Kafka" — я крайне рекомендую ознакомиться с ней для расширения кругозора. Клеппман популяризирует подход CDC через декодирование wal-лога PostgreSQL с последующей отправкой событий в Apache Kafka и выкладывает исходный код проекта «Bottled Water». В статье он приводит ссылки на пару уже существующих проектов: Databus от LinkedIn (2012) и Wormhole от Facebook (2013). В то время в описаниях этих проектов ещё не звучало название Change Data Capture, но усилиями Клеппмана понятие завоевало популярность.
Таким образом, работа Клеппмана популяризировала и сам CDC-подход в общем, и реализацию CDC через декодирование wal-лога в частности.
Вскоре после этой статьи на GitHub появилось примерно полтора десятка проектов, реализующих то же самое для MySQL — их даже собрали в единый каталог.
В основном сейчас там все проекты мертвые, но можно выделить:
Спустя полгода после выхода статьи Мартина Клеппмана появился проект Debezium, подробнее о нём расскажу в следующем блоке.
Несколько реализаций CDC в опенсорсных база-неспецифичных проектах:
База-специфичные CDC:
Также механизм CDC реализован в закрытых инструментах некоторых облачных вендоров.
Таким образом, работа Клеппмана популяризировала и сам CDC-подход в общем, и реализацию CDC через декодирование wal-лога в частности.
Вскоре после этой статьи на GitHub появилось примерно полтора десятка проектов, реализующих то же самое для MySQL — их даже собрали в единый каталог.
В основном сейчас там все проекты мертвые, но можно выделить:
- Maxwell, который развивается до сих пор,
- Сanal — разработку Alibaba, которая интегрирована с китайскими Apache-инструментами.
Спустя полгода после выхода статьи Мартина Клеппмана появился проект Debezium, подробнее о нём расскажу в следующем блоке.
Несколько реализаций CDC в опенсорсных база-неспецифичных проектах:
- Airbyte. Может поставлять CDC из MySQL/PostgreSQL/MSSQL, обещают добавить поддержку Oracle.
- Nifi. Реализует CDC для MSSQL, интегрируется с Debezium, также позволяет организовать CDC через временны́е метки на строках.
База-специфичные CDC:
- CDC в YDB. Есть нативный механизм создания CDC, но есть и интеграция с Yandex Data Transfer (об этом ниже).
- CDC в Google BigQuery.
- Oracle Golden Gate — CDC для баз данных Oracle.
- Dynamo DB Streams — CDC для DynamoDB.
- CDC для Аpache Ignite.
- Встроенный в MSSQL инструмент.
- CDC в CockroachDB.
- IBM Infosphere CDC.
Также механизм CDC реализован в закрытых инструментах некоторых облачных вендоров.
На просторах GitHub я нашел лишь один проект (и тот малоизвестный), который реализовывал бы CDC не через декодирование wal-лога, а через версии на строках. На современном рынке CDC-решений значительную часть занимает проект Debezium, основанный на декодировании wal-лога. Так что рассмотрим его подробнее.
Debezium — самая популярная реализация CDC
Debezium сегодня является стандартом де-факто в мире CDC. Он появился в 2015 году силами разработчиков из Red Hat и сейчас поддерживает 9 популярных источников: MySQL, MongoDB, PostgreSQL, Oracle, MSSQL, Db2, Cassandra, Vitess, Google Spanner. Изначально инструмент был только Kafka-коннектором, но в 2020-м появился проект Debezium Server, который умеет отправлять события во все популярные очереди.
Проект написан на Java, исходники лежат на GitHub под свободной лицензией Apache 2.0, в основном проекте 447 контрибьюторов.
Debezium поддерживает три формата сериализации событий: json (default), avro и protobuf. Сериализаторы модульны и параметризованы, и можно как настроить любой из существующих сериализаторов, так и написать свой. Поддерживаются интеграции с различными Schema registry. Также поддерживаются трансформации, интеграция с мониторингами, есть UI.
А ещё Debezium выдаёт формат данных, единый для всех БД. Таким образом, научившись обрабатывать дебезиумные потоки из MySQL, вы практически тем же кодом можете обрабатывать дебезиумные потоки и из любых других поддерживаемых Debezium баз данных.
В общем, проект уже достаточно зрелый, чтобы быть надёжным решением, но всё ещё быстро развивается, богат на фичи и интеграции, с обилием материалов и документации. Предоставляются удобные Docker-контейнеры с Debezium, которые позволяют ставить эксперименты за считанные минуты, к тому же есть замечательный официальный репозиторий с демо-примерами.
Как Yandex Data Transfer пришёл к CDC
Yandex Data Transfer появился как сервис миграции баз данных в облако. Когда пользователям необходимо заехать в облачную базу данных (managed database), как правило, у них уже есть база данных на железе (on-premise) и нужно мигрировать эти данные в облако.
Data Transfer решает задачу следующим образом: сначала переносится снапшот базы данных, после чего к базе-приёмнику применяются все изменения, произошедшие на базе-источнике с момента взятия снапшота. В итоге в облаке получается асинхронная реплика базы данных, остаётся только отключить пишущую нагрузку на базу-источник, подождать несколько секунд, пока реплика догонит мастера, и включить нагрузку уже на базу в облаке.
Таким образом можно мигрировать в облако с минимальным даунтаймом.
Со временем помимо задачи миграции сервис начал использоваться для переливания данных между разными БД, например, из транзакционной в аналитическую, а также между очередями сообщений и между базами данных и очередями. Если свести все поддерживаемые варианты трансфера в одну матрицу, видно, что Data Transfer сразу умеет работать и со снапшотами, и с репликационными потоками данных, горизонтально масштабируясь и шардируясь.
В терминологии сервиса есть две основных сущности:
- Эндпоинт — это настройки подключения + дополнительные настройки. Эндпоинт может быть либо источником, из которого выгружаются данные, либо приёмником, куда данные загружаются.
- Трансфер, который соединяет эндпоинт-источник с эндпоинтом-приёмником. Содержит собственные настройки, прежде всего тип трансфера: снапшот, репликация, снапшот+репликация.
После того как трансфер создан, его можно активировать разово, или же можно настроить активацию по расписанию. В случае снапшота таблицы переливаются, и затем трансфер деактивируется сам. В случае репликации запускается бесконечный процесс переноса новых данных из источника в приёмник.
Data Transfer написан на Go, работает как решение cloud-native — есть контрол-плейн, отвечающий за API и управление дата-плейнами, а на активацию пользовательских трансферов создаются дата-плейны в рантаймах. Например, среди поддержанных рантаймов есть Kubernetes (k8s) — т.е. на этом рантайме на активацию трансфера в k8s запускаются поды. Таким образом, это самостоятельный сервис, работающий поверх некоторого рантайма: помимо Kubernetes поддерживаются Yandex Cloud Instance Groups, YT и локальный рантайм. Data Transfer на активации трансфера создаст в рантайме виртуалки в нужном количестве и начнёт переливку данных. В несколько кликов можно настроить поставку данных на гигабайты в секунду.
Сервис уже несколько лет успешно эксплуатируется внутри Яндекса в боевых продакшнах с солидными объёмами данных. Вдобавок к тому, что сервис изначально горизонтально масштабируемый, мы научились параллелиться везде, где это возможно, и сейчас во внутренней инфраструктуре бежит почти две тысячи потоков данных, перенося гигабайты в секунду.
Помимо этого мы реализовали наиболее часто запрашиваемые ETL-преобразования, и возможности ETL в дальнейшем будут только расширяться. Настраивать можно как через удобный UI, так и через API и Terraform.
Всё это привело к тому, что Data Transfer стал универсальным сервисом переноса данных из любого источника в любой приёмник (с возможностями ETL-процессинга): как снапшотов, так и потоков данных — и пользователи помимо применения сервиса по прямому назначению придумали массу неочевидных способов использования. CDC является лишь одним способом применения сервиса Data Transfer из множества.
Как реализован CDC в Yandex Data Transfer
Поскольку Yandex Data Transfer с момента создания получал репликационный поток на уровне логической репликации, естественным шагом было научиться отдавать это пользователям. Именно это превращало Data Transfer в CDC-решение, работающее через обработку wal-лога.
Реализовывать отгрузку событий логической репликации в очередь мы начали по пользовательским запросам, и было принято решение порождать события в формате Debezium, чтобы мы могли стать drop-in replacement для Debezium. Так можно было бы в настроенном пайплайне подменить один CDC-продукт другим, и пайплайн остался бы рабочим. Таким образом и мы бы получили полезные интеграции, и в мире не появилось бы нового формата данных.
{kind=link}
Соответственно нужно было сделать конвертеры из наших внутренних объектов в сериализованный Debezium-формат и покрыть это миллионом тестов, что мы и сделали.
На данный момент в Data Transfer сериализатор реализован для PostgreSQL и MySQL-источников, а недавно появилась поддержка YDB-источника. Теперь вы можете в несколько кликов настроить поставку CDC из ваших таблиц YDB в Apache Kafka и в YDS в формате Debezium.
Вскоре после поддержки YDB появилась и поддержка Schema Registry, что на порядок уменьшает объёмы передаваемых данных и даёт дополнительные плюшки. В планах получить ещё больше интеграций с различными опенсорс-сервисами.
Таким образом, для MySQL и PostgreSQL получился drop-in replacement для Debezium. Из крупных отличий: Data Transfer умеет переживать переезд мастера PostgreSQL (ситуация, когда реплика становится мастером) при включенном плагине pg_tm_aux, а также сервис умеет переносить user-defined types в PostgreSQL.
Также в Data Transfer реализовали возможность организовывать query-based CDC — в документации это называется «инкрементальные таблицы», а на внутреннем сленге мы этот режим исторически называем «доливочки».
Недавно у нас вышел вебинар по использованию Data Transfer в нетривиальных кейсах.
Реальные кейсы использования CDC через Data Transfer
Расскажу про популярные пользовательские кейсы.
- Самый распространённый вариант — использование CDC для создания реплик транзакционных баз (PostgreSQL, MySQL, YDB) в аналитических хранилищах (ClickHouse, YTsaurus). Сохранение событий в очередь выгружает данные из транзакционной БД один раз, а аналитических баз-приёмников как правило по две — по одной в каждом дата-центре, чтобы гарантировать DC-1.
Проблема
Продакшн-процессы бегут в транзакционных базах данных, а бизнесу интересно получать аналитические отчёты, которые удобно делать через аналитические БД. Поскольку HTAP-базы — ещё экзотика, нужно каким-то образом перекладывать данные из транзакционной базы в аналитическую.
Было
Обычно все команды переливают данные из транзакционной базы в аналитическую через собственные ad-hoc скрипты или in-house решения снапшотами, в лучшем случае query-based CDC. Как правило, это не оформлено в продукт и неудобно для использования.
Стало
CDC позволяет удобным образом, например, через UI, организовать реплику транзакционной базы в аналитическую с отставанием реплики в районе единиц секунд.
- Наши коллеги из Яндекс Маркета организовали схему, похожую на описанную, но с любопытными отличиями.
Проблема
Нужно было выгружать продакшн-данные из PostgreSQL в YTsaurus для аналитики, желательно с минимальным отставанием.
Было
Когда-то давно использовался самописный сервис на java, который раз в сутки выгружал снапшот.
Потом был написан ещё ряд скриптов для выгрузки, а после этого использовался ещё один внутренний сервис, который уже умел производить query-based CDC. Но заводить новую поставку данных было сложно.
Стало
Ребята организовали поставку инкрементальных таблиц в кросс-датацентровую очередь с регулярным запуском — это один трансфер, а два других трансфера с типом «репликация» — из очереди в YTsaurus. Два трансфера нужны для обеспечения гарантии DC-1 — каждый из этих двух трансферов поставляет данные в инсталляцию YTsaurus в отдельном дата-центре.
Сама очередь тут даёт дополнительный эффект: в транзакционную базу осуществляется один поход, а данные оказываются в двух аналитических базах.
В итоге у команды Маркета три трансфера: один сам запускается по расписанию и выгружает новые строчки, два бегут постоянно в режиме репликации, выгружая данные из очереди в аналитические хранилища.
- Коллеги из Яндекс Недвижимости начали использовать CDC, чтобы обновлять поисковые индексы Elasticsearch, потом применили CDC для реактивного взаимодействия компонентов, и в конце концов — CDC стал неотъемлемой частью проекта.
Проблема
При изменении данных в MySQL нужно было обновлять индексы Elasticsearch.
Было
До CDC пришлось бы реализовывать transactional outbox pattern. Но поскольку с появлением задачи в Yandex Data Transfer уже был CDC — сначала реализовали отгрузку событий в очередь и сделали скрипт, обрабатывающий события из очереди.
Стало
Yandex Data Transfer позволил организовать процесс обновления поисковых индексов, после чего коллеги, оценив удобство организации реактивной инфраструктуры, нашли множество применений CDC. Теперь они с помощью CDC: отправляют пуши и нотификации, проксируют данные во внешнюю CRM, планируют задачи, реактивно реагируют на промокоды, и ещё много чего.
- Коллеги из Яндекс Метрики превратили MySQL/PostgreSQL при помощи CDC-событий в потоковую базу данных, работающую поверх YTsaurus. Созданный инструмент назвали «инкрементальные материализованные представления».
Проблема
В метрике есть MySQL с настройками, в который множество сервисов ходит забирать эти настройки.
Было
Запускать все сервисы в MySQL — не вариант, поскольку это создавало серьезную нагрузку.
Сначала были организованы кеши — кеширующие сервисы периодически ходили за настройками в MySQL, и все остальные сервисы ходили в кеширующие сервисы.
Но со временем кеширующие сервисы стали потреблять много ресурсов и начали заметно отставать до пары десятков минут. А сервисы, ходящие за настройками, начали рестартоваться слишком долго, поскольку долго инициализировали свои кеши.
Стало
Была разработана потоковая база данных, потоковый аналог связки airflow+dbt, где DAG'и пересчитывают производные данные только для изменившихся строчек, реактивно реагируя на CDC-события.
В итоге кеши стали отставать в среднем на 5 секунд вместо десятков минут до этого. Сервисам удалось избавиться от локальных кешей, что сэкономило много RAM, и сервисы стали рестартиться быстро. Надеюсь, когда-нибудь коллеги расскажут об этом решении подробнее.
Подведём итоги
В статье мы рассмотрели Change Data Capture со всех сторон: история возникновения, теория, сценарии применения, опенсорс-практика, корпоративная практика и реальные пользовательские истории.
Чтобы узнать о CDC больше, смотрите вебинар, читайте статью Мартина Клеппмана, экспериментируйте с Debezium и Yandex Data Transfer.
Отмечу, что Yandex Data Transfer — бесплатный сервис в Yandex Cloud.
Приходите пользоваться, оставляйте фидбек и фичареквесты.
Что ещё почитать по рассмотренным темам
- CDC и Redis
Несколько докладов:- RedisCDC: Seamless database migrations and continuous changed-data replication
- Cache Prefetching: Building an efficient and consistent cache with RedisCDC
- CDC Replication to Redis from Oracle and MySQL
Пара примечательных статей:
- Паттерны проектирования микросервисов
- Обзорная статья для более глубокого понимания всех тонкостей отличия похожих паттернов друг от друга:
Distributed Data for Microservices — Event Sourcing vs. Change Data Capture - Полезное чтиво про outbox pattern и CDC:
Reliable Microservices Data Exchange With the Outbox Pattern - Полезное чтиво про CQRS:
DDD Aggregates via CDC-CQRS Pipeline using Kafka & Debezium
CqrsWithCDC на GitHub
Building CQRS views with Debezium Kafka Materialize and Apache Pinot: part 1
Building CQRS views with Debezium Kafka Materialize and Apache Pinot: part 2 - Полезное чтиво про Strangler:
Application modernization patterns with Apache Kafka, Debezium, and Kubernetes
- Обзорная статья для более глубокого понимания всех тонкостей отличия похожих паттернов друг от друга:
- Хорошая статья про способы реализации в PostgreSQL:
PostgreSQL Change Data Capture (CDC): The Complete Guide - Про метод «инкрементальных снапшотов» — очень нетривиальную и изящную технологию, позволяющую совместить перенос снапшота с репликацией и заодно не думать о росте wal.
- О реализации в блоге Debezium:
Incremental Snapshots in Debezium - О реализации в теоретической работе от Netflix:
A Watermark Based Change-Data-Capture Framework
- О реализации в блоге Debezium:
mark_ablov
CDC через чтение WAL лога не позволяет обеспечить транзакционность между изменением и уведомлением об этом изменении. К примеру, мы хотим всегда быть уверены что при изменении записи в исходной базе, мы успешно отразим это в другом сервисе. И если это не получилось сделать, то нужно откатить исходное изменение. Transactional outbox в данном случае куда применимее.
timmyb32r Автор
Вся разница между outbox и transactional outbox заключается в том, что в первом случае изменения хранятся в wal логе, а во втором случае - в таблице.
Процессы нотификации другого сервиса в обоих случаях асинхронные - а стало быть и откатывать состояние могут одинаково.
Откатывание стейта связанных микросервисов - это же паттерн saga, но его реализуют и на обычном outbox.
mark_ablov
Ну кроме самих изменений хочется хранить еще мета-информацию о статусе синхронизации. Скажем, в табличку я могу докинуть поле, которое отражает успешно ли сообщение отправлено брокеру или нет, время последней попытки, еще какие-то связанные метрики, и т.д. В случае с WAL-логом сложно будет обеспечить дискретность сообщений - придётся всё равно где-то state хранить.
Опять же с табличкой есть вариант делать оркестрацию на самом сервисе, а если у вас WAL вычитывает кто-то еще, то да, хореография с сагами скорее всего неизбежны.
PS: transactional outbox можно запилить не только на триггерах. Для такого паттерна мы используем возможности ORM'ки - в хуках транзакция не закрыта и можно докинуть в неё нужные SQL выражения.
timmyb32r Автор
Круто! Видел похожий подход в статье https://debezium.io/blog/2018/09/20/materializing-aggregate-views-with-hibernate-and-debezium/
правда там ORM'кой таблички джойнили для CDC, а не transactional outbox организовывали.