

Всем привет, меня зовут Роман. В ИТ я больше 15 лет — начинал как системный администратор, сейчас SRE-инженер. Расскажу, как мы дошли до семи петабайт логов в Elastic и как он устроен.
Поделюсь некоторыми архитектурными принципами для нашего большого хранилища, когда мы его создавали. Какие принципы и как мы ими руководствовались. Расскажу, почему нас перестали устраивать стандартные компоненты.
Sage — предыстория и архитектура
В нашем случае Elastic — это база данных для хранения логов, которая находится под капотом Sage.
В 2019 году у нас бизнес-мониторинг и все бизнес-показатели собирались в Splunk — это такой Elastic на стероидах, заточенный под логи. У него очень крутой язык запросов.
В Splunk было очень много логов — собирались они из сотен всяких систем, также использовалось много дашбордов на логах. И, естественно, были алерты — тоже на логах. И тут внезапно Splunk решил уйти из России (совсем). Лицензию нельзя продлить, поддержку нельзя купить — ничего нельзя.
Мы посмотрели на рынок и не нашли ничего подходящего, что бы могло эту систему заменить. Поэтому решили сделать свою систему для логов, с алертами и всякими штуками.

Примерно так и появился Sage. Изначально он задумывался только для логов, но в итоге вмещает в себя и логи, и метрики всех сервисов в Тинькофф. Он уже решает такие задачи, как сбор метрик и логов, а также запросы к ним.
Запросы пишем на собственном языке, потому что мы хотели повторить язык Splunk, а встроенный язык Elastic этого не позволял. У системы есть свой UI, в котором можно визуализировать данные по запросам. Еще мы написали плагин для Grafana, сделали алертинг и предоставили возможности для интеграции. Поиск, которым мы сделали свой язык запросов, — это поисковая API, готовая к любой интеграции.
Вот архитектурная схемка Sage для понимания, какую часть в ней занимает Elastic:

Как устроен Elasticsearch
Прежде чем строить свою систему для логов, мы составили список требований к этой системе:
Полнотекстовый поиск, потому что такой у нас уже был в Spunk. На основе такого поиска было настроено много всего, что мы хотели перенести в новую систему. К тому же полнотекстовый поиск — это свобода: можно искать что угодно, а не только то, что размечено.
Open Source, потому что мы хотели дорабатывать самостоятельно решение. У нас все этим заканчивается, что бы мы ни выбрали — допиливаем под себя. Думаю, многие так делают.
On-Premise — чтобы хранить свои логи у себя, и регуляция так проще.
Горизонтальное масштабирование, потому что логи разрастаются. Чем больше систем, тем больше логов будет.
Стать заменой Splunk после всех доработок. На момент выбора ничего лучше Elastic не было. А еще у нас уже была экспертиза по Elastic, причем они работали с кластерным режимом и казалось, что мы делаем правильный выбор.
Все любят этот мем, я тоже его очень люблю, к Elastic он идеально подходит:

Основная единица в Elastic — индекс:
. Внутри сегментов лежат документы (Lucene Documents). Они, в свою очередь, содержат последовательность полей — это как раз те самые документы, которые мы туда изначально и пишем")
Еще у нас есть несколько нод, чтобы кластер Elastic был устойчивым. Нод может быть много, они могут объединяться в кластер:
. Там указано, что такой-то шард лежит на одной ноде, а вот этот шард — на другой. Все это и есть индекс — просто абстракция над шардами. Шарды бывают primary и replica: реплик может быть несколько, все зависит от replication-фактора. Сначала аллоцируется primary, а потом replica. И primary не может находиться на одной ноде с репликой. После того как replica-шарды аллоцируются, туда реплицируются данные. Вот так и появляются индексы, которые размазываются по нодам")
Архитектурные принципы большого хранилища логов
Sage сейчас обрабатывает в Тинькофф суммарный поток с нескольких дата-центров — примерно 3,5 ГБ в секунду. Когда поток логов становится большим, могут быть проблемы, вплоть до того, что этим трафиком начнет захлебываться сеть. Поэтому нужна распределенная архитектура, которая позволит, с одной стороны, сделать отказоустойчивость, а с другой — при отказе системы обеспечить понятную и минимальную деградацию.
Перечислю архитектурные принципы распределенной системы, которыми мы руководствовались.
Data per data center — это значит, что у нас минимум взаимодействия между ЦОДами. Мы не переливаем логи из одного дата-центра в другой. Получается, где логи родились, там они остаются и живут вплоть до самой смерти.
Есть много сборщиков логов: Filebit, fluentbit, vector и другие. Еще бывает, что приложение умеет само напрямую писать логи. Полученные так или иначе логи записываем в Kafka. У нас один кластер Kafka на дата-центр, получается, это входная точка системы. Как туда записывать логи, решает клиент: filebit поставить или записать напрямую из приложения. Потом мы вычитываем логи из Kafka с помощью нашей замены Logstash, обрабатываем и записываем в Elastic.

Кросс-дата-центровый поиск — между дата-центрами есть трафик, но мы стараемся делать так, чтобы этот трафик был только поисковый.
В дата-центре данные лежат в кластере Elastic, и таких кластеров у нас много. Есть один особый кластер Elastic, настроенный на то, чтобы проксировать запросы на кластеры Elastic с данными. Такой кластер называется Elastic Proxy Cluster, и его задача — собрать и объединить результаты поиска, если данные лежат в разных кластерах.
Над Elastic Proxy Cluster находится поисковый движок, который ходит в Proxy Cluster, и Elastic выполняет за него основную работу. Выглядит просто до тех пор, пока не появляется второй дата-центр.
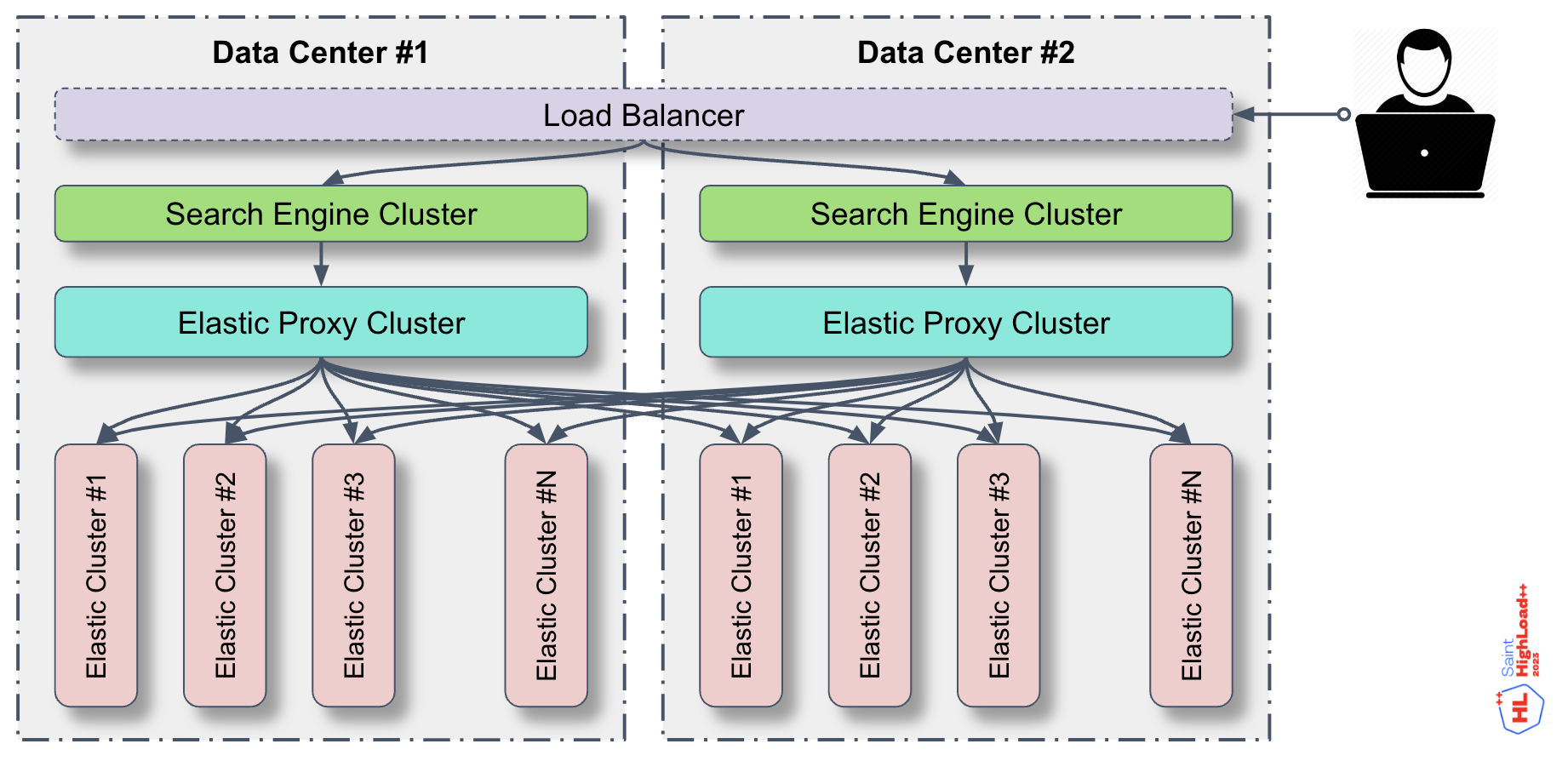
Например, данные есть в кластере Elastic#1 в DC1, а еще данные есть в таком же кластере, только в DC2. Нужно поискать и там, и там — и получить не просто две пачки данных, а чтобы они были логически объединены.
Мы решили прописать в Proxy Cluster одного дата-центра кластера Elastic из другого. Получилось, что каждый Proxy Cluster смотрит во все кластеры Elastic. Возможно, когда-нибудь мы перенесем это к себе в поисковый движок, но пока все работает именно так.
Над всем этим есть кластер балансировщика, который обеспечивает единую точку входа для пользователя: сюда приходят поисковые запросы.
Делаем небольшие кластеры Elastic — со временем пришли к такому решению, отказавшись от одного большого кластера. Наш большой кластер Elastic тяжело работал. Мы разделили его на несколько маленьких и получили плюсы:
У нескольких маленьких кластеров Elastic меньше вектор поражения. Если происходит сбой, деградация или проблемы в каком-то кластере, страдают только те клиенты нашей системы мониторинга, которые находятся в этом кластере, и это не задевает остальных.
Меньше Cluster State: у маленького кластера логично, что меньше состояние, которое хранит записи обо всех шардах, маппингах и всем прочем — все то, что находится в кластере. И этим Cluster State постоянно обмениваются все ноды в кластере. Если этот Cluster State какая-то нода не примет, не обработает, такая нода, скорее всего, вылетит из кластера. А значит, кластер работает менее стабильно, чем когда у него небольшой Cluster State.
В определенный момент появилось ощущение, что кластер стал очень большой: много индексов и клиентов. После разделения одного большого кластера на маленькие все стало работать стабильнее и быстрее.
У подхода есть и минусы:
Для большого количества маленьких кластеров нужно больше накладных расходов: каждому кластеру, кроме нод с данными, нужны мастер-ноды. Мы вынесли мастер-ноды на отдельные хосты из-за того, что кластера часто разваливались. Поэтому мастер-ноды придется делать под каждый мелкий кластер.
Если чего-то стало больше — то и сопровождать это, как правило, сложнее.
Могут быть клиенты, которые не влезают в такой кластер. Наших клиентов мы поделили на группы, для каждой группы выделили квоту — тот максимум, сколько клиент может заливать логов.
Однажды случилось, что клиент попросил квоту, которая по размеру не влезет ни в один кластер. Мы предложили разбить эту группу на две поменьше и вот так обойти ограничение. И в дальнейшем решаем вопрос так же — не выдаем квоту, а делим группу на две поменьше.
Стандартный кластер Elastic устроен так:
 максимально равномерно. Поэтому надо учитывать количество нод, чтобы оно было делителем для количества шардов. Есть warm-ноды — туда данные переезжают «остывать». Обычно это нужно, когда данных очень много и они должны еще полежать, возможно, в них будут осуществляться поиски. Может, интеграция сделает какие-нибудь отчеты на больших объемах. И там уже диски медленные — HDD на шпинделях. Сверху находится proxy-кластер. Эту историю мы также сделали тиражируемой: стандартный прокси-кластер — это три ноды")
Практически сразу мы поняли, что для многопользовательской системы, в которой ресурс может закончиться, нужна квота — какой-то лимит, ограничение. Иначе такая система недолго проживет, потому что любой может залить ее логами, если нет никакого ограничения, какой бы запас ресурсов туда ни заложили. Любой может написать какой-нибудь клевый скрипт с огромным количеством полей, генерацией логов, и будет не очень весело.
Без квотирования не получится планировать ресурсы системы (так называемый capacity planning). Непонятно, сколько и когда закупать, сколько «дров подносить». И сложно будет настраивать какие-либо подсистемы, такие основы, как шарды, сколько их, retention, сколько хранить, где хранить, когда перевозить.
Есть одна плохая новость: у Elastic нет встроенного механизма квотирования. Я много статей пересмотрел, но, кажется, все делают подобные вещи своими средствами: вначале ставят какой-то ограничитель либо используют Kafka, потому что на ней есть квоты.
Мы используем Kafka Quotas для того, чтобы ограничивать логи по группам, у каждой группы есть своя квота и свои нюансы.
Формат и валидация логов
Чтобы упростить пайплайн процессинга логов и не делать много предобработки, мы решили, что необходим единый формат логов.
Слишком жесткий формат усложнит интеграцию с лог-системой, поэтому формат должен решать какую-то реальную задачу и быть минимально необходимым.
Наши требования к формату:
Принимаем на вход только JSON — кажется, что это уже и так стандарт, который поддерживается примерно всеми коллекторами и смежными системами.
Обязательные поля: timestamp — стандартное поле в ISO8601, group — объединение, на которое завязаны права доступа к логам + квоты. Деление может быть любым: продуктовая команда, подразделение, отдел, system — обычно внутри группы есть логи от разных приложек или систем, это поле поможет их сразу отфильтровать, env — редко кто смотрит логи из prod/test/stage в одной куче вперемешку.
Теперь можно раскладывать логи по индексам с учетом наших полей:
logs.<group>.<system> -000001
logs.<group>.<env> -000001
logs.<group>.<env>.<system> -000001У нас индексы формируются вот так:
logs.<env>.<group>.<system> -000001Профиты:
Сразу видно, где чьи логи.
Просто настроить политики ротации, например, удалять логи с теста пораньше: logs.*.test.
Можно сделать сбор метрик в разрезе индексов — удобно для overview по индексам или нодам.
Перед тем как записать логи в Elastic, их нужно валидировать, иначе формат никто не будет соблюдать:
Валидный JSON — мы же решили, что у нас на входе только JSON. Как ни странно, это надо проверять.
Обязательные поля — без проверки их наличия и совпадения требованиям они перестают быть обязательными примерно через секунду.
Кажется, все продумали, да? ????

Как бы не так! Предположим, к вам начали прилетать логи, у которых в поле system вот такое:
0408aee0-6a29-4f8a-9d61-f68866e8813f
169d8399-668f-4d6d-b694-c490ed76702f
95af9011-3294-4e0d-9399-209392a124dfКогда в поля, используемые для формирования названия индекса, протекает что-либо с большой вариативностью, то индексов становится очень много и кластер Elastic начинает деградировать (cluster state: index, mapping).
— Окей. Уже можно логи заливать?
— Рано! ✋
Надо еще решить, что делать, когда к нам начнут прилетать логи, не соответствующие формату. А они начнут, не сомневайтесь.
Сделали корзину — специальный индекс dead letters. В нем можно посмотреть исходник лог-сообщения, а также причину, по которой оно туда попало. Без этого пользователям будет непонятно, что не так и как починить это на своей стороне.
???? Совет: сделайте метрику с количеством DL в разрезе групп.
— Дай угадаю, еще не все?

Вот что мы еще валидируем или контролируем:
размер сообщения: не более 1 МБ;
максимальный уровень вложенности полей: после 10-го уровня объекты конвертируются в строки;
количество полей в логе: не более 1000, в индексе: не более 1500;
длина данных в поле: не более 1 млн символов;
длина имени поля: не более 1000 символов;
названия полей:
^[a-zA-Z@][a-zA-Z0-9-]+$;кол-во индексов: на группу не больше 100;
типы полей в mappings.
Динамическая схема — mapping. Когда в новый индекс попадает сообщение с полями и данными в них, Elastic индексирует поля на основе данных в этом поле: на ходу создается схема данных — dynamic mapping. Ошибки конфликта полей — очень частая проблема в Elastic!
???? Совет: про ошибки конфликтов полей надо обязательно писать в dead letters. А еще такое хорошо бы мониторить и оповещать об этом пользователей.
Sensitive-данные в логах. Наверняка очень скоро вам понадобится срочно удалить какие-то определенные логи, обычно когда туда протекли персональные данные или sensitive-данные — пароли или токены.
???? Мы проверяем это автоматически на потоке.
???? Совет: заранее придумайте и протестируйте процесс поиска sensitive-данных и удаления их (автоматически или по требованию).
Замена стандартных компонентов стека Elastic
Сначала у нас был Logstash, но мы отказались от него по ряду причин.
Не умел в кластер, а нам хотелось масштабировать горизонтально. У нас много клиентов, которые заливают логи. Мы их поделили на группы, и у каждой группы есть свой топик. Мы хотели распределять это между инстансами нашей переливалки, а в Logstash так не получалось.
Умная работа с Elastic. Иногда Elastic может затупить, и если в этот момент его еще больше нагружать, скорее всего, ничем хорошим это не закончится. Мы хотели создать такую обработку, чтобы не перегружать Elastic, если у него проблемы.
Требовалась сложная валидация полей. Нам важно было проверять не только содержимое полей, но и количество. Мы хотели делать это в разрезе групп и пользователей. А еще был набор всяких нужных штук, которые мы решили написать самостоятельно.
Работал недостаточно стабильно. Мы постоянно получали какие-то проблемы: то
Logstash перестает читать, то записывать. Также Logstash на разные ошибки Elastic может реагировать не очень адекватно. Любая валидация, которую мы пытались сделать, получалась слишком затратной по ресурсам, а как оптимизировать, мы не придумали. Решили, что проще сделать что-то свое.
В итоге вот что умеет наша замена Logstash:
Умно обрабатывать ошибки от Elastic. Например, она делает ретраи, когда есть какие-то некритичные ошибки. Когда Elastic затупил, мы можем поретраить.
Для ошибок, которые нельзя в моменте обработать, мы сделали специальные error-топики в Kafka, и некоторые ошибки мы складываем в эти топики. Такой подход позволяет сразу перейти к следующей пачке логов и процессить ее, а все остальные отложенные логи дообработать потом.
У нас есть Circuit Breaker — когда Elastic плохо, он закрывает заслонку и ждет, чтобы Elastic стало лучше. Потом постепенно увеличивает нагрузку и доливает то, что осталось. А еще есть встроенная защита от дублей.
Kafka consumer под каждый топик, это позволяет делать быструю ребалансировку. Наши замены Logstash успешно работают в кластере, потому что, если так не делать, работает намного медленнее. И переподключение, ребалансировка с Kafka занимает много времени.
Киллер-фича: фиксит работу с типами полей. Есть в Elastic частая проблема с типами полей. Это происходит из-за того, что может случиться несовпадение типов полей.
Например, создали индекс и записали туда лог, в котором есть поле. В поле попало цифровое значение. А чуть позже прилетел лог, в котором такое же поле, с таким же именем, и там объект. Elastic на это дело скажет exception и не будет это записывать. Так работает динамический маппинг: какой тип поля первым упал, такой и будет.
В таких случаях мы создаем новый индекс и записываем туда первым логом тот, в котором тип поля с новым типом. В нашем случае — объект. Тогда Elastic считает, что все хорошо. Такой подход работает, если у нас не скачут objects и integers через один лог.
Наша тула делает это в автоматическом режиме. Она видит, что тип поля поменялся, откладывает этот лог, ролит индекс, создает новый, пытается записать проблемный лог, который был с ошибкой типа поля, заново в новый индекс. И все идет дальше, вмешательства не требуется.
Легко масштабируется, потому что мы изначально ее делали как кластер. Можно просто ввести ноду, а дальше она сама перераспределит между собой топики, индексы. Никаких перенастроек не требуется. Можно спокойно релизить, по одной ноде выводить, обновлять и так далее. Добавлять ноды тоже очень легко — добавили, а дальше оно там само все разберется.
Graceful shutdown позволяет правильно дозаписать логи, которые прервались по какой-то причине. Раньше, если в какой-то момент логи останавливались, а потом мы запускали запись заново, наша замена Logstash шла подбирать логи и записывала части, которые уже есть. Получались дубли, ловившие ошибки от Elastic.
Graceful shutdown позволяет дозаписывать то, что мы уже схватили, отпустить топики в Kafka аккуратно, а потом в Kafka запустить логи. И при следующем запуске будет намного меньше проблем и ошибок, а реальная запись в Elastic пойдет быстрее.

Своя реализация ILM
Index Lifecycle Management (ILM) — это встроенная в Elastic функциональность для управления жизненным циклом индексов.
В нашей системе мониторинга большинство запросов по логам делается в интервале от нескольких часов до суток. Через какое-то время логи можно переместить на более медленные ноды, где более медленные диски, а затем вообще удалить. Обычно хранить логи вечно не требуется. Этим и занимается Index Life Cycle Management в Elastic — проносит все данные через эти стадии.
Наш процесс достаточно простой и коррелирует с тем, как у нас живут данные:

Вот список того, что нам не хватило в стандартном ILM.
Настройки сезонности. Мы обнаружили, что у нас большая нагрузка на запись, поиски и чтение днем, которая уменьшается в несколько раз ночью.
Мы решили переместить на ночь процессы, которые днем занимают ресурсы и мешают процессингу логов. Например, мы хотели мержить ночью сегменты и перевозить шарды, потому что оказалось, что сегменты создают с не очень оптимальной структурой. Когда данные уже записаны, их можно скомпоновать, смержить и они будут занимать меньше места в памяти. А значит, и искать по ним что-то будет легче.
Разные политики в зависимости от потока. Встроенный ILM не умеет работать с потоком. Есть шарды, индексы, он знает их количество и время, когда их создали. А то, что группы данных могут быть разного размера, он не учитывает.
Мы настроили разные политики в зависимости от потока. Иногда это нужно для того, чтобы поменять политику уже созданного индекса задним числом, что-то внепланово перевести, или для решения каких-то проблем.
Логика на основе содержимого индекса, потому что ILM — простой парень: он видит дату создания индекса, отсчитывает от нее 14 дней и перевозит. А мы хотели, чтобы ILM учитывал, когда в последний раз был записан документ.
Распределение индексов с учетом наших групп. Мы сделали свою реализацию с учетом разного потока клиентов. У нас разное количество шардов учитывается на индексах, разные политики ротации. Мы мелкие индексы перевозим реже, а большие — почаще, потому что нам хотелось как можно оптимальнее тратить ресурсы.
У нас свой алгоритм распределения индексов клиентов по кластерам. Есть вместимость кластера — сколько туда может влезть логов, мы ее эмпирически высчитали. У нас есть большие клиенты, их сейчас около полутора тысяч.
Мы хотели этих клиентов равномерно распределить, потому что, как показывает опыт, поместить два огромных клиента на один кластер и свалить тучу мелких на другой не очень оптимально.
Надо помещать несколько больших клиентов и постепенно их размазывать более мелким клиентам вместе с большими. Поэтому в нашей туле написали такой алгоритм: он сам смотрит вместимость кластера, какие есть группы и какие квоты им выданы, и равномерно это распределяет между кластерами.
Если появилась новая группа, происходит перераспределение, и он может начать по-другому перекладывать данные и размазывать более оптимально с учетом новой группы. Перераспределяет он еще шарды, потому что встроенный ILM просто раскидывает шарды по количеству или по времени, а про поток опять же не знает и равномерную нагрузку делать не умеет. Мы умеем.
Сжатые указатели в Java
В 64-битной JVM указатели занимают в два раза больше места в памяти, чем в 32-битной. Внезапно.
Сжатые указатели → расходы на операцию сжатия/разжатия при каждом обращении к указателю, как следствие, падение производительности Elastic.

Нам не хотелось тратить ресурсы на это. Поэтому мы решили перейти на JVM Heap = 32 ГБ, и увидели повышение производительности.
Мониторинг
У системы мониторинга должен быть свой мониторинг. Потому что Elastic с таким объемом логов иногда будет требовать внимания и даже сбоить. И вот как мы это мониторим.
Node Exporter:
CPU (Used) — хорошо видно ноды, на которые свалился какой-нибудь жирный шард либо залип какой-нибудь Thread Pool.
RAM (Total, Used) — когда в потолке, значит, такая нода перегружена.
Network (Bytes, Packets, Errors) — Elastic очень чувствителен к проблемам на сети.
Disk Performance (Read/Write bytes/time) — Elastic постоянно проводит диагностику записи данных на диск, и если это происходит очень медленно, такая нода может быть выброшена из кластера.
Disk usage — напомню, что в Elastic есть настройка watermark (low/high), которая при превышении low не даст аллоцировать/создавать индексы на ноде, а превышении high — начнет свозить шарды с этой ноды.
NUMA — Non-Uniform Memory Access.
Elasticsearch Exporter:
Cluster status — смотрим в разрезе нод.
Nodes health — видим, когда ноды выпадают из кластера.
Shards — количество шардов по статусам: Active, Unassigned, Delayed, Unassigned.
Pending tasks — когда их долгое время много, значит, БЕДА!
Thread Pools — в разрезе нод и типа треда: generic, search, write.
Documents + Indexes size — по всплескам и резким провалам можно понять, что-то идет не так.
JVM Heap — по эмпирическим вычислениям, когда долго выше 85%, скорее всего, такая нода будет снижать производительность кластера.
GC — видно залипающие или тупящие ноды.
Кастомные метрики:
Master nodes — напомню, что в кластере Elastic всегда только один активный master, остальные master-ноды запасные (master eligible nodes), смена активного мастера — важное событие, знать про такое полезно.
Восстановление шардов — сразу понятно, если какая-то нода не вывозит или на ней долго что-то не восстанавливается. Однажды мы так деградирующую дисковую подсистему нашли.
Миграция шардов — очень полезные графики получаются, видно, как проходит ночной переезд шардов.
Merge — количество индексов, которые будут объединяться. Операция ресурсозатратная, но без нее будет деградация кластера, поэтому объем этой операции важно контролировать.
Indexes size — размер индексов в разрезе кластеров и группы.
Примерно так на метриках выглядит ночной переезд шардов:

Советы и планы
Несколько советов, к которым мы пришли опытным путем:
Сделать квотирование.
Вынести мастер-ноды на отдельные хосты.
Вынести мастер-роль на отдельные ноды.
Равномерно разложить шарды по нодам.
Рестартовать залипшие ноды Elastic.
Кажется, мы выжали из Elastic все, что можно. Иногда страдали, иногда экспериментировали. И пришли к тому, что хотим перейти на собственную базу данных для хранения логов.
Ведь изначально Elastic не задумывался именно для логов, просто однажды кто-то попробовал их туда залить — и понеслось.
В планах у нас:
разработка более жесткой схемы данных;
отключение индексации всех полей по умолчанию;
автоматическая блокировка проблемных запросов;
переключение на запись свежих логов в случае сбоя, а работа с долгом — потом;
переход на БД собственной разработки — SageDB.
Ссылки
Sage — система мониторинга Tinkoff
Роман Суслов — выступление на Elasticsearch Community Meetup (2021)
Мартин Клеппман — «Высоконагруженные приложения. Программирование, масштабирование, поддержка»
Это была расшифровка доклада на SaintHighload++ с дополнениями, которые не влезли в доклад. Если у вас остались вопросы — жду в комментариях.
Комментарии (13)

Kirikekeks
31.08.2023 13:13-6Я загадал - почта? Не не угадал.
Хвастатьс тем, что развёл Авгиевы конюшни на рабочем месте - это для админа моветон. Надо прочитать кто тут СРЕ.

mgyk
31.08.2023 13:13+2Самая лучшая оптимизация логов их не писать. Поймали ошибку - отправили в какой-нибудь sentry или аналог. Нужны метрики - пишите сразу метрики (prometeus, datadog, etc.) Нужен аудит? Это явно не elastic в котором можно потерять данные. Мне интересно, почему всегда круто решать проблему с неправильной сторны. Перепишем пол эластика, но не будем смотреть в сами логи и анализировать что из них нужно, а что нет.

r_j Автор
31.08.2023 13:13+2Как сопровождавший такую систему с логами — соглашусь, что лучше не писать логи. Но без логов не решить многие проблемы в тех случаях, когда нужно большое cardinality, да и проблемы на проде надо как-то диагностировать. Мы стараемся не строить реалтайм-мониторинг на логах (вместо этого пишем метрики), но не во всех случаях это поможет.
У команд может быть несколько систем на сопровождении, и часто полезно смотреть логи из нескольких взаимосвязанных систем вместе.

AirLight
31.08.2023 13:13У кого-то есть опыт перноса данных из эластика в кликхаус? По экономии места предполагаю, что будет в 10-100 раз эффект, а вот насколько изменится обозреваемость? Насколько сложнее будут запросы?
r_j Автор
31.08.2023 13:13Я могу ошибаться, и это неактуальная инфа, но Clickhouse вроде не умеет в настоящий полнотекст: https://prohoster.info/blog/administrirovanie/clickhouse-dlya-prodvinutyh-polzovatelej-v-voprosah-i-otvetah#fulltext-search


nikto_b
31.08.2023 13:13А чем какой-нибудь loki+Prometheus не угодил?
r_j Автор
31.08.2023 13:13Среди требований была поддержка полнотекстового поиска (Loki работает на основе лейблов), да и в 2019 году Loki только появился, а хотелось чего-то проверенного.
Prometheus — изначально метрики были в нем, но у него один из главных недостатков — он не умеет масштабироваться горизонтально, да и хранить в нем метрики долгосрочно (и доставать их поисковыми запросами) не так оптимально, как в VictoriaMetrics, которая к тому же менее требовательна к дисковой подсистеме.

webaib1
31.08.2023 13:13+1Есть прекрасная картинка, как из буханки хлеба сделать троллейбус, но зачем? По заголовку сразу было понятно, что люди не понимают, что они делают и денег не считают. Так оно и оказалось. Запомните и повторяйте: "эластик всегда либо ещё не нужен, либо уже слишком дорог".

chemtech
31.08.2023 13:13Подскажите, какая главная причина большого количества логов? Сколько по времени вы храните логи? Используете ли APM? Строите ли метрики на основе логов?
Gorthauer87
А вот мне интересно, если же в лог залетит какой нибудь важный секрет, проскочив мимо валидации, то как его потом вычищать из базы, ведь удалять данные из логов, скорее всего, супер дорогая операция?
Ну или кто нибудь придет по gdpr, и попросит все свои данные из логов убрать, то как тогда жить?
r_j Автор
В таких эпизодических случаях данные удаляются, как правило, прямо индексами. За счет того, что данные льются в индексы в разрезе группы/энва/системы, и нарезаются по времени в зависимости от потока, то удалить данные не сложно. В особых случаях можно и отдельные записи удалить.
r_j Автор
GDRP и прочие регуляторные штуки — в логах не должно быть sensitive data и перс. данных, такие логи запрещается писать и они удаляются сразу, к отправителям логов быстро придут безопасники и отбезопасят.