
Несколько месяцев назад, закончив пост об SDF-пончике, я поставил перед собой задачу написать компилятор C в 500 строках Python1. Насколько сложна эта задача? Оказалось, что довольно сложна, даже после отказа от достаточно большого количества возможностей. Но в то же время она была довольно интересной, а результат оказался на удивление функциональным и вполне простым для понимания!
Кода слишком много, чтобы подробно объяснять его в посте2, поэтому я просто вкратце расскажу о принятых мной решениях, об аспектах, которые пришлось вырезать, и об общей архитектуре компилятора, коснувшись самого главного в каждой из частей. Надеюсь, после прочтения поста код станет для вас доступнее!
[1] Строго говоря, 500 строк кода, не считая комментариев, docstring и пробелов. Статистика
sloccount:$ sloccount compiler.py | grep python:
python: 500 (100.00%)Я не считал комментарии, потому что не хотел мотивировать себя не писать их. Кроме того, мой код отформатирован
black: в нём нет никаких строк длиной по 400 символов![2] На самом деле изначально я намеревался построчно объяснить весь компилятор, написал десять тысяч слов, но добрался только до объявления переменных. Я написал целую литературную среду программирования. Не стоит и говорить, что этот черновик никогда не будет опубликован.
Решения, решения...
Первым и самым важным решением стало то, что это будет однопроходный компилятор. 500 строк — это слишком мало для задания и преобразования абстрактного синтаксического дерева!
Что это значит?
Большинство компиляторов: возня с синтаксическими деревьями
Внутренности большинства компиляторов выглядят примерно так:
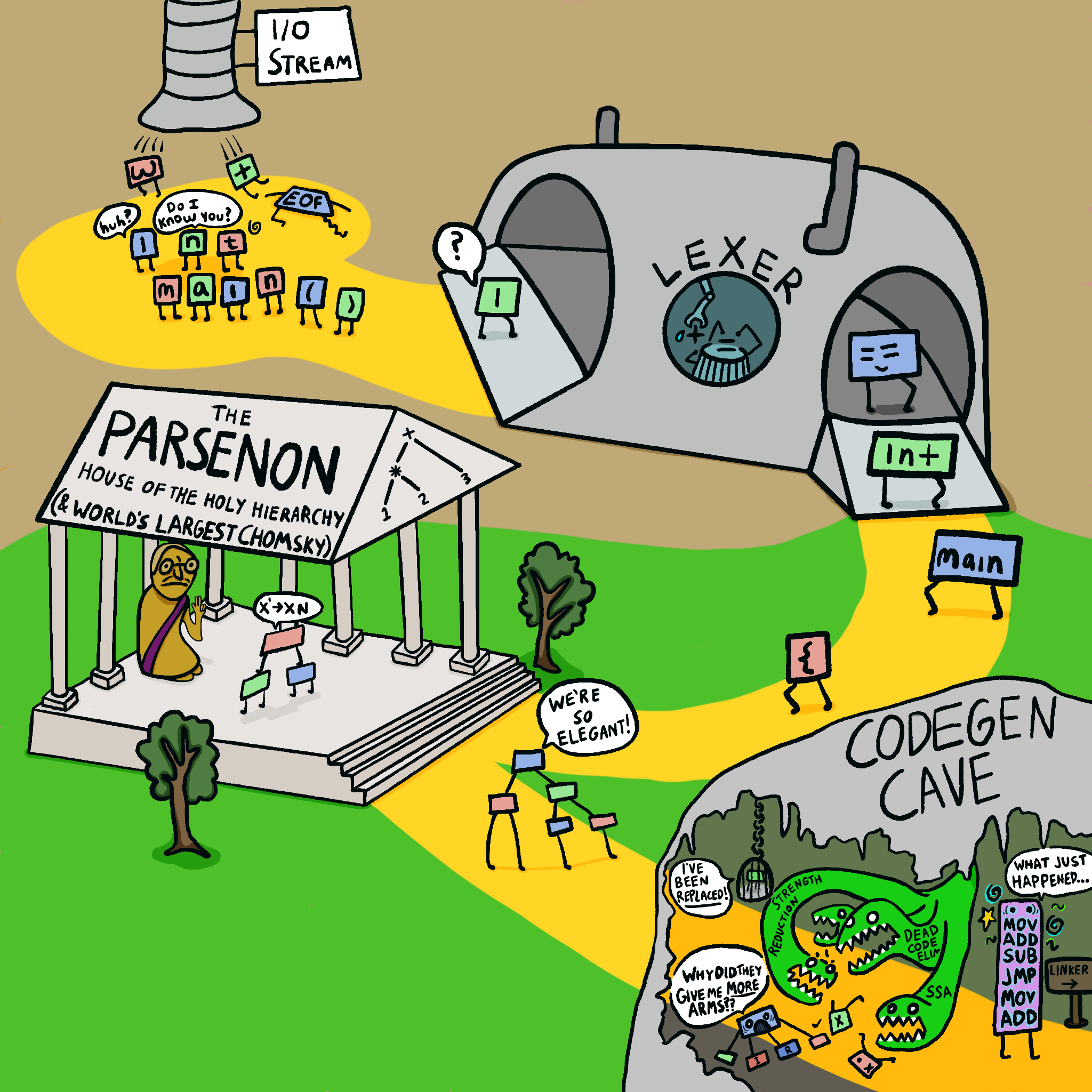
Поток ввода-вывода -> лексический анализатор -> Парсенон (храм священной иерархии и самая высокая в мире статуя Хомского) -> пещера генерации кода.
Токены подвергаются лексическому анализу, после чего их обрабатывает парсер и создаёт красивые маленькие синтаксические деревья:
# гипотетический код, не из какой-то программы
def parse_statement(lexer) -> PrettyLittleSyntaxTree:
...
if type := lexer.try_next(TYPE_NAME):
variable_name = lexer.next(IDENTIFIER)
if lexer.try_next("="):
initializer = parse_initializer(lexer)
else:
initializer = None
lexer.next(SEMICOLON)
return VariableDeclarationNode(
type = type,
name = variable_name,
initializer = initializer,
)
...
# много позже...
def emit_code_for(node: PrettyLittleSyntaxTree) -> DisgustingMachineCode:
...
if isinstance(node, VariableDeclarationNode):
slot = reserve_stack_space(node.type.sizeof())
add_to_environment(node.name, slot)
if node.initializer is not None:
register = emit_code_for(node.initializer)
emit(f"mov {register}, [{slot}]")
...Здесь важно то, что существует два прохода: сначала парсинг создаёт синтаксическое дерево, а затем второй проход перерабатывает это дерево в машинный код. Для большинства компиляторов это очень полезно! Это разделяет этапы парсинга и генерации кода, поэтому каждый из них может эволюционировать независимо друг от друга. Также это значит, что перед использованием синтаксического дерева для генерации кода его можно преобразовать, допустим, применив оптимизации. На самом деле, у большинства компиляторов есть несколько уровней «промежуточного представления» между синтаксическим деревом и генерацией кода!
И это действительно здорово: хорошее проектирование, передовая практика, рекомендовано специалистами и так далее. Но… для этого требуется слишком много кода, поэтому для нас не подходит.
Вместо этого мы реализуем один проход: генерация кода будет происходить во время парсинга. Мы немного парсим, затем создаём немного кода, парсим чуть дальше, создаём ещё немного кода. Для примера вот реальный код из компилятора
c500 для парсинга префикса ~:# lexer.try_next() проверяет, является ли следующий токен ~, и если это так, он потребляет
# и возвращает его (truthy)
elif lexer.try_next("~"):
# prefix() парсит и генерирует код для выражения после ~,
# а load_result при необходимости генерирует код для его загрузки
meta = load_result(prefix())
# сразу же начинаем выдавать код отрицания!
emit("i32.const 0xffffffff")
emit("i32.xor")
# webassembly поддерживает только 32-битные типы, так что если это тип меньшего размера,
# то маскируем его
mask_to_sizeof(meta.type)
# возвращаем информацию о типе
return metaОбратите внимание, что синтаксические деревья и узлы
PrefixNegateOp отсутствуют. Мы видим токены и мгновенно выдаём соответствующие команды.Вы могли заметить, то эти команды на WebAssembly, что приводит нас к следующему разделу…
Зачем использовать WebAssembly?
Я решил сделать целевой системой компилятора WebAssembly. Честно говоря, не знаю, зачем это сделал, на самом деле, это ничего не упростило. Возможно, мне просто было любопытно? WebAssembly — очень странная целевая система, особенно для C. Кроме внешних проблем (например, я очень долго не мог разобраться, пока не понял, что WebAssembly v2 сильно отличается от WebAssembly v1), сам набор команд странен.
Во-первых, в нём нет goto. Вместо этого есть блоки (представьте себе, структурированный ассемблер!) и команды «break», выполняющие переход или к началу, или к концу конкретного уровня вложенности блока. Это было непоследовательно для
if и while, а уж реализацию for сделало крайне неудобной, о чём мы поговорим ниже.Кроме того, в WebAssembly нет регистров, у него есть стек и стековая машина. Поначалу это кажется потрясающим, правда? Ведь C требуется стек! Можно просто использовать стек WebAssembly в качестве стека C! Но нет уж, невозможно делать ссылки на стек WebAssembly. Поэтому нам необходимо поддерживать собственный стек в памяти, а затем реализовывать его взаимодействие со стеком параметров WASM.
То есть в конечном итоге, думаю, у меня получилось чуть больше кода, чем бы понадобилось для более нормальных целевых архитектур наборов команд наподобие x86 или ARM. Но это было интересно! И теоретически можно выполнять скомпилированный
c500 код в браузере, хотя я и не пробовал (я просто использовал CLI wasmer).Обработка ошибок
По сути, компилятор ею не занимается. Есть функция
die, вызываемая, когда происходит что-то странное и дампящее трассировку стека компилятора. Если повезёт, вы получите номер строки и довольно расплывчатое описание ошибки.------------------------------
File "...compiler.py", line 835, in <module>
compile("".join(fi)) # todo: make this line-at-a-time?
File "...compiler.py", line 823, in compile
global_declaration(global_frame, lexer)
<snip>
File "...compiler.py", line 417, in value
var, offset = frame.get_var_and_offset(varname)
File "...compiler.py", line 334, in get_var_and_offset
return self.parent.get_var_and_offset(name)
File "...compiler.py", line 336, in get_var_and_offset
die(f"unknown variable {n}", None if isinstance(name, str) else name.line)
File "...compiler.py", line 14, in die
traceback.print_stack()
------------------------------
error on line 9: unknown variable cЭто вам не компилятор Rust!
От чего отказаться
Наконец, мне нужно было решить, что не поддерживать, потому что невозможно засунуть весь язык C в 500 строк. (Простите!) Я решил, что мне нужна очень приличная выборка функций, позволяющая протестировать возможности обобщённой реализации — например, если бы я отказался от указателей, то мог бы обойтись только стеком параметров WASM и избавиться от множества сложностей, но это бы походило на жульничество.
В конечном итоге я выбрал следующие возможности:
- арифметические операции и двоичные операторы с правильной приоритетностью
- типы
int,shortиchar - строковые константы (с escape-последовательностями)
- указатели (на любое количество уровней), в том числе настоящую арифметику указателей (инкремент
int*прибавляет 4) - массивы (только одноуровневые, без
int[][]) - функции
- typedef (и хак лексического анализатора!)
Важные неподдерживаемые возможности:
- структуры можно было бы реализовать при большем объёме кода, фундамент уже был заложен, но я просто не смог уместить их
- перечисления / объединения
- директивы препроцессора (наверно, для них одних понадобилось бы 500 строк...)
- числа с плавающей запятой; их можно было бы реализовать, в коде есть
wasm_type, но снова просто не хватило места - 8-байтные типы (
long/long longилиdouble) - некоторые другие мелочи наподобие префиксных/постфиксных инкрементов, in-place-инициализации и так далее, которые просто не удалось уместить
- какая-нибудь стандартная библиотека или ввод-вывод, не возвращающий integer из
main() - выражения приведения типов
Компилятор проходит 34/220 тестовых случаев c-testsuite. Но для меня важнее, что он может успешно скомпилировать и выполнить следующую программу:
int swap(int* a, int* b) {
int t;
t = *a; *a = *b; *b = t;
return t;
}
int fib(int n) {
int a, b;
for (a = b = 1; n > 2; n = n - 1) {
swap(&a, &b);
b = b + a;
}
return b;
}
int main() {
return fib(10); // 55
}Ну ладно, хватит о решениях, давайте перейдём к коду!
Типы-хелперы
Компилятор использует небольшой набор вспомогательных типов и классов. Все они довольно обычные, так что рассмотрю их вкратце.
Emitter (compiler.py:21)
Это вспомогательный singleton для генерации правильно отформатированного кода WebAssembly.
WebAssembly, по крайней мере, в текстовом формате, форматируется как s-выражения, но отдельные команды не нужно заключать в скобки:
(module
;; <snip...>
(func $swap
(param $a i32)
(param $b i32)
(result i32)
global.get $__stack_pointer ;; prelude -- adjust stack pointer
i32.const 12
i32.sub
;; <snip...>
)
)Emitter просто помогает с созданием кода с отступами для удобства чтения. Также он имеет метод no_emit, который ниже будет использован в качестве уродливого хака.StringPool (compiler.py:53)
StringPool хранит все строковые константы, чтобы их можно было разместить в сплошной области памяти, и выдаёт адреса в этой области, которые использует генератор кода. Когда мы пишем char *s = "abc" в c500, то происходит следующее:-
StringPoolдобавляет нулевой символ -
StringPoolпроверяет, сохранял ли уже"abc", и если да, то просто возвращает адрес - В противном случае
StringPoolдобавляет её в словарь с базовым адресом + общей байтовой длиной сохранённого ранее, то есть с адресом этой новой строки в пуле -
StringPoolвозвращает этот адрес - После завершения компиляции всего кода мы создаём раздел
rodataс огромной конкатенированной строкой, созданнойStringPool, которая хранится по базовому адресу строкового пула (задним числом делая валидными все переданныеStringPoolадреса)
Lexer (compiler.py:98)
Класс
Lexer сложен, потому что лексический анализ в C сложен ((\\([\\abfnrtv'"?]|[0-7]{1,3}|x[A-Fa-f0-9]{1,2})) — это реальное регулярное выражение в этом коде для escape-последовательностей символов), но концептуально прост: лексический анализатор просто проходит по коду, определяя, что за токен находится в текущей позиции. Вызывающая сторона может увидеть этот токен или использовать next, чтобы лексический анализатор двигался дальше, «потребляя» этот токен. Также он может использовать try_next, чтобы двигаться дальше при условии, если следующий токен имеет определённый тип: по сути, try_next — это краткая запись if self.peek().kind == token: return self.next().В компиляторе есть дополнительная сложность, вызванная хаком лексического анализатора. По сути, при парсинге C нам нужно знать, является ли нечто именем типа или переменной (потому что для компилирования некоторых выражений важен контекст), но между ними нет синтаксического различия:
int int_t = 0; — это абсолютно валидный код на C, как и typedef int int_t; int_t x = 0;.Чтобы знать, является ли произвольный токен
int_t именем типа или переменной, нам нужно передать информацию о типе с этапа парсинга/генерации кода обратно в лексический анализатор. Это огромная проблема для обычных компиляторов, желающих разделять свои модули лексического анализатора, парсера и генератора кода, но для нас это не так сложно! Подробнее я объясню это, когда мы доберёмся до раздела typedef, но, по сути, нам нужно всего лишь хранить types: set[str] в Lexer, и при выполнении лексического анализа перед отправкой вида токена проверять, находится ли он в этом множестве:if m := re.match(r"^[a-zA-Z_][a-zA-Z0-9_]*", self.src[self.loc :]):
tok = m.group(0)
...
# хак лексического анализатора
return Token(TOK_TYPE if tok in self.types else TOK_NAME, tok, self.line)CType (compiler.py:201)
Это просто класс данных для описания информации о типе C, аналогично записи
int **t или short t[5] или char **t[17] за минусом t.Он содержит:
- имя типа (со всеми заресолвленными typedefs ), например,
intилиshort - уровень, на котором находится указатель (
0= не указатель,1=int *t,2=int **tи так далее) - размер массива (
None= не массив,0=int t[0],1=int t[1]и так далее)
Примечательно, что, как и говорилось ранее, этот тип поддерживает только одноуровневые массивы, а не вложенные массивы наподобие
int t[5][6].FrameVar и StackFrame (compiler.py:314)
Эти классы работают с нашими кадрами стека C.
Как говорилось ранее, поскольку мы не можем получать ссылки на стек WASM, нужно обрабатывать стек C вручную и нельзя использовать стек WASM.
Для настройки стека C вводная часть, созданная в
__main__, задаёт глобальную переменную __stack_pointer, а затем каждый вызов функции уменьшает её на объём пространства, необходимый функции под её параметры и локальные переменные; он вычисляется экземпляром StackFrame этой функции.Когда мы доберёмся до функций парсинга, я подробнее расскажу о работе этих вычислений, но, по сути, каждый параметр и локальная переменная получает слот в этом пространстве стека и в зависимости от его размера увеличивает
StackFrame.frame_size (а значит, смещение переменной next). Смещение, информация о типе и другие данные для каждого параметра и локальной переменной хранятся в порядке объявления внутри экземпляра FrameVar в StackFrame.variables.ExprMeta (compiler.py:344)
Этот последний класс данных используется для отслеживания того, является ли результат выражения значением или местом. Нам нужно отслеживать это, чтобы обрабатывать отдельные выражения по-разному в зависимости от того, как они используются.
Например, если есть переменная
x типа int, её можно использовать двумя способами:- для выполнения
x + 1требуется значение ofx, допустим,1 -
&xнужен адрес иx, допустим,0xcafedead
При парсинге выражения
x мы можем с лёгкостью получить адрес из кадра стека:# ищем переменную в `StackFrame`
var, offset = frame.get_var_and_offset(varname)
# помещаем базовый адрес стека C на вершину стека WASM
emit(f"global.get $__stack_pointer")
# прибавляем смещение (в стеке C)
emit(f"i32.const {offset}")
emit("i32.add")
# адрес переменной теперь находится наверху стека WASMНо что дальше?
Если мы выполним
i32.load этого адреса, чтобы получить значение, то &x никак не сможет получить адрес. Но если мы не загрузим его, то x + 1 попытается прибавить единицу к адресу, что приведёт к 0xcafedeae вместо 2!Именно здесь приходит на помощь
ExprMeta: мы оставляем адрес в стеке и возвращаем ExprMeta, обозначающий, что это место:return ExprMeta(True, var.type)Тогда для операций наподобие
+, которым всегда нужно работать со значениями, а не с адресами, есть функция load_result, преобразующая любые места в значения:def load_result(em: ExprMeta) -> ExprMeta:
"""Загружаем `ExprMeta` места, превращая его в значение
`ExprMeta` того же типа"""
if em.is_place:
# создаём i32.load, i32.load16_s, и так далее, на основании типа
emit(em.type.load_ins())
return ExprMeta(False, em.type)
...
# в коде для парсинга `+`
lhs_meta = load_result(parse_lhs())
...В то же время операции типа
& не просто загружают результа и вместо этого оставляют адрес в стеке: здесь важно, что в нашем компиляторе & — это no-op, потому что не создаёт никакого кода!if lexer.try_next("&"):
meta = prefix()
if not meta.is_place:
die("cannot take reference to value", lexer.line)
# типом &x является int*, когда x является int, поэтому more_ptr
return ExprMeta(False, meta.type.more_ptr())Стоит также заметить, что несмотря на то, что это адрес, результат
& не является местом! (Код возвращает ExprMeta с is_place=False.)Результат
& должен обрабатываться как значение, потому что &x + 1 должна прибавлять 1 (или, скорее sizeof(x)) к адресу. Именно поэтому нам нужно это разделение на места и значения, потому что просто «быть адресом» недостаточно, чтобы знать, должен ли загружаться результат выражения.Ладно, достаточно о вспомогательных классах. Давайте перейдём к генерации кода!
Парсинг и генерация кода
Общий поток управления выглядит так:
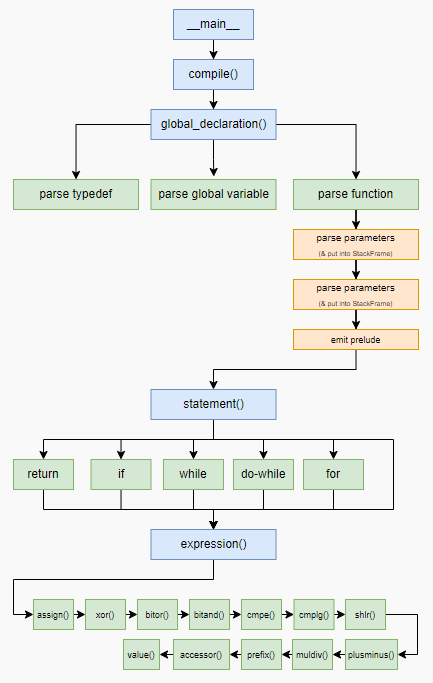
Синими прямоугольниками обозначены главные функции компилятора —
__main__, compile(), global_declaration(), statement() и expression(). Длинная цепочка квадратов внизу показывает приоритет операторов, однако большинство этих функций автоматически генерируется функциями более высокого порядка!Я пройдусь по каждому из синих прямоугольников и объясню интересное о каждом из них.
__main__ (compiler.py:827)
Довольно короткая и простая функция. Вот она полностью:
if __name__ == "__main__":
import fileinput
with fileinput.input(encoding="utf-8") as fi:
compile("".join(fi)) # todo: сделать это построковым?Очевидно, что я так и не закончил TODO! Единственное, что здесь интересно — это модуль
fileinput, о котором вы, возможно, не слышали. Цитата из документации к модулю:Типичное использование:import fileinput for line in fileinput.input(encoding="utf-8"): process(line)
Этот код итеративно обходит все файлы, перечисленные в sys.argv[1:], в случае пустоты списка используя sys.stdin. Если имя файла равно '-', оно также заменяется sys.stdin, а режим опциональных аргументов и openhook игнорируются. Чтобы указать альтернативный список имён файлов, можно передать его в качестве аргумента input(). Также допускается единственное имя файла.
Строго говоря, это означает, что
c500 поддерживает множественные файлы! (Если вас не волнует, что все они будут конкатенированы и иметь перепутанные номера строк. На самом деле, fileinput довольно сложен и имеет метод filelineno(), который я не использовал по причинам нехватки места.)compile() (compiler.py:805)
compile() — это первая интересная здесь функция, она достаточно коротка, чтобы привести её полностью:def compile(src: str) -> None:
# компилирует весь файл
with emit.block("(module", ")"):
emit("(memory 3)")
emit(f"(global $__stack_pointer (mut i32) (i32.const {PAGE_SIZE * 3}))")
emit("(func $__dup_i32 (param i32) (result i32 i32)")
emit(" (local.get 0) (local.get 0))")
emit("(func $__swap_i32 (param i32) (param i32) (result i32 i32)")
emit(" (local.get 1) (local.get 0))")
global_frame = StackFrame()
lexer = Lexer(src, set(["int", "char", "short", "long", "float", "double"]))
while lexer.peek().kind != TOK_EOF:
global_declaration(global_frame, lexer)
emit('(export "main" (func $main))')
# создаёт раздел данных str_pool
emit(f'(data $.rodata (i32.const {str_pool.base}) "{str_pool.pooled()}")')Эта функция занимается созданием вводной части на уровне модуля.
Сначала мы создаём pragma для виртуальной машины WASM, чтобы зарезервировать три страницы памяти (
(memory 3)), и устанавливаем указатель стека так, чтобы он начинался в конце этой зарезервированной области (он будет расти вниз).Затем мы определяем две вспомогательные функции для манипуляций со стеком:
__dup_i32 и __swap_i32. Если вы пользовались Forth, то вам они должны быть знакомы: dup дублирует элемент на вершине стека WASM (a -- a a), а swap меняет позиции двух верхних элементов на вершине стека WASM (a b -- b a).Далее мы инициализируем кадр стека для хранения глобальных переменных, инициализируем лексический анализатор встроенными именами типов для хака и потребляем глобальные объявления, пока не закончим!
Наконец, мы экспортируем
main и дампим строковый пул.global_declaration() (compiler.py:743)
Эта функция слишком длинна, чтобы приводить её целиком, но её сигнатура выглядит так:
def global_declaration(global_frame: StackFrame, lexer: Lexer) -> None:
# парсинг глобального объявления -- typedef, глобальная переменная или функция.
...Она работает с typedef, глобальными переменными и функциями.
Typedef — это круто, потому что именно в них происходит хак лексического анализатора!
if lexer.try_next("typedef"):
# да, `typedef int x[24];` - это валидный (хотя и странный) код на C
type, name = parse_type_and_name(lexer)
# хак лексического анализатора!
lexer.types.add(name.content)
typedefs[name.content] = type
lexer.next(";")
returnМы повторно используем инструмент парсинга имён типов, потому что typedef наследуют все странные правила C «объявление отражает использование», что для нас удобно. (Но не для новичков!) Затем мы сообщаем лексическому анализатору, что обнаружили новое имя типа, чтобы в будущем этот токен лексически анализировался как имя типа, а не имя переменной.
Наконец, для typedef мы сохраняем тип в глобальном реестре typedef, потребляем замыкающуюся точку с запятой и возвращаемся в
compile() за следующим глобальным объявлением. Важно, что сохраняемый нами тип — это полный распарсенный тип, потому что если выполнить typedef int* int_p;, а позже написать int_p *x, то x должен получить окончательный тип int** — уровень указателей аддитивен! Это значит, что мы не можем просто хранить базовое имя типа C и вместо этого должны хранить весь CType.Если объявление не было typedef, то мы парсим тип и имя переменной. Если мы находим токен
;, то знаем, что это объявление глобальной переменной (так как мы не поддерживаем глобальных инициализаторов). В таком случае мы добавляем глобальную переменную в глобальный кадр стекаи завершаем.
if lexer.try_next(";"):
global_frame.add_var(name.content, decl_type, False)
returnЕсли точки с запятой нет, то мы определённо имеем дело с функцией. Для генерации кода функции нам нужно:
- Создать новый
StackFrameдля функции с именемframe - Затем спарсить все параметры и сохранить их в кадре с
frame.add_var(varname.content, type, is_parameter=True) - После этого спарсить все объявления переменных при помощи
variable_declaration(lexer, frame), что добавляет и вframe - Теперь, когда мы знаем, насколько большим должен быть кадр стека функции (
frame.frame_size), можно начать создавать вводную часть! - Во-первых, для всех параметров в кадре стека (добавляемых при помощи
is_parameter=True) мы генерируем объявленияparamWASM, чтобы функцию можно было вызвать в соответствии со стандартом вызова WASM (передавая параметры в стек WASM):for v in frame.variables.values(): if v.is_parameter: emit(f"(param ${v.name} {v.type.wasmtype})") - Затем мы можем создать аннотацию
resultдля возвращаемого типа и изменить указатель стека C так, чтобы обеспечить пространство для параметров и переменных функции:emit(f"(result {decl_type.wasmtype})") emit("global.get $__stack_pointer") # выращиваем стек вниз emit(f"i32.const {frame.frame_offset + frame.frame_size}") emit("i32.sub") emit("global.set $__stack_pointer") - Каждый параметр (в обратном порядке, потому что это стеки) копируем из стека WASM в наш стек:
for v in reversed(frame.variables.values()): if v.is_parameter: emit("global.get $__stack_pointer") emit(f"i32.const {frame.get_var_and_offset(v.name)[1]}") emit("i32.add") # получаем переменную из стека WASM emit(f"local.get ${v.name}") # и сохраняем её по вычисленному адресу в стеке C emit(v.type.store_ins()) - Наконец, мы можем вызвать в цикле
statement(lexer, frame), чтобы сгенерировать код для всех конструкций в функции, пока не доберёмся до закрывающей фигурной скобки:while not lexer.try_next("}"): statement(lexer, frame) - Бонусный этап: мы предполагаем, что функция всегда будет иметь
return, поэтому выполняемemit("unreachable"), чтобы анализатор WASM не сходил с ума.
Ух! Мы сделали очень много. Но на этом работа с функциями, а значит, и с
global_declaration(), закончена, так что перейдём к statement().statement() (compiler.py:565)
В
statement() много кода. Однако большая его часть довольно однообразная, поэтому я объясню только те while и for, о которых стоит знать.Помните, что в WASM нет переходов, а только структурированный поток управления? Сейчас это для нас важно.
Для начала давайте посмотрим, как это работает с
while, где это не вызывает особых проблем. Цикл while в WASM выглядит так:block
loop
;; <проверка>
i32.eqz
br_if 1
;; <тело цикла>
br 0
end
endКак видите, есть два типа блоков:
block и loop (также есть тип блоков if, который я не использовал). Каждый из них включает в себя некие конструкции, а заканчивается на end. Внутри блока можно выполнять break безусловно при помощи br или условно на основании вершины стека WASM при помощи br_if (также есть br_table, который я не использовал).Семейство
br получает параметр labelidx, здесь он имеет значение 1 или 0, обозначающее, к какому блоку операции он применяется. Итак, в нашем цикле while br_if 1 применяется к внешнему блоку — индекс 1, а br 0 применяется к внутреннему блоку — индекс 0 (индексы всегда указываются относительно рассматриваемой команды: 0 — это самый внутренний блок относительно этой команды).И последнее правило, которое нужно знать:
br в блоке выполняет переход вперёд, к концу блока, а br в цикле переходит назад, к началу цикла.Так что, надеюсь, теперь код цикла while теперь вам понятен! Взглянем на него ещё раз.
block
loop
;; <test>
i32.eqz
;; если test == 0, переход вперёд (1 = labelidx блока `block`),
;; наружу из цикла
br_if 1
;; <тело цикла>
;; безусловный переход назад (0 = labelidx цикла `loop`).
;; к началу цикла
br 0
end
endВ более обычном ассемблерном коде это будет соответствовать следующему:
.loop_start
;; <проверка>
jz .block_end
;; <тело цикла>
jmp .loop_start
.block_endНо при помощи переходов можно выразить то, что нельзя (простым способом) выразить в WASM — например, можно перейти в середину блока.
(В основном это проблема для компиляции
goto языка C, которую я даже не пытался решать — существует алгоритм, способный преобразовать любой код с goto в эквивалентную программу со структурированным потоком управления, но он сложен, и я не думаю, что он будет работать с нашей однопроходной системой.)Но для циклов while всё не так плохо. Нам достаточно сделать следующее:
# `emit.block` - это менеджер контекста для создания первого параметра (в данном случае "block"),
# а затем второго ("end") при выходе
with emit.block("block", "end"):
with emit.block("loop", "end"):
# создание кода для теста, завершающегося на `i32.eqz`
parenthesized_test()
# создание кода для выхода из цикла, если `i32.eqz` истинно
emit("br_if 1")
# создание кода для тела
bracketed_block_or_single_statement(lexer, frame)
# создание кода для перехода обратно к началу
emit("br 0")Однако с циклами for всё становится неприятно. Рассмотрим следующий цикл for:
for (i = 0; i < 5; i = i + 1) {
j = j * 2 + i;
}Лексический анализатор/генератор кода будет видеть части цикла for в следующем порядке:
i = 0i < 5i = i + 1j = j * 2 + i
Но для работы со структурированным потоком управления WASM они должны находиться в коде в следующем порядке:
block
;; < code for `i = 0` (1) >
loop
;; < code for `i < 5` (2) >
br_if 1
;; < code for `j = j * 2 + i` (4!) >
;; < code for `i = i + 1` (3!) >
br 0
end
endОбратите внимание, что в сгенерированном коде 3 и 4 поменялись местами, то есть получился порядок 1, 2, 4, 3. Для однопроходного компилятора это будет проблемой! В отличие от обычного компилятора, мы не можем сохранить конструкцию продвижения вперёд для дальнейших этапов. Или можем?
Я справился с этой проблемой, сделав лексический анализатор клонируемым и повторно спарсив конструкцию продвижения вперёд после парсинга тела. По сути, код выглядит так:
elif lexer.try_next("for"):
lexer.next("(")
with emit.block("block", "end"):
# парсим инициализатор (i = 0)
# (снаружи цикла, потому что это происходит только один раз)
if lexer.peek().kind != ";":
expression(lexer, frame)
emit("drop") # отбрасываем результат инициализатора
lexer.next(";")
with emit.block("loop", "end"):
# парсим проверку (i < 5), если она присутствует
if lexer.peek().kind != ";":
load_result(expression(lexer, frame))
emit("i32.eqz ;; for test")
emit("br_if 1 ;; exit loop")
lexer.next(";")
# обрабатываем первый проход конструкции продвижения вперёд, если она присутствует
saved_lexer = None
if lexer.peek().kind != ")":
saved_lexer = lexer.clone()
# emit.no_emit() отключает вывод кода внутри него,
# поэтому мы пока можем пропустить конструкцию продвижения вперёд,
# чтобы перейти к телу цикла for
with emit.no_emit():
expression(lexer, frame)
lexer.next(")")
# парсим тело
bracketed_block_or_single_statement(lexer, frame)
# спарсив тело, мы возвращаемся и повторно парсим
# конструкцию продвижения вперёд при помощи сохранённого лексического анализатора
if saved_lexer != None:
expression(saved_lexer, frame)
# переходим в начало цикла
emit("br 0")Как видите, хак заключается в том, чтобы сохранить лексический анализатор, затем использовать его, чтобы позже вернуться и обработать конструкцию продвижения вперёд, вместо сохранения синтаксического дерева, как это сделал бы обычный компилятор. Не особо изящно: компилирование циклов for — это, наверно, самый неприятный код в компиляторе, но работает достаточно неплохо!
Остальные части
statement() в основном похожи, поэтому я пропущу их и перейду к основной части компилятора — expression().expression() (compiler.py:375)
expression() — это последний большой метод в компиляторе, который, как и можно догадаться, выполняет парсинг выражений. Он содержит множество внутренних методов, по одному для каждого уровня приоритета, и каждый возвращает описанную выше структуру ExprMeta (она обрабатывает различие между местом и значением и может быть превращена в значение при помощи load_result).Внизу стека приоритетов находится
value() (имя немного сбивает с толку, потому что он может возвращать return ExprMeta(is_place=True, ...)). Он обрабатывает константы, выражения в скобках, вызовы функций и имена переменных.Базовый паттерн для уровня приоритета — это функция наподобие такой:
def muldiv() -> ExprMeta:
# lhs - это операция с более высоким приоритетом (в данном случае - префиксный оператор)
lhs_meta = prefix()
# проверяем, можно спарсить операцию
if lexer.peek().kind in ("*", "/", "%"):
# если да, загружаем левую часть
lhs_meta = load_result(lhs_meta)
# берём конкретный оператор
op_token = lexer.next()
# правая часть должна использовать эту функцию, например, `x * y * z`
load_result(muldiv())
# создаём опкод для выполнения операции
if op_token == "*":
emit(f"i32.mul")
elif op_token == "/":
emit(f"i32.div_s")
else: # %
emit(f"i32.rem_s")
# маскируем результат, если этот тип меньше 32 битов
mask_to_sizeof(lhs_meta.type)
# мы создали значение (is_place=False)
return ExprMeta(False, lhs_meta.type)
# если мы не нашли токен, просто возвращаем левую часть без изменений
return lhs_metaНа самом деле, этот паттерн настолько устойчив, что большинство операций, в том числе
muldiv, не записываются, а определяются функцией более высокого порядка makeop:# функция для генерации уровней приоритетов простых операторов из декларативных
# словарей { token: instruction_to_emit }
def makeop(
higher: Callable[[], ExprMeta], ops: dict[str, str], rtype: CType | None = None
) -> Callable[[], ExprMeta]:
def op() -> ExprMeta:
lhs_meta = higher()
if lexer.peek().kind in ops.keys():
lhs_meta = load_result(lhs_meta)
op_token = lexer.next()
load_result(op())
# TODO: проверка типов?
emit(f"{ops[op_token.kind]}")
mask_to_sizeof(rtype or lhs_meta.type)
return ExprMeta(False, lhs_meta.type)
return lhs_meta
return op
muldiv = makeop(prefix, {"*": "i32.mul", "/": "i32.div_s", "%": "i32.rem_s"})
...
shlr = makeop(plusminus, {"<<": "i32.shl", ">>": "i32.shr_s"})
cmplg = makeop(
shlr,
{"<": "i32.lt_s", ">": "i32.gt_s", "<=": "i32.le_s", ">=": "i32.ge_s"},
CType("int"),
)
cmpe = makeop(cmplg, {"==": "i32.eq", "!=": "i32.ne"}, CType("int"))
bitand = makeop(cmpe, {"&": "i32.and"})
bitor = makeop(bitand, {"|": "i32.or"})
xor = makeop(bitor, {"^": "i32.xor"})
...Лишь несколько операторов с особым поведением необходимо определять явным образом, например,
plusminus, которому нужно обрабатывать нюансы математики указателей C.Вот и всё! Это последняя оставшаяся главная часть компилятора.
Подведём итог
Такой была наша экскурсия по компилятору C в 500 строках Python! Компиляторы имеют репутацию сложных систем — GCC и Clang огромны, и даже TCC (Tiny C Compiler, "крошечный компилятор C") состоит из десятков тысяч строк кода, но если вы готовы пожертвовать качеством кода и делать всё за один проход, они могут быть удивительно компактными!
Я думаю, что подобный компилятор благодаря своей простоте может быть отличным stage0 для собственного языка.
Комментарии (5)


JQuery567
20.09.2023 08:01+2все пишут компиляторы C, как будто в этом есть нужда. А напишите уже хоть раз компилятор python!!!

dmitry_lyzin
20.09.2023 08:01+1Мда... Питон... 500 строк...
Вот тут человек действующий компилятор C в 510 байт запихнул.

AnthonyMikh
20.09.2023 08:01+1И при этом:
У функций нет аргументов, нет for, нет switch, нет никаких типов кроме int, нет указателей (только доступ через (int)), нет массивов, нет return (функции ничего не возвращают), нет строковых литералов, нет локальных переменных (только определённые вне функции), нет оператора деления, нет оператора остатка
Мягко говоря, не сопоставимый функционал
Number571
Дубль: https://habr.com/ru/companies/cloud4y/articles/760400/