

В прошлом материале мы рассказали, с какой проблемой столкнулись, и проанализировали четыре СУБД в поиске рабочего решения. Мы оценили преимущества и недостатки каждого отобранного варианта и остановились на ClickHouse. Несмотря на то, что готовой интеграции этой БД с Zabbix не существует, CH отлично подходил как решение под наши инженерные задачи.
БД в Zabbix
Прежде чем мы перейдем к рассказу о реализации, расскажем о специфике работы БД в Zabbix. Вся ее логика вынесена в отдельную библиотеку — zbxhistory. Она используется сервером и прокси для сохранения данных мониторинга. В классе history описывается интерфейс, который имплементируется каждой реализацией подключения к хранилищу данных.
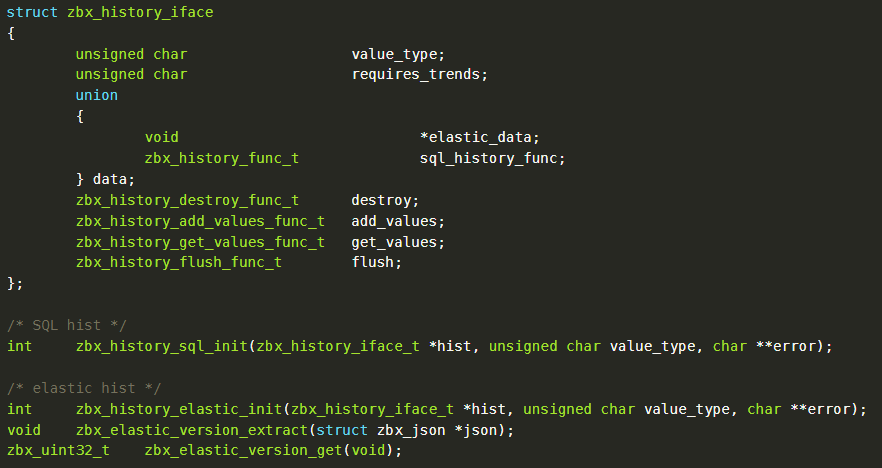
Кроме функций для выполнения CRUD-операций, в конкретном классе могут содержаться дополнительные функции для преобразования полученных значений. Так, в реализации history можно найти zbx_history_init — она создает под каждый тип данных Zabbix соответствующий коннектор с базой в зависимости от параметров файла.
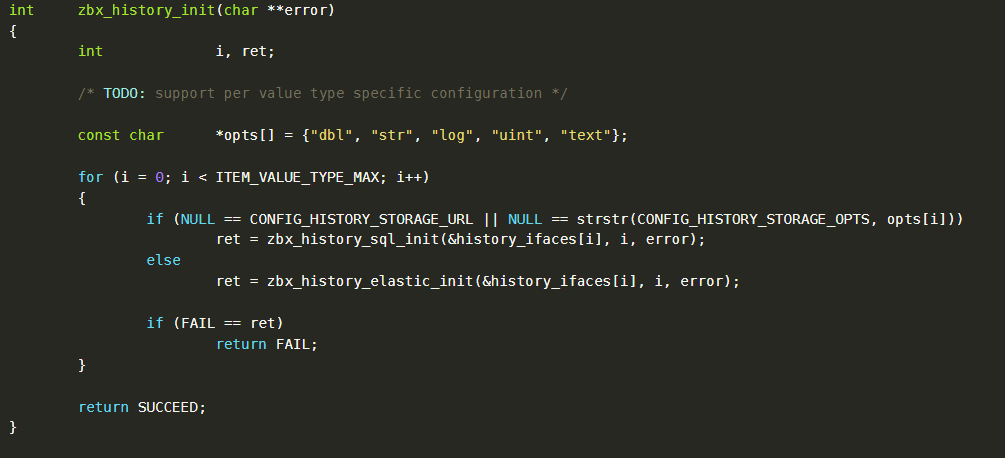
Конфигурация экспортируется из классов server.c или proxy.c, где описаны переменные, содержащие информацию о наших источниках данных, хранимых типах и настройках буфера.
На этом этапе способ реализации понятен. Оставалось определиться, как мы будем взаимодействовать с CH. У него есть множество возможных коннекторов, но лучше всего описана работа с HTTP API. Конечно, лучшим вариантом с точки зрения производительности является использование проприетарного протокола CH, но доступной документации по нему нет, а поисковик вообще отсылает к изучению исходников clickhouse-client. Поэтому для прототипа решили остановиться на HTTP-протоколе.
За дело
Итак, мы создали класс clickhouse.c в нашей библиотеке и реализовали основные функции: init, destroy, add_values, get_values. Мы добавили для каждого типа данных буфер, который накапливал бы их перед записью в БД. Данный буфер сбрасывается по достижению какого-то ограниченного времени жизни либо при заполнении. В качестве стандартных значений указали 10 000 строк или 10 секунд. Это снизило нагрузку на базу, уменьшив количество «засечек», которые позднее предстоит смержить в более крупные файлы данных.
Пример инициализации коннектора, где мы заполнили дефолтные значения параметров и указали функции для использования высокоуровневым zbx_history_iface_t., выглядит так:
int zbx_history_clickhouse_init(zbx_history_iface_t* hist, unsigned char value_type, char** error)
{
zbx_clickhouse_data_t* data;
if (0 != curl_global_init(CURL_GLOBAL_ALL))
{
*error = zbx_strdup(*error, "Cannot initialize cURL library");
return FAIL;
}
data = (zbx_clickhouse_data_t*)zbx_malloc(NULL,
sizeof(zbx_clickhouse_data_t));
memset(data, 0, sizeof(zbx_clickhouse_data_t));
data->base_url = zbx_strdup(NULL,
CONFIG_HISTORY_CLICKHOUSE_STORAGE_URL);
zbx_rtrim(data->base_url, "/");
data->buffer.data = NULL;
data->buffer.alloc = 0;
data->buffer.offset = 0;
data->buffer.lastflush = time(NULL);
data->buffer.num = 0;
hist->value_type = value_type;
hist->data.clickhouse_data = data;
hist->destroy = clickhouse_destroy;
hist->add_values = clickhouse_add_values;
hist->flush = clickhouse_flush;
hist->get_values = clickhouse_get_values;
hist->requires_trends = 0;
return SUCCEED;
}Дорабатывая конфиги, мы переделали функцию создания history_iface_t, чтобы назначить хранилище для каждого типа и не ломать интеграцию с Elasticsearch.
После реализации серверной части создали схему таблиц в БД. Для каждой из них указали необходимый набор полей, в качестве движка использовали MergeTree, настроили правила партиционирования и TTL (о нём поговорим позднее).
CREATE TABLE zabbix.history
(
`itemid` UInt64,
`clock` UInt32,
`ns` UInt32,
`value` Float64
)
ENGINE = MergeTree
PARTITION BY toYYYYMM(CAST(clock, 'date'))
ORDER BY (itemid, clock)
TTL CAST(clock, 'date') + toIntervalSecond(2592000)
SETTINGS index_granularity = 8192
Куча дебаг-сообщений, десяток сборок, и (о, чудо!) данные начали записываться.
Дорабатываем web-интерфейс и API
В web-интерфейсе добавили в конфигурационный файл параметры для подключения к БД (URL, username, password, database) и реализовали чтение из CH по HTTP API по аналогии с Elasticsearch.
В целом, отличается только процесс парсинга полученного JSON-сообщения[1] и запрос данных из БД. Для этих целей мы создали класс /include/classes/helpers/CClickhouseHelper.php, где предусмотрены функции Query для запроса данных и ParseResult для преобразования полученного JSON’a в многомерный массив.
public static function query($method, $request = null) {
global $HISTORY;
$time_start = microtime(true);
$result = [];
$options = [
'http' => [
'header' => "Content-Type: text/plain; charset=UTF-8",
'method' => $method,
'protocol_version' => 1.1,
ignore_errors' => false // To get error messages from Clickhouse.
]
];
if ($request) {
$options['http']['content'] = $request;
}
try {
$result =
file_get_contents($HISTORY['storages']['clickhouse']['url'], false, stream_context_create($options));
if($result){
$result = self::parseResult($result);
}
}
catch (Exception $e) {
error($e->getMessage());
}
CProfiler::getInstance()->profileClickhouse(microtime(true) -
$time_start, $method, $request);
return $result;
}Переменная $HISTORY содержится в конфигурационном файле /conf/zabbix.conf.php и хранит в себе креденшелы для подключения к базе. Для подключения к БД нам понадобилась авторизация — для этого мы передали данные в виде параметров url:
?database=zabbix?username=zabbix?password=123
$HISTORY['storages'] = [
'elastic' => [
'url' => '',
'types' => []
],
'clickhouse' => [
'url' => '',
'types' => []
]
]; На заметку: все эти параметры можно указать в самом файле, либо они подтягиваются из env-переменных.
После реализации хелпера приступили к доработке классов CHistoryManager[2] и CHistory[3]. Логика в них достаточно простая. Тем не менее стоит учитывать, что под разные типы данных нужно на ходу генерировать SQL-запросы для выборки истории из таблиц. Помимо этого, данные через API должны возвращаться в типе string. В результате получили работающие графики:
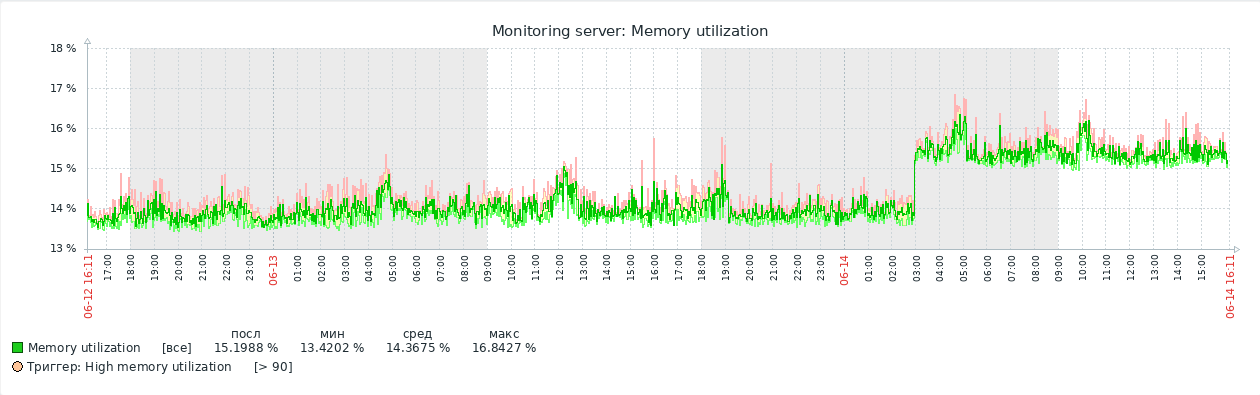
На последнем этапе решения нам оставалось реализовать расчет трендов по историческим данным. Перед нами было два пути. Для начала мы попробовали сделать это при помощи Zabbix-сервера, но процесс оказался слишком трудоемким. Расчет трендов описан в отдельной библиотеке, которая заточена сугубо на работу с классическими базами. Для того чтобы эта история стала рабочей, нам нужно было реализовать интерфейс, который смог бы имплементировать разные СУБД, как, например, библиотека zbxhistory.
Второй раз мы подошли к проблеме при помощи движка AggregatingMergeTree на стороне CH. Он изменяет логику слияния кусков и агрегирует данные с одинаковым первичным ключом в рамках определенной выборки. И это сработало. Данные (min, max, avg) в таблицах трендов рассчитывались автоматически каждый час при поступлении исторических данных в таблицы history и history_uint. После мы доработали функцию извлечения данных в web-интерфейсе, чтобы при запросе с интервалом более двух дней использовались тренды. Вот какой у нас вышел результат.

Все еще в интерфейсе: Time to Live
Ранее мы уже затрагивали тему TTL (Time to Live) — параметр, который задает время жизни данных. Он устанавливается в секундах, и при его исчерпании можно выполнить следующие действия: зачистить старые блоки, агрегировать старые данные, изменить уровень компрессии, переместить данные между зонами хранения. Подробнее обо всех возможностях и способах управления TTL можно почитать здесь.
Хоть с управлением TTL как операцией мы сталкивались редко, нам нужна была полноценная интеграция. Поэтому мы вынесли параметры управления временем жизни в меню Housekeeper в web-интерфейсе, доработав контроллер Housekeeper API, дизайн страницы Housekeeper и добавив два новых поля ch_history_global, ch_history в таблицу config:

И пожалуйста — мы получили полноценную интеграцию CH и Zabbix.
[1] СH умеет принимать сообщения в формате JSON, а в Zabbix реализованы все необходимые функции для работы с ним, что облегчило задачу.
[2] Получает данные из БД для отрисовки графиков, последние данные и отображает истории в эвентах и т.д.
[3] Расширяет класс CApiService и реализует интерфейс для получения данных из БД через API.
lgnmx
А как же glaber ?