
Привет! Я Виталий, DevOps в LEADS.SU, в этой статье хочу рассказать как мы внедряли Sentry self-hosted и приводили к продакшен состоянию, которое должно отвечать требованиям высокодоступности - нельзя терять события ошибок. При этом не хотелось заморачиваться с кластеризацией для разных инструментов (вроде redis, postgresql, clickhouse, kafka и прочее). И тут мы вспомнили про распределенную сеть доставки логов из нескольких узлов td-agent и решили попробовать.
Предисловие
Sentry был принесен из предыдущего опыта, раньше я "иногда трекал ошибки". Но после внедрения в нашей компании, я понял что в прошлом использовал лишь малую часть из предоставляемого функционала.
Сначала я предлагал Sentry везде где есть хоть какой-то минимальный профит от использования, почти на каждом созвоне. Отслеживание ошибок приложений, фоновых задач, и всего того куда можно встроить Sentry.
Примерно через месяц мы запустили пилотную версию self-hosted с очень сырой реализацией компонента приложения. Постепенно мы довели нашу обертку над клиентом Sentry до нужного нам состояния, а для сервера организовали высокодоступную сеть доставки из td-agent'ов, настроили мониторинг, и внедрили в производственный процесс.
Sentry VS Logging
Когда я предложил Sentry разработчики возразили: у нас уже есть логирование, там же есть инфа по ошибкам, зачем нам еще один инструмент для логирования ошибок?
В том то и дело - логирование ошибок, а не трекинг. Полагаю скрин из поисковой выдачи покажет нагляднее:

На сайте Sentry есть интересная статья на эту тему, а если кратко то мысль сводится к следующему:
Ведение журнала дает след событий. Иногда эти события являются ошибками, но в большинстве случаев носят информационный характер. Sentry фокусируется только на сбоях приложений.
SaaS VS Self-hosted
Sentry можно использовать как облачное решение SaaS (высокодоступное и отказоустойчивое решение совместимое с PCI-DSS) или потратить несколько месяцев чтобы развернуть и обслуживать самостоятельно self-hosted (репозиторий, документация).

Мы решили пойти по пути самообслуживания так как приложение может считаться безопасным если оно работает на серверах компании-пользователя (здесь мы умолчим про провайдеров защиты от DDoS). Тем более пилотную версию можно развернуть в docker-compose. Как оказалось в таком виде и до production версии недалеко.
Установка Sentry
Мы завели специального пользователя app для работы с контейнерами и приложениями для Sentry.
Разворачивали по инструкции в docker контейнерах почти так:
./install.sh
Но у меня не получилась установка с первого раза, поэтому небольшой чеклист со ссылками:
Если не получилось с первого раза установить и теперь
/etc/sentry/docker-entrypoint.sh: line 20: 999: command not foundЕсли пропустил шаг создания юзера то на форуме есть обсуждение
Если проблемы с миграциями, то можно не указывать sha
В простом варианте нужно создать и сконфигурировать sentry/config.yml.
А если хочется без контейнеров на хосте то можно посмотреть например вот и вот.
LDAP
Для LDAP нам нужно сконфигурировать sentry/enhance-image.sh и sentry/sentry.conf.py. Здесь на хабре уже есть статья про подключение LDAP при установке Sentry, мы же подключали LDAP к работающему инстансу.
Сначала я пошел осторожно на тестовую машину: выяснил в какой контейнер нужно LDAP, зашел в контейнер, установил, погоняли (не без приколов), работает.
Но теперь нельзя down контейнеров потому что down = stop + remove, а значит все наши изменения в контейнере будут потеряны. И когда следующий раз мы up'нем контейнеры - они не поднимутся, потому что конфиг требует пакет ldap для python, а его нет.
Проблема усугублялась тем, что конфигурация docker-compose была идентичная для 8 контейнеров, хотя по факту нужно только в одном sentry-selfhosted-web-1.
Все эксперименты закончились провалом, мне надоело и я решил запустить ./install (на бэкапе машины с Sentry) и посмотреть что будет - все заработало, а потом удалось обновиться.
А позже при обновлении Sentry с 23.5.2 на 23.9.1 выяснилось что пакет sendry-ldap-auth был переименован в sendry-auth-ldap и это ломало вход по LDAP. Но есть обсуждение, которое наводит на нужные мысли по исправлению проблемы.
Обновление Sentry
Все действия производим от пользователя
app.
Первоисточник в документация по обновлению Sentry, а список релизов можно псмотреть на github.
Нам нужно перейти в директорию репозитория Sentry и остановить контейнеры:
cd /sentry/self-hosted
docker compose down
Переходим на основную ветку проекта:
git checkout main
Раньше нужно было прятать свои изменения в репозитории, а после стягивания изменений возвращать обратно. Теперь они добавлены разработчиками в
.gitignore, так что этого делать не надо.
Обновить репозиторий:
# стянуть все обновления
git pull
# перейти на конкретный тег релиза со страницы релизов https://github.com/getsentry/self-hosted/releases
git checkout {version}
Теперь нужно проверить что наши надстройки актуальны, например сверить конфиги из
sentry/*.example.*файлов с тем что у нас есть.
Запустить скрипт обновления:
./install.sh
Запустить Sentry:
docker compose up -d
Убедиться что все контейнеры запущены:
docker ps
Production Sentry
Инструкций по настройке отказоусточивого и высокодоступного кластера Sentry от команды разработки найти не удалось, все темы ведут к рекомендации использовать облачное решение sentry.io

Но нам было интересно как поднять HA self-hosted. Так мы нашли: обсуждение на форуме Sentry, оттуда можно найти ссылки на репозиторий Sentry helm charts и ссылку на статью на китайском языке (через переводчик вполне читабельно), затем можно нагуглить продолжение этой статьи на форуме Sentry. Еще можно нагуглить статью от cloudera.
А мы пошли другим путем ...
Сеть доставки с гарантией

У нас уже была построена сеть доставки логов в Elasticsearch состоящая из узлов td-agent. Сразу стоит упомянуть что td-agent по функционалу это тоже самое что и fluentd, но td-agent содержит в себе fluentd. Кстати, здесь на хабре есть краткая статья про использование fluentd.
В Интернете можно найти плагин Sentry для fluentd и успешно его установить для td-agent, но нам этот вариант не подошел: нам нужна существующая сеть доставки, через которую должны проходить события, и на первых этапах внедрения Sentry мы не хотим обновлять ПО.
На самом деле мы были не против обновления, но внедрение плагина предвещало нам его установку на каждом td-agent'е где отправляются события в Sentry, счет шел на десятки. Посмотрев на встроенный td-agent плагин out_http, мы поняли: он делает то что нам нужно.
Теперь стоит поговорить о том, почему сеть td-agent'ов считается надежной с гарантией доставки событий.
Каждый td-agent умеет гарантировано доставлять события: даже если сервер приемник недоступен, td-agent будет сбрасывать/буферизировать событие в файл на диск (вот еще), и периодически повторять попытку отправки, до истечения лимитов на отправку либо бесконечно. То есть доставка событий асинхронная.
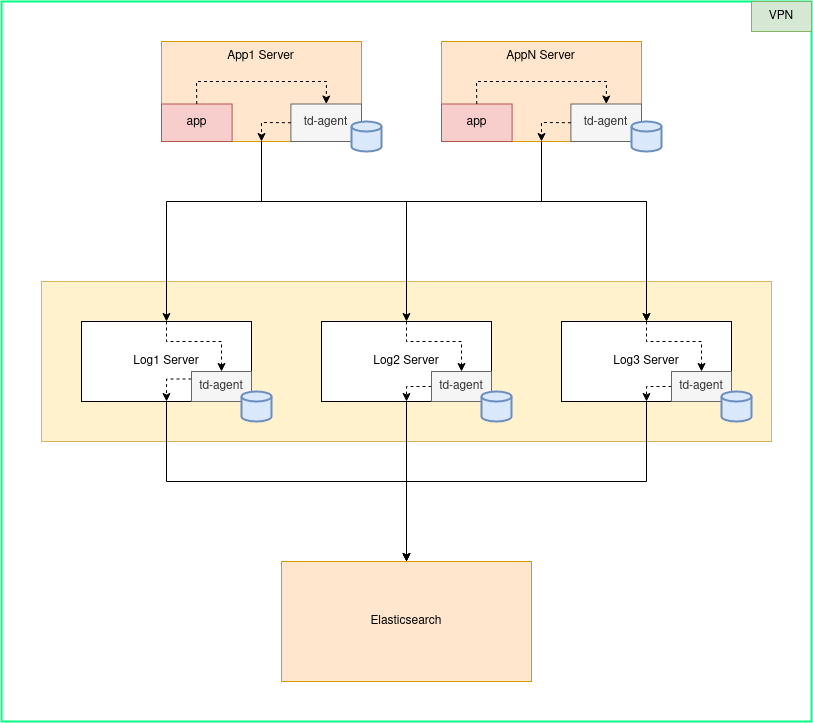
Буферизация события ошибки возможна на любом узле td-agent. Это гарантирует, что в случае недоступности принимающего сервера, буферизация на диск будет осуществляться на подходящем для этого сервере и событие будет доставлено до сервера-приемника когда тот будет работать.
Возникает логичный вопрос: а зачем сеть доставки? Разве нельзя отправлять события из локального td-agent'а в конечное хранилище, например в Sentry?
Во первых: высокодоступность принимающих узлов на входе. Еще раз взгляните на схему выше, у нас на входе 3 узла td-agent принимают события от локальных td-agent'ов, которые отправляют через out_forward с балансировкой нагрузки и обнаружениями сбоев. То есть хотя бы 1 сервер на входе в сеть доставки примет событие от локального td-agent.
Во вторых: стоит посмотреть на рядовую схема нашего обычного сервиса размещенного на одном сервере:
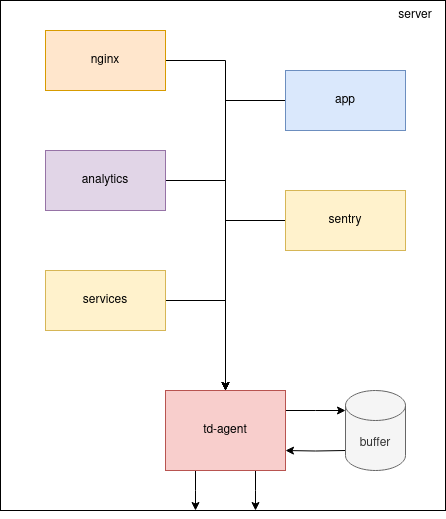
На схеме видно что в локальный td-agent поступают события из нескольких источников на текущем localhost. На каждом таком сервисе мы стремимся к stateless (чтобы как можно меньше данных хранилось на сервере). Если внезапно какие-то конечные хранилища (Sentry или Elasticsearch) станут недоступны, то данные будут копиться на сервере с td-agent. В случае с localhost все это будет там же где приложение - событий много, а выделенного места мало из-за стремления к stateless (конечно есть запас). Значит буферизировать эти данные мы должны на специально созданном для этого сервере где выделено достаточно дискового пространства.
Еще одна приятная особенностью td-agent: события можно писать в unix socket, а это значительно быстрее чем отправка по http. Разницу можно увидеть на диаграмме ниже, она взята из доклада на конференции Middleware 2007 под авторством Сюзанны Макинтош и соавторов:
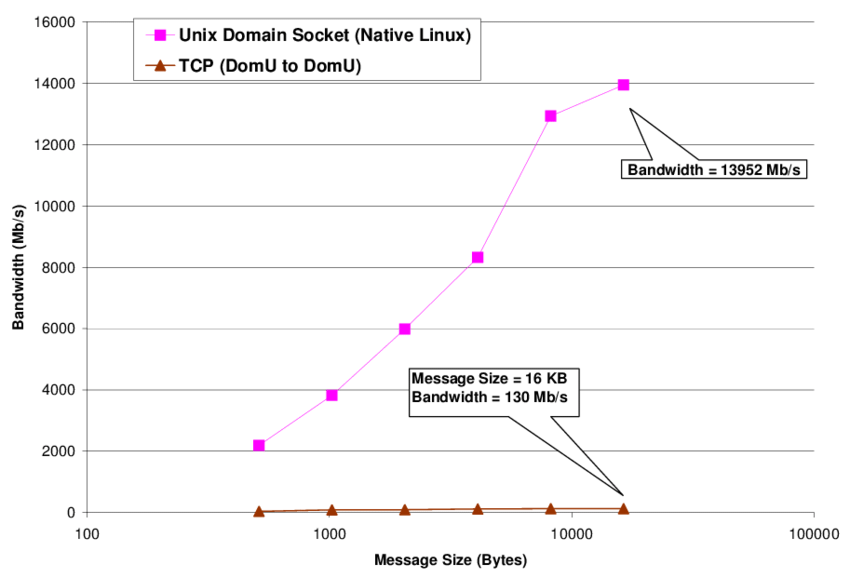
Все это подводит нас к следующему:
если сервер Sentry недоступен или отвечает
>=500то наш транспортировщик (td-agent) гарантированно доставит события позжеесли научить клиента Sentry писать в
unix-socketто снизится время передачи событий для транспортировки
Оба преимущества имеют асинхронную природу и позволяют отделить этап генерации события об ошибке, от этапа гарантированной доставки, а значит наше приложение может не беспокоиться о доставке и задержках.
Если принять доказательства надежности сети доставки событий, то все-равно остается вопрос: Sentry клиент и Sentry сервер работают синхронно по http, как сюда воткнуть ассинхронную доставку через td-agent?

На самом деле ни клиенту ни серверу необязаталельно работать синхронно, если только вы не хотите знать ответ сервера на отправку вашего события. Но это не имеет особого смысла, поэтому внедрив между клиентом и сервером асинхронный прокси доставщик, мы нисколько не нарушим протокол работы обоих компонентов трекинга ошибок.
Backend
Для некоторых приложений в backend мы используем php, для этого есть sentry-sdk, который использует store endpoint с json в теле. Все это хорошо ложится на td-agent.
Что нам нужно:
в клиенте подменить транспортировку - отправку по
httpзаменяем отправкой вunix socketна локальном
td-agent'едобавляем конфиг, который будет принимать события с нашим тегом и отправлять их дальше в нашу сеть доставки, точно с таким же тегомна финальном узле
td-agent'адобавляем конфиг приема событий с нашим тегом и отправкой этого события в Sentry поhttp
Если по каким-то причинам локальный
td-agentне сможем отправить событие дальше, он его буферизирует на диск и будет ждать подходящего случая.
Все детали мы реализовали на тестовом стенде, который доступен в нашем репозитории. Поэтому опустим реализацию и посмотрим на движение данных:
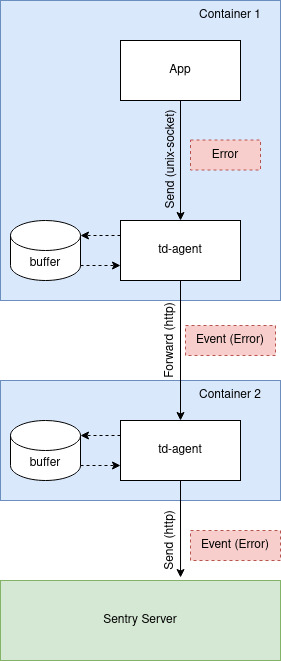
И здесь мы просто перегоняем данные без изменений потому что json, в отличии от frontend.
Frontend
На frontend очевидно javascript, и здесь sentry-javascript использует envelope endpoint с ndjson, это доставляет проблемы потому что td-agent не работает с многострочным json (список форматов).
Немного почитав документацию было найдено решение: в плагине in_http parse: none, а в out_http format: single_value - теперь тело запроса будет передано из приемника в транслятор "как есть".
Ладно, различия понятны, но вот желания вмешиваться в реализацию клиента (как это мы делали на php) совсем нет тем более на javascript. Но у нас есть наш штатный, программируемый и проксируемый инстурмент HAProxy, который нам поможет. Здесь пригодились телепатические способности потому что в документации нужных для реализации средств найти не удалось.
Что нам нужно:
нода с
HAProxy, куда дляfrontendвстроим обработкуluaскриптом, который сделает всю работу по преобразованию запроса в понятный вид дляtd-agentобязательно нужно отправить в высокодоступную сеть, потому что у нас есть только однак попытка, если
HAProxyне сможет достучаться доtd-agentто событие будет утерянофинальная нода с
td-agent, которая примет событие с нашим тегом и отправит его в Sentry поhttp(это событие не похоже на точто было вbackend)

Но здесь есть интересная особенность: сервер Sentry может быть вообще недоступен из Интернета, потому что все может делаться в нашей внутренней сети. Для этого мы можем проложить "ассинхронный маршрут" опубликовав HAProxy с единственным endpoint (ну почти) во внешний мир.
Как и в прошлый раз детали реализованы на тестовом стенде.
В конечно итоге у нас получается такая схема серверов в сети доставки событий ошибок от приложений до Sentry:
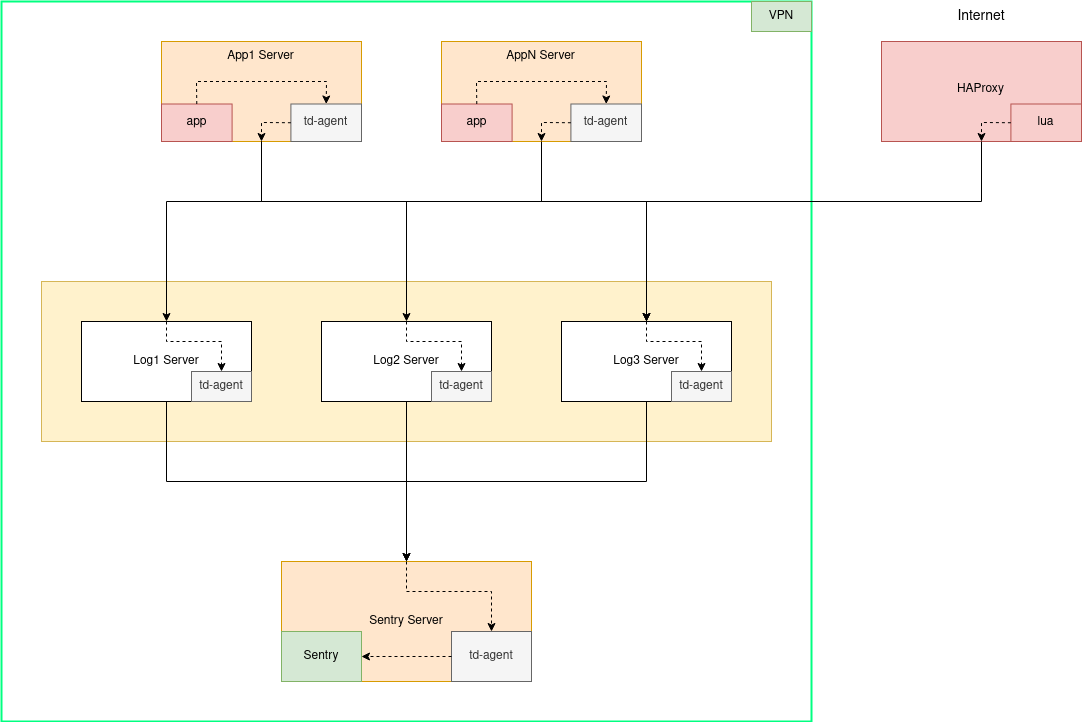
Буферизация и потеря событий
После настройки и внедрения Sentry в приложения, мы обнаружили что не все события-ошибки доставляются до сервера, что-то теряется на пути, и дело вовсе не в маршрутной инфраструктуре td-agent'ов.
Оказалось: виновник недоставки неверный конфиг td-agent конечного узла, который отправляет событие в Sentry.
Еще раз вернемся к буферизации в td-agent: она нужна для отложенной доставки чтобы дождаться доступности конечного сервера-приемника. Еще на этапе буферизации используется группировка событий. Группировка может быть на основании данных, мы использовали только тег состоящий условно из project_id.sentry_key. События для одного и того же проекта в одну и ту же секунду склеивались, потому что теги одинаковые!
Буферизация == группировка == пакетная отправка
Исправили путем добавления еще одного критерия группировки на основании event_id - то есть вообще без группировки, потому что у каждого события event_id уникальный.
На графике из Kibana видно что до фикса мы ежедневно теряли события, а после перестали терять:
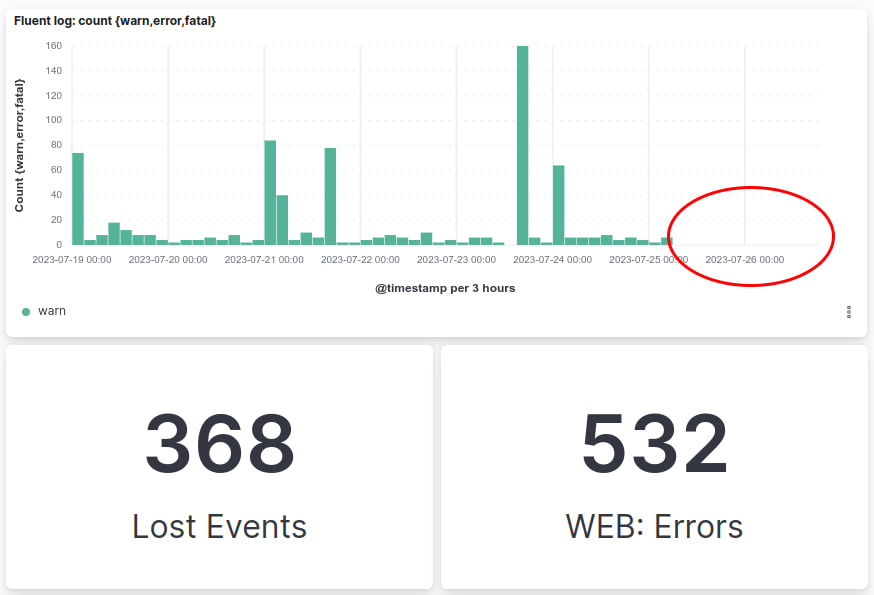
Мониторинг
Для эксплуатации важны жизненные показатели сервера, поэтому в zabbix мы организовали такой дашборд:

может ли Sentry принимать события об ошибках, ответ
200- может, в ином случае проблемаработает ли
sentryhooks* (чтобы можно было создавать карточки на доске Kaiten изissueв Sentry), ответ200- может, в ином случае проблема
* sentryhooks это web-сервер интеграции трекера задач Kaiten и трекера ошибок Sentry, о нем поговорим в другой раз
Остальные графики выведены на этот дашборд как наиболее важные для понимания проблем с сервером.
Основной характеристикой жизни Sentry является возможность приема и просмотра событий. Для этого был сделан специльный проект в Sentry для фейковых issue и были сделаны bash скрипты для отправки и просмотра фейковых событий через Sentry API на предмет поступления новых событий.
В Zabbix были заведены графики с триггерами (для каждого пункта отдельная issue в Sentry):
отправка* и проверка** события через store endpoint
отправка* и проверка** события через envelope endpoint
отправка* и проверка** события через envelope tunnel endpoint
* График отправки показывает ответ web-сервера Sentry, при штатной работе ожидаем 200.
** График проверки показывает сколько минут назад было последнее событие. Если дольше 15 минут возможны проблемы в работе Sentry.

Сбор логов

Сервис Sentry доступен публично, один envelope endpoint но публично, поэтому хотелось бы знать про:
количество и качество трафика (nginx графики), здесь можно видеть какие методы запросов идут и какие ответы получают
типы и уровень внутренних событий Sentry (web графики), например некоторое время web-сервис Sentry отклонял события и мы не могли понять почему
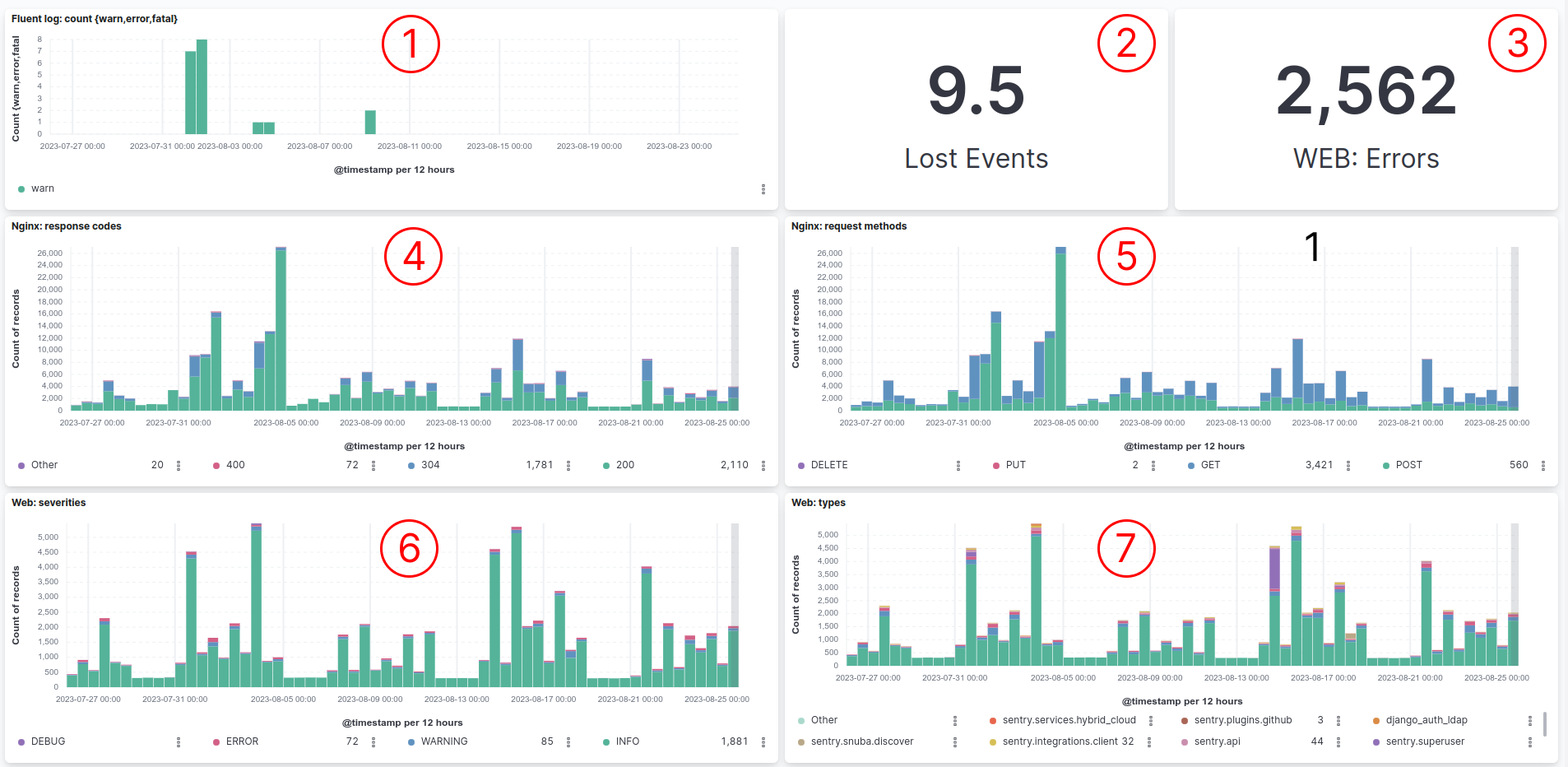
График потерянных (отклоненных Sentry) событий об ошибках
Количество потерянных событий
Количество ошибок выданных web-сервисом
Коды ответов от web-сервиса
Методы запросов к web-сервису
Уровни сообщений лога в web-сервисе
Сервисы отвечающие ошибками web-сервису
Сборка осуществляется через td-agent путем подмены драйвера логирования, а конфигурирование инфраструктуры через docker-compose.override.yml, этот файл размещаем прямо в корне репозитория Sentry self-hosted:
docker-compose.override.yml
services:
web:
logging:
driver: "fluentd"
options:
fluentd-address: localhost:24224
#fluentd-async: 'true'
tag: sentry-docker.web
nginx:
logging:
driver: "fluentd"
options:
fluentd-address: localhost:24224
#fluentd-async: 'true'
tag: sentry-docker.nginx
Конфиг td-agent'a выглядит так:
td-agent.conf
<source>
@type forward
port 24224
bind 0.0.0.0
</source>
#########################
# WEB
#########################
# отсекаем строки лога web-сервиса которые не сообщают нам о запросах, иногда в лог сыпятся стектрейсы python
<filter sentry-docker.web>
@type grep
<regexp>
key log
pattern /^(?:[^ ]*)\s+\[(?:\w+)\]\s+(?:.+)$/gm
</regexp>
</filter>
<filter sentry-docker.web>
@type parser
<parse>
#@type regexp
#expression /^(?:[^ ]*)\s+\[(?<severity>\w+)\]\s+(?:[^ ]*)\s+(?<type>[^ ]*)\s+\((?:method\=\'(?<method>[^\']*))\'\s+(?:[^ ]*)\s+(?:response\=(?<response>[^ ]*))\s+(?:user_id\=\'(?<user_id>[^\']*)\')\s+(?:is_app\=\'(?<is_app>[^\']*)\')\s+(?:token_type\=\'(?<token_type>[^\']*)\')\s+(?:is_frontend_request\=\'(?<is_frontend_request>[^\']*)\')\s+(?:organization_id\=\'(?<organization_id>[^\']*)\')\s+(?:auth_id\=\'(?<auth_id>[^\']*)\')\s+(?:path\=\'(?<path>[^\']*)\')\s+(?:caller_ip\=\'(?<caller_ip>[^\']*)\')\s+(?:user_agent\=\'(?<user_agent>[^\']*)\')\s+(?:rate_limited\=\'(?<rate_limited>[^\']*)\')\s+(?:rate_limit_category\=\'(?<rate_limit_category>[^\']*)\')\s+(?:request_duration_seconds\=(?<request_duration_seconds>[^\']*))\s+(?:rate_limit_type\=\'(?<rate_limit_type>[^\']*)\')\s+(?:concurrent_limit\=\'(?<concurrent_limit>[^\']*)\')\s+(?:concurrent_requests\=\'(?<concurrent_requests>[^\']*)\')\s+(?:reset_time\=\'(?<reset_time>[^\']*)\')\s+(?:group\=\'(?<group>[^\']*)\')\s+(?:limit\=\'(?<limit>[^\']*)\')\s+(?:remaining\=\'(?<remaining>[^\']*)\')\)?/gm
#types response:integer, user_id:integer, organization_id:integer, request_duration_seconds:float
@type regexp
expression /^(?:[^ ]*)\s+\[(?<severity>\w+)\]\s+(?<type>.[^:]+):\s+(?<message>.+)$/gm
time_format %d/%b/%Y:%H:%M:%S %z
</parse>
key_name log
</filter>
#######################
# NGINX
#######################
# отсекаем строки лога nginx которые не сообщают о запросах (warn и прочее)
<filter sentry-docker.nginx>
@type grep
<regexp>
key log
pattern /^(?:[^ ]*) (?:[^ ]*) (?:[^ ]*) \[(?:[^\]]*)\]/
</regexp>
</filter>
<filter sentry-docker.nginx>
@type parser
<parse>
@type regexp
expression /^(?<remote>[^ ]*) (?<host>[^ ]*) (?<user>[^ ]*) \[(?<time>[^\]]*)\] "(?<method>\S+)(?: +(?<path>[^\"]*?)(?: +\S*)?)?" (?<code>[^ ]*) (?<size>[^ ]*)(?: "(?<referer>[^\"]*)" "(?<agent>[^\"]*)"(?:\s+(?<http_x_forwarded_for>[^ ]+))?)?$/
time_format %d/%b/%Y:%H:%M:%S %z
types code:integer, size:integer
</parse>
key_name log
</filter>
######################
<match sentry-docker.*>
# отправляем логи в хранилище, у нас Elasticsearch
</match>
Заключение
Внедрение было шероховатым, но удовлетворяет все наши условия, а от сотрудника на обслуживании не требует специльных знаний кластеризации, потому что кластера нет.
Высокодоступность Sentry для приложений обеспечивает сеть доставки td-agent, а для менеджмента не долго переподнять VPS, на уровне администрирования у нас есть достаточные ресурсы для обеспечения быстрого восстановления. Тем более что Sentry за время нашего использования работает безотказно.
Уже больше полугода используем описанную конфигурацию доставки событий до Sentry, работает стабильно.