

Всем привет. Решил поделиться новостью, может кому-то будет интересно. Я закончил перевод книги Windows APT Warfare. В своем роде очень интересное чтиво, для тех кто занимается ассемблером, малварью и информационной безопасностью. Первую часть оставлю здесь. Всю остальную книгу можно забрать на дамаге, ныне — xss.is. Может кто-то сможет сверстать в PDF, буду очень благодарен. Всем спасибо.
От исходного кода к двоичным файлам: путь программы на C
В этой главе мы изучим основы того, как компиляторы упаковывают двоичные файлы EXE из кода C, и методы выполнения системных процессов. Эти основные понятия помогут вам понять, как Windows компилирует C в программы и связывает их между системными компонентами. Вы также поймете структуру программы и рабочий процесс, которым должны следовать анализ вредоносного ПО.
В этой главе мы рассмотрим следующие основные темы:
- Простейшая программа для Windows на C
- Компилятор C – генерация ассемблерного кода
- Ассемблер – преобразование ассемблерного кода в машинный код
- Компиляция кода
- Компоновщик Windows — упаковка бинарных данных в формат Portable Executable (PE)
- Запуск скомпилированных исполняемых файлов PE как динамических процессов
Простейшая программа Windows на C
Любое программное обеспечение разработано с учетом определенной функциональности. Эта функциональность может включать в себя такие задачи, как чтение внешних входных данных, их обработка в соответствии с ожиданиями инженера или выполнение определенной функции или задачи. Все эти действия требуют взаимодействия с базовой операционной системой (ОС). Программа, чтобы взаимодействовать с базовой ОС, должна вызывать системные функции. Практически невозможно разработать осмысленную программу, не использующую никаких системных вызовов.
Кроме того, в Windows программисту при компиляции программы на C необходимо указать подсистему (подробнее об этом можно прочитать на docs.microsoft.com/en-us/cpp/build/reference/subsystem-specify-subsystem); windows и console, вероятно, являются двумя наиболее распространенными.
Давайте рассмотрим простой пример программы на C для Windows:

Здесь представлена максимально упрощенная программа на языке C для Windows. Его цель — вызвать функцию USER32!MessageBox() в точке входа функции main(), чтобы открыть всплывающее окно с информационным заголовком и приветственным содержимым.
Компилятор C — генерация ассемблерного кода
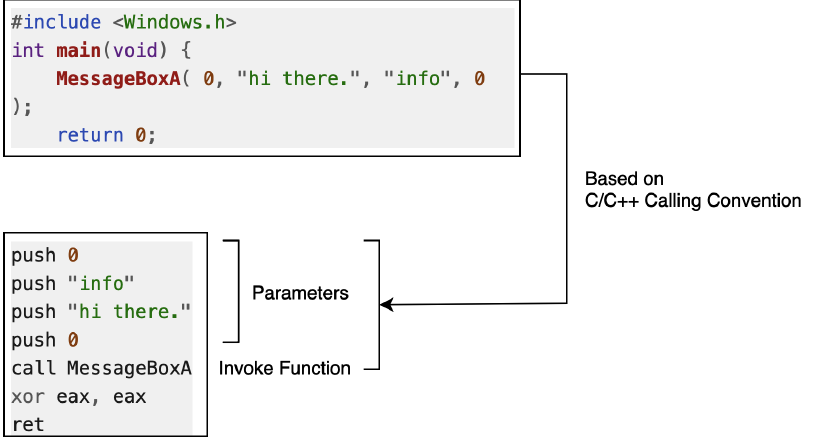
Что интересно понять в предыдущем разделе, так это причину, по которой компилятор понимает этот код C. Во-первых, основная задача компилятора — преобразовать код C в код сборки в соответствии с соглашением о вызовах C/C++, как показано на рис. 1.1:
Для удобства и практичности следующие примеры будут представлены с инструкциями x86. Однако методы и принципы, описанные в этой книге, являются общими для всех систем Windows, а примеры компиляторов основаны на коллекции компиляторов GNU (GCC) для Windows (MinGW).
Поскольку различные системные функции (и даже сторонние модули) имеют ожидаемый доступ в памяти к уровню памяти ассемблерного кода, существует несколько основных соглашений о вызовах двоичного интерфейса приложения (ABI) для простоты управления. Заинтересованные читатели могут обратиться к документам Microsoft о передаче аргументов и именовании (https://docs.microsoft.com/en-us/cpp/cpp/argument-passing-and-naming-conventions).
Эти соглашения о вызовах в основном касаются нескольких вопросов:
- Позиция, в которой параметры размещаются по порядку (например, в стеке, в регистре, таком как ECX, или смешиваются для ускорения работы)
- Объем памяти, занимаемый параметрами, если параметры необходимо сохранить
- Занятая память, которая будет освобождена вызывающим или вызываемым абонентом
Когда компилятор генерирует ассемблерный код, он распознает соглашения о вызовах системы, упорядочивает параметры в памяти в соответствии со своими предпочтениями, а затем вызывает адрес памяти функции с помощью команды call. Следовательно, когда поток переходит к системной инструкции, он может правильно получить параметр функции по ожидаемому адресу памяти.
Возьмем в качестве примера рис. 1.1: мы знаем, что функция USER32!MessageBoxA предпочитает соглашения о вызовах WINAPI. В этом соглашении о вызовах содержимое параметра помещается в стек справа налево, а память, освобождаемая для этого соглашения о вызовах, выбирает вызываемый объект. Таким образом, после помещения в стек 4 параметров, занимающих 16 байт в стеке (sizeof(uint32_t) x 4), код будет выполнен в USER32!MessageBoxA. После выполнения запроса функции вернитесь к следующей строке инструкции Call MessageBoxA с ret 0x10 и освободит 16 байт памяти из стека (т. е. xor eax, eax).
Книга посвящена только тому, как компилятор генерирует сингл-чип инструкции и инкапсулирует программу в исполняемый файл. Он не включает важные части продвинутой теории компилятора, такие как создание семантического дерева и оптимизация компилятора. Эти части зарезервированы для читателей, чтобы изучить их для дальнейшего обучения.
В этом разделе мы узнали о соглашении о вызовах C/C++, о том, как параметры размещаются в памяти по порядку и как освобождается память после завершения программы.
Ассемблер — преобразование ассемблерного кода в машинный код
В этот момент вы можете заметить, что что-то не так. Микросхемы процессоров, которые мы используем каждый день, не способны выполнять текстовый ассемблерный код, а вместо этого преобразуются в машинный код соответствующего набора инструкций для выполнения соответствующих операций с памятью. Таким образом, в процессе компиляции ранее упомянутый ассемблерный код преобразуется ассемблером в машинный код, понятный чипу.
На рис. 1.2 показано распределение динамической памяти 32-битного PE:
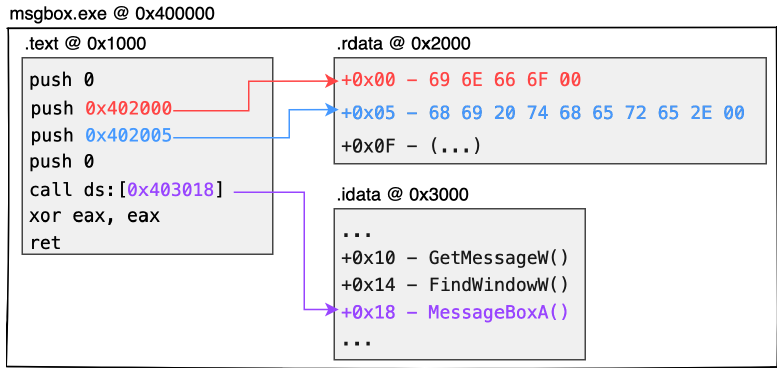
Поскольку чип не может напрямую анализировать такие строки, как ПРИВЕТ МИР или ИНФО, данные (такие как глобальные переменные, статические строки, глобальные массивы и т. д.) сначала сохраняются в отдельной структуре, называемой секцией. Каждый раздел создается со смещенным адресом, где он должен быть размещен. Если позже коду потребуется извлечь ресурсы, идентифицированные в течение этих периодов компиляции, соответствующие данные можно получить по соответствующим адресам смещения. Вот пример:
- Вышеупомянутая информационная строка может быть выражена как \x69\x6E\x66\x6F\x00 в коде ASCII (всего 5 байтов с нулем в конце строки). Двоичные данные этой строки можно хранить в начале раздела .rdata. Точно так же строка приветствия может храниться рядом с предыдущей строкой по адресу раздела .rdata со смещением +5.
- На самом деле вышеупомянутый вызов MessageBoxA API не понимается чипом. Поэтому компилятор создаст структуру таблицы адресов импорта, которая является разделом .idata, для хранения адреса системной функции, которую хочет вызвать текущая программа. Когда это необходимо программе, соответствующий адрес функции может быть извлечен из этой таблицы, что позволяет потоку перейти к адресу функции и продолжить выполнение системной функции.
- Вообще говоря, компилятор обычно хранит содержимое кода в секции .text.
- Каждый отдельный запущенный процесс не имеет только одного PE-модуля. Либо *.EXE, либо *.DLL, смонтированные в памяти процесса, упакованы в формате PE.
- На практике каждому модулю, загружаемому в память, должен быть присвоен базовый адрес образа для хранения всего содержимого модуля. В случае 32-разрядного *.EXE базовый адрес образа обычно равен 0x400000.
- Абсолютным адресом каждого фрагмента данных в динамической памяти будет базовый адрес образа этого модуля + смещение раздела + смещение данных на разделе. В качестве примера возьмем базовый адрес образа 0x400000. Если мы хотим получить информационную строку, ожидаемое содержимое будет размещено по адресу 0x402000 (0x400000 + 0x2000 + 0x00). Точно так же ПРИВЕТ будет находиться по адресу 0x402005, а указатель MessageBoxA будет храниться по адресу 0x403018.
Нет никакой гарантии, что на практике компилятор сгенерирует разделы .text, .rdata и .idata или что они будут использоваться для этих функций. Большинство компиляторов следуют ранее упомянутым принципам выделения памяти. Компиляторы Visual Studio, например, не создают исполняемые программы с разделами .idata для хранения таблиц указателей функций, а скорее с разделами .rdata, доступными для чтения и записи.
Здесь лишь приблизительное понимание свойств блочной и абсолютной адресации в динамической памяти; не нужно зацикливаться на понимании содержания, атрибутов и того, как правильно их заполнить на практике. В следующих главах будет подробно объяснено значение каждой структуры и то, как ее спроектировать самостоятельно.
В этом разделе мы узнали о преобразовании операций машинного кода во время выполнения программы, а также о различных разделах и смещениях данных, хранящихся в памяти, к которым можно получить доступ позже в процессе компиляции.
Компиляция кода
Как упоминалось ранее, если код содержит непонятные чипу строки или текстовые функции, компилятор должен сначала преобразовать их в абсолютные адреса, понятные чипу, а затем сохранить их в отдельных разделах. Также необходимо перевести текстовый сценарий в собственный код или машинный код, который сможет распознать чип. Как это работает на практике?
В случае Windows x86 инструкции, выполняемые на ассемблере, транслируются в соответствии с набором инструкций x86. Текстовые инструкции переводятся и кодируются в машинный код, который
понимает чип. Заинтересованные читатели могут выполнить поиск x86 Instruction Set в Google, чтобы найти полную таблицу инструкций или даже закодировать ее вручную, не полагаясь на компилятор.
После того, как компилятор завершит вышеупомянутую упаковку блока, следующим этапом будет извлечение и кодирование текстовых инструкций из скрипта, одна за другой, в соответствии с набором инструкций x86, и запись их в раздел .text, который используется для хранения машинного кода.
Как показано на рис. 1.3, пунктирная рамка — это ассемблерный код текстового типа, полученный в результате компиляции кода C/C++:
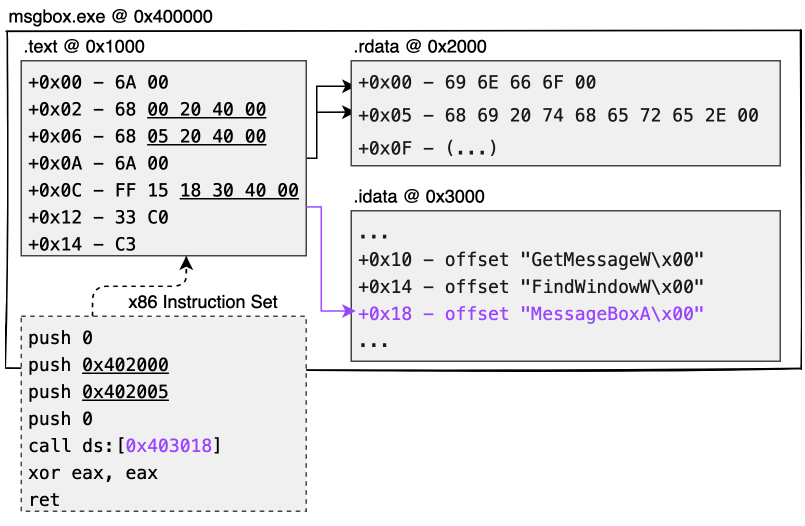
Вы можете видеть, что первая инструкция — это push 0, которая помещает 1 байт данных в стек (сохраняется как 4 байта), а 6A 00 используется для представления этой инструкции. Инструкция push 0x402005 одновременно помещает в стек 4 байта, поэтому push 68 50 20 40 00 используется для достижения более длинной инструкции push. call ds:[0x403018] — это адрес из 4 байтов и длинный вызов машинного кода, FF 15 18 30 40 00, используется для представления этой инструкции.
Хотя на рис. 1.3 показано распределение памяти динамического файла msgbox.exe, файл, созданный компилятором, еще не является исполняемым PE-файлом. Скорее, это файл под названием Common Object File Format (COFF) или объектный файл, как его называют некоторые люди, который представляет собой файл-оболочку, специально предназначенный для записи различных секций, создаваемых компилятором. На следующем рисунке показан файл COFF, полученный путем компиляции и сборки исходного кода с помощью команды gcc -c и просмотра его структуры с помощью известного инструмента PEview.
Как показано на рис. 1.4, в начале COFF-файла имеется структура IMAGE_FILE_HEADER для записи количества включенных секций:
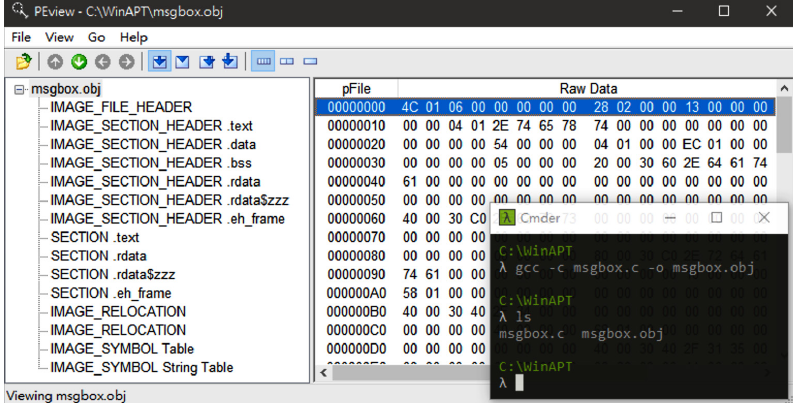
В конце этой структуры находится целый массив IMAGE_SECTION_HEADER для записи текущего местоположения и размера содержимого каждого раздела в файле. В конце этого массива тесно связано основное содержание каждого раздела. На практике первый раздел обычно будет содержимым раздела .text.
На следующем этапе компоновщик отвечает за добавление в загрузчик приложения экстра фрагмента COFF-файла, который станет нашей общей EXE-программой.
В случае систем с чипом x86 принято менять местами указатель и цифру на бит в памяти при кодировании. Эта практика называется прямым порядком байтов, в отличие от строки или массива, которые должны располагаться от младшего к старшему адресу. Расположение данных из нескольких байтов зависит от архитектуры микросхемы. Заинтересованные читатели могут обратиться к статье Как писать независимый от порядков байтов код на C (https://developer.ibm.com/articles/au-endianc/).
В этом разделе мы узнали о COFF, который используется для записи содержимого в память различных секций, записанных компилятором.
Компоновщик Windows — упаковка бинарных данных в формат PE
В предыдущем разделе мы предполагали некоторое распределение памяти во время компиляции программы. Например, база образа EXE-модуля по умолчанию должна иметь адрес 0x400000, чтобы исполняемый контент должен быть размещен. Раздел .text должен располагаться по адресу 0x401000 над базовым образом. Как мы уже говорили, раздел .idata используется для хранения таблицы адресов импорта, поэтому возникает вопрос, кто или что отвечает за заполнение таблицы адресов импорта?
Ответ заключается в том, что в каждой ОС есть загрузчик приложений, который предназначен для корректного выполнения всех этих задач при создании процесса из статической программы. Однако есть много информации, которая будет известна только во время компиляции, а не разработчику системы, например:
- Требуется ли программе включить рандомизацию размещения адресного пространства (ASLR) или предотвращение выполнения данных (DEP)?
- Где находится функция main(int, char) в разделе .text, написанная разработчиком?
- Какая часть общей памяти используется исполнительным модулем во время динамической фазы?
Поэтому Microsoft представила формат PE, который, по сути, является расширением файла COFF, с дополнительной опциональной структурой заголовка для записи информации, необходимой загрузчику программы Windows для корректировки процесса. В следующих главах основное внимание будет уделено игре с различными структурами формата PE, чтобы вы могли написать исполняемый файл вручную сами на коленке.
Все, что вам нужно знать сейчас, это то, что исполняемый файл PE имеет некоторые ключевые особенности:
- Код: обычно хранится в виде машинного кода в разделе .text.
- Таблица импорта: чтобы позволить загрузчику заполнить адреса функций и позволить программе правильно их получить.
- Необязательный заголовок: эта структура позволяет загрузчику читать и знать, как исправить текущий динамический модуль.
Вот пример на рисунке 1.5:

msgbox.exe — это минималистичная программа для Windows, состоящая всего из трех разделов: .text, .rdata и .idata. После динамического выполнения загрузчик системного приложения последовательно извлекает содержимое трех секций и записывает их каждую по смещению 0x1000, 0x2000 и 0x3000 относительно текущего PE-модуля (msgbox.exe).
В этом разделе мы узнали, что загрузчик приложения отвечает за исправление и заполнение содержимого программы для создания статического файла программы в процессе.
Запуск статических PE-файлов как динамических процессов
К этому моменту у вас есть общее представление о том, как минимальная программа генерируется, компилируется и упаковывается компилятором в исполняемый файл на статической фазе. Итак, следующий вопрос: что делает ОС, чтобы запустить статическую программу?
На рис. 1.6 показана структура процесса преобразования исполняемой программы из статического в динамический процесс в системе Windows:
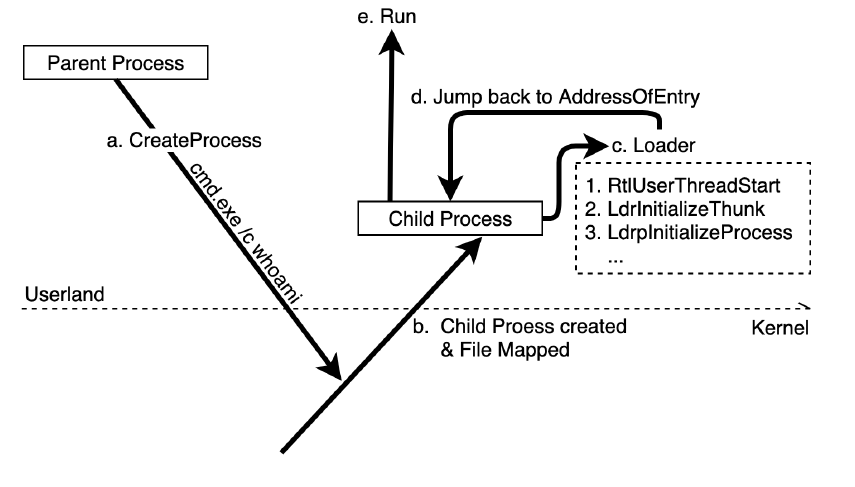
Обратите внимание, что это отличается от процесса хатчинга последней версии Windows. Ради пояснения мы проигнорируем процессы повышения привилегий, механизм патча и генерацию ядра, а поговорим только о том, как правильно анализируется и запускается статическая программа.
В системах Windows все процессы должны запускаться родительским процессом путем прерывания системной функции для перехода на уровень ядра. Например, родительский процесс в настоящее время пытается запустить команду cmd. exe /c whoami, которая представляет собой попытку превратить статический файл cmd.exe в динамический процесс и назначить его параметры /c whoami.
Итак, что же происходит во всем процессе? Как показано на рисунке 1.6, это шаги:
1. Родительский процесс делает запрос к ядру с помощью CreateProcess, указывая на создание нового процесса (дочернего процесса).
2. Затем ядро создаст новый контейнер процессов и заполнит контейнер исполняемым кодом с сопоставлением файлов. Ядро создаст поток для назначения этому дочернему процессу, который обычно называют основным потоком или потоком GUI. В то же время ядро также организует блок памяти в динамической памяти Userland для хранения двух структурных блоков: блока среды процесса (PEB) для записи текущей информации о среде процесса и блока среды потока (TEB) для записи информации о среде потока. Подробная информация об этих двух структурах будет полностью представлена в главе 2 «Память процесса — сопоставление файлов, синтаксический анализатор PE, tinyLinker и Hollowing» и в главе 3 «Вызов динамического API — информация о потоке, процессе и среде».
3. Функция экспорта NtDLL, RtlUserThreadStart, является основной функцией маршрутизации для всех потоков и отвечает за необходимую инициализацию каждого нового потока, например за создание структурированной обработки исключений (SEH). Первый поток каждого процесса, то есть основной поток, выполнит NtDLL!LdrInitializeThunk на уровне пользователя и войдет в функцию NtDLL!LdrpInitializeProcess после первого выполнения. Это исполняемый программный загрузчик, отвечающий за необходимое исправление загружаемого в память PE-модуля.
4. После того, как загрузчик выполнения завершает исправление, он возвращается к текущей записи выполнения (AddressOfEntryPoint), которая является основной функцией разработчика.
С точки зрения кода поток можно рассматривать как человека, ответственного за выполнение кода, а процесс можно рассматривать как контейнер для загрузки кода.
Уровень ядра отвечает за сопоставление файлов, то есть процесс размещения содержимого программы на основе предпочтительного адреса в период компиляции. Например, если базовый адрес образа равен 0x400000, а смещение .text равно 0x1000, то процесс сопоставления файлов, по сути, сводится к простому запросу блока памяти по адресу 0x400000 в динамической памяти и записи фактического содержимого .text по адресу 0x401000.
На самом деле функция-загрузчик (NtDLL!LdrpInitializeProcess) после выполнения напрямую не вызывает AddressOfEntryPoint; вместо этого задачи, исправленные загрузчиком и точкой входа, рассматриваются как два отдельных потока (на практике будут открыты два контекста потока). NtDLL!NtContinue будет вызвана после исправления и передаст задачу в запись для продолжения выполнения в качестве расписания задачи потока.
Точка входа выполнения записывается в NtHeaders→OptionalHeader. AddressOfEntryPoint структуры PE, но не является прямым эквивалентом основной функции разработчика. Это только для вашего понимания. Вообще говоря, AddressOfEntryPoint указывает на функцию CRTStartup (C++ Runtime Startup), которая отвечает за ряд необходимых подготовительных действий C/C++ по инициализации (например, преобразование аргументов в удобные для разработчика вводы) перед вызовом основной функции разработчика.
В этом разделе мы узнали, как EXE-файлы превращаются из статических в динамически работающие процессы в системе Windows. С процессом и потоком и необходимыми действиями по инициализации программа готова к запуску.
Итоги
В этой главе мы объяснили, как ОС преобразует код C в ассемблерный код с помощью компилятора и в исполняемые программы с помощью компоновщика.
Следующая глава будет основана на этой структуре и проведет вас через практический опыт работы со всей блок-схемой в нескольких лабах C/C++. В следующих главах вы изучите тонкости проектирования формата PE, создав компактный загрузчик программ и самостоятельно написав исполняемую программу.
Комментарии (2)

vb64
11.10.2023 16:32+1Насчет рендера в pdf. Если текст в markdown, то можете попробовать вот этот способ.
Если возникнут проблемы/вопросы/пожелания, пишите в личку.
gmtd
(удалено)