
На сегодняшний день существуют сотни программ для оценки производительности вычислительных устройств, но абсолютным лидером среди них несомненно является PassMark - "Industry standard benchmarking since 1998", - как его позиционирует сам разработчик, и вдобавок предоставляющего обширную публичную базу оценок производительности разнообразных устройств по всему миру для возможности их сравнения между собой. Все это делает PassMark выбором №1 для всех, кто не только желает оценить производительность своего устройства, но и сравнить его с любым другим устройством в мире.
Но что находится под капотом у легендарной программы для бенчмаркинга? В этой статье мы изучим ее алгоритмы тестирования и воспроизведем их самостоятельно на других языках программирования, чтобы иметь независимую возможность получения оценки производительности.
Эта статья и ей подобные исследования сначала публикуются на моем сайте bekhan.org. Узнать первыми о публикациях можно в моих сообществах.
Общий обзор работы PassMark
На момент публикации статьи актуальная версия PassMark - 10.1
Если зайти на официальную страницу загрузки PassMark, мы увидим, что программа кроссплатформенная, и на первый взгляд может показаться, что сборка происходит из единой кодовой базы (по крайней мере ядро кодовой базы с набором бенчмарков), однако на практике это не так - исходный код, как и интерфейс, сильно разнятся от платформы к платформе, что тем не менее позволяет достигать универсальности оценки между разными платформами (в ходе аудита убедимся, так ли это на самом деле).
Интерфейс в MacOS:
Интерфейс в Windows:
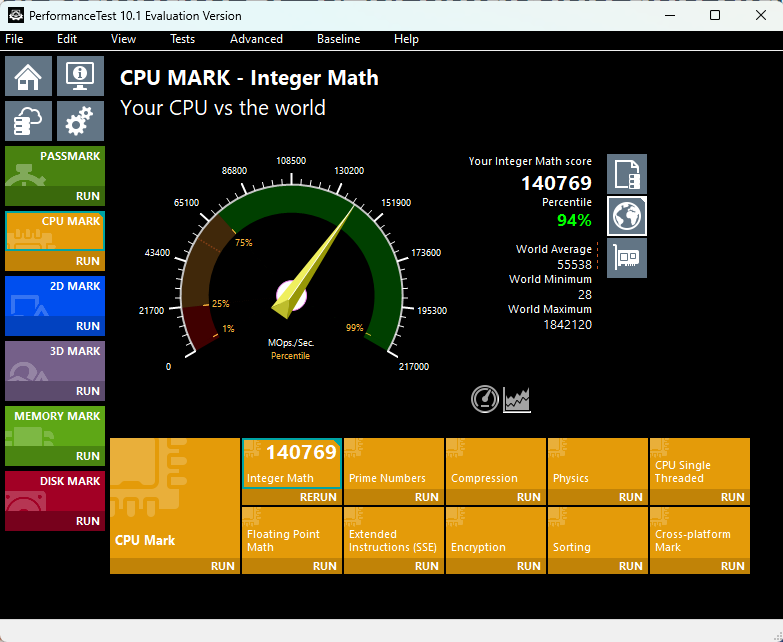
Windows-версия PassMark, к примеру, представлена в виде множества исполняемых файлов под каждый бенчмарк (CPU Mark, 2D Mark и т.д) на скриншоте, а MacOS - как standalone файл, содержащий в себе все бенчмарки.
Файловая структура PassMark в Windows:

При запуске любого теста из бенчмарка (Integer Math, Floating Point Math и т.д.) программа PassMark порождает новые процессы, количество которых равно числу ядер процессора. Это делается для максимальной загрузки CPU через параллелизм: на каждое ядро приходится один процесс. После завершения работы каждого процесса программа собирает их числовые результаты для последующего суммирования.
Способ порождения новых процессов разнится от платформы к платформе. В MacOS, например в ходе работы бенчмарка CPU Mark, делается fork основного процесса PassMark, а в Windows - запускается отдельный процесс PT-CPUTest с параметрами командной строки, позволяющими контролировать длительность теста по времени и число используемых ядер процессора:
PT-CPUTest64.exe [-slave|-standalone] [№ теста CPU] [число ядер] [длительность выполнения в милисекундах]
Это же отличие, кстати, позволяет задавать число ядер в UI-настройках в Windows и не позволяет в MacOS.
Windows-Пользователь может самостоятельно выполнить любой бенчмарк и любой тест, введя команду выше в терминал. Номера тестов из бенчмарка CPU доступны следующие:
0 - Integer Math
1 - Floating Point Math
2 - Prime Numbers
3 - Extended Instructions Set (через перемножение матриц)
4 - Compression
5 - Encryption
6 - String Sorting
9 - Все тесты выше, но в 1 поток CPU
Таким образом механизм работы любого теста PassMark сводится к следующему алгоритму:
Запуск N процессов, где N - число ядер CPU.
Ожидание завершения всех N процессов.
Суммирование числовых результатов от всех N процессов.
Каждый числовой результат процесса в среднем равен суммарному результату / N, но это не всегда так, о чем мы еще поговорим в конце.
Суммарный результат - это и есть то, что PassMark отображает в своей публичной базе по каждому устройству.
Алгоритм работы бенчмарков
Чтобы посмотреть, как устроены алгоритмы бенчмарков, нужно загрузить исполняемый файл PassMark в любой удобный дизассемблер.
Все бенчмарки внутри PassMark, вне зависимости от платформы, организованы примерно следующим образом: по номеру теста запускается функция с кодом конкретного теста.
Дизассемблированный код запуска тестов PassMark:

Каждый тест в свою очередь организован схожим образом:
Запускается цикл длительностью в заданное количество миллисекунд (по умолчанию 6000)
На каждой итерации производится некоторое число вычислительных операций (полезная нагрузка)
-
После завершения цикла вычисляется результат работы на 1 ядро (поток) по следующей формуле:
<результат на 1 ядро> = <суммарное количество выполненных вычислительных операций> / <длительность выполнения в милисекундах>
Таким образом, все результаты тестов на скриншоте ниже - это ничто иное, как количество вычислительных операций определенного типа (в зависимости от бенчмарка) в микросекунду (не в миллисекундах) с заданного числа ядер процессора (по умолчанию - всех ядер).

Воспроизведение кода тестов
Приступаем к самому интересному. Воспроизводить тесты лучше всего на низкоуровневом языке программирования без виртуальной машины, чтобы сократить вычислительные затраты на трансляцию кода из IL в машинный - что снизит итоговый результат тестов. Далее мы еще сравним результаты тестов, реализованных на C# (с IL), а пока остановимся на C++ (без IL).
Возьмем пару наиболее примечательных тестов со скриншота выше - IntegerMathTest и FloatingPointMathTest.
Код теста IntegerMathTest (С++): здесь
Код теста FloatingPointMathTest (С++): здесь
Код был восстановлен на основе анализа PassMark под Windows и MacOS. Оба теста по структуре кода очень похожи, и их универсальный алгоритм выглядит так:
Заполнить буфер случайными числами, чтобы от итерации к итерации результаты вычислений не кэшировались внутри CPU
-
Запустить цикл на 6 секунд, на каждой итерации которого:
Совершить N 32-битных операций
Совершить M 64-битных операций
Увеличить счетчик совершенных операций на N+M, где N и M - это число операций, заложенные разработчиками PassMark в рамках одной итерации.
Посчитать число операций в микросекунду (по формуле выше)
Здесь есть несколько замечаний, которые могут быть интересны всем, кто интересуется сравнимостью оценки между различными устройствами:
Разработчики PassMark учли, что кэш процессора "срежет" реальные вычисления, что приведет к недостоверным результатам. Чтобы обойти это, на каждой итерации цикла их код избыточно обращается к оперативной памяти (буферу чисел), что при большом количестве итераций (а их много!) приведет к несколько заниженным результатам теста. У разных устройств разная скорость обращения к ОЗУ.
Подсчет операций производится слишком усредненно: смешиваются в одну кучу 32- и 64-битные операции сложения, вычитания, умножения и деления, хотя на уровне языка ассемблера эти операции, конечно же, не равнозначны - в идеале их нужно суммировать с коэффициентом друг относительно друга. Процессоры разных устройств могут быть оптимизированы под операции определенного типа.
Сравнение результатов
Восстановленный код работает в один поток (на одном ядре), а PassMark запускает этот же код у себя в количестве ядер процессора, поэтому для сравнения результатов необходимо либо заставить PassMark запускаться в одноядерном режиме, либо наш код - в количестве ядер процессора. Первый вариант выглядит более привлекательно - это не будет создавать избыточную нагрузку.
Так как интерфейс PassMark отличается по набору функций между платформами (об этом выше), на каждой платформе придется искать свой метод запуска на 1 ядре. В Windows, например, можно просто задать число потоков (процессов, ядер) в настройках интерфейса PassMark. В MacOS придется "обманывать" PassMark грязными способами - например, отключая ядра процессора из терминала:
// отключить все, кроме одного главного ядра
for I in `seq 0 48`; do sudo cpuctl offline $I; done;
// включить все ядра обратно
for I in seq 0 48; do sudo cpuctl online $I; done;
На других платформах придется искать что-то свое. Но скорее всего, метод для MacOS будет работать везде, где получится найти альтернативу команде cpuctl.
Добившись запуска на одном ядре, мы увидим примерно одинаковые результаты бенчмарков:

Результаты тестов восстановленного кода на C++ сошлись с результатами PassMark на том же PC практически идеально. Но чтобы достичь этого недостаточно просто закинуть код C++ в любую IDE и скомпилировать. Когда совершаются миллиарды итераций, каждая дополнительная операция в цикле и "телодвижение" компилятора может стать "эффектом бабочки" на пути к общему результату.
Эксперименты с кодом бенчмарков и особенности работы современных компиляторов
Как известно, код, написанный на C++ компилируется в язык ассемблера и имеет, соответственно, не меньше различных "машинных" представлений, чем существует различных архитектур процессоров (языков ассемблера). На практике производительность скомпилированного ассемблерного код зависит от еще большего числа признаков.
1. Компилятор
Разные компиляторы производят различный машинный код из-за различий алгоритмов построения AST-дерева.
2. Опции компилятора
Современные IDE позволяют варьировать тип сборки(debug/release). Debug-сборка отключает любые оптимизации компилятора для более удобной отладки, в то время как release-сборка включает самые важные оптимизации, но далеко не все возможные. Из-за задействованных оптимизаций компилятора производительность одного и того же C++ кода бенчмарка может отличаться в 3-4 раза!
Разные IDE имеют различные настройки оптимизации по умолчанию: в Visual Studio release режим имеет по умолчанию второй уровень оптимизации (-O2), а IDE CLion - третий (-O3), из-за чего следующий код бенчмарка FloatingPointMathTest необходим для CLion, но необязателен для Visual Studio:
...
// добавлено(!): бессмысленная проверка r1 и r2, чтобы компилятор не срезал полезные вычисления в ходе оптимизации
if(r1 == 0 && r2 == 0){
break;
}
...Этот код обязывает оптимизатор компилятора CLion производить вычисления r1 и r2 на каждой итерации цикла. Если же этот блок убрать, в ассемблерном коде вычисление r1 и r2 произойдет только на последней итерации, а на каждой итерации будут просчитываться только переменные v7 .. v11 для последней итерации, напрочь срезав все полезные вычисления, оценивающие производительность CPU. Нельзя не отметить, что этот дополнительный код снижает производительность теста.
Следующий же код уже необходим для любого уровня оптимизации >= -O2 (-O2, -O3, и т.д):
...
// выводим все значения, чтобы компилятор не срезал вычисления в ходе оптимизации
std::cout << "IntegerMath Test: " << result << " | "
<< v11 + v17 + v4 + v10 + v12 + v13 + v18 +
v15 + v16 + v14 + v8 + v9 + v31 + i << std::endl;
...Так как если вычисляются переменные, которые никак не используются, компилятор их выбрасывает в ходе оптимизации.
Вероятнее всего PassMark был скомпилирован с опцией оптимизации -O2, что было подтверждено эмпирически, и в результате чего результаты тестов сошлись с восстановленным кодом.
3. Структура кода
Каждая избыточная операция в восстановленном коде (любое дополнительное условие, обращение к памяти, математическая процедура) нарушает результаты тестов. Разработчики PassMark уже "поигрались" с кодом своих бенчмарков за нас и сумели организовать структуру кода наиболее оптимально. Рассмотрим несколько показательных фрагментов.
В IntegerMathTest алгоритм подсчета индекса буфера организован таким образом:
mem_index = (mem_index + 6) % (randomBufferSize - 6);А в FloatingPointMathTest следующим образом:
v8 = v6 + 1;
v6 = v8 + 1;
...
if (v6 >= 20000) {
v6 = 0;
}Если в FloatingPointMathTest сделать так же, как в IntegerMathTest, производительность падает на 3-5%. А если в IntegerMathTest так же, как в FloatingPointMathTest - производительность не меняется.
Другой пример - уродливые реверсивные (убывающий счетчик) циклы в IntegerMathTest:
do {} while (v19 > 0);
...
for (; v20 > 0; --v20) {}
...
do {} while (v22 > 0);
...
for (int j = mulDivOpsCount; j > 0; --j) {Если сделать данные циклы с возрастающим счетчиком (Например, for (int j = 0; j<mulDivOpsCount; j++)), то производительность скомпилированного кода при прочих равных обрушится на 15%!
Кстати говоря, то, что проход цикла в обратном направлении может значительно увеличивать производительность, известно уже давно (и разработчикам PassMark, очевидно, тоже). Еще в далеком 2014 году этот прием разбирался в этой статье для языка Javascript - каким бы высокоуровневым ни был язык, а простые операции вроде условий и циклов все равно транслируются в примерно одинаковый машинный код.
Сравнение производительности языков программирования с помощью бенчмарков
Имея "на руках" восстановленный код тестов PassMark, мы можем использовать его для любых своих неординарных нужд - например, для сравнения производительности языков программирования.
Возьмем C#, в качестве си-подобного языка с наличием IL, и оценим, насколько в нем операции с целыми и дробными числами медленнее, чем в нативном C++.
Прогресс преподносит много приятных подарков, недоступных еще пару лет назад, а потому для "перевода" C++ в C# больше не нужно думать - достаточно попросить это сделать за нас ChatGPT, который справляется с подобными задачами превосходно.
Переписав код из С++
Отдаем в ChatGPT восстановленный С++ код, на выходе получаем C# код, компилируем его в release-режиме и смотрим результаты:

Прогнав тест 10 раз, получаем усредненный результат, который показал, что C# (язык с IL) на 6-8% менее производителен по сравнению с C++ (язык без IL) с точки зрения числовых операций. Из-за этого отличия и был изначально выбран C++ для воспроизведения кода бенчмарков.
PassMark: Резюме
До начала исследования PassMark было несколько иное представление об организации его кода: так как код тестов должен быть одинаковым вне зависимости от платформы (для сравнимости результатов по публичной базе), казалось бы, наиболее правильный способ организации кода - обособление в динамически подключаемые библиотеки (.dll, .so), которые существуют во всех поддерживаемых PassMark-ом платформах. Однако разработчики предпочли под каждую платформу выпускать продукт "с нуля", делая ручной копипаст кода тестов в платформо-зависмый вариант программы. Это приводит к тому, что для каждого теста необходимо проводить отдельный аудит на каждой платформе, чтобы убедиться, что он действительно везде работает одинаково.
В этой статье аудит был сделан для двух ключевых тестов CPU - IntegerMathTest и FloatingPointMathTest на платформах Windows и MacOS - по его результатам можно в целом предположить, что внутри одинаковых бенчмарков на разных платформах находится одинаковый код, не затронутый оптимизатором конкретного компилятора и спецификой платформенного ассемблера.
И отдельного внимания заслуживают публичные результаты тестов PassMark. Как уже было упомянуто выше, результат любого бенчмарка - это просто сумма операций/мкс со всех запущенных подпроцессов в количестве ядер процессора. Но что, если запустить процессов больше, чем ядер у процессора?
Возьмем для примера результаты тестов PassMark на 1, 24, 48 и 64 потока для экспериментального 24-ядерного Core I9-13950Hx, которые уже частично демонстрировались ранее:

С их помощью можно увидеть несколько интересных моментов работы PassMark и современных процессоров:
Результаты на 24 ядра не равны результатам на 1 ядро, умноженным на 24. Это происходит из-за того, что ядра современных процессоров не идентичны по производительности - ядра делятся на performance и efficient.
Операции с дробными числами в 1 поток могут быть быстрее операций с целыми числами в 1 поток на некоторых процессорах. Наиболее вероятное объяснение этому - строение performance ядер конкретного процессора.
Если запустить потоков больше, чем ядер процессора, результаты тестов увеличатся на 10-25%, что таким образом покажет настоящую производительность процессора под 100% нагрузкой, и она не будет соответствовать той, что можно увидеть в публичной базе данных PassMark! Публичная база PassMark собирается с устройств по всему миру со стандартными настройками программы PassMark.
Если запустить еще больше потоков, результаты особо не улучшатся, что свидетельствует о полной загрузке процессора.
Таким образом можно резюмировать, что разработчики PassMark изрядно постарались создать универсальную оценку производительности различных устройств по всему миру. Но в реальности же устройства могут быть на 10-25% мощнее усредненной публичной оценки, а заложенный в основу тестов алгоритм "загрязнен" побочными операциями, еще более занижающими реальную оценку.
В любом случае, имея на руках алгоритм интересующего бенчмарка PassMark и публичную базу результатов с миллионами устройств по всему миру, можно проводить довольно интересные исследования:
Сколько целочисленных операций на C# в среде Mono из Unity сможет выполнить iPhone 14 Pro Max? А на сколько больше, если переписать код на C++? Стоит ли оно того?
Какой лучше выбрать язык для разработки серверного приложения с большим числом операций с плавающей точкой на базе процессора Xeon Bronze 3204: Python или Javascript
И на все другие подобные вопросы можно будет получить ответ путем нехитрых манипуляций с результатами тестов из разных языков программирования и устройств.