

Real-Time-рекомендательные системы — сложный с точки зрения реализации и поддержания продукт. Его разработка требует тщательной проработки архитектуры и этапов, качественной работы с данными и обеспечения возможности масштабирования решения. Причём большинство подобных задач приходится решать уже в процессе, с учётом реалий и возникающих подводных камней.
Привет, Хабр. Я Антон Шишкин, ведущий архитектор проектов компании «СКБ ЛАБ». Мы занимаемся финтех-проектами и специализируемся в том числе на решениях на основе машинного обучения. В этой статье я расскажу о нашем опыте разработки Real-Time-рекомендательной системы для мобильного банкинга: с чего начинали, что учитывали, с какими подводными камнями столкнулись и что получили в итоге.
Статья подготовлена по мотивам моего доклада на вебинаре «Архитектура Real-Time-рекомендательной системы на примере банка: с нуля до готового продукта».
Этап 0: постановка задачи
Мы в «СКБ ЛАБ» занимаемся финтех-проектами разного профиля и масштаба — от кор-систем банка до чат-ботов. В числе наших специализаций интеграционные решения и решения на базе машинного обучения.
Одним из наших клиентов был небольшой банк, которому мы помогали с запуском дистанционного обслуживания, то есть мобильного банка. После успешного релиза продукта мы получили запрос от банка на разработку рекомендательной системы для автоматического подбора релевантного дополнительного банковского продукта. Причём поскольку основной онлайн-банк был запущен не так давно, рекомендательную систему надо было построить быстро и при минимуме данных. Начали с MVP.
MVP рекомендательной системы
Основная задача продукта на этапе MVP была одна — подбирать клиентам дополнительные, но обязательно релевантные им банковские продукты. Например, долгосрочные вклады, инвестиции и другие. Мы планировали рассчитывать рекомендации дополнительного продукта на основе:
- данных от клиента — например, дата рождения директора компании;
- данных из открытых источников — например, ЕГРЮЛ, ЕГРИП;
- данных на основе «жизни» клиента в онлайн-банкинге — например, транзакционные данные, данные о заявках;
- контекстной информации — например, месяц года, который важен, если речь идёт о бизнесе, связанном с сезонными товарами и услугами.
Мы хотели извлекать из этих сырых данных полезные признаки и на их основе рассчитывать рекомендации дополнительного продукта.
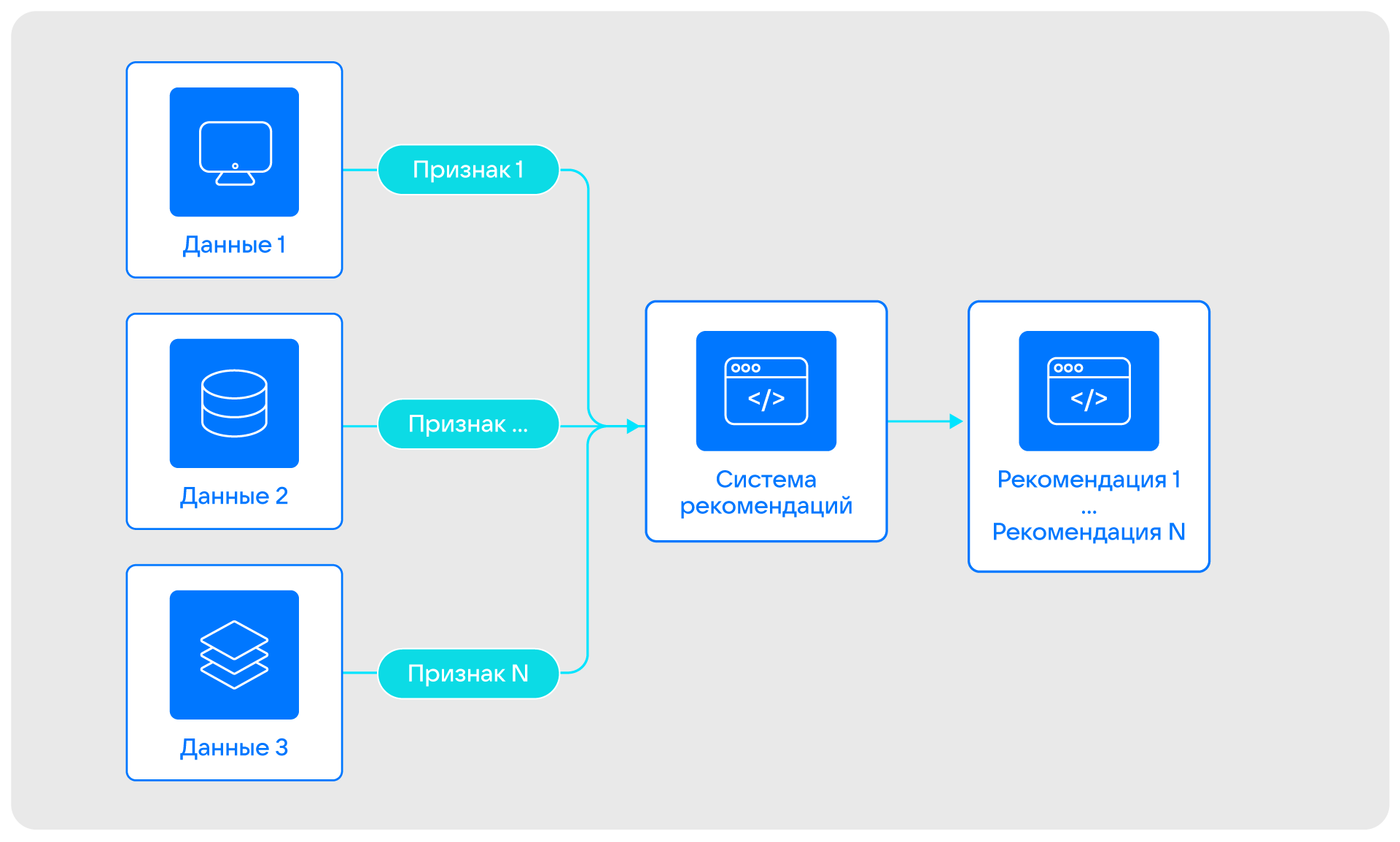
Основным источником информации по клиентам на этапе MVP была автоматизированная банковская система (АБС). Также мы сразу определили, что будем выводить рекомендации в одну точку контакта с клиентом — в дистанционное банковское обслуживание (ДБО), то есть онлайн-банкинг. Для взаимодействия АБС и ДБО мы добавили в архитектуру проекта корпоративную шину.

В самом начале мы выработали некоторые требования к MVP продукта:
- Минимальное влияние на основные процессы. Было важно не сломать то, что работает и приносит пользу.
- Рекомендовать без фейлов. Мы хотели исключить ситуации, когда в рекомендации попадают продукты, на которые клиент уже подал заявку или которые он не может оформить по разным причинам.
- Время ответа — 0,5 секунды. В онлайн-банкинге важно взаимодействие с клиентом здесь и сейчас. Он может выйти из приложения в любой момент, поэтому надо успеть показать ему рекомендацию.
Реализация MVP
Основной сложностью на этапе MVP для нас стал недостаток данных для построения портретов по каждому банковскому продукту: мы не могли провести аналитику и вывести общие паттерны для построения ML-модели, поскольку банк не успел накопить нужные массивы данных. Чтобы компенсировать этот «пробел в знаниях» и стартовать разработку MVP до того, как на стороне банка накопится большая история пользовательских запросов, мы решили прибегнуть к работе с экспертными моделями.
Мы попросили у банка базовую информацию по каждому продукту и представление о потенциальных клиентах. Например, мы узнали, что депозит лучше предлагать человеку, который является клиентом банка несколько месяцев и обязательно имеет неснижаемый остаток на счёте в течение определённого периода. Получив такие конкретные признаки для каждого продукта, мы смогли использовать математические подходы на основе векторов для определения, насколько клиент близок к продукту, если представлять их в одном векторном пространстве.
Далее мы начали делать систему рекомендаций с учётом этих экспертных моделей на основе автоматизированной банковской системы, построенной на Oracle. В ней не было готовых библиотек для математических расчётов, поэтому все расчеты векторных расстояний мы выполняли самостоятельно. В источнике:
- хранились сырые данные;
- извлекались полезные признаки;
- рассчитывались и отдавались рекомендации по запросу от онлайн-банкинга.
Поскольку все расчеты мы выполняли в источнике, мы смогли быстро выполнять операции без дополнительных инфраструктурных задач — не надо ничего нового разворачивать, ведь источник данных, корпоративная шина и онлайн-банкинг уже есть в проде.
Такой реализации оказалось достаточно для выкатки MVP и накопления данных для создания ML-моделей. Расчёт рекомендаций по всем клиентам мы выполняли один раз в сутки, на это уходило около часа. Мы выбрали время, когда АБС нагружена меньше всего. Таким образом мы накапливали некоторый пул предварительно посчитанных рекомендаций, которые могли быстро отдавать в онлайн-банкинг. И перед отправкой мы дополнительно проверяли рекомендации на наличие фейлов. Например, как только оформлялась заявка на продукт, мы сразу исключали его из списка рекомендаций.
На этапе подготовки MVP мы поняли, что могут часто меняться экспертные модели и появляться новые продукты, по которым надо также реализовывать эти экспертные модели. В итоге решили добавить возможность настройки экспертной модели — сами модели не были добавлены прямо в код.

От MVP к продакшен-версии
На этапе MVP мы выделяли для себя три основных недостатка:
- Рекомендации вычислялись на устаревших данных. Поскольку расчёт мы делали раз в день, рекомендации получались «на вчера» — гарантировать полное отсутствие факапов мы не могли.
- У автоматизированной банковской системы есть свой жизненный цикл и регламентные окна. Соответственно, мы не могли обрабатывать запросы на список рекомендаций в режиме 24/7.
- Даже при обращении к АБС один раз в день мы влияли на её работу задачами, для которых она не предусмотрена.
При переходе от MVP нам было важно избавиться от этих недостатков.
Пока мы запускали прототип и проверяли его работоспособность, банк успел накопить достаточное количество данных по продуктам. Это позволило нам перейти от экспертных к полноценным ML-моделям, то есть автоматизировать формирование портрета клиента по каждому продукту.
Мы обучили несколько моделей машинного обучения на основе XGBoost и обернули их в микросервис, в который перенесли расчёт рекомендаций по банковским продуктам.

Чтобы покрыть остальные недостатки MVP, нам надо было как минимум обеспечить расчёт рекомендаций в режиме онлайн. Для этого нужно было развернуть хранилище актуальных признаков и вынести всё, кроме сырых данных, из основного источника.

Когда мы искали инструмент для развёртывания хранилища, нам было важно, чтобы решение позволяло:
- создавать и удалять признаки извне;
- получать признаки для расчётов рекомендаций;
- работать в фоне с признаками внутри;
- масштабироваться с минимальным влиянием;
- работать в фоне с признаками изнутри.
Поскольку мы понимали, что объём обрабатываемых транзакционных и других пользовательских данных будет увеличиваться, а точек контакта с клиентами станет больше, при поиске был важен каждый критерий.
Мы рассматривали несколько вариантов, в том числе:
- Oracle;
- Memcached;
- CouchBase;
- Redis;
- Tarantool;
- Oracle с таблицей в памяти.
Oracle нам не подошёл из-за проблем, связанных с перестроением индекса при частом удалении записей: мы сталкивались с этим на другом проекте и понимали, что от решения лучше отказаться.
При рассмотрении Memcached, CouchBase, Redis и Tarantool мы нашли исследование, которое показало, что Tarantool превосходит конкурентов по скорости на запись и чтение. Оставалось только сравнить Tarantool и Oracle с таблицей в памяти. Для этого мы собрали стенд и прогнали тесты с учетом наших критериев. Tarantool оказался лучше и в этом случае.
Кроме соответствия критериям, Tarantool понравился нам и тем, что:
- в нём есть файберы для фоновых процессов;
- это Open-Source-продукт с большим комьюнити;
- есть удобный модуль для шардирования vshard.
Итоговое решение
После выбора стека мы смогли сделать полноценное решение. При этом мы сразу решили, что будем:
- делать хранилище, которое адаптировано под наши потребности, нашу функциональность;
- использовать асинхронную запись журнала WAL и асинхронную репликацию;
- обеспечивать RPO близким к нулю на прикладном уровне.

В итоге мы получили следующую реализацию.
Извлечение признаков

У нас есть несколько сценариев извлечения признаков в зависимости от источника данных или событий. С клиентскими данными мы действуем по принципу обновления: нам достаточно прогнать заново сырые данные по клиенту через экстракторы признаков, удалить старые признаки из хранилища и положить новые.
С транзакционными данными подход другой. Если поступает новая информация, мы извлекаем признаки и просто их складываем. Если приходит запрос на удаление транзакции, операция выполняется без извлечения признаков: запрос прилетает от менеджера напрямую в хранилище признаков.
При этом мы обеспечиваем RPO близким к нулю. Для этого в нашей архитектуре предусмотрен отдельный модуль, который необходим для повторного проигрывания сырых данных. Например, в случае аварии и после её устранения он прогоняет сырые данные, поступившие во время сбоя, через извлечение признаков и заменяет старые признаки новыми. Таким образом мы закрываем возможные дыры в данных.
Расчёт рекомендаций

Первый компонент на этапе расчёта — менеджер рекомендаций. Он:
- принимает запрос по клиенту;
- получает признаки клиента;
- рассылает запросы на расчёт в отдельные микросервисы по каждому банковскому продукту.
Далее менеджер получает рассчитанные рекомендации, отдаёт их в блок принятия итогового решения, получает ответ и отдаёт его в точку контакта с клиентом.
Также в этом блоке есть микросервис на основе ALS и настраиваемые рекомендации — мы оставили возможность ручной настройки рекомендаций. Здесь же мы применили Tarantool в качестве кэша.
Хранение актуальных признаков

Мы реализовали шардированное хранилище. У нас несколько роутеров и несколько шардов, каждый из которых состоит из мастера и двух реплик. Для экстрактора и расчёта рекомендаций мы реализовали Rest API — универсальный интерфейс с расширенной поддержкой. С его помощью можно:
- записать признаки по новым транзакциям;
- записать или удалить признаки по клиентским данным;
- получить признаки по субъекту (с агрегацией или без);
- запросить расчёт рекомендаций: получить признаки по клиенту, получить матрицу для ALS.
Структурно хранение организовано так: в основе один спейс, каждая запись которого — плоский признак. При этом каждая запись содержит:
- value — значение признака;
- subject — клиент банка;
- time_use — время жизни признака. Оно учитывается, например, при определении суммы платежей за отдельный период;
- subject + time_use — составной индекс. Используется, когда надо выбрать все признаки по субъекту и отсортировать их по time_use;
- object — то, из чего извлекается признак, например из ID платежа;
- bucket_id — компонент, необходимый для шардирования, который рассчитывается на основе субъекта.

При выборе структуры хранения мы исходили из того, что сложно будет схлопывать признаки в реальном времени, когда прилетает запрос на рекомендацию, либо предварительно их рассчитывать и хранить посчитанные агрегаты. Поэтому мы остановились на варианте простого хранилища с плоским хранением. При этом схлопываем не предварительно, а в реальном времени по запросу — Tarantool предоставляет такую возможность.
Подводные камни при реализации
При подготовке реализации и после её выкатки в эксплуатацию мы столкнулись с несколькими подводными камнями:
-
Первичный индекс мешает масштабированию vs Primary index. У нас Primary index в каждом шарде берётся из Sequence, то есть из последовательности. При добавлении нового шарда данные в него поступали из разных шардов. Причём часть записей поступала с одинаковым Primary index, из-за чего сохранялся только первый экземпляр. Для решения этой проблемы мы добавили новое поле, в которое записываем Replica set ID. Теперь у нас составной Primary index (Sequence + Replica set ID), что исключает пересечения.
-
«Жирные» клиенты. Мы столкнулись с тем, что у некоторых клиентов может быть много признаков. Например, у нас по ошибке таким стал банк — изначально его признаки попадали в хранилище. В итоге мы получали нетипичное увеличение шарда по памяти и критичные скачки по Lua-памяти при удалении признаков транзакций. Устранить проблему помог отказ от сохранения признаков по банку.
-
Переполнение Lua-памяти. В начале разработки на Lua из-за недостатка опыта мы «переусложняли» циклы, в том числе использовали промежуточные переменные. Это приводило к переполнению Lua-памяти. После консультаций с командой Tarantool мы переписали простые циклы на использование Lua Fun, и проблема была решена.
Итоги и перспективы нашего проекта

Сейчас наше решение качественно работает в проде, выдерживая около 4 тысяч запросов на запись и чтение в секунду, а также до 40 тысяч изменений в хранилище в секунду. Хранилище в текущей реализации достаточно небольшое по объёму: три шарда, каждая реплика по 8 ГБ. Это связано с тем, что мы используем его исключительно для актуальных данных, а неактуальные оперативно удаляем.
Мы обеспечили возможность гибкого и бесшовного масштабирования Real-Time-рекомендательной системы — при необходимости мы можем:
- добавить новые источники данных;
- добавить новые шарды хранилища;
- подключить дополнительные роутеры для обработки большего количества запросов;
- доработать REST API для взаимодействия по бинарному протоколу.
Примечательно, что мы стартовали, когда часть ИТ-компонентов уже была в проде, поэтому при реализации новой архитектуры ключевую роль сыграл Tarantool, интеграция которого позволила нам закрыть недостающую функциональность.