
Библиотека pandas 2.0 вышла в начале апреля, в ней появилось много улучшений нового режима Copy‑on‑Write (CoW, копирование при записи). Ожидается, что в pandas 3.0 режим CoW будет использоваться по умолчанию. Сейчас полный переход на копирование при записи запланирован на апрель 2024 года. У разработчиков библиотеки нет планов поддержки некоего «режима совместимости» или режима, в котором CoW не применяется.

Эта серия публикаций посвящена рассказу о том, как работают внутренние механизмы CoW в pandas. Она призвана помочь пользователям библиотеки понять, что происходит при выполнении кода, узнать о том, как эффективно пользоваться копированием при записи, и о том, как адаптировать свой код под новые возможности pandas. Здесь будут приведены примеры того, как использовать данный механизм для того чтобы добиться от системы самого высокого уровня производительности. Здесь же будет рассмотрено и несколько антипаттернов, использование которых в программах ведёт к появлению в них ненужных «узких мест». Пару месяцев назад я написал небольшой вводный материал по Copy‑on‑Write в pandas.
У меня, кроме того, есть заметка, посвящённая структурам данных pandas, которая поможет вам разобраться с некоторыми идеями, необходимыми для понимания того, как работает CoW.
Я вхожу в основную команду разработчиков pandas и до настоящего времени принимаю активное участие в реализации и улучшении CoW. Я занимаюсь опенсорсными разработками в Coiled, где работаю над библиотекой Dask. В частности, в мои обязанности входит интеграция pandas и этой библиотеки, а так же — обеспечение того, чтобы эта библиотека была бы совместима с Pandas.
Как режим CoW меняет поведение pandas
Многие из вас уже, возможно, знакомы со следующими нюансами pandas:
import pandas as pd
df = pd.DataFrame({"student_id": [1, 2, 3], "grade": ["A", "C", "D"]})Выберем столбец grade и перезапишем то, что находится в его первой строке, поместив туда "E".
grades = df["grade"]
grades.iloc[0] = "E"
df
student_id grade
0 1 E
1 2 C
2 3 DКак ни печально, но в ходе выполнения этой операции изменения будут внесены не только в grades, но и в df. Это вполне может привести к появлению ошибок, которые сложно будет найти. CoW сделает невозможным такое поведение программы и обеспечит то, что в подобной ситуации изменения будут внесены только в grades. Мы, кроме того, видим при выполнении этой операции ложноположительное предупреждение SettingWithCopyWarning, от которого тут нет никакой пользы.
Рассмотрим теперь пример ChainedIndexing (цепное индексирование), код которого не выполняет никаких действий:
df[df["student_id"] > 2]["grades"] = "F"
df
student_id grade
0 1 A
1 2 C
2 3 DНам снова выдаётся предупреждение SettingWithCopyWarning, но в этом примере с df ничего не происходит. Все эти странности сводятся к правилам работы с копиями (copy) и срезами (view) данных в библиотеке NumPy, которая используется во внутренних механизмах pandas. Пользователи pandas должны быть осведомлены об этих правилах и о том, как они применяются к объектам DataFrame pandas. Это позволяет понять то, почему похожие комбинации команд дают разные результаты.
CoW устраняет все эти разночтения. Когда включён режим CoW, пользователь может вносить изменения лишь в один объект за один раз. То есть — при использовании CoW в нашем первом примере датафрейм df не изменится, так как изменения будут внесены лишь в grades. А во втором примере, который до этого не выполнял никаких действий, будет вызвано исключение ChainedAssignmentError. Смысл тут в том, что с использованием CoW нельзя будет обновлять состояние двух объектов одновременно. Например, это может выразиться в том, что в примерах, подобных нашим, одни объекты будут вести себя так, как будто они являются копиями других объектов.
Существует и множество других ситуаций, в которых проявляется подобное поведение, но тут мы не стремимся к тому, чтобы разобрать все такие ситуации.
Как работает копирование при записи
Подробнее разберём особенности работы CoW и обратим внимание на некоторые факты об этой технологии, которые полезно знать. Это — основная часть данного материала, она носит технический характер.
CoW обеспечивает то, что любой объект DataFrame или Series, полученный любым способом из другого объекта, всегда ведёт себя как копия исходных данных. Это означает, что с помощью одной операции невозможно модифицировать больше одного объекта. Например, в нашем первом примере это означает, что модифицирован будет лишь объект grades.
Весьма агрессивным подходом для обеспечения такого поведения системы могло бы быть защитное копирование DataFrame и его данных при выполнении каждой операции, что позволило бы полностью уйти от работы со срезами в pandas. Это гарантировало бы соблюдение принципов CoW, но при этом привело бы к огромным потерям производительности, поэтому такой подход нежизнеспособен.
Теперь мы поговорим о механизме, который обеспечивает то, что состояние двух объектов не обновляется одной операцией, и то, что наши данные, без необходимости, не подвергаются копированию. Второе свойство этого механизма — это как раз то, что делает реализацию CoW интересной темой.
Нам, чтобы выполнять только те операции копирования, которые абсолютно необходимы, нужно точно знать о том, когда инициировать такие операции. Нужда в копировании может возникнуть только тогда, когда пытаются изменить значения одного из объектов pandas, не копируя его данные. Копирование необходимо выполнять только в том случае, если данные этого объекта совместно с ним использует и другой объект pandas. Это значит, что нужно следить за тем, ссылаются ли на один и тот же массив NumPy два объекта DataFrame (в общем случае нам надо знать о том, ссылаются ли на один массив NumPy два любых объекта pandas, но я, ради простоты, буду пользоваться термином «DataFrame»).
df = pd.DataFrame({"student_id": [1, 2, 3], "grade": [1, 2, 3]})
df2 = df[:]В этом коде создаётся объект df и срез этого объекта — df2. То, что это срез, говорит нам о том, что оба датафрейма основаны на одном и том же массиве NumPy. Если рассмотреть эту ситуацию с точки зрения CoW, то окажется, что df должен знать о том, что на его массив NumPy ссылается и df2. Правда, одного этого недостаточно. Датафрейм df2 тоже должен знать о том, что на массив NumPy, который он считает своим, ссылается df. Если оба объекта знают о том, что есть другой объект DataFrame, ссылающийся на «их» массив NumPy, можно инициировать операцию копирования данных в том случае, если один из этих объектов будет модифицирован. Например:
df.iloc[0, 0] = 100Тут выполняется непосредственная модификация df. Датафрейм df знает о том, что существует другой объект, который ссылается на те же данные, и поэтому он, например, может инициировать копирование этих данных. Он не знает о том, какой именно объект ссылается на эти данные — только о том, что существует такой объект.
Взглянем на то, как можно добиться такого поведения системы. Мы создали внутренний класс BlockValuesRefs, который используется для хранения этой информации. Он содержит записи обо всех объектах DataFrame, которые ссылаются на некий массив NumPy.
Есть три типа операций, в ходе выполнения которых может быть создан объект DataFrame:
Объект
DataFrameсоздаётся на основе внешних данных. Например — посредством команды видаpd.DataFrame(...)или с использованием любого метода ввода/вывода.Новый объект
DataFrameсоздаётся посредством операции pandas, которая вызывает копирование неких исходных данных. Например — практически все случаи использования командыdropnaприводят к созданию копии данных.Новый DataFrame создаётся при выполнении операции pandas, которая не вызывает копирование исходных данных. Например — наподобие
df2 = df.reset_index().
В первых двух случаях всё просто. Когда создаётся DataFrame — массив NumPy, который лежит в его основе, подключён к новому объекту BlockValuesRefs. Ссылки на подобные массивы есть лишь у новых объектов, поэтому нам не нужно следить за какими-то другими объектами. Новый объект создаёт ссылку weakref (слабую ссылку), хранящуюся у него внутри, которая указывает на объект Block, являющийся обёрткой для массива NumPy. Концепция объектов Block разъясняется здесь.
Использование weakref позволяет создать ссылку на любой Python-объект. Наличие такой ссылки не приводит к сохранению этого объекта в том случае, когда он естественным образом выходит из области видимости соответствующего кода.
import weakref
class Dummy:
def __init__(self, a):
self.a = a
In[1]: obj = Dummy(1)
In[2]: ref = weakref.ref(obj)
In[3]: ref()
Out[3]: <__main__.Dummy object at 0x108187d60>
In[4]: obj = Dummy(2)В этом примере создаётся объект Dummy и слабая ссылка на этот объект. После этого той же самой переменной присваивается другой объект. То есть — исходный объект уходит из области видимости, память, занимаемую им, освобождает сборщик мусора. Наличие слабой ссылки не влияет на этот процесс. Если разрешить слабую ссылку — она будет указывать на None, а не на исходный объект.
In[5]: ref()
Out[5]: NoneЭто позволяет обеспечить такое поведение системы, когда массивы, к которым может быть применена сборка мусора, подвергаются ей, а не удерживаются в рабочем состоянии.
Посмотрим на то, как организованы эти объекты (это и следующие изображения подготовлены автором материала):
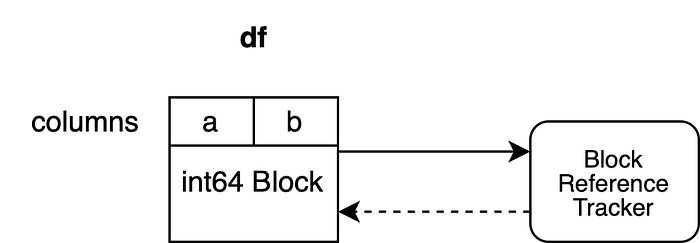
В нашем примере есть датафрейм с двумя столбцами — «a» и «b», dtype и первого, и второго — «int64». Их базой является один объект Block, хранящий данные для обоих столбцов. Этот объект хранит жёсткую ссылку на объект, обеспечивающий наблюдение за ссылками, благодаря чему этот объект будет существовать до тех пор, пока сборщик мусора не уничтожит объект Block. Объект для наблюдения за ссылками хранит слабую ссылку на Block. Это позволяет наблюдать за жизненным циклом объекта Block, но не мешает сборщику мусора уничтожить Block. Объект для наблюдения за ссылками пока не хранит слабых ссылок на какие‑нибудь другие объекты Block.
Так выглядят самые простые сценарии развития событий. Мы знаем о том, что тот же массив NumPy не используется никакими другими объектами pandas. Поэтому можно просто создать новый объект для наблюдения за ссылками.
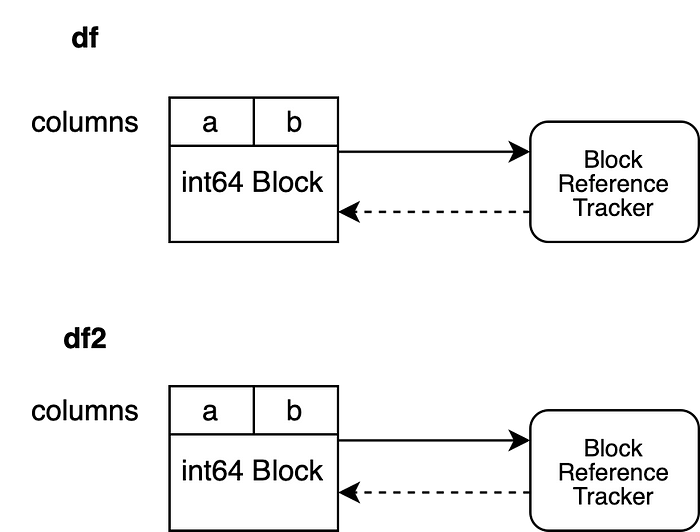
А вот третий сценарий уже выглядит сложнее. Новый объект видит те же данные, что и исходный объект. Это означает, что оба объекта имеют ссылки на одни и те же области памяти. Наша операция создаёт новый объект Block, который ссылается на тот же массив NumPy. Это называется «поверхностной копией» (shallow copy). Теперь надо зарегистрировать этот новый объект Block в нашем механизме наблюдения за ссылками. В ходе регистрации мы воспользуемся тем же объектом для наблюдения за ссылками, который подключён к старому объекту.
df2 = df.reset_index(drop=True)
Теперь объект для наблюдения за ссылками, BlockValuesRefs, ссылается на объект Block, который является основой исходного датафрейма df, и на объект Block, являющийся основой df2. Это обеспечивает нашу осведомлённость обо всех объектах DataFrame, в основе которых лежат одни и те же участки памяти.
Теперь мы можем спросить у объекта для наблюдения за ссылками о том, сколько имеется работоспособных объектов Block, ссылающихся на один и тот же массив NumPy. Объект для наблюдения за ссылками проверяет слабые ссылки и сообщает нам о том, что на одни и те же данные ссылается более одного объекта. Это даёт нам возможность самостоятельно инициировать операцию копирования в том случае, если выполнена непосредственная модификация одного из них.
df2.iloc[0, 0] = 100Объект Block, используемый в df2, создан посредством глубокого копирования, что приводит к созданию нового объекта Block, который имеет собственные данные и собственный объект для наблюдения за ссылками. Исходный блок, который раньше служил основой для df2, теперь может быть обработан сборщиком мусора. Это обеспечивает то, что массивы, лежащие в основе df и df2, не имеют общих участков памяти.
Рассмотрим теперь другой сценарий.
df = None
df2.iloc[0, 0] = 100Датафрейм df объявляется недействительным до того, как мы модифицировали df2. Следовательно — слабая ссылка объекта для подсчёта ссылок, которая указывает на объект Block, лежащий в основе df, разрешается в None. Это позволяет нам модифицировать df2 не инициируя при этом копирование данных.

Объект для наблюдения за ссылками хранит ссылку лишь на один объект DataFrame, что позволяет непосредственно модифицировать данные, не прибегая к копированию.
Вышеприведённая команда reset_index создаёт срез. Этот механизм немного упрощается в том случае, если у нас есть операция, которая сама инициирует копирование.
df2 = df.copy()При выполнении такой команды сразу же создаётся новый объект для наблюдения за ссылками для датафрейма df2.

Итоги
Мы исследовали работу механизма наблюдения за ссылками, используемого в CoW, поговорили о том, когда инициируются операции копирования данных. Этот механизм в pandas откладывает копирование настолько, насколько возможно. Это сильно отличается от поведения библиотеки без использования CoW. Механизм наблюдения за ссылками отслеживает все объекты DataFrame, которые пользуются одними и теми же участками памяти, что приводит к тому, что работа с данными в pandas оказывается более логичной.
В следующей статье мы разберём технические приёмы, которые используются для того чтобы сделать этот механизм эффективнее.
О, а приходите к нам работать? ???? ????
Мы в wunderfund.io занимаемся высокочастотной алготорговлей с 2014 года. Высокочастотная торговля — это непрерывное соревнование лучших программистов и математиков всего мира. Присоединившись к нам, вы станете частью этой увлекательной схватки.
Мы предлагаем интересные и сложные задачи по анализу данных и low latency разработке для увлеченных исследователей и программистов. Гибкий график и никакой бюрократии, решения быстро принимаются и воплощаются в жизнь.
Сейчас мы ищем плюсовиков, питонистов, дата-инженеров и мл-рисерчеров.
abagnale
А вон там гражданин говорил, что pandas это устаревшая библиотека. Получается, обманул!