

Привет, Хабр! С прошлого дайджеста произошло много событий в мире MLOps и дата-аналитики. Например, Microsoft анонсировал свой AI-чип, Databricks стал скупать «игроков поменьше», а рынку аналитических решений прогнозируют рост на 40% каждый год. Подробнее об этом рассказываем в статье. Еще больше полезных материалов — в Telegram-сообществе «MLечный путь».
Используйте навигацию, чтобы выбрать интересующий раздел:
→ Теория
→ Практика
→ Обзор рынка
→ Инструменты
→ Видео
Теория
From Data Platform to ML Platform
Статья об эволюции систем для работы с данными в компаниях. Всего автор выделил четыре этапа с подробными иллюстрациями:
- базы данных с OLTP/OLAP-нагрузкой,
- Data Lake для хранения неструктурированных данных,
- инфраструктура для обработки данных в реальном времени,
- MLOps.
Дополнительно автор поделился своим взглядом на объединенную Data/ML-платформу. В целом, такой подход выглядит логично, но не всегда его можно реализовать как на уровне инфраструктуры, так на уровне необходимых компетенций профильных специалистов.

Инфраструктура БД с с OLTP/OLAP.
Why You Don’t Want to Use Your Data Warehouse as a Feature Store
Специалисты из Tecton решили отработать возражения насчет их Feature Store и рассказали, почему не нужно хранить фичи в Data Warehouse. Основной акцент сделали на недостатке возможностей для работы с real-time преобразованиями данных: streaming ingestion сделать можно, а вот превратить это в пайплайн уже сложно.

Практика
Как работают Model Serving инструменты изнутри
Если планируете писать собственный serving в компании, рекомендую почитать эту статью. В ней автор делится собственным опытом разработки тематического фреймворка:
- Первоначальная настройка ML-модели.
- Создание интерфейса командной строки (CLI).
- Описание конфигураций с помощью YAML.
- Интеграция модели в Docker-контейнер.
- Деплой ServingML.
По его словам, он вдохновлялся исходным кодом BentoML и MLRun.
From Big Data to Better Data: Ensuring Data Quality with Verity
Инженер из Lyft написал статью об обеспечении качества данных. В ней рассказал о внутреннем продукте Verity и описал пять аспектов концепции качества данных, разработанной сотрудниками компании. Пригодится, если хотите улучшить свои бизнес-процессы.

Пять аспектов качества данных.
Потоковая обработка данных: анализ альтернативных решений
Коллеги из ITSumma рассказали о своем опыте работы со Spark и Flink в качестве решений для потоковой обработки данных. Дополнительно сравнили их по трем критериям:
- время задержки при прохождении данных через потоковую систему обработки,
- наличие параллельной обработки с масштабированием общей пропускной способности,
- гарантия однократной передачи каждой записи (Exactly Once Semantics).
Как часто бывает при работе с Open Source-продуктами, без написания собственного коннектора не обошлось.
MLOps в билайн
Не знали, как обстоят дела с MLOps в крупных компаниях? Прочитайте статью от Билайн. В ней коллеги поделились, как и по каким причинам менялись их ML-процессы и инфраструктура. Особенно понравилось, что упомянули дообучение моделей (Retrain) — редко где встретишь информацию об этом. Теперь будем ждать продолжение, чтобы узнать, какие инструменты и технологии они применили.
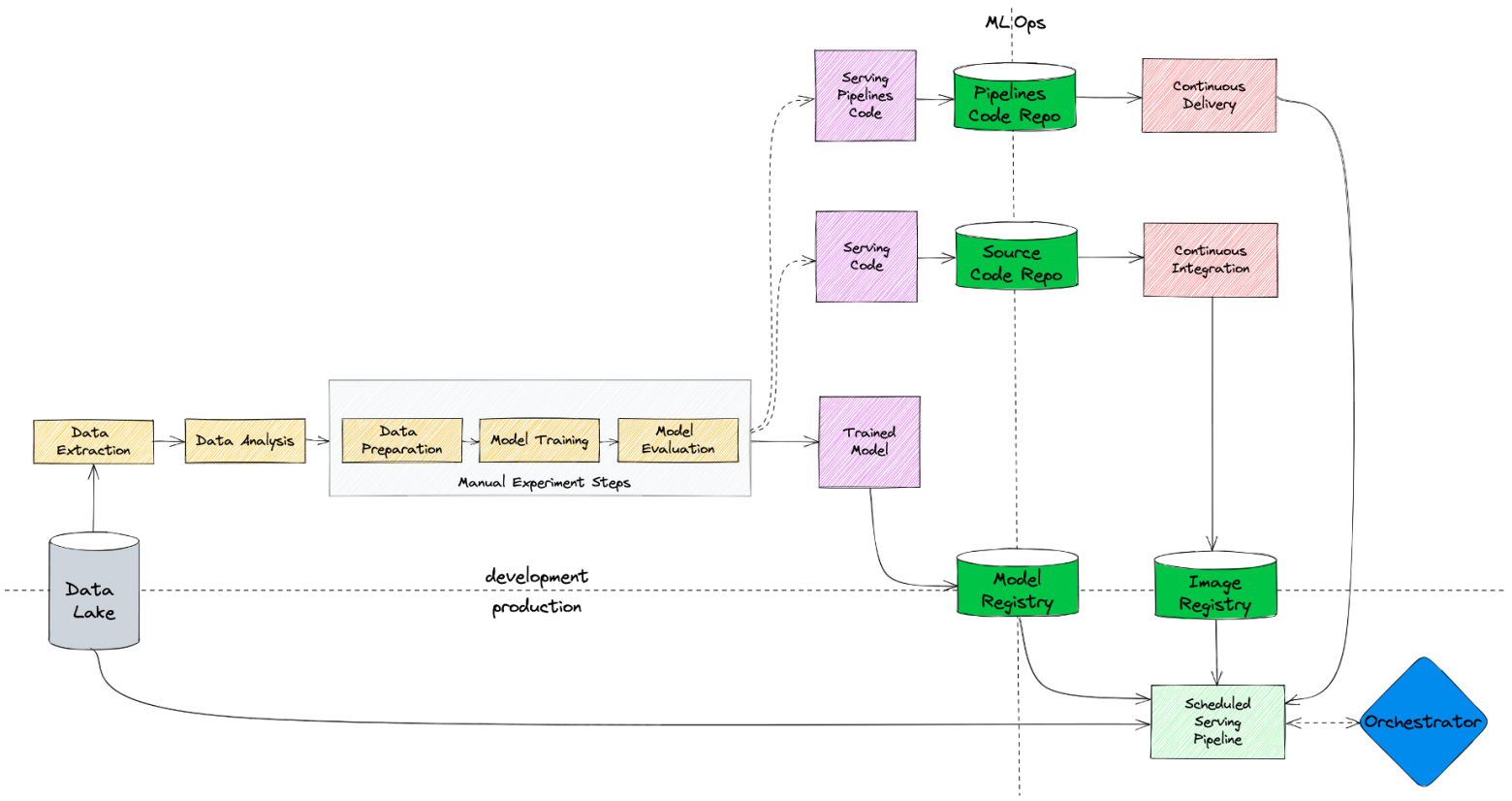
Схема построения MLOps в Билайн.
Обзор рынка
Microsoft AI-чип
На конференции Ignite 2023 Microsoft презентовал новый чип для искусственного интеллекта Maia 100. Несложно догадаться, что ребята из Redmond хотят получить собственные платформы для обучения и инференса больших языковых моделей. При таких масштабах не получится без оптимизации и кастомизации.
Напомню, что у Google давно уже есть тензорные процессоры (TPU) и чипы Tensor для смартфонов. Какое решение займет рынок — покажет время.

Российский рынок дата-решений вырастет до 170 млрд рублей за пять лет
TAdvisor поделились результатами исследования фонда «Центр стратегических разработок». Прогноз объема рынка получился оптимистичным — даже больше, чем обещают крупные аналитические агентства. Особенно годовой прирост на 40% в ближайшие два года. Из необычного: объем data governance-решений почти равен сегменту оказания услуг. По субъективным ощущениям столько быть не должно.

Структура продуктов и услуг на рынке в 2022 году.
Does venture capital ruin great products?
Периодически я делюсь новостями об инвестициях в аналитические или ML-решения. Делаю это для того, чтобы показать динамику рынка и выделить перспективных игроков, которые влияют на его развитие. Очередной повод — статья о венчурных инвестициях. В ней автор размышляет, так ли хорошо они помогают разрабатывать качественные продукты. Спойлер: далеко не всегда.
Gartner Top 10 Strategic Technology Trends for 2024
Статья о топ-10 технологических трендов, которые подходят для ML и AI. По мнению Gartner, эти инновации помогут компаниям быстрее достичь своих бизнес-целей. Platform Engineering не самый очевидный вариант для этого. Он больше о кастомизации платформы под задачи пользователя, но в этом и ценность для текущей аудитории.
Инструментов появилось настолько много, что хочется выбрать галочками необходимые и больше не усложнять. В своей ML-платформе мы по такому пути и стараемся идти.

Databricks acquires data replication startup Arcion
Новая тенденция: лидеры рынка решают свои стратегические задачи с помощью компаний поменьше. Вот, например, у Databricks была проблема: интеграция данных в платформу отнимала много — в том числе и материальных — ресурсов. Они подумали и решили выкупить стартап Arcion, занимающийся репликацией данных. Ранее они также приобрели MosaicML. Вопрос: кто следующий?
Survey: Large Language Model Adoption Reaches Tipping Point
Исследовательская работа от Arise по внедрению LLM в бизнес. В ней поделились основными выводами с опроса. Главный поинт: у компаний увеличились барьеры c использованием LLM в продакшене.
Мне кажется, все это связано. Компании начали мигрировать в on-premise для большей безопасности — и это привело к тому, что у сотрудников выросла ответственность за развертывание и точность ответов.
AMD Rallies After Predicting Sales Surge for New AI Processor
Большая аналитика от Bloomberg по перспективам Instinct MI300. По их словам, многие компании уже сделали предзаказы GPU на основе этого чипа. Такое чувство, что скоро AMD поглотит немалую часть рынка — хотя бы из-за возможного дефицита карт от Nvidia.

Ускоритель Instinct MI300 от AMD.
Инструменты
BI Adoption Guide
Подробный mindmap о проблемах внедрения и использования BI-систем в компаниях. Автор выделил восемь причин неактивного использования BI в организациях и предложил варианты по их решению. Сама схема находится в Miro, ее можно сохранить и использовать в похожих ситуациях.

Major Milestone: lakeFS 1.0 Is Now Generally Available
LakeFS выпустил обновленный инструмент для версионирования данных. Это некий «Git для аналитиков» при работе с Data Lake. Помимо косметических изменений, теперь в LakeFS можно интегрировать Databricks, Apache Iceberg, Microsoft Azure и другие решения. Выглядит стильно — посмотрим, как будет на деле.

Burn Unstoppable Rusty Neurons
Rust сейчас в моде, поэтому делюсь фреймворком для машинного обучения. Он упрощает эксперименты, обучение и развертывание моделей. В целом, прикольный инструмент для людей со специфическими вкусами.
Autonomous DAta (Labeling) Agent framework
Наткнулся на новый для себя фреймворк со схемой разметки текста. Пригодится тем, кто работает с клиентами от имени других организаций (агентская схема). Кажется, теперь классификацию тикетов в техподдержку можно решить намного проще.

CUDA Toolkit 12.3
Недавно вышла новая версия CUDA Toolkit. В ней есть важное обновление типа deprecated:
«Starting in CUDA 12.4, the NVIDIA driver installation on Linux will be opt-in. The goal is to improve user experience for a wide range of use cases such as installing the open module flavor driver. The cuda-runtime dependency and therefore the cuda-drivers (NVIDIA driver) dependency will be removed from the top-level cuda meta-package. Effectively, the cuda and cuda-toolkit meta-packages will be equivalent in CUDA 12.4».
Видео
MLOps London October 2023 — Testing ML Pipelines
В последнее время встречаю мало материалов о тестировании в ML-среде, поэтому советую посмотреть доклад с MLOps London. В нем спикер затрагивает много интересных аспектов о работе с синтетическими данными, о которых сразу и не вспомнишь.
Понравились материалы из дайджеста? Делитесь своими в комментариях!