

Звание текста с лучшими мемами получила статья про антисоветы для работы с ML-экспериментами.
Привет, Хабр! Это уже четвертый выпуск дайджеста по ML и работе с данными для тех, кто тащит эти направления в своих компаниях. Сегодня в программе — антисоветы для работы с ML-экспериментами, обзор библиотеки для Pandas с примесью ChatGPT, очень сложная статья про Ray и многое другое. Еще больше полезных текстов по DataOps и MLOps — в Telegram-сообществе «MLечный путь».
Используйте навигацию, если не хотите читать текст полностью:
→ Теория
→ Практика
→ Мнение
→ Инструменты
→ Видео
Теория
CI/CD in Data Science: Revolutionizing the Way We Work with Data
Автор погружает в основы концепции CI/CD и объясняет, какую роль могут играть ее практики в улучшении аналитических процессов. В итоге упоминаются следующие точки применения:
- валидация и тестирование данных,
- интеграционные и юнит-тесты для пайплайнов,
- дебаг пайплайнов и моделей,
- обеспечение воспроизводимости всех процессов и артефактов.
OLTP Vs OLAP – What Is The Difference
Полезная шпаргалка на тему различий между транзакционными и аналитическими системами обработки данных. Внутри — инфографика с пояснениями про OLAP/OLTP, колоночные и строчные СУБД, а также особенности моделирования данных в этих системах.
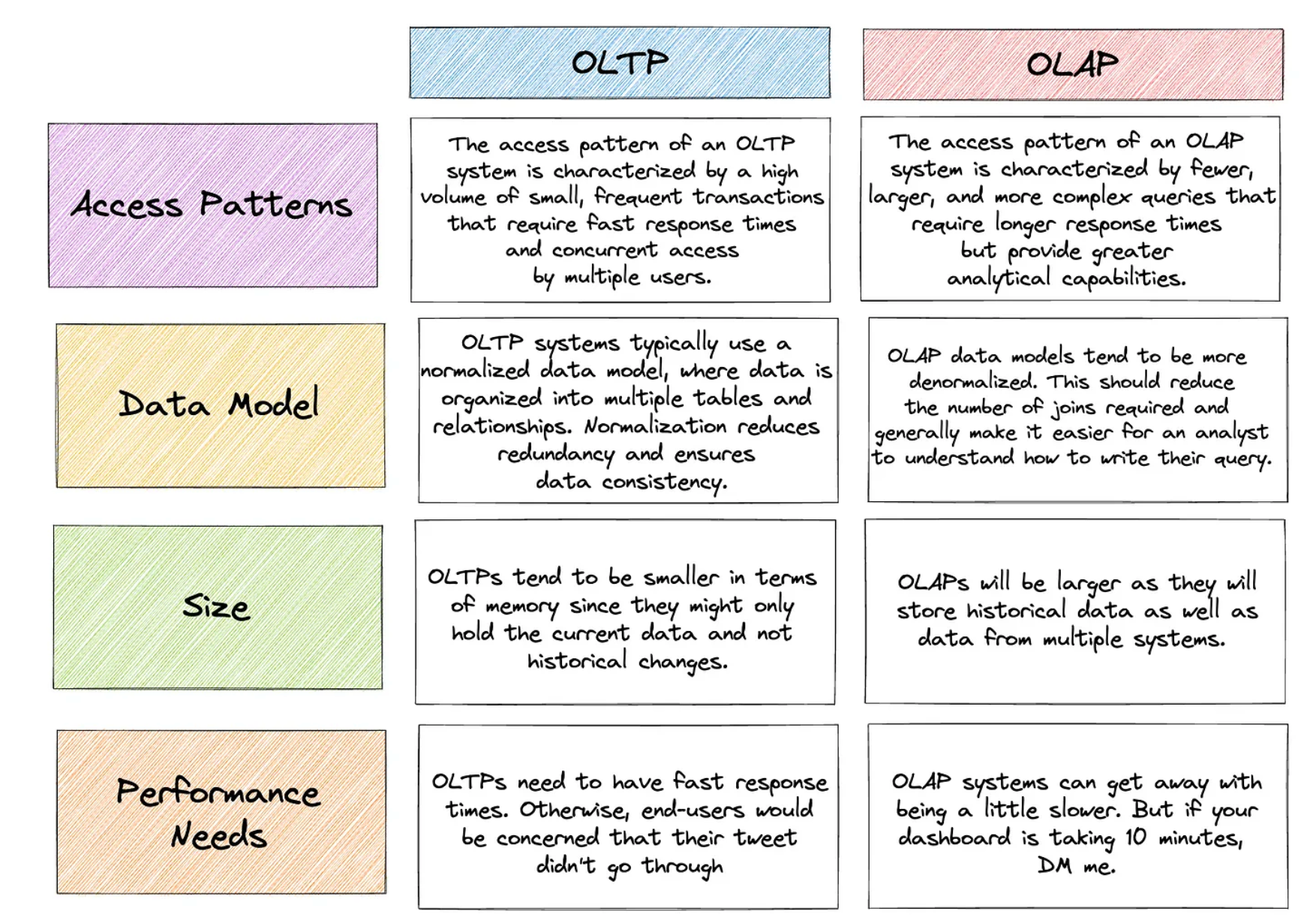
Вот такая симпатичная таблица со сравнением. Источник
Efficiently Scale LLM Training Across a Large GPU Cluster with Alpa and Ray
Давно не встречался со «страшными» статьями про Ray — фреймворк для управления распределёнными вычислениями. Конкретно в этом тексте собрали все тренды машинного обучения — LLM, GPU, Alpa.ai и сам Ray.io. Предупрежу сразу: технический уровень текста очень высокий.
Optimizing ETL Workflows: Trends, Challenges, and Best Practices for DataOps Success
Тезисная статья про текущее состояние инструментов для преобразования данных. В ней подробно перечислены тренды, вызовы, лучшие практики и все, что связано c DataOps. Дополнительно предложены рекомендации по управлению рабочими процессами вокруг ETL/ELT, а также ключевые факторы, которые следует учитывать при выборе платформенных решений. Почему-то нет конкретных примеров инструментов, так что практическая полезность под угрозой.
Delta, Hudi, and Iceberg: The Data Lakehouse Trifecta
Неплохая обзорная статья по технологиям для реализации LakeHouse-архитектуры. Автор подробно описал особенности и причины появления основных функций Delta Lake, Apache Hudi, Apache Iceberg. В дополнение — табличка со сравнением возможностей этих продуктов. Пригодится, если не читали наши предыдущие дайджесты.

Практика
Deploy a Voice-Based Chatbot with BentoML, LangChain, and Gradio
Отличная инструкция по созданию голосового бота с помощью BentoML — фреймворка Python для обслуживания и развертывания моделей. В своем проекте автор опирается на OpenAI API и использует «Википедию» в качестве дополнительного источника данных. После прочтения вы не только создадите своего бота, но и научитесь работать с модными инструментами. Если Gradio не нравится, можно попробовать прикрутить Streamlit, но уже самостоятельно.
Philosophy of an Experimentation System — MLOPs Intro
Очень понравилась статья про опыт компании Loris в управлении экспериментами. Кроме профессиональных мемов, повеселил список антисоветов в работе с экспериментами — можно себя оценить. Самый любимый — «You try to avoid collaboration because explaining how to continue on your results might take several days» («Вы пытаетесь избежать совместной работы, потому что объяснение того, как работать с вашими результатами, может занять несколько дней»). Статья небольшая, так что всем советую прочитать.
The struggles scaling data teams face
Еще один любопытный текст от сооснователя компании Synq — Mikkel Dengsøe (когда-нибудь смогу произнести эту фамилию). В большинстве материалов у него интересный фокус на управлении дата-командами и работу с различными менеджерскими сложностями в этой области. Эта статья — про решение проблем, связанных с масштабированием аналитических команд в четырех областях:
- Онбординг,
- Разработка,
- Мониторинг,
- Самообслуживание.
Мнение
Топ-5 тенденций потоковой передачи данных на 2023 год
В тексте — целый сборник трендов по streaming-сценарию обработки данных от Kai Waehner. Любезно переведен на русский коллегами из Southbridge. Из статьи вы узнаете о децентрализованной сети передачи данных, построении облачных LakeHouse, совместном использовании и расширенном управлении данными. Разговор в основном вокруг Apache Kafka, но к этому, кажется, нужно просто привыкнуть.
BI by another name
Люблю статьи-размышления от Benn Stancil. В этой он раскрывает свой подход к тому, что сейчас принято называть headless BI — семантический слой, хранящий значимые для бизнеса метрики и показатели. В общем, это модель данных, к которым в теории можно обращаться из любого интерфейса — будь то удобный BI, SQL-движок, Jupyter и любой аналог Excel.
Какое-то количество инструментов в этой области уже имеется, но проблемы с внедрением остаются. Например, сложно мигрировать с одного проприетарного решения на другое, у существующих решений недостаточно универсальности. Кстати, узнал из текста о двух новых для себя инструментах (языках) для моделирования данных — Motif, Malloy. Может, они вас тоже заинтересуют.
Инструменты
A Framework for Building a Production-Ready Feature Engineering Pipeline
Автор напоминает, что среди Feature store есть не только Tecton и Feast. В тексте он достаточно подробно разбирает опенсорсный Hopsworks: и схемы, и примеры кода присутствуют. Стоит отметить, что все известные нам примеры использования open source «магазинов» фичей заканчивались написанием собственного… Так что предлагаю рассматривать эту статью как источник вдохновения и архитектурных решений.
Introducing Microsoft Fabric: Data analytics for the era of AI
В мае этого года Microsoft выпустил новую аналитическую платформу Fabric. Выглядит она как единое рабочее пространство, которое объединяет все сервисы компании для аналитиков — Azure Data Factory, Azure Synapse Analytics и Power BI. Все это в отдельном интерфейсе, интегрировано между собой, основано на DataLake-подходе (под это есть отдельный сервис OneLake). И все, конечно же, с AI-составляющей — куда без нее. Настоящий праздник на улице фанатов Power BI.

Источник
GPT-4 + Stable-Diffusion = ?: Enhancing Prompt Understanding
Несмотря на впечатляющие возможности диффузионных моделей, у них не всегда получается точно следовать prompt’ам, особенно если требуется пространственное мышление или здравый смысл. В статье научные работники Беркли предлагают решение этой проблемы — метод LLM-grounded Diffusion, собственную генеративную модель для преобразования текста в изображение.
Sketch: искусственный интеллект на службе аналитика данных в Pandas
Обзор библиотеки для Pandas, которая автоматизирует некоторые аналитические операции за счет ChatGPT. И все это прямо из Jupyter. Пока проект выглядит сыровато и его сложно рекомендовать тем, кто поверхностно разбирается в анализе данных — за нейросетью нужно будет перепроверять. Но в остальном появление таких библиотек ожидаемо — прогресс не остановить.
Видео
Explainable AI and DevOps/MLOps for Banking — Unicredit
Время просмотра: 1 час.
Если вам интересны темы AI и ML в FinTech, советую посмотреть запись доклада UniCredit на конференции Data Science Milan. В видео специалисты банка выступают с двумя докладами:
- Ilaria Bordino, старший разработчик UniCredit, рассказывает про Explainable AI в банковской среде,
- Bhaskar Chakraborty, AI-архитектор/ ML-инженер банка, рассказывает о применении DevOps и MLOps для автоматизации цифровых процессов в банковской сфере.
Data Summit 2023
Время просмотра: 16 видео от 2 до 8 минут.
10-11 мая в Бостоне прошла конференция Data Summit 2023. На ней спикеры выступили с интересными темами — от стратегий по работе с данными до современных data stack-ов. Про AI и MLOps тоже поговорили — куда без них. Все видео и презентации находятся в открытом доступе, поэтому рекомендую ознакомиться с материалами в свободное время.
MLOps London May — Data Quality and Optimising Inference
Время просмотра: 1 час 30 минут.
Еще одно видео про MLOps от одноименного сообщества специалистов в Лондоне. Оно объединяет инженеров, разработчиков и аналитиков, которые занимаются проблемами создания и развертывания ML-систем. В видео два доклада:
- Andrew Jones, Principal Engineer из GoCardless, рассказывает про опыт использования концепции Data Contracts для повышения качества данных.
- Ed Shee, Head of Developer Relations из Seldon, рассказывает про возможности своего продукта и акцентируется на Multi Model Serving.
Понравились материалы из дайджеста? Делитесь своими в комментариях!
Возможно, эти тексты тоже вас заинтересуют:
→ Разработчики — налево, методологи — направо: четыре шага к оптимизации работы BI-аналитиков
→ Полезные материалы по Data Science и машинному обучению, которые помогут пройти сквозь джунгли из терминов
→ Как улучшать продукты, опираясь на мнение пользователей, или загадка плавающего IP-адреса