

Привет, Хабр! Делюсь новым уловом текстов, которые помогут вам лучше разобраться в темах ML, искусственного интеллекта и дата-аналитики. В этой подборке — смесь фундаментальных трудов и более «популярных» статей. Начнем с красочного лонгрида, а закончим — сводом знаний по управлению данными в 10 главах (не пугайтесь).
Еще больше полезных подборок по DataOps и MLOps публикуем в Telegram-сообществе «MLечный путь». Там обсуждаем проблемы и лучшие практики организации production ML-сервисов, а также обмениваемся опытом. Присоединяйтесь к более 1 000 специалистов, развивающим ML- и Data-направления в российских и зарубежных компаниях.
Используйте навигацию, если не хотите читать текст полностью:
→ Мнение
→ Теория
→ Практика
→ Инфраструктура
→ Инструменты
→ Библиотеки
→ Подборки и рейтинги
→ Видео
Мнение
MLOps Is an Extension of DevOps. Not a Fork
Вы еще не подписались на обновления в блоге neptune.ai? Самое время. В нем опубликовали большую концептуальную статью про MLOps. Интересно, что основана она на той же публикации трех немцев, которую мы рассматривали в рамках нашей большой статьи про MLOps на Хабре. Она, в отличие от текста neptune.ai, на русском языке. При этом автор также обратил внимание на reasonable MLOps, то есть на концепцию «осмысленного MLOps», когда компания выделяет самые нужные для себя компоненты и внедряет только их. В общем, этот текст дополнит общую картину MLOps, если она у вас еще не до конца сформировалась.
Generative AI: A Creative New World
Классный красочный лонгрид про актуальное состояние дел в направлении Generative AI, созданный в соавторстве с GPT-3. Текст написан популярно и интересно — есть некоторая историческая ретроспектива и обзор рынка. В частности, добавлен AI Application Landscape, частью которого являются используемые модели. Список не очень большой — больше всего моделей в сегменте работы с текстом, в списке есть даже отечественные разработки.

Источник
Data-centric ML benchmarking: Announcing DataPerf’s 2023 challenges
Многие скорее всего знакомы с MLPerf — проектом, задача которого состоит в создании честных и полезных бенчмарков программного и аппаратного обеспечения и сервисов в задачах обучения и инференса. В обзоре по ссылке вы узнаете больше о DataPerf, который тоже про бенчмарки, но более «датацентричные». DataPerf может усложнить задачу по проектированию конвейеров данных для production-систем, так как они должны будут не только решать задачи, но и делать это с нужным количеством «попугаев» в рейтинге. В общем, в мире дата-инженеров может прибавиться головной боли.
Data Architecture: Rich + Happy = Fata Data Stacks?
В статье на Medium автор делится семью советами, которые помогут построить простую и гибкую архитектуру для анализа данных — без лишних усложнений. Вот короткое овервью этих уроков:
- не используйте чрезмерно большое количество инструментов, решающих мелкие задачи,
- иногда лучше просто не использовать какой-то инструмент,
- не нужно недооценивать силу поддержки сообществ (ряд инструментов популярен именно по причине наличия ответов на большинство часто задаваемых вопросов),
- новые модные инструменты не всегда так уж полезны,
- избегайте вендор-лока,
- не бойтесь заменять инструменты на другие,
- инвестируйте в автоматизацию.
Каждый урок подкреплен жизненными историями разной степени полезности.

Теория
Управление данными: DAMA DMBOK2
Здесь у нас целый проект по популяризации «DAMA-DMBOK2: Cвода знаний по управлению данными». Составители — а это на секундочку эксперты Международной ассоциации управления данными (DAMA) — обещают, что это наиболее полное и актуальное введение в дисциплину управления данными с обзором лучших практик. В этом курсе — 10 глав про то, почему данными нужно управлять «по-взрослому». Удобно, что можно выбирать интересующий блок, а не читать все. Также для каждой главы записано видео с экспертами по теме, на страничке есть готовый плейлист. Контент основательный и для энтерпрайз-компаний, но некоторая информация будет полезна и бизнесам поменьше.
The Evolution of Architecture from ETL to EtLT
Автор рассматривает эволюцию подхода к трансформации данных в аналитических системах — от 90-х годов до наших дней и далее.
Он выделяет три временных отрезка:
- 1990–2015 — время ETL,
- 2015–2020 — время ELT,
- 2020–202x — EtLT.
Последний подход — это гибрид ETL и ELT, сочетающий в себе сильные стороны обеих концепций. В качестве инструмента для реализации последнего этапа предлагается ApacheSeaTunnel. Это платформа интеграции данных «нового поколения», которая находится в активной разработке. Если не слышали про этот инструмент, почитайте текст — в нем подробно рассмотрены его архитектурные аспекты, основные компоненты и принципы работы.
Практика
Как мы подружили ML и биореакторы
Всегда интересно посмотреть на внутреннюю кухню в какой-то сильно специализированной компании. Ни на мгновение не сомневался, что в биотехнологической компании BIOCAD есть ML и все вокруг него, но до этого момента предметные статьи про их процессы мне не попадались. Здесь же ребята рассказали про применение машинного обучения при производстве лекарственных средств и, в целом, поделились информацией о команде и процессах в ней. Стоит сказать, что статья больше про концептуальные аспекты математики, но, если это вас не пугает, смело читайте. Кроме того, я увидел, как выглядит биореактор. Спойлер: в большинстве компьютерных игр нас обманывают — реакторы выглядят иначе.
Специфика DataOps в Учи.ру
Интересный текст от ребят из Учи.ру — к слову, наших клиентов. В статье — отличный пример построения платформы обработки данных по ELT-сценарию.
Что по технологическому стеку:
- основное хранилище — S3 (на самом деле Data Lake),
- ETL/ELT: Apache Spark,
- витрины данных: ClickHouse,
- пользовательские интерфейсы: Tableau, Jupyter.
Ценно описание IaC, который это все обеспечивает: Terraform, Ansible, GitLab — все по-взрослому.
Как развернуть нейросеть в облаке за 5 минут: начало работы с Diffusers
Тут наша инструкция, как использовать облачные серверы с GPU для развлечения или для победы в конкурсах живописи (судя по последним данным, ИИ скоро соберет все трофеи в мире изобразительного искусства). Описан каждый шаг, чтобы любой пользователь мог взять и сгенерировать картинку из придуманного prompt’а. Без лимита на количество запросов и вот это вот все.
Инфраструктура
NVIDIA Triton Inference Server with Ensemble Models
Сервер для инференса Triton сейчас активно используется в России. По сути это открытое программное обеспечение для развертывания моделей глубокого обучения в рабочей среде. Найти нормальную документацию по нему — полную и красочную — довольно сложно (GitHub не предлагать). В свое время мне пришлось довольствоваться видео с YouTube. Но вот техническая статья от самой Nvidia — в ней про serving ансамбля моделей. Интересно, что в Triton preprocessing и postprocessing реализуются прямо в файле model.py в секциях initialize и finalize.
Supercharging AI Video and AI Inference Performance with NVIDIA L4 GPUs
Спустя 4 года выходит прямой наследник Tesla T4. Пишут, что это универсальное решение, а не как Tesla A2, но акцент в статье делается на обработку видеопотока. Да и память в 24 ГБ тоже намекает. Из коробки поддерживается AV1 и DLSS3 (который 2,5 по сути). Компания заявляет о возможности построить на NVIDIA L4 целый video end-to-end pipeline.
NVIDIA H100 Tensor Core GPU
И еще одна заявка от вендора видеокарт. Компания запускает новое «супергпу» на замену A100. Что же в H100?
- поддержка MIG до 7 инстансов,
- 80 ГБ HBM2e-памяти,
- в исполнении SXM до 900 ГБ/c. NVlink,
- (вроде как) 18432 FP32 CUDA Cores на всю карту.
Инструменты
Релиз Kubeflow 1.7
Подсмотреть релиз-ноутсы новой версии Kubeflow можно на GitHub. Но формат не очень информативный: список, что добавили и починили, а также благодарности комьюнити. Официального поста в блоге как не было, так и нет. Впрочем, общее представление об изменениях, а их достаточно, сделать можно. Даже логи в notebooks details добавили!
Building the Next-Generation Data Lakehouse: 10X Performance
В последнее время замечаю сильный рост числа публикаций, посвященных Apache Doris. Конкретно в этой статье подробно разбираются ее особенности и преимущества при реализации Lakehouse-архитектуры. Авторы предлагают использовать Doris в качестве единой точки доступа к данным — как из классических DWH, так и из Data Lake. При этом основная фишка решения — в быстром и оптимизированном query-движке, который по бенчмаркам «уделывает» Presto/Trino. Отдельное удовольствие доставляют таблички и схемы — очень по-инженерному!

Графики бенчмарков.
Библиотеки
AI Library
Недавно на Product Hunt стартовал новый проект — каталог всякой всячины для ML. По задумке напоминает G2, но чисто для AI-сегмента. Уже сейчас в нем можно найти полезную инструментальную дичь.
Open source-библиотеки от команд ИТМО
Петербургский университет опубликовал на Хабре обзор своих open source-проектов. В статье только мельком упоминается FEDOT — открытый фреймворк автоматического машинного обучения (AutoML), хотя он тоже из ИТМО. Попавшие в список библиотеки, конечно, не всем пригодятся, но вдруг вы сейчас ищете как раз что-то такое.
Using PyGWalker to Enhance Your Jupyter Notebook EDA Experience
Не перестаю удивляться библиотекам, расширяющим возможности Jupyter Notebook. Теперь его можно превратить не только в гуглшиты (Mito), но еще и в drag-and-drop генератор визуализаций (PyGWalker). Насколько это удобнее кода, сказать не могу, но выглядит очень круто.
Pandas 2.0 and its Ecosystem (Arrow, Polars, DuckDB)
Текст посвящен выходу второй версии «панд» и экосистеме вокруг этой библиотеки. Одно из самых мощных изменений — уход с NumPy на Apache Arrow в качестве бэкенда. Это должно сильно ускорить основные операции с датафреймами. Помимо описания изменений, автор по верхам проходится по альтернативам Pandas: Polars, Dask, DuckDB, Koalas, Vaex, VertiPaq.
Подборки и рейтинги
A List of 7 Best Data Modeling Tools for 2023
Сайт KDNuggets продолжает серию статей про разные группы инструментов вокруг аналитики данных. В этот раз рассмотрели решения для моделирования данных. Удивительно, но в списке нет dbt — даже не знаю, чем они насолили автору. Зато есть другие прикольные инструменты: Erwin Data Modeler, Idera's ER/Studio, Archi. Есть кое-что «энтерпрайзное» от Oracle и IBM, а также бессмертная классика вроде MySQL Workbench и SQL database modeler.
Рейтинг BI-платформ 2022
Насколько серьезно относиться к рейтингам — выбор каждого. Как минимум они помогают сложить какое-то общее мнение по рынку, даже если некоторые критерии оценки вызывают сомнения. Тут — таблички, графики и тексты, посвященные отечественным BI-платформам за 2022 год.
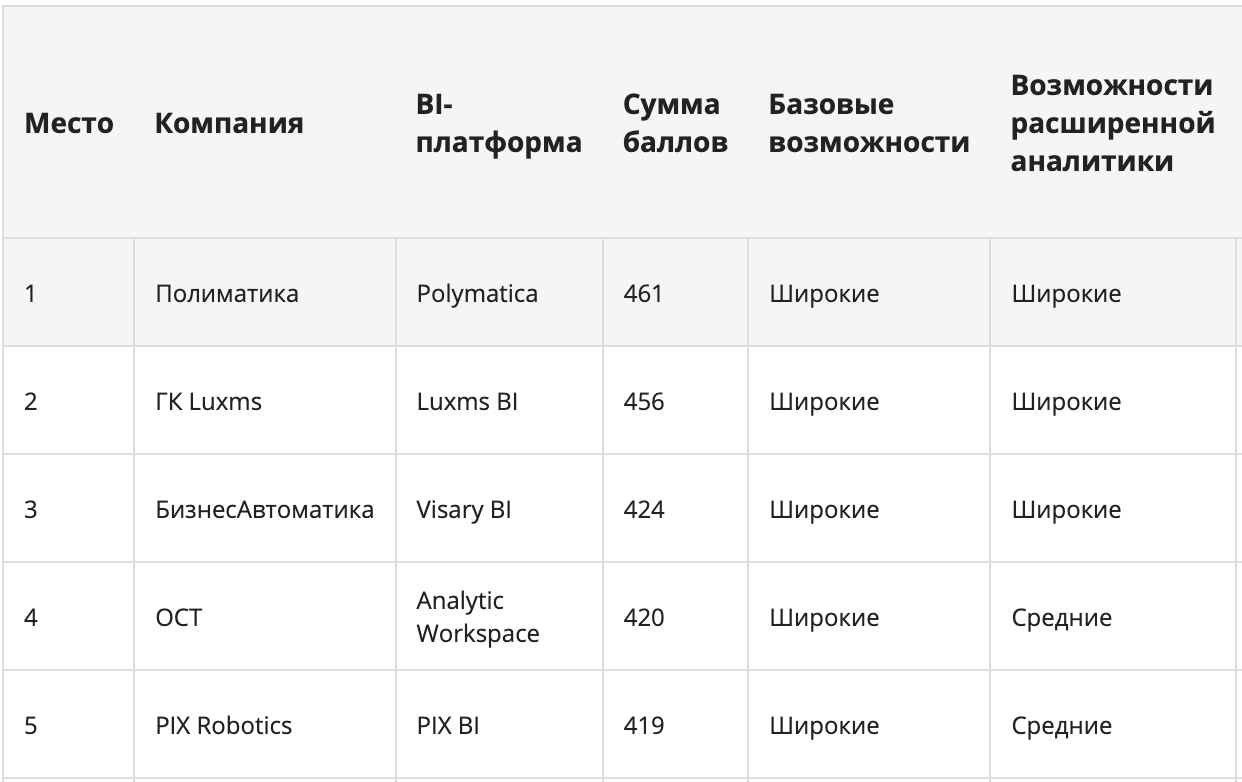
Топ-5 для тех, кто не хочет лезть по ссылке.
Видео
Lets Talk MLOps
Интересное видеоинтервью с очередным представителем профессии MLOps. Ведущая, между прочим, Senior MLOps Consultant! Собеседник же освещает MLOps с точки зрения бизнеса, преимущества его внедрения и т.д. Также в видео упоминаются тренды и варианты входа в этот чудесный мир.
Время просмотра: 27 мин.
ML Monitoring for Bias & Fairness with Tracing
Практическое видео от Whylabs про мониторинг моделей. Все видео Sage Elliott показывает возможности продукта компании. Возможно, кто-то из вас пользуется open source-библиотекой, а с платной версией не знаком. Видео позволит закрыть этот пробел.
Время просмотра: 40 мин.
Возможно, эти тексты тоже вас заинтересуют:
→ 6 дисплеев, 192 ядра и 3 ТБ ОЗУ DDR5: на что способен «ноутбук» от Mediaworkstations и другие подобные системы
→ Что изменилось в инструментах OpenStack? Рассказываем о самых важных обновлениях в релизе Antelope
→ Как улучшать продукты, опираясь на мнение пользователей, или загадка плавающего IP-адреса
ivankudryavtsev
Чем Вам a10 не угодил как замена T4? L4 это уже замена A10, как мне видится.