

Привет, Хабр! Возвращаюсь с новым выпуском полезных материалов, который поможет разобраться в ML, AI и дата-аналитике. Сегодня в программе — состояние MLOps в 2024 году, возможности дата-контрактов, оценка качества данных DQ Score и Python-библиотека для работы с SQL. Подробнее — под катом. Еще больше полезных материалов — в Telegram-сообществе «MLечный путь».
Используйте навигацию, чтобы выбрать интересующий блок
→ Теория
→ Практика
→ Инструменты
→ Мнения
→ Инфраструктура
→ Обзоры рынка
→ Видео
Теория
From Database to AI: The Evolution of Data Platforms
Рано или поздно каждая компания задумывается, как оценить платформу на актуальность и соответствие задачам. Тогда и появляются разные модели зрелости, одна из них — шестиступенчатая. С ее помощью можно оценить уровень развития аналитических решений — от нуля до пяти.

Пятый уровень модели зрелости аналитических решений. Источник.
Из интересного: прикладное использование ML и AI начинается только на предпоследнем уровне, а пятый полностью завязан на применении GenAI.
What is the difference between LLMOps and MLOps?
Полезный материал о различиях между LLM- и MLOps. Если не хотите читать полную версию, можно ознакомиться с основными тезисами на картинке. Все коротко и по делу.

Сравнительная таблица LLM- и MLOps. Источник.
500 ресурсов для аналитиков
Ребята из NewHR подготовили таблицу с источниками по A/B-тестированию, BI, AI, маркетингу, менеджменту и другим категориям. Ознакомиться с самыми популярными можно в подборке от авторов. Пригодится, если хотите быть в курсе аналитического рынка и не тратить время на поиски интересного материала.
Практика
Deploying Deep Learning Models at Scale — Triton Inference Server 0 to 100
В статье автор рассказывает о принципах работы Triton и делится конфигурационными файлами. Все это — на примере запуска сервиса с ML-моделью для ресайза изображений. Возможно, для кого-то она станет точкой входа в мир Triton. К тому же подобные материалы редко увидишь.
Как проводят оценку качества данных в Airbnb
Перевод статьи о контроле качества в Airbnb и их системе оценки DQ Score. Идея внутренней сертификации данных в едином формате перспективная — еще не видел подобного у других компаний. Жаль, что решение закрытое. Хотя это не мешает использовать инструмент как источник вдохновения.

Шкала качества данных и весовые коэффициенты. Источник.
Как мы не выбрали Airbyte, или почему собирать данные лучше по старинке
Коллеги из BI-отдела Selectel поделились своим опытом использования Airbyte — инструмента для сбора данных. Они могли и дальше применять его к своим боевым задачам, если бы не одно «но»… Не буду спойлерить, лучше почитайте самостоятельно.
Для меня это подтверждение того факта, что даже зрелое и популярное open source-решение может не подойти для решения некоторых задач. Но таких инструментов много, всегда есть из чего выбрать.

Инструменты
Power of Data Contracts in Simplifying Data Complexity and tools to build data Contracts
Интересный материал о дата-контрактах. Если коротко, это документ, который определяет параметры использования для обмена данными между поставщиками данных и их потребителями. Реализовать его можно с помощью нескольких инструментов — подробнее о каждом рассказывает автор.
- PayPal’s YAML Specification,
- Data Mesh Manager,
- Data Contract Studio,
- Data Contract CLI,
- Great Expectations,
- Gable.ai.

Механизм работы дата-контрактов. Источник.
Multi-engine data stack — v0
Еще один увлекательный термин из мира «стеков для работы с данными» — multi-engine. Пригодится, если хотите сэкономить средства с помощью использования разных движков для хранения и обработки данных.
- S3 и файлы в формате Parquet.
- DuckDB.
- Snowflake.
- Dbt.
- Dagster.
Дополнительно есть несколько сценариев работы multi-engine. Поможет параллельно использовать инструменты в одной экосистеме.

Используемые стеки для работы с данными в одной экосистеме. Источник.
Data Catalog Tools List & Evolution
Сравнение десяти дата-каталогов от создателей Castor. Компания использовала четырехуровневую модель зрелости и традиционный Landscape. Рейтинг по понятным причинам получился предвзятым, но с критериями оценки и продуктами ознакомиться это не мешает.
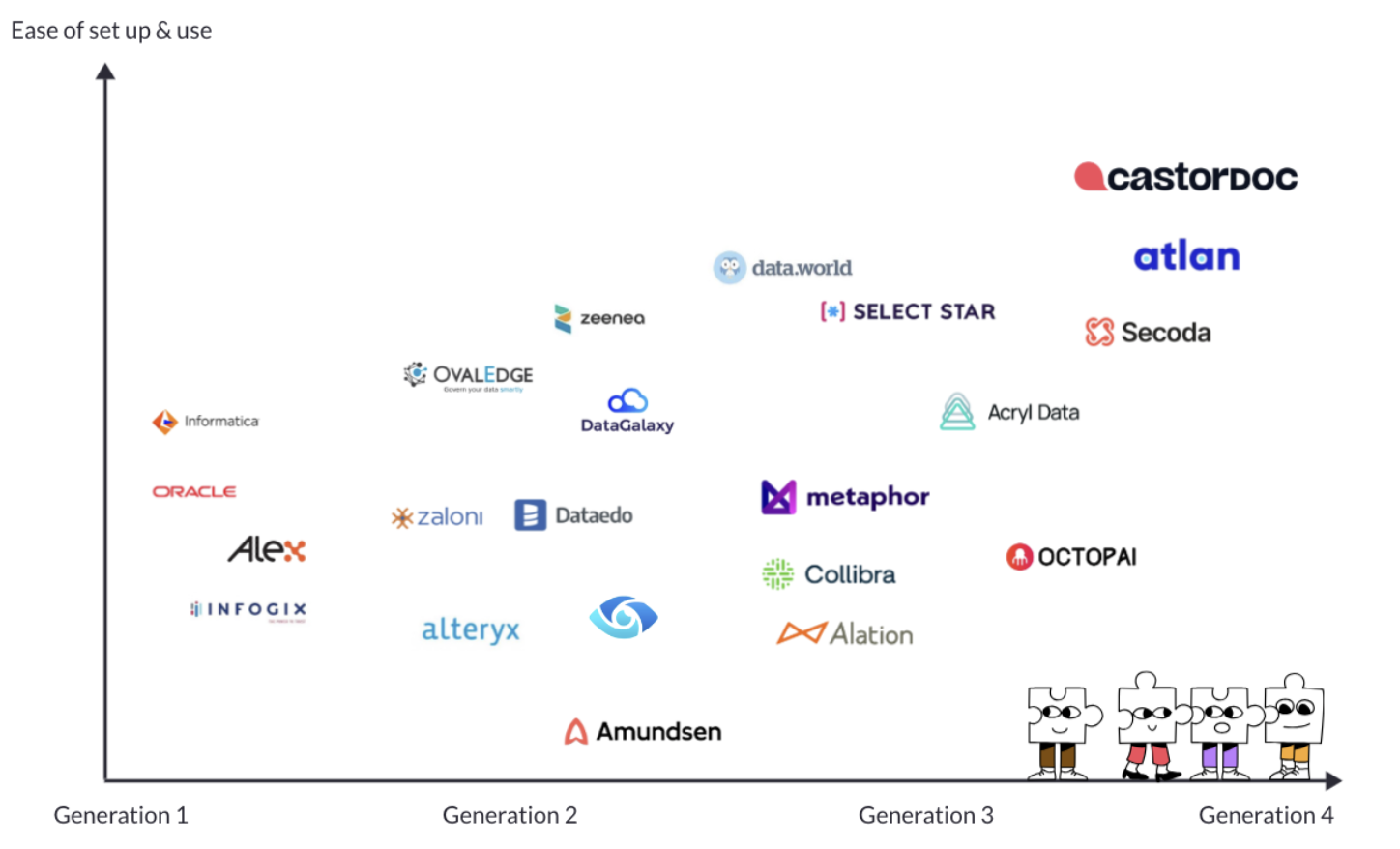
Landscape дата-каталогов. Источник.
SQL Assistant: Text-to-SQL Application in Streamlit
Ребята поделились Python-библиотекой Vanna.ai, которая умеет генерировать SQL и графики на основании полученных данных. Конечно, после определенных манипуляций с LLM. Использовать ее можно прямо в Jupyter, без сторонних инструментов.

Архитектура Vanna.ai. Источник.
Выглядит амбициозно. Не нужно знать SQL: просто пишете запрос и получаете данные. Вот только насчет качества такого решения я не уверен.
Мнения
Data Management in 2024
Автор размышляет о влиянии открытых форматов хранения данных (Apache Iceberg, Apache Hudi, Delta Lake) на появление дата-платформ «новой волны». Похожие решения можно посмотреть на StarTree и Dremio, но до общепринятых и повсеместно используемых им еще далековато.
It's time to build
Кажется, я не перестану делиться материалами автора Benn Stansil. И это несмотря на то, что он пишет сложно, душно и с неинформативными выводами, которые можно пропустить.
В тексте автор поднимает сразу несколько злободневных тем:
- популярность новых аналитических инструментов.
- смещение фокуса в общественном пространстве на AI/ML,
- подход к разработке новых дата-стартапов.
Если у вас хороший уровень английского — рекомендую к прочтению.
What Will 2024 Bring to Advance Analytics?
CEO рынка аналитических решений рассуждают о векторах развития аналитики в 2024 году. Главный тренд, я полагаю, угадает каждый. Ведь это обработка естественного языка и LLM. В общем, «English will replace SQL» и все в таком духе.
Инфраструктура
Delivering Efficient, High-Performance AI Clouds with NVIDIA DOCA 2.5
Исходя из опыта, один из самых сложных компонентов высокопроизводительного облака — сеть между вычислительными нодами. Если запустить регион с пропускной способностью 5 Гбит, то добавить еще 10 Гбит просто так не получится. Физическое оборудование, программные компоненты, гипервизоры и другие факторы накладывают свои ограничения.

Аппаратный и программный стек NVIDIA. Источник.
У NVIDIA есть целый аппаратно-программный комплекс для оптимизации производительности облачных вычислений. Подробнее о них можно почитать в материале.
Groq LPU Inference Engine
Мало нам было CPU, GPU, TPU, так теперь появился LPU — Processing Unit для LLM. Оказалось, малоизвестный стартап Groq стал лидером в инференсе LLM, выпустив языковой процессор (LPU) с «первым независимым бенчмарком LLM». Время покажет, так ли это на самом деле.
Обзоры рынка
Итоги-2023 от ServerNews: ИИ везде, ИИ повсюду
ServerNews собрал в одном тексте значимые релизы нового AI-железа за 2023 год. Среди них — два поколения процессоров Xeon® Scalable, ускорители от NVIDIA и другие. Конечно, за последнее время появилось много железа «круче» рассмотренного в обзоре, но он поможет составить общее впечатление о рынке и тенденциях.
PostgreSQL возглавила мировой рейтинг роста популярности СУБД и стала абсолютным лидером среди популярных СУБД в России
Это один из тех случаев, когда суть материала передана в заголовке — хоть и объемном. Дополню, что PostgreSQL возглавила рейтинг DB-Engines. По данным Google Trends за 2023 год популярность этой СУБД в России оказалась на 65% выше, чем Oracle, на 76% — MySQL и на 95% — MS SQL Server.
Видео
Аналитические инструменты для ленивых. JupyterLab, SuperSet, Prefect на инфраструктуре с GPU
Недавно прошел вебинар, в котором мы рассказали о вариантах использования наших продуктов — DAVM, DSVM и ML-платформы. Для практики взяли кейс с sentiment-анализом комментариев под статьями из нашего блога на Хабре. Как результат — развернули инференс-сервис с моделью в Kserve и автоматизировали загрузку данных в дашборд Apache Superset.
Getting Started With CUDA for Python Programmers
Специалист по обработке данных Jeremy Howard выпустил обучающее видео по CUDA-программированию. В нем продемонстрировал весь процесс разработки прямо в Google Collab, аналоге Jupyter Notebook. Советую посмотреть урок Python-разработчикам, которые только начинают работу с CUDA.
MLOps Best Practices in 2024
Компания Featureform обсудила состояние MLOps на 2024 год и поделилась лучшими практиками. Их еще нужно обосновать, но было интересно ознакомиться.
Особенно понравились метрики MLOps. Лично знаю людей, которым необходимо отчитываться о результативности внутренних MLOps-платформ, поэтому эта часть может им пригодиться.
GenAI for Financial Services
McKinsey и Iguazio рассказали, как они используют GenAI в финансовой сфере. Всегда было интересно узнать прогнозы и результаты анализа, особенно с конкретными значениями. Вот они и представили их в виде «слайдумента». Можно просто читать и не слушать спикера — ничего важного не потеряете.
MLOps London Jan 2024: A tour of Model Serving Strategies
В прошлой статье я рассказывал о лондонском митапе по MLOps. В этом Ramon Perez из Seldon рассказывает о стратегиях сервинга моделей. Его система для меня не очень понятна: в нем находятся и streaming с batch-обработкой, и Bare metal с serverless, и edge device c mobile app. Даже о PostgresML вспомнил. Отдельно отмечу, что на каждый случай приводятся примеры инструментов для реализации.