
Целью любого проекта, будь то разработка сайта, внедрение искусственного интеллекта или модернизация оборудования, является получение бизнес-результата. Поэтому для клиента важно понимать, какую выгоду он получит от внедрения проекта и как это отразится на его прибыли. Кроме того, разработчикам также необходимо оценить эффект от проекта по нескольким причинам: увеличение вероятности получения новых проектов, лучшее понимание потребностей клиента, повышение рыночной стоимости и моральное удовлетворение от значимости своей работы.
Эффект от введения проекта можно измерить, такими косвенными качественными показателями, как, например, увеличение точности прогноза бизнес-метрик. Также показателем могут стать драйверы дохода (увеличение скорости бизнес-процесса, объемов продаж, количества клиентов, удовлетворенности клиентов и т.п.), но в первую очередь, это увеличение дохода.
Используя различные методы анализа данных, можно с точностью определить эффект даже в том случае, когда классические методы оценки затруднены.
Приведем пример, на котором покажем основные способы оценки эффекта.
Продуктовый магазин планирует ввести в работу робота-консультанта, который будет перемещаться по магазину и предлагать покупателям товары. Требуется оценить эффект от данного проекта в терминах выручки. При этом магазин снабжен камерами с возможностью распознавания лиц, поэтому есть возможность отслеживать – к каким именно покупателям подъезжал робот с консультацией.
Для предварительного анализа магазин предоставил данные по покупкам с января 2022 года по конец июня 2023 года. Запуск проекта планируется в начале июля 2023 года.

Данные имеют следующие колонки:
• date – дата покупки;
• PurchasID – уникальный ID каждой покупки;
• Time_Interval – временной интервал (утро, день, вечер) в который была совершена покупка;
• Payment_Method – способ оплаты (карта или наличные) ;
• Gender_Recognized – пол клиента, совершившего данную покупку, определяется по камерам при помощи технологии распознавания лиц;
• Age_Recognized – возраст клиента, совершившего данную покупку, определяется по камерам при помощи технологии распознавания лиц;
• Flag_loyalty – бинарный флаг, определяющий была ли использована карта лояльности при совершении покупки;
• Loyalty_ID – уникальное ID карты лояльности;
• Gender – пол клиента, согласно информации с карты лояльности;
• Age – возраст клиента, согласно информации с карты лояльности;
• Loyalty_duration – количество пройденных дней с момента активации карты лояльности;
• Check_Amount – суммарная стоимость покупки.
Значения колонок Gender, Age, Loyalty_duration присоединяются по Loyalty_ID из таблицы, содержащей информацию о картах лояльности и их владельцах, соответственно, если при покупке не была использована карта лояльности, то эти колонки в строке не содержат каких-либо значений.
Задача состоит в выявлении и оценке финансового эффекта от введения проекта, то есть целевой колонкой является Check_Amount.
Основным методом оценки эффекта от проекта является АБ-тестирование, которое заключается в разделении клиентов на две группы. Группа, в которой действует измененный процесс называется тестовой группой, а группа в которой не происходит изменений – контрольной. Затем сравниваются средние значения целевых метрик между тестовой и контрольной группами, чтобы определить насколько внесенные изменения повлияли на результаты.
Для того, чтобы сделать вывод о наличии эффекта от внесенных изменений, среднее значение разницы метрики контрольной и тестовой групп должно быть значимо отличным от нуля. Для определения значимости используются статистические критерии проверки гипотез.
Гипотеза 0: внесенные изменения в проект статистически не повлияли на целевую метрику;
Гипотеза 1: внесенные изменения в проект статистически повлияли на целевую метрику.
С точки зрения статистики гипотезы о наличии эффекта можно записать следующим образом:
где μt – среднее значение тестовой выборки, μc – среднее значение контрольной выборки.
Для проверки подобных гипотез в статистике существует ряд критериев – параметрических (когда выборка распределена по нормальному закону) и непараметрических (выборка распределена не по нормальному закону). При этом исследователь должен заранее выбрать границу значимости, при которой гипотеза H0 будет принята.
Посмотрим на распределение целевой метрики в наших данных:

Видно, что значения Check_Amount распределено не по нормальному закону, поэтому для проверки гипотезы необходимо использовать один из непараметрических статистических тестов, например, тест Колмогорова-Смирнова.
Но перед оценкой эффекта важнейшим этапом является определение длительности тестирования. Слишком непродолжительное тестирование может привести к тому, что собранных данных будет недостаточно для подведения итогов, а очень долгое тестирование ведет к нерациональной потере времени и ресурсов (например, затрат на подзарядку робота). Исследователь, проводящий тест, должен соблюдать длительность и не проверять результаты до конца рассчитанного срока, иначе это может привести к ошибке (проблема подглядываний). Минимальное необходимое количество данных для оценки эффекта можно определить по формуле:
где:
• N – необходимое минимальное количество наблюдений;
• Φ-1 – обратная функция распределения стандартной нормальной величины;
• α – выбранный уровень значимости (вероятность того, что ожидаемый эффект будет ошибочно зафиксирован);
• r – выбранная мощность теста (вероятность того, что при наличии необходимого эффекта, он будет зафиксирован);
• σ2c, σ2t– дисперсия (разброс) в контрольной и тестовой группах;
• ε – выбранный минимальный ожидаемый эффект (разница в целевых метриках у тестовой и контрольной группы).
Функция, реализующая данную формулу на Python:
from scipy.stats import norm
def AB_test_duration(alfa, power, eps, var_test, var_control):
alfa_ppf_value = norm.ppf(1-alfa*0.5)
power_ppf_value = norm.ppf(power)
N_steps = ((var_control+var_test)*(alfa_ppf_value+power_ppf_value)**2)/(eps**2)
return N_stepsВеличины уровня значимости (ошибки первого рода), мощности теста, минимального ожидаемого эффекта выбираются до начала АБ-тестирования. Как правило, α = 0.5, r = 0.8, ε определяют исходя из характера бизнес-задачи. Дисперсия групп до начала тестирования оценивается на основе дисперсии общей совокупности.
Допустим, что в примере с роботом-консультантом мы ожидаем, что средний чек увеличится хотя бы на 5%. Также необходимо учесть, что функция AB_test_duration выдаст продолжительность в количествах покупках, а нас интересует необходимое количество дней проведения теста для обнаружения минимального эффекта при заданном уровне значимости и мощности теста.
#Вычисляем необходимое количество наблюдений для AB-теста
num_purchases_required = AB_test_duration(0.05,0.8,
0.05*data['Check_Amount'].mean(),
np.var(data['Check_Amount']),
np.var(data['Check_Amount']))
# определение среднего кол-ва покупок в день
mean_num_purchas = data.groupby('date').size().mean()
# определение длительности теста в днях
test_days = num_purchases_required/mean_num_purchas
#округление в большую сторону и приведение числа к целому типу
test_days = np.ceil(test_days).astype(int)
print('Продолжительность теста (в днях): ', test_days) Out[]: Продолжительность теста (в днях): 48Для проведения АБ-тестирования 48 дней является достаточно длительным периодом. Магазину может быть не выгодно запускать такой долгий пилот проекта. Необходимо сократить длительность тестирования.
Из формулы расчета необходимого количества данных N видно, что большинство значений выбираются до начала эксперимента. Во время теста могут меняться только дисперсии групп, от которых прямо пропорционально зависит N, поэтому исследователи могут варьировать дисперсию для уменьшения необходимого количества данных при заданном минимальном ожидаемом эффекте.
Одним из методов уменьшения дисперсии является стратификация. Суть данного метода заключается в разделении общей выборки клиентов на кластеры (страты) по характеристикам, которые коррелируют с целевой метрикой, но не зависят от исхода эксперимента. Это может быть возраст клиента, его пол, страна проживания и другие подобные характеристики. Затем формируются контрольная и тестовая группы, с сохранением соотношений страт в каждой группе как в исходной выборке. Стратификация может быть применима при наличии сильных различий в поведение клиентов в разных кластерах, дисбаланса размеров страт и при небольшом количество данных.
При стратифицированном сэмплировании (разбиении совокупности на тестовую и контрольную группу с сохранением исходной частоты страт) мы получаем несмещенную оценку среднего:
Но при этом меньшую дисперсию:
Вывод формул для стратификации
Неизменность среднего целевой метрики при стратификации:
Простое среднее
Взвешенное среднее (стратифицированное среднее):
Снижение дисперсии при стратификации:
Дисперсия при случайном сэмплировании:
Но:
Тогда:
Легко заметить, что:
Тогда дисперсия при случайном сэмплировании будет равна:
Дисперсия при стратификации:
По свойству дисперсий:
Т.к. дисперсия среднего – это отношение дисперсии выборки (σ2) к количеству элементов в выборке:
Тогда:
Или
Где:
• Y – значение метрики;
• var – функция дисперсии;
• K – количество страт;
• Ῡ – общее среднее значение;
• Ῡk – среднее k-ой страты;
• σ2k – дисперсия k-ой страты;
• nk - число объектов в k-ой страте;
• n = Σnk - общее количество объектов;
• wk = nk/n – доля k-ой страты в общей совокупности.
Из формул дисперсий видно, что дисперсия при случайном сэмплировании на Σwk(Ῡk -Ῡ)2 больше стратифицированной дисперсии. Данная величина отражает дисперсию между разными стратами: чем больше разброс значений между стратами, чем сильнее стратификация снижает дисперсию. Если значения внутри одной страты практически не отличаются от значений другой страты, то это означает, что стратификация по данному критерию не целесообразна.
Возвращаясь к примеру с введением робота-консультанта, мы можем стратифицировать все покупки по временному интервалу, способу оплаты, распознанному полу или по наличию или отсутствию карты лояльности при совершении покупки.
Для оценки дисперсии стратифицированного сэмплирования до эксперимента была написана функция calculation_stratification_var:
def calculation_stratification_var(df, target_col, strat_col):
"""
df - датафрейм, содержащий колонку по которой оценивается эффект
и колонку по которой стратифицируем, type: pd.DataFrame
target_col - название колонки по которой оценивается эффект (целевая),type: str
strat_col - название колонки по которой происходит стратификация, type: str
Output : var_strat – оценка дисперсии при стратификации, type: float
"""
len_df = len(df)
df_group = df.groupby(strat_col).agg(
w_group = (target_col, lambda x: len(x)/len_df),
var_group = (target_col, lambda x: np.var(x)))
df_group['w_var_group'] = df_group['w_group']*df_group['var_group']
var_strat = df_group['w_var_group'].sum()
return var_stratИспользуя функцию calculation_stratification_var рассчитаем оценку дисперсии после стратификации по имеющимся категориальным признакам покупки:

Видно, что группа имеет наименьшую оценку дисперсии в сумме покупки при стратификации по признаку наличия карты лояльности у клиента, поэтому используем результаты разделения на страты по этому категориальному признаку для дальнейших вычислений.
На наших данных мы можем проверить правильность соотношения дисперсии при стратификации и дисперсии при случайном сэмплировании. Дисперсию при случайном сэмплировании мы можем посчитать формулам:
Первое слагаемое второй формулы мы используем для оценки дисперсии при стратифицированном сэмплировании. Второе слагаемое, как описано выше, отражает дисперсию между стратами. Таким образом, при стратификации по признаку наличия или отсутствия карты лояльности во время совершении покупки мы можем рассчитать дисперсию между стратами (var_between_strat) и прибавить ее к оценке дисперсии при стратификации (var_stratification). Если расчеты верны, то мы получим значение (var_calculated) равное дисперсии, рассчитанной по первой (простой) формуле (var_simple).
Код для проверки соотношения дисперсий
w_Flag_loyalty_True = (len(data[data['Flag_loyalty']==True])/len(data['Check_Amount']))
w_Flag_loyalty_False = (len(data[data['Flag_loyalty']==False])/len(data['Check_Amount']))
average_check = data['Check_Amount'].mean()
deviation_strata_True = w_Flag_loyalty_True*(data[data['Flag_loyalty']==True]['Check_Amount'].mean() - average_check)**2
deviation_strata_False = w_Flag_loyalty_False*(data[data['Flag_loyalty']==False]['Check_Amount'].mean() - average_check)**2
var_between_strat = deviation_strata_True + deviation_strata_False
var_stratification = calculation_stratification_var(data, 'Check_Amount', 'Flag_loyalty')
var_calculated = var_stratification+var_between_strat
var_simple = np.var(data['Check_Amount'])
Видно, что мы получили одинаковые значения (var_calculated== var_simple), а значит теоретические формулы работают правильно на наших данных.
Применим ранее приведенную формулу для расчета длительности АБ-теста, предполагая, что дисперсия при стратифицированном разделении на группы во время теста будет равна оценке дисперсии при стратификации до проведения эксперимента.
Out[]: Продолжительность теста со стратификацией (в днях): 33Длительность тестирования при использовании стратификации по признаку наличия карты лояльности у клиента при совершении покупки уменьшилось с 48 до 33 дней, однако наш тест будет длиться более месяца. Необходимо попробовать еще уменьшить продолжительность АБ-тестирования.
Еще одним методом снижения дисперсии является CUPED (Controlled-experiment Using Pre-Experiment Data) – контролируемый эксперимент с использованием доэкспериментальных данных. В основе CUPED лежит предположение о том, что на поведение клиента влияют постоянные (или длительные) факторы, коррелирующие с суммой покупки данного клиента (например, наличие или отсутствие детей, уровень достатка и т.п.). С точки зрения математики суть метода заключается в добавлении оценки еще одной случайной величины X, после чего определяется новая метрика с меньшей дисперсией (YCUPED).
где:
• Х – параметр, который влияет на Y, но на который эксперимент не влияет;
• X̅ – среднее значение параметра;
• cov(X, Y) – ковариация X и Y;
• p – коэффициент корреляции двух величин.
При использовании CUPED, как и при стратификации мы получаем несмещенную оценку среднего значения, но меньшую дисперсию, чем при классическом АБ-тесте.
Вывод формул для CUPED
Несмещенность среднего:
где θ – коэффициент.
Исходя из свойства несмещенности оценки матожидания:
Тогда:
Уменьшение дисперсии:
Дисперсия новой метрики:
Точка минимума (определяется из производной var(Ycuped) по θ, приравненной к 0):
Тогда:
Учитывая, что коэффициент корреляции двух переменных:
Дисперсия новой метрики:
В формуле оценки дисперсии CUPED-метрики присутствует квадрат коэффициента корреляции между целевой метрикой и дополнительной случайной величиной, то есть чем больше коррелирует наша целевая метрика с дополнительной величиной X, тем меньше дисперсия у новой CUPED-метрики. В качестве X могут использоваться различные величины, коррелирующие с Y, но, как правило, в качестве X берут исторические значения метрики Y, что позволяет учесть сразу несколько постоянных факторов, влияющих на метрику.
Так как мы сделали стратификацию по признаку наличия карты лояльности у клиентов (а по карте лояльности можно получить информацию о предыдущих покупках), мы можем использовать CUPED совместно со стратифицированным сэмплированием. Это может значительно уменьшить дисперсию, соответственно, и необходимую длительность АБ-тестирования.
Посмотрим значения дисперсий в стратах:

Видно, что дисперсия Check_Amount у клиентов с картой лояльности во много раз превышает дисперсию суммы чеков для клиентов без карты, уменьшив дисперсию в страте «лояльных» клиентов, мы сможем понизить и общую дисперсию. Учитывая то, что для клиентов, имеющих карту лояльности у нас есть история покупок, мы можем применить метод CUPED и получить новую метрику с меньшей дисперсией для данной страты.
Классическим подходом является проставление константного значения в качестве X для данных без истории, но в нашем случае мы выполним переход к новой метрики только для страты клиентов с историей, это связано с тем, что ковариация в формуле новой метрики рассчитывается для всех данных по Y и X, а в наших данных в некоторых случаях Y может равняться одному и тому же значению (например, в случае пустых покупок, когда клиент пришел в магазин, но ничего не купил, его чек будет равен 0). Из-за подобных случаев может сдвинуться общее значение ковариации, поэтому для сохранения принципа стратификации более «тонким» подходом в данном случае является применение CUPED только к страте клиентов с картой лояльности.
В качестве возможных ковариат были выбраны:
• средняя сумма покупки за данный месяц по данной карте лояльности в предыдущем году (Y_prev_year);
• средняя сумма покупки по данной карте лояльности за ближайший к данному месяцу в предыдущем году месяц (Y_prev_year_ffill);
• последнее значение суммы покупки на историческом периоде для данной карты лояльности (Y_prev_period_last_value);
• среднее значение суммы покупки с данной картой лояльности за исторический период (Y_prev_period_mean_value).
В итоге мы получили матрицу корреляций, из которой видно, что наиболее предпочтительной является ковариата: среднее значение суммы покупки с данной картой лояльности за исторический период с коэффициентом корреляцией 0.54.

К целевой метрике и выбранной ковариате в страте клиентов с картой лояльности была применена формула для перехода к новой метрике-CUPED.
Построим графики исходной метрики и новой метрики для покупок с картой лояльности:


Дисперсия метрики в страте «лояльных» клиентов с применением CUPED уменьшилась с 13768930.5 до 9774430.9, при этом оценка среднего значения осталась той же 3524.58.
По известной формуле посчитаем продолжительность тестирования для тех же параметров при использовании стратифицированного сэмплирования и CUPED-метрики в страте клиентов с карточкой лояльности.
Out[]: Продолжительность теста со стратификацией и CUPED (в днях): 24Таким образом, суммарно нам удалось уменьшить продолжительность АБ-теста в два раза (с 48 до 24 дней).
Итак, мы рассчитали необходимую длительность теста, теперь можем переходить непосредственно к оценке эффекта от введения робота-консультанта.
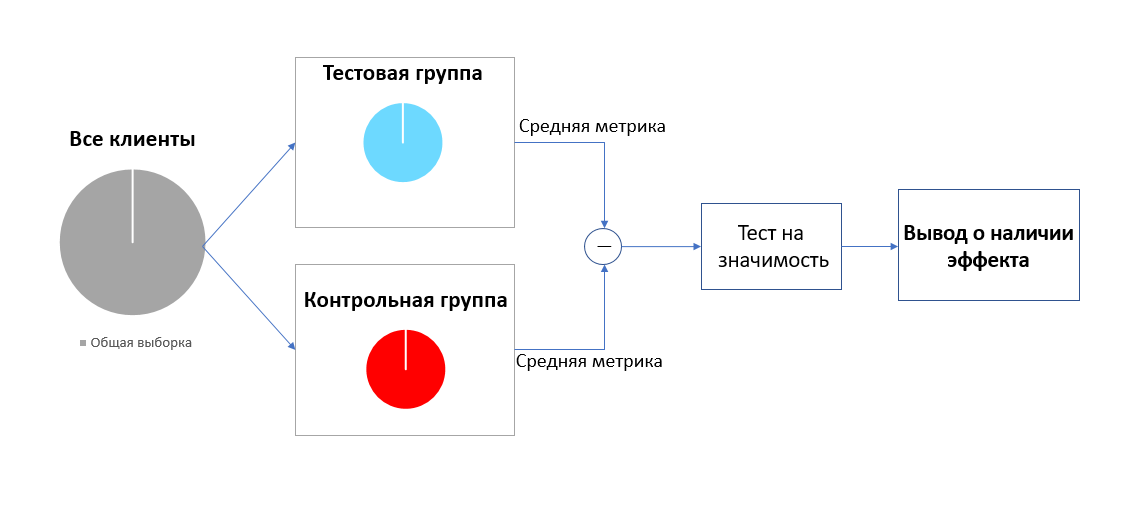
В первом случае АБ-тестирование длилось 48 дней, робот совершенно случайным образом (без распознавания пола, возраста и т.п.) подъезжал к клиентам и предлагал им продукты. После чего на основе данных с камер наблюдений и времени выдачи чека из базы данных были соотнесены две группы: покупки, совершенные после консультации робота и покупки, совершенные без консультации робота, то есть тестовая и контрольная группы. Согласно пайплайну классического АБ-тестирования, изображённого ниже, нам необходимо рассчитать разницу целевой метрики (Check_Amount) между тестовой и контрольной выборкой и проверить значимость найденного значения.
Рассчитаем разницу между средними значениями двух групп:
check_mean_test = data_test[data_test['Group_type'] == 'Test']['Check_Amount'].mean()
check_mean_control = data_test[data_test['Group_type'] == 'Control']['Check_Amount'].mean()
effect_Check_Amount = check_mean_test - check_mean_controlВ итоге мы получили оценку эффекта в 109.19 рубля, что составляет 6.8% от средней суммы чека до введения робота-консультанта в магазин. После проверки полученного результата на значимость был сделан вывод, что данное значение действительно является статистически значимым эффектом.
Другая версия тестирования – со стратификацией клиентов, совершающих покупки, по признаку наличия карты лояльности. В этом случае наш робот должен уметь определять людей с картой лояльности и без нее (это можно реализовать при помощи системы распознавания лиц и фото клиента из базы данных карточек) и подъезжать к людям для консультирования с такой частотой, чтобы сохранялись пропорции страт, определенные на этапе до начала эксперимента. При этом наш тест длился 33 дня.
Сформировав тестовую и контрольную группы вышеописанным методом, нам необходимо, как и в случае с классическим АБ-тестированием, посчитать разницу между средними значениями и проверить его статистическую значимость.
Ниже изображен пайплайн АБ-тестирования со стратификацией:

В результате расчетов мы получили статистически значимый эффект равный 110.63.
Можно заметить, что при случайном сэмплировании, как и при стратификации были сформированы сопоставимые однородные тестовая и контрольная группы, в которых доля присутствия страт сохранилась примерно такой же, как и в общей выборке.


В случае классического АБ-тестирования сохранение долей страт было достигнуто за счет большого количества данных, а в случае применения стратификации это произошло из-за контроля попадания покупки определенной страты в ту или иную группу, при этом нам понадобилось меньшее количество дней для формирования однородных групп.
Еще одним вариантом нашего теста является применение CUPED в одной из страт после стратифицированного сэмплирования. В этом случае наш робот настроен точно таким же образом, как и в предыдущей версии эксперимента, отличие заключается в обработке данных полученных групп.
После формирования данных по группам, нам необходимо выполнить переход к новой метрики, для этого использовалась наиболее коррелируемая переменная, определенная на доэксперементальном этапе – среднее значение Check_Amount за исторический период. Переход к новой метрике осуществлялся только для страты покупок с карточкой лояльности по методике аналогичной примененной в расчете длительности теста. Важно заметить, что при переходе к новой метрики в случаи наличия групп необходимо применять CUPED отдельно по группам.
Пайплайн тестирования со стратификацией и CUPED для одной из страт показан ниже:

После вычисления разницы между средними значениями метрики тестовой и контрольной группы мы получили статистически значимый результат 109.24 рубля.
Таким образом, мы выполнили расчет эффекта тремя методами АБ-тестирования разной продолжительности. В результате были получены примерно одинаковые оценки эффекта от внедрения проекта.
Но что делать, если у нас нет камер с функцией распознавания лиц и мы не можем точно определить – консультировал ли робот клиента, чек которого мы анализируем. То есть у нас нет возможности распределить покупки в тестовую и контрольную группу.
В этом случае классическая постановка гипотезы АБ-тестирования не подходит, так как у нас нет групп, среднее значение которых мы могли бы сравнить, поэтому необходимо сформулировать другую гипотезу.
В случае, когда нет возможности распределить клиентов по группам, необходимо учитывать воздействие других факторов (вектор X), которые могли повлиять на изменение метрики до и после введения изменения, причем набор Х и функция зависимости метрики от Х не известны.
Метрика до эксперимента определена случайной величиной A:
A1, A2, ..., At – наблюдения A, ε – случайный шум.
Метрика после введения изменения определена случайной величиной B:
B1, B2, ..., Bt – наблюдения B.
По итогу эксперимента необходимо сравнить оценку значения, полученного во время эксперимента и оценку значения, если бы мы не ввели робота-консультанта:
Для наблюдаемых значений:
est() – несмещенная оценка.
Проблема заключается в «what-if»-оценке, так как мы не наблюдали значения F(X) для Xi, i>t.
Существует несколько методов для оценки значения метрики «если бы изменения не произошло». Попробуем применить их для решения нашей задачи.
Когда нет никакой возможности выделить контрольную группу, а также есть предположение о наличии факторов, которые объясняют изменение метрики во времени (кроме введенного изменения) для оценки эффекта, может быть применен метод альтернативного прогнозирования. При использовании данного подхода строится модель, связывающая метрику до эксперимента и факторы, которые могли повлиять на эту метрику во времени. После чего на основе этой модели прогнозируются значения метрики на период после начала эксперимента, затем сравниваются наблюдаемое значение метрики и прогнозируемое, на основе этого оценивается эффект.

Перейдем к примеру введения робота-консультанта с тем же набором предэкспериментальных данных, что и в кейсе с возможностью создания тестовой и контрольной групп в дальнейшем.
В нашем случае мы можем сделать предположение о том, что дата покупки влияет на сумму среднего чека в эту дату, то есть мы предполагаем, что в среднем, например, сумма покупки в выходные дни отличается от суммы покупки в будни, а сумма покупки в конце декабря отличается от суммы покупки в конце ноября (т.к. люди готовятся к Новому году). Если наши предположения подтвердятся и в данных до начала эксперимента действительно присутствуют сезонности, то задачу моделирования и прогнозирования можно будет свести к time series forecasting.
Проверим наличие сезонной компоненты в зависимости от дня недели. Для это найдем среднее значение Check_Amount по каждому дню, разложим временной ряд на тренд, сезонность и остатки (при помощи библиотеки statsmodels):
import statsmodels.api as sm
data_by_day = data.groupby('date')['Check_Amount'].mean()
data_by_day_decompose = sm.tsa.seasonal_decompose(data_by_day, model='additive')
data_by_day_seasonality = data_by_day_decompose.seasonalВизуализируем сезонную компоненту, заменив дату на наименование дня недели ей соответствующего:

Видно, что в данных до начала эксперимента присутствует сезонность в зависимости от дня недели: пик среднего чека покупок приходится на пятницу-субботу. В воскресенье люди меньше всего тратят деньги в данном магазине.
Для анализа сезонности в зависимости от месяца в году у нас недостаточно данных (т.к. нам предоставили данные по покупкам до проведения эксперимента с января 2022 по июнь 2023, т.е. мы имеем только 1 полный год). Но мы можем оценить присутствие сезонности внутри года по косвенным признакам, например, при помощи визуального анализа графика суммы чека покупок по месяцам.
Найдем среднее значение Check_Amount для каждого месяца.
data_by_month = data[['date', 'Check_Amount']] \
.groupby(pd.Grouper(key='date', freq='1M')).mean().reset_index()
По графику можно заметить ряд совпадающих паттернов поведения среднего значения Check_Amount в январе-июне 2022 и 2023 года.
Таким образом, можно сделать вывод, что наше предположение о влиянии временно́й компоненты на среднее значение Check_Amount подтвердилось. Это означает, что для построения модели Check_Amount до введения робота-консультанта и дальнейшего прогнозирования величины «Check_Amount (если бы проект не был введен» на период тестирования), мы можем использовать модели прогнозирования временных рядов.
Одной из эффективных моделей прогнозирования временных рядов является ARIMA (autoregressive integrated moving average). ARIMA-модель учитывает взаимосвязь между текущим значением ряда и его прошлыми значениями, а также возможные тренды и сезонность. Она представляет собой комбинацию трех компонентов: авторегрессионной (AR), интегрированной (I) и скользящей средней (MA). Это позволяет учитывать как предыдущие значения ряда, так и ошибки предсказаний.
Для выбранной ARIMA были подобраны гиперпараметры таким образом, чтобы после обучения на доэксперементальных данных модель выполняла predict на уровне дня с хорошей точностью.
from statsmodels.tsa.arima.model import ARIMA
model_arima = ARIMA(data_by_day['Check_Amount'], order = (7, 0, 30))
modelfit_arima = model_arima.fit()Качество прогнозирования модели было оценено с помощью метрики R2. На доэксперементальных данных качество прогнозирование ARIMA составляет 0.826, что является достаточно неплохим результатом.
Из графика видно, что в целом модель смогла уловить сезонности покупок:

Таким образом, мы получили модель, характеризующую в среднем поведение клиентов в зависимости от даты покупки без введения изменений, и можем использовать ее при оценке эффекта от внедрения робота-консультанта.
В данном случае, робот был настроен также, как при классическом АБ-тесте со случайным сэмплированием. Тест продолжался 48 дней и в итоге мы получили данные, содержащие обычные покупки и покупки, выполненные после рекомендации робота. Но у нас нет информации о том, в каких именно случаях покупка была совершена после консультации робота.
Определим среднее значение Check_Amount по дням в данных, полученных после окончания теста. Затем выполним прогнозирование на основе модели ARIMA, подобранной и обученной на доэксперементальном периоде и сравним полученные результаты:

Затем необходимо вычислить разницу между средними наблюдаемых значений и значений, полученных по модели, характеризующей покупки без введения робота-консультанта. В результате расчетов мы получили значение разности, равное 70.61 рублей.
Проиллюстрируем оценку эффекта на уровне месяца методом альтернативного прогнозирования:

70.61 рублей – это оценка в среднем в день для того, чтобы сравнить данное значение с оценкой эффекта суммы чека за покупку (109.19 рублей), определенной в ходе классического АБ-тестирования, когда известно к тестовой или контрольной группе относится покупка, необходимо агрегировать эти результаты АБ-теста также по дням. При этом из особенностей проведения АБ-теста ясно, что эффект в 109.19 рублей присутствует только в тестовой группе, а в контрольной группе оценка эффекта равна 0. Усредняя найденный эффект по датам, получим средний результат – 54.46 рубля. То есть с использованием АБ-тестирования мы получили оценку среднедневного эффекта, равную 54.46 рубля, а применяя альтернативное прогнозирование на аналогичных данных, но без информации о попадании покупки в тестовую или контрольную группу, вычисленная оценка равна 70.61 рублей.
Мы получили неплохой результат, однако метод альтернативного контроля не позволяет точно оценить эффект при возникновении экстремальных событий (например, начало пандемии, резкий рост инфляции и т.п.).
В случае, когда у нас есть несколько неподверженных изменению выборок и выборка данных, которая характеризует объект с изменениями, мы можем использовать метод синтетического контроля. Суть данного метода заключается в моделировании контрольной группы путем взвешенного комбинирования нескольких неподверженных воздействию объектов, уже существующих в данных.
Для оценки эффекта от введения робота-консультанта в одном из магазинов методом синтетического контроля мы можем подгрузить данные из трех других филиалов этого магазина, где не был применен данный проект. Идея метода синтетического контроля основана на том, что на все магазины примерно одинаково (но с разными весами) действуют различные внешние факторы (финансовый, эпидемиологический и т.д.). Определив соотношение между средним чеком в магазине, где планируется введение нового проекта консультирования и магазинами, в которых не будет нововведений, мы можем использовать это соотношение на период проведения тестирования. Создав синтетические данные «целевой магазин в период работы робота-консультанта», «если бы робота-консультанта не было», по информации о поведении клиентов в магазинах, где не было изменений, и сравнить наблюдаемую сумму чека и сумму чека в синтетических данных.

С точки зрения математики при использовании синтетического контроля до проведения эксперимента подбирается модель:
где:
• Ῠpre – наблюдаемые значения целевой метрики объекта, где планируется изменение;
• Ypre – наблюдаемые значения целевой метрики объектов, где не планируется изменение;
• ki – подобранные коэффициенты.
Таким образом, строится зависимость целевой метрики объекта, где планируется изменение, но изменение еще не введено от значений целевой метрики объектов, где не планируется изменение. После введения изменения найденные коэффициенты и наблюдаемые величины объектов, не подверженных изменению, используется для характеристики целевой метрики объекта с изменением, если бы его не было:
где:
• Ῠpost – ненаблюдаемые значения метрики объекта «если бы изменения не было» на периоде проведения теста нового проекта;
• Ypost – наблюдаемые значения целевой метрики объектов, где не был внедрен новый проект на период теста.
При использования метода синтетического контроля на весовые коэффициенты накладываются дополнительные ограничения: в случае, если есть объекты с большей и меньшей метрикой, чем у объекта с изменением, то необходимо ограничивать веса Σki = 1,
ki >=0. Если же таких объектов нет, то применяют LASSO-регуляризацию для оценки весов ki >=0. Это связано с интерпретируемостью метода и мультиколлеарностью регрессоров.
Попробуем использовать метод синтетического контроля для оценки эффекта от введения робота-консультанта без информации о том, какие именно покупки были выполнены после консультации. Для этого выгрузим из базы данных информацию о покупках в трех других магазинах, где не планируется введение нового проекта консультирования. Выделим для всех магазинов Check_Amount и посчитаем среднее значение данной метрики на каждый день для всех магазинов по-отдельности. Это позволяет представить данные как панельный датафрейм, где store_1, store_2, store_3 – магазины, в которых не планируется введение робота-консультанта. Target_store – целевой магазин, в котором в июле будет внедрен робот-консультант.

Теперь нам необходимо подобрать весовые коэффициенты таким образом, чтобы взвешенная сумма store_1, store_2, store_3 отражала средний чек target_store. Также нам необходимо учитывать ограничения коэффициентов, описанные выше. В нашем случае магазины store_1, store_2, store_3, target_store располагаются в разных районах, поэтому есть магазины, в которых среднее значения Check_Amount превышают аналогичные значения в target_store и магазин, где целевая метрика в среднем меньше, чем в интересующем нас, поэтому используем ограничения весов: Σki = 1, ki >=0. Разделим значения целевой метрики магазинов следующем образом: y = target_store, X = [store_1, store_2, store_3]. Для определения коэффициентов с ограничениями, используем функцию minimize из пакета scipy.optimize. Выполним начальную инициализацию весовых коэффициентов случайными значениями, после чего, будем их изменять таким образом, чтобы функция потерь, отражающая разницу между получаемыми и желаемыми результатами модели, стремилась к минимуму с учетом двух ограничений коэффициентов, оформленных в виде логических выражений.
from scipy.optimize import minimize
def pred_synthetic(x, coef):
return np.dot(x, coef)
# Функция потерь
def loss_function(weights, X, y):
y_pred = pred_synthetic(X, weights)
loss = (1/len(X))*np.sum((y_pred - y)**2)
return loss
# Функция ограничения (сумма коэф = 1)
def constraint_sum_coef(params):
return np.sum(params) - 1
# Функция ограничения (положительность коэф)
def constraint_positive_coef(params):
return 1 - (any(params)<0)
#начальная инициализация коэффициентов случайными значениями
initial_params = np.random.rand(X.shape[1])
# Ограничения
constraints = [{'type': 'eq', 'fun': constraint_sum_coef},
{'type': 'ineq', 'fun': constraint_positive_coef}]
# Минимизируем функцию потерь с ограничением
model_synthetic = minimize(loss_function,
initial_params,
args=(X, y),
constraints=constraints)В результате выполнения кода, мы получили следующие коэффициенты:
Out[]: Coefficients: [0.21026726 0.51584009 0.27389265]Используя найденные коэффициенты и наблюдаемые величины среднего Check_Amount в день в магазинах store_1, store_2, store_3 мы можем создать синтетические значения среднего Check_Amount в интересующем нас магазине target_store.
Посмотрим, как соотносятся реальные и синтетические данные на доэкспериментальном периоде:

По прошествии 48 дней тестирования мы можем применить полученную модель для оценки эффекта от внедрения робота-консультанта методом синтетического контроля.
Построим график наблюдаемых и синтетических значений целевой метрики после получения итоговых данных тестирования:

В среднем дневная разница суммы чека в данных после введения робота-консультанта и в смоделированных данных отличается на 66.47 рублей – это и есть оценка эффекта методом синтетического контроля.
В ряде работ предлагается использовать тест на перестановку (определение синтетических значений для всех объектов и сравнение их отклонений от наблюдаемых величин на этапе введения изменения) для доказательства того, что разница между средними наблюдаемых и синтетических значений в целевом магазине является не случайным шумом, а обусловлена изменениями. Однако в данном случае мы имеем слишком мало регрессоров для использования этого подхода. Если мы будем использовать значения target_store в качестве одного из регрессоров синтетической модели другого магазина, то при таком небольшом количестве других параметров модели, наблюдаемые значения метрики target_store окажут сильное влияние на синтетические значения моделируемого магазина. Учитывая, что мы предполагаем, что значения в target_store меняются в период теста, то и зависимые от них синтетические данные другого моделируемого магазина тоже будут сильно изменяться и отклоняться от наблюдаемых величин в этом магазине, что может привести к неверным выводам. Также при использовании данного подхода отбрасываются объекты, имеющие наибольшую и наименьшую целевую метрику. Чтобы показать, что разница между средними значениями обусловлена именно введенным проектом, а не ошибкой модели, сравним среднюю разницу между наблюдаемыми и синтетическими значениями на предтестовом и тестовом периодах:

До введения робота-консультанта синтетические значения Check_Amount в среднем на 5.41 рублей превышали наблюдаемые значения, а после введения данного проекта наблюдаемая метрика Check_Amount стала на 66.48 рублей превышать синтетические значения. Учитывая, что в магазинах store_1, store_2, store_3 не было введено никаких изменений и средняя сумма покупок в день в них зависела от тех же факторов, что и до теста проекта, можно сделать вывод, что разница в 66.48 рублей связана именно с использованием робота-консультанта в магазине target_store.
Результат, полученный методом синтетического контроля, ближе к оценке эффекта, рассчитанной по классическому АБ-тесту с известными контрольными и тестовыми группами, чем альтернативное прогнозирование.
Еще одним методом оценки эффекта от проекта с использованием сторонних данных является мэтчинг. При использовании данного подхода оценка эффекта происходит путём сопоставления метрики объекта после введения изменения и метрики максимально похожего на него по различным признакам объекта из совокупности данных, не подверженных влиянию проекта.

Рассмотрим применение мэтчинга для определения эффекта от внедрения робота-консультанта в магазине, используя данные из трех магазинов, где никаких изменений не происходило. Здесь целесообразно исследовать только выборку покупок, в которых использовалась карта лояльности, так как для покупок без карты у нас слишком мало характеристик для сравнения. В этом случае мы считаем, что наш проект повлиял на клиентов без карты лояльности так же, как и на клиентов, имеющих такую карту. То есть мы будем сравнивать покупки из магазина с изменением target_store и магазинов без изменения, предполагая, что помимо проекта консультирования на чек покупки влияют и другие факторы. При минимизации разницы этих факторов в объектах тестовой и набранной (псевдослучайной) контрольной группах мы можем с большей точностью обнаружить «величину влияния» нашего проекта. Из особенностей данного метода ясно, что нам не обязательно знать, подвергся ли конкретный объект из тестовой группы (target_store) влиянию, так как сравнивая покупку из target_store клиента, которого не консультировал робот с покупкой, имеющей аналогичные характеристики, но из магазина без введения изменений, мы получим оценку эффекта, равную нулю. Сезонная компонента также влияет на сумму чека покупки, поэтому для сравнения необходимо использовать покупки из магазинов, где не были введены изменения, совершенные в период введения робота-консультанта в интересующем нас магазине. В данном случае, мы будем сравнивать покупки на индивидуальном уровне, поэтому нет смысла агрегировать данные по дням, переходить к временным рядам как в методах альтернативного прогнозирования и синтетического контроля. Соответственно, оценку эффекта мы получим в среднем на покупку.
Для оценки эффекта от введения робота-консультанта используем класс CausalModel из библиотеки causalinference. В качестве параметров сопоставления покупок были выбраны две характеристики времени покупки (день недели, период дня) и две характеристики клиента, совершившего покупку (пол, возраст). Предварительно данные всех магазинов были объединены в один датафрейм, после чего для магазина с роботом-консультантом был установлен бинарный флаг Target=1, а для других магазинов Target=0 категориальные параметры были перекодированы в численные для использования CausalModel, после чего был вызван метод класса est_via_matching.
from causalinference import CausalModel
cm = CausalModel(
Y = data_test_matching_all_store["Check_Amount"].values,
D = data_test_matching_all_store["Target"].values,
X = data_test_matching_all_store [["Code_Gender",
"Code_Time",
"Code_Weekday",
"Age"]].values
)
cm.est_via_matching(bias_adj=False)Для отображения принципа работы мэтчинга «поверх» CausalModel была написана функция, позволяющая визуализировать сопоставляемые пары покупок. В таблице ниже в левой части показаны покупки из магазина с роботом-консультантом, а в правой части подобранные для каждой покупки на индивидуальном уровне пары из магазинов, где изменений не было. Видно, что при совпадении параметров покупки суммы чеков в левой и правой части таблицы отличаются.
Параметры покупок из магазина с введением нового проекта |
Параметры подобранных покупок из магазинов, где изменений не произошло |

Результатом работы кода библиотеки causalinference является вывод значений ATE, ATC и ATT. Нас интересует эффект в тестовой группе, поэтому рассмотрим только значение ATT, которое составляет 132.83. Этот эффект является статистически значимым на уровне P>|z| = 0.021.
Подводя итоги, следует отметить, что оценка эффекта от внедрения проекта является комплексной задачей, требующей индивидуального подхода. В данной статье мы рассмотрели и применили шесть математических методов определения эффекта, а ниже привели сравнительную таблицу. Направление Data Science в компании Neoflex непрерывно исследует методы анализа данных и машинного обучения для применения и развития различных методик определения эффекта от внедрения проекта.
АБ-тест |
Стратификация |
CUPED |
Альтернативное прогнозирование |
Синтетический контроль |
Мэтчинг |
|
Оценка эффекта от проекта в среднем за покупку |
109.19 |
110.63 |
109.24 |
|
|
132.83 |
Применение |
Оценка эффекта от внедрения проекта, когда возможно случайное разделение объектов на тестовую и контрольную группу |
Повышение чувствительности АБ-теста, снижение кол-ва необходимых данных |
Повышение чувствительности АБ-теста, снижение кол-ва необходимых данных |
Оценка эффекта при отсутствии возможности определения объектов, подверженных влиянию изменений |
Создание объектов для сравнения, когда определение объектов, подверженных влиянию изменений, затруднительно или невозможно |
Формирование группы объектов для сравнения, когда определение объектов, подверженных влиянию изменений, затруднительно или невозможно |
Суть |
Объекты разделяют на две группы: контрольную и тестовую. В Контрольной группе действует процесс без изменений, а в тестовой внедряется новый проект, после чего сравниваются целевые метрики для этих двух групп на основе чего и оценивается эффект от изменений проекта |
Разделение объектов на кластеры перед проведением АБ-теста. Характеристики по котором происходит разделение должны коррелировать с целевой метрикой, но не зависеть от исхода эксперимента |
Использование данных, полученных до АБ-теста, и, полученных во время теста |
Моделирование контрольной метрики на основе различных факторов до начала теста и ее прогнозирование на период теста |
Создание синтетической контрольной группы, не существующей в реальности, но агрегирующей данные без введения проекта |
Создание контрольной и тестовой группы на основе схожих характеристик объектов |
Плюсы |
Простота реализации и интерпретации результатов |
Учёт разнородности объектов. Интерпретируемость результатов |
Учёт влияния внешних постоянных факторов. Наличие исторических данных упрощает подготовку к эксперименту |
Осуществим без необходимости дополнительных данных и альтернативных групп |
Позволяет учитывать большое количество факторов и переменных при оценке эффекта. Может использоваться, когда нет большого количества информации об объектах на индивидуальном уровне. |
Позволяет снизить потерю точности при формировании контрольной и тестовой групп. Прост в понимании и применении. |
Минусы |
Может потребоваться большое кол-во данных |
Сложность осуществления (при большом наборе характеристик и высокой степени их разброса). Необходимость доступа к дополнительной информации об объектах. |
Объекты должны иметь исторические данные |
Рассчитанная оценка эффекта может быть связан не с введенным изменением, а с факторами, не учтёнными в модели. Необходимость доп. исследований и feature engineering, что может быть трудоемким и времязатратным процессом. |
Необходимость наличия панельных данных. Процесс осуществления может быть трудоемким и времязатратным. Имеет |
Необходимость проведения дополнительного анализа характеристик объектов. Сложность осуществления (при большом наборе характеристик и высокой степени их разброса). Необходимость доступа к дополнительной информации об объектах |