
Сегодня я расскажу про hippotable — удобный инструмент для анализа данных, который я сделал для себя и для людей.
Я люблю ковыряться в данных. Иногда станет интересно, в какой области больше всего городов, так аж кушать не могу, пока не выясню (как легко догадаться, в Московской, но потом в Свердловской). А на работе мне иногда удаётся совместить приятное с полезным: о нет, вижу ошибку в логах! Из каких браузеров она летит?
Но чем простому парню вроде меня поковыряться в данных? Есть 3 варианта, но все они так себе:
bash. Я могу нашлепать что-то вроде
cat user-ids.csv | sort | uniq | wc -cдля подсчета уникальных пользователей с багом. Если вопрос чуть сложнее (посчитать распределение по платформам), начинаются проблемы — будем честны, настоящих мастеров баша мало.Google sheets & co на вид хорошо подходят для задачи — много статистических функций, графики, все удобно и интерактивно. Но есть две беды: много ненужных функций (зачем мне ручное форматирование?) и сложность работы с несколькими таблицами (если вы пробовали поджойнтить таблицы через VLOOKUP, вы понимаете, о чем я). У онлайн-решений ещё проблемы с конфиденциальностью, не отправлять же данные пользователей на сервер гугла.
Pandas / jupyter — отличный инструмент для анализа, но нужно писать много кода. Мои задачи довольно простые, мне вполне подойдет что попроще.
Этой осенью я поступил в магистратуру и мне нужно было придумать курсовой дата-проект. Отличный повод решить мою проблему! Получился hippotable — удобный инструмент для ковыряния в небольших данных. Сегодня я объясню как этот инструмент работает, покажу пример использования, и расскажу о дальнейшем развитии продукта.
Делаем сами
Чего я желаю от инструмента для анализа данных?
Открывать довольно большие файлы (до 100 Мб).
Сортировки и фильтры.
Агрегации — без них не получится ответить на многие вопросы.
Работает в браузере, чтобы я мог поковыряться в данных хоть с компьютера, хоть с телефона, не устанавливая никаких программ.
Не отправляет данные на сервер, чтобы можно было работать с конфиденциальными данными, и заодно сэкономить на передаче по сети.
Удобная таблица для просмотра данных со скроллом, автоматической шириной столбца и вообще отличным UX.
Графики, чтобы видеть закономерности глазами.
Теперь подберем инструменты, которые нам понадобятся. Это UI-фреймворк для отрисовки интерфейса и мощный dataframe-движок (я уже делал эффективное column-based хранилище на JS, боьше не хочется).
С UI определился быстро — давно хотел попробовать solidjs, и вот подвернулся шанс. По бенчмаркам солид в топе, на уровне ванильного JS. Синтетические бенчмарки ругают за то, что в них тестируют отрисовку большой таблицы, а это же не типичное приложение, но вот удача — мое приложение по сути и есть большая таблица! Не жалуюсь, работает правда быстро.
С датафреймом интереснее. Есть два вида решений: классические JS-бибилиотеки (arquero, danfo.js) и wasm-сборки in-memory СУБД (SQLite, DuckDB). wasm-сборки работают быстрее, но грузятся дольше. В итоге я решил использовать традиционный JS, чтобы не закапываться в wasm и асинхронность, а из двух библиотек выбрал arquero — он лучше по бенчмаркам, и по репозиторию видно, что продукт развивается. Скорости вполне хватает — можно работать с датасетами на миллионы строк. Но тут я сомневаюсь в выборе: SQL — популярный язык, и на нем пользователям проще писать мощные запросы. На будущее оставлю возможность подмены дата-бекенда на DuckDB (у нас же OLAP, duck как раз для этого и сделан).
Про саму разработку рассказать особо нечего. Дедлайн в январе помог за 8 суббот нашлепать простую первую версию, которая уже помогает мне в работе и по жизни.
Пользуемся
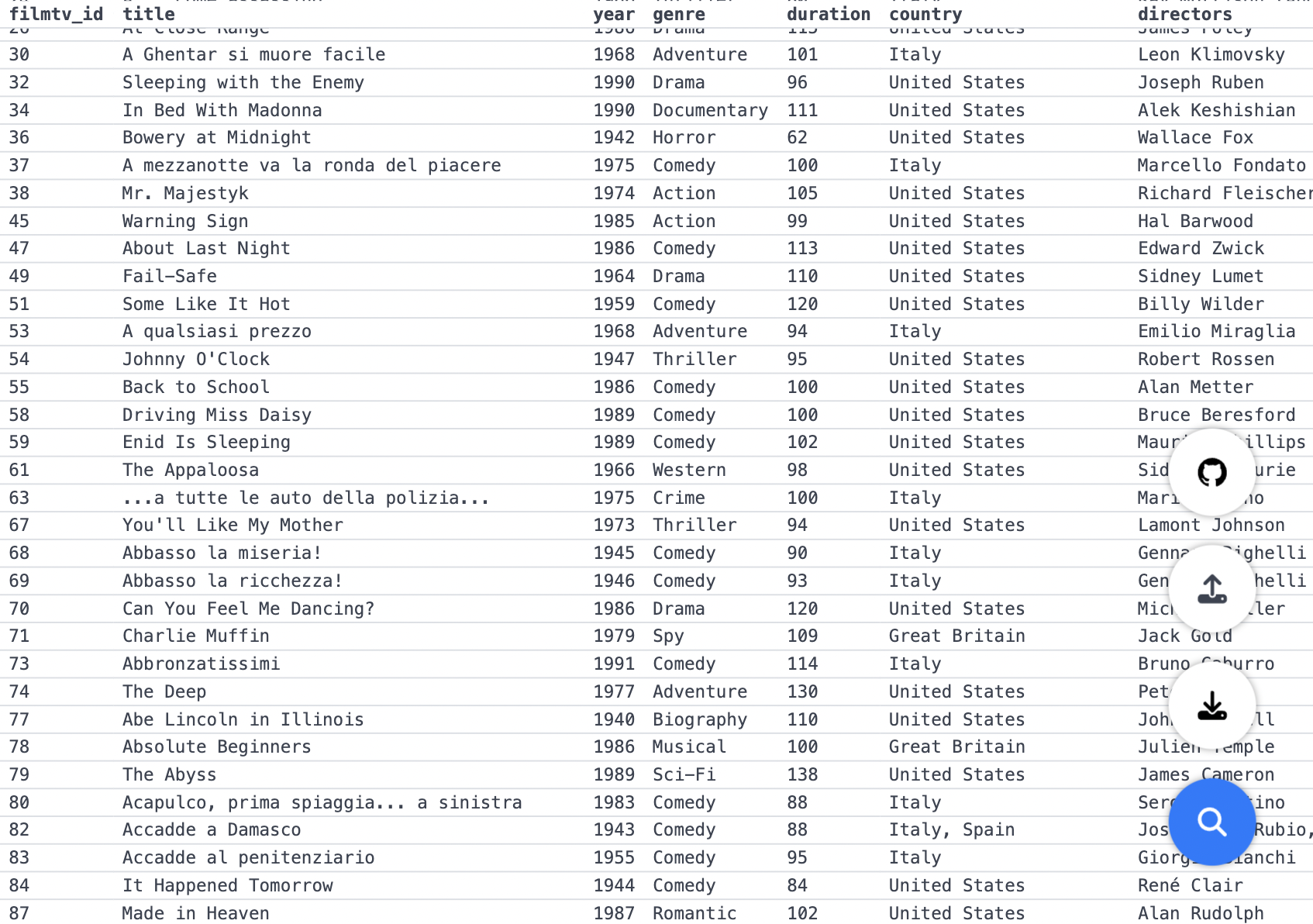
Сейчас покажу небольшой пример использования hippotable на демо-датасете с kaggle — наборе 40К+ фильмов с оценками. Если интересно, можете сами воспроизвести мой анализ.
Начнем с простого — в какой стране, в среднем, снимают фильмы с лучшими оценками? Группируем по стране, сортируем по средней оценке:

Упс, мы нашли экзотические комбинации стран, которые однажды вместе сняли неплохой фильм — не совсем то, что мы хотели. Оставим только страны с выборкой из более 10 фильмов:

Неожиданно. Кстати, если любопытно — худшие фильмы, в среднем, снимали в Италии:

Слои фильтрации и агрегации можно чередовать, чтобы строить более сложные пайплайны. Например, страны, в которых больше всего режиссеров снимали неплохие фильмы:

Что же дальше
Чтобы не затягивать разработку первой версии, я оторвал много полезных фичей. Сейчас расскажу, в какую сторону хочется развивать продукт.
Импорт. Главная цель — поддержать импорт не только CSV, но и JSON. Это позволит подключать hippotable к данным из API — получится публичный no-code дашборд. Еще можно попробовать импорт xlsx, но боюсь, что будет сложно обработать все форматы, которые люди делают в своих таблицах.
Сохранение пайпланов. Иногда хочется подпихивать разные данные в один и тот же пайплайн — например, я часто считаю число уникальных пользователей или распределение по платформам. Было бы здорово сохранять фильтры и агрегации, а потом просто "загружать" их — для начала локально, но можно подумать и про серверное хранилище (и премиум хранилище, куда можно сложить и данные, и пайплайн, за деньги).
Инструменты анализа. Тут самые большие дыры, просто перечислю: вычислимые столбцы, агрегации с параметром (это квантили), корреляция, дедубликация. Сюда же — работа с несколькими таблицами.
Графики. Что за анализ данных без красивых графиков? Осталось определиться с подходящей библиотекой и продумать UX расположения графиков на экране.
Экспорт. Результатами анализа хочется делиться. Сейчас есть экспорт в CSV — неплохо, но бедновато. В идеале каждой таблицей можно поделиться по ссылке или скачать в HTML, подредактировать и выложить на свой хостинг.
И два направления, которые меня не сильно интересуют:
Поддержка более огромных датасетов. Я люблю самое-самое (самые большие датасеты! самая быстрая обработка!), и это интересная задача (с потоковой обработкой можно загрузить хоть 1 Тб данных), но hippotable уже хорошо работает в районе миллиона строк, и этого вполне достаточно для практических задач.
Продвинутая аналитика с произвольным JS / tensorflowjs и так далее. В первую очередь я делаю удобный браузерный интерфейс для arquero. Если вы мастер программирования, проще напрямую использовать его в своем коде с любой дополнительной обработкой вокруг. Интересный вариант — опубликовать веб-компонент таблицы как npm-пакет, который можно подключать в любое приложение для удобного просмотра данных.
Сегодня я рассказал вам про hippotable — браузерный инструмент для анализа данных. В первой версии уже есть много классного:
Открывайте большие CSV-файлы (сотни мегабайт, миллионы строк).
Удобный и быстрый UI, можно скроллить таблицу даже на телефоне.
Фильтры и сортировка в реальном времени.
Агрегации для анализа данных.
Мощные пайплайны из нескольких слоев фильтров и агрегаций.
Экспорт результата в CSV.
На этом всё! Используйте hippotable, если поставите звездочку на гитхабе — очень мне поможете. Буду держать вас в курсе новостей.
Комментарии (13)

freeExec
27.12.2023 09:17Что-то у меня не заработал "start with" по полю country.
А так классная вещь я думаю, вот только переучиваться с двойного клика по csv когда открывается эксель на что-то иное - тяжело. Так что я подожду внедрения duckdb, чтобы иметь больше мотивации.
thoughtspile Автор
27.12.2023 09:17Спасибо за багрепорт, исправил! Думаю, перед дальнейшим развитием хорошо бы намазать тестов =)
DuckDB мотивирует SQL-синтаксисом или чем-то еще?freeExec
27.12.2023 09:17+2Да, но в большинстве в генерации новых данных, т.е. какие-то формулы над данными и прочее.

economist75
27.12.2023 09:17+1Отлично, +1 и :star:, действительно удобный инструмент для уже нормализованных (очищенных) данных в одной таблице. На эту роль годятся 1С-проводки, логи, журналы итп.
Интерактивная пошаговая агрегация позволяет мыслить "срезами" данных, а всегда доступная сортировка результата дает простой взгляд на существенное и мелкое. Локально, правда, не запустилось, в логе error Missing script: "ci" - но это, полагаю, из-за моего старья Win7/node v16.6.2/npm v7.20.3thoughtspile Автор
27.12.2023 09:17+2Спасибо за отзыв! С локальным запуском мой косяк, имелся в виду
npm ci(без run) — обновил ридми.


dedmagic
27.12.2023 09:17Но чем простому парню вроде меня поковыряться в данных? Есть 3 варианта, но все они так себе
А Yandex DataLens? Мощная и бесплатная BI-система. И ничего кодить не надо :).
thoughtspile Автор
27.12.2023 09:17Интерактивности маловато, на датасете in-memory размера хочется поиграться с параметрами и чтобы таблица менялась в реальном времени.
dedmagic
27.12.2023 09:17Параметры есть, и в реальном времени будет всё меняться. Причём не только таблица, но и куча разных графиков.
thoughtspile Автор
27.12.2023 09:17Хмм, на самом деле не думал про BI системы для этой задачи! Тогда сегментируемся так, hippotable:
Просто использовать: просто открываешь файл и работаешь, не надо плясать с подключениями, датасетами, чартами.
Работает действительно быстро из-за отсутствия клиент-серверности.
Простой деплой on-premises.
Почти неограниченная нагрузка с низкими операционными костами (S3 по цене грязи).
При этом:
Ограниченный размер датасета
Меньше источников данных и интеграций
khailo
А как вы решили проблему джойнов таблиц?
thoughtspile Автор
Пока никак =) На слое данных это не проблема, в arquero есть полный комплект джойнов, но много интерфейсной работы (переключение таблиц, мульти-табличные пайплайны и всё такое). Задача в топе на развитие.