
Несмотря на избитость темы и многочисленные рекомендации избегать OR в выражениях WHERE/ON SQL запросов, жизнь вносит свои коррективы. Иногда сама постановка задачи подразумевает необходимость использовать OR. Я не собираюсь здесь рассматривать простые случаи, а сразу возьму быка за рога и рассмотрю случай, когда OR должно привести к двум разным выборкам по разным индексам одной и той же таблицы. Для лучшего понимания, пример будет сильно упрощен. Ровно до того предела, пока проявляется суть проблемы. Ну а для того, чтобы заинтересовать больше аудитории, так же проведу сравнение поведения планировщиков запросов в MS SQL и PostgreSQL при решении проблемы выборки по двум разным индексам одной и той же таблицы.
Пусть у нас имеется следующая таблица в PostgreSQL:
CREATE TABLE tmp_tmp (
ID int PRIMARY KEY,
SessionId int NOT NULL,
Val int NOT NULL,
IsValidated boolean NOT NULL
);и аналогичная ей в MS SQL:
CREATE TABLE tmp_tmp (
ID int PRIMARY KEY,
SessionId int NOT NULL,
Val int NOT NULL,
IsValidated bit NOT NULL
)Разница тут не только в том, что в MS SQL вместо логического типа boolean приходится использовать тип bit. Разница ещё в том, что в MS SQL первичный ключ по ID будет создан кластерным. А в PostgreSQL кластерных индексов нет и первичный ключ не будет иметь никаких приоритетов перед остальными индексами.
Заполним таблицу тестовыми данными в PostgreSQL:
INSERT INTO tmp_tmp(ID, SessionId, Val, IsValidated)
SELECT G.n AS ID,
G.n%100 AS SessionId,
G.n%1000 AS Val,
((G.n/1000)%2)::boolean AS IsValidated
FROM generate_series(1,1000000) G(n);и в MS SQL:
INSERT INTO tmp_tmp(ID, SessionId, Val, IsValidated)
SELECT N.number+T.number*1000 AS ID,
N.number%100 AS SessionId,
N.number%1000 AS Val,
(T.number%2) AS IsValidated
FROM master.dbo.spt_values T
JOIN master.dbo.spt_values N ON N.type='P'
AND N.number BETWEEN 1 AND 1000
WHERE T.type='P'
AND T.number BETWEEN 0 AND 999Почему не GENERATE_SERIES()?
Я в курсе, что MS SQL 2022 появилась табличная функция GENERATE_SERIES(), но так как её не было в предыдущих версиях, которых еще не мало в эксплуатации, то я не стал её использовать в примере. К тому же на суть проблемы это совершенно не влияет. Зато примеры будут работоспособны даже MS SQL 2016. Если кому-то не нравится использование master.dbo.spt_values для генерации последовательного ряда натуральных чисел - готов обсудить это в комментариях.
Ну а теперь создадим два разных индекса для демонстрации проблемы. В PostgreSQL:
CREATE INDEX tmp_tmp_IsValidated
ON tmp_tmp (SessionId, Val) INCLUDE (ID) WHERE IsValidated;
CREATE INDEX tmp_tmp_IsNotValidated
ON tmp_tmp (SessionId, Val) INCLUDE (ID) WHERE NOT IsValidated;и в MS SQL:
CREATE INDEX tmp_tmp_IsValidated
ON tmp_tmp (SessionId, Val) INCLUDE (ID) WHERE IsValidated=1;
CREATE INDEX tmp_tmp_IsNotValidated
ON tmp_tmp (SessionId, Val) INCLUDE (ID) WHERE IsValidated=0;
Еще раз извиняюсь за столь сильное упрощение, когда индексы различаются лишь фильтром в WHERE. В реальных условиях индексы могут различаться не только этим и вовсе не быть частичными (фильтрованными в терминах MS). Для рассмотрения проблемы нам важно только чтобы это были разные индексы, необходимые в рамках одного запроса.
Начнем с простой выборки. Для однообразия, опять с PostgreSQL:
SELECT T.ID
FROM tmp_tmp T
WHERE T.SessionId BETWEEN 30 AND 49
AND T.Val=530
AND (T.IsValidated OR NOT T.IsValidated);
Bitmap Heap Scan on tmp_tmp t (cost=3342.26..3557.61 rows=149 width=4) (actual time=5.667..7.586 rows=1000 loops=1)
Recheck Cond: (((sessionid >= 30) AND (sessionid <= 49) AND (val = 530) AND isvalidated) OR ((sessionid >= 30) AND (sessionid <= 49) AND (val = 530) AND (NOT isvalidated)))
Heap Blocks: exact=1000
-> BitmapOr (cost=3342.26..3342.26 rows=199 width=0) (actual time=5.573..5.574 rows=0 loops=1)
-> Bitmap Index Scan on tmp_tmp_isvalidated (cost=0.00..1676.51 rows=100 width=0) (actual time=2.813..2.814 rows=500 loops=1)
Index Cond: ((sessionid >= 30) AND (sessionid <= 49) AND (val = 530))
-> Bitmap Index Scan on tmp_tmp_isnotvalidated (cost=0.00..1665.67 rows=99 width=0) (actual time=2.758..2.758 rows=500 loops=1)
Index Cond: ((sessionid >= 30) AND (sessionid <= 49) AND (val = 530))
Planning Time: 0.123 ms
Execution Time: 7.643 msКак видим, в простом запросе планировщик запросов повел себя достойно и сумел использовать оба индекса.
Что же MS SQL?
SELECT T.ID
FROM tmp_tmp T
WHERE T.SessionId BETWEEN 30 AND 49
AND T.Val=530
AND T.IsValidated IN (0,1)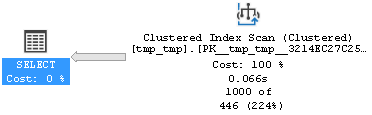
Как видим, тут планировщик MS SQL оказался не на высоте и вцепился в кластерный индекс, что в данном случае, никаких преимуществ не принесло. Впрочем, если бы мы при создании таблицы объявили бы первичный ключ не кластерным, то лучше бы не стало:

Будем считать пока счет 1:0 в пользу PostgreSQL. Просьба без холиваров! Я в курсе, что планировщик запросов MS SQL в подавляющем большинстве случаев ведет себя оптимальней, чем планировщик запросов PostgreSQL. Но посмотрим, а что будет если усложнить задачу планировщику. Создадим и наполним данными таблицу для PostgreSQL:
CREATE TABLE tmp_sessions AS
SELECT G.n AS SessionId
FROM generate_series(30,49) G(n);И аналогичную для MS SQL:
SELECT N.number AS SessionId
INTO tmp_sessions
FROM master.dbo.spt_values N
WHERE N.type='P'
AND N.number BETWEEN 30 AND 49А теперь мы можем усложнить наш первый простой запрос. Для PostgreSQL:
SELECT T.ID
FROM tmp_sessions S
JOIN tmp_tmp T ON T.SessionId=S.SessionId
AND T.Val=530
AND (T.IsValidated OR NOT T.IsValidated);Здесь ситуация уже интересней. Если не трогать настройки по-умолчанию, то планировщик выбирает параллельное последовательное сканирование таблицы tmp_tmp:
Hash Join (cost=1067.38..12091.62 rows=9524 width=4) (actual time=0.604..39.444 rows=1000 loops=1)
Hash Cond: (t.sessionid = s.sessionid)
-> Gather (cost=1000.00..11689.03 rows=747 width=8) (actual time=0.575..39.272 rows=1000 loops=1)
Workers Planned: 2
Workers Launched: 2
-> Parallel Seq Scan on tmp_tmp t (cost=0.00..10614.33 rows=311 width=8) (actual time=0.162..31.718 rows=333 loops=3)
Filter: ((isvalidated OR (NOT isvalidated)) AND (val = 530))
Rows Removed by Filter: 333000
-> Hash (cost=35.50..35.50 rows=2550 width=4) (actual time=0.019..0.020 rows=21 loops=1)
Buckets: 4096 Batches: 1 Memory Usage: 33kB
-> Seq Scan on tmp_sessions s (cost=0.00..35.50 rows=2550 width=4) (actual time=0.014..0.015 rows=21 loops=1)
Planning Time: 0.142 ms
Execution Time: 39.499 msИ только если запретить ему выбирать параллельный план получим опять корректный выбор обеих индексов и резкий прирост производительности:
SET max_parallel_workers_per_gather = 0;
Hash Join (cost=11810.19..13123.60 rows=9524 width=4) (actual time=16.546..18.582 rows=1000 loops=1)
Hash Cond: (t.sessionid = s.sessionid)
-> Bitmap Heap Scan on tmp_tmp t (cost=11742.82..12721.01 rows=747 width=8) (actual time=16.516..18.418 rows=1000 loops=1)
Recheck Cond: (((val = 530) AND isvalidated) OR ((val = 530) AND (NOT isvalidated)))
Heap Blocks: exact=1000
-> BitmapOr (cost=11742.82..11742.82 rows=996 width=0) (actual time=16.418..16.419 rows=0 loops=1)
-> Bitmap Index Scan on tmp_tmp_isvalidated (cost=0.00..5887.52 rows=500 width=0) (actual time=8.470..8.470 rows=500 loops=1)
Index Cond: (val = 530)
-> Bitmap Index Scan on tmp_tmp_isnotvalidated (cost=0.00..5854.93 rows=496 width=0) (actual time=7.947..7.947 rows=500 loops=1)
Index Cond: (val = 530)
-> Hash (cost=35.50..35.50 rows=2550 width=4) (actual time=0.017..0.018 rows=21 loops=1)
Buckets: 4096 Batches: 1 Memory Usage: 33kB
-> Seq Scan on tmp_sessions s (cost=0.00..35.50 rows=2550 width=4) (actual time=0.011..0.013 rows=21 loops=1)
Planning Time: 0.118 ms
Execution Time: 18.640 msЧто же MS SQL?
SELECT T.ID
FROM tmp_sessions S
JOIN tmp_tmp T ON T.SessionId=S.SessionId
AND T.Val=530
AND (T.IsValidated=1 OR T.IsValidated=0)
Как и предполагалось - лучше не стало. Как видим, планировщики и в PostgreSQL, и в MS SQL могут встать в тупик и не выбрать оптимальный план. Ну что же, мы люди не гордые и объясним планировщикам, как все же мы хотим выбрать данные из нашей таблицы.
Для PostgreSQL:
SELECT T.ID
FROM tmp_sessions S
CROSS JOIN LATERAL (
SELECT V.ID
FROM tmp_tmp V
WHERE V.SessionId=S.SessionId
AND V.Val=530
AND V.IsValidated
UNION ALL
SELECT V.ID
FROM tmp_tmp V
WHERE V.SessionId=S.SessionId
AND V.Val=530
AND NOT V.IsValidated ) T;
Nested Loop (cost=0.42..36996.35 rows=25500 width=4) (actual time=0.045..2.336 rows=1000 loops=1)
-> Seq Scan on tmp_sessions s (cost=0.00..35.50 rows=2550 width=4) (actual time=0.011..0.014 rows=21 loops=1)
-> Append (cost=0.42..14.39 rows=10 width=4) (actual time=0.008..0.108 rows=48 loops=21)
-> Index Only Scan using tmp_tmp_isvalidated on tmp_tmp v (cost=0.42..7.12 rows=5 width=4) (actual time=0.005..0.057 rows=24 loops=21)
Index Cond: ((sessionid = s.sessionid) AND (val = 530))
Heap Fetches: 500
-> Index Only Scan using tmp_tmp_isnotvalidated on tmp_tmp v_1 (cost=0.42..7.12 rows=5 width=4) (actual time=0.004..0.048 rows=24 loops=21)
Index Cond: ((sessionid = s.sessionid) AND (val = 530))
Heap Fetches: 500
Planning Time: 0.142 ms
Execution Time: 2.383 msПрошу обратить внимание, что если в первом запросе без JOIN время выполнения запроса было 7.643 ms, во втором запросе с задушенной параллельностью - 18.640 ms, то при явной выборке по двум разным индексам время выполнения стало всего 2.383 ms!
Аналогично поступим и с MS SQL:
SELECT T.ID
FROM tmp_sessions S
CROSS APPLY (
SELECT V.ID
FROM tmp_tmp V
WHERE V.SessionId=S.SessionId
AND V.Val=530
AND V.IsValidated=1
UNION ALL
SELECT V.ID
FROM tmp_tmp V
WHERE V.SessionId=S.SessionId
AND V.Val=530
AND V.IsValidated=0 ) T
Тут комментарии уже излишни. MS SQL такие мелкие интервалы даже не измеряет, выдавая в качестве времени выполнения запроса 0 ms.
Резюме будет следующим. Действительно OR в выражениях WHERE/ON SQL запросов следует избегать. И даже в случае, как в первом примере с PostgreSQL или во втором примере с ним же и задушенной параллельностью, когда план запроса похож на приемлемый, запрос следует переписать без OR, что стабильно даст не только более предсказуемый план запроса, но еще и сократит время его выполнения.
Спасибо, если дочитали. И тем более спасибо, если этот небольшой обзор оказался вдруг полезен.
Комментарии (18)

mentin
29.12.2023 17:32+2Хм, я не понял базовой вещи. Привык к аналитическим / колоночным базам, где всё по другому.
IsValidated- булевский, не ноль. Следовательно(T.IsValidated OR NOT T.IsValidated)- покрывает всю таблицу. Каким образом использование совершенно не избирательного индекса ускоряет запрос? Неужели замержить два битмапа и потом проверять в битмапе настолько быстрее, чем просто проверить булевское значение напрямую?
ptr128 Автор
29.12.2023 17:32Вы не поняли другого. В статье рассматривается не вопрос покрытия или не покрытия индексами таблицы, а вопрос SQL запроса, требующего двух разных выборок по разным индексам одной и той же таблицы.
А причины упрощения, на которое Вы обратили внимание, в статье я указал дважды:
Для лучшего понимания, пример будет сильно упрощен. Ровно до того предела, пока проявляется суть проблемы.
Еще раз извиняюсь за столь сильное упрощение, когда индексы различаются лишь фильтром в WHERE. В реальных условиях индексы могут различаться не только этим и вовсе не быть частичными (фильтрованными в терминах MS). Для рассмотрения проблемы нам важно только чтобы это были разные индексы, необходимые в рамках одного запроса.
mentin
29.12.2023 17:32+3Мой вопрос это не придирка к статье, пример вполне нормальный, и разумное упрощение, хорошо показавшее разные планы.
Мой вопрос ортогональный: почему использование столь неселективного индекса ускорило выполнение запроса? Индекс хорошо когда он помогает найти "иголку в итоге сена". Когда индекс покрывает всю таблицу (и чтением только индекса не обойтись), толку от него вроде бы быть не должно, но цифры показывают что есть. Вот про это вопрос.
ptr128 Автор
29.12.2023 17:32почему использование столь неселективного индекса ускорило выполнение запроса?
Потому что два индекса покрыли все записи, необходимые этому запросу. При наличии полного индекса потребовалась бы лишь одна выборка и это было бы явно быстрее, чем две выборки по двум индексам. Например:
CREATE INDEX tmp_tmp_All ON tmp_tmp (SessionId, Val, IsValidated) INCLUDE (ID); SELECT T.ID FROM tmp_sessions S JOIN tmp_tmp T ON T.SessionId=S.SessionId AND T.Val=530 AND (T.IsValidated OR NOT T.IsValidated); Nested Loop (cost=0.42..38.91 rows=157 width=4) (actual time=0.479..1.258 rows=1000 loops=1) -> Seq Scan on tmp_sessions s (cost=0.00..1.21 rows=21 width=4) (actual time=0.380..0.382 rows=21 loops=1) -> Index Only Scan using tmp_tmp_all on tmp_tmp t (cost=0.42..1.73 rows=7 width=8) (actual time=0.030..0.039 rows=48 loops=21) Index Cond: ((sessionid = s.sessionid) AND (val = 530)) Filter: (isvalidated OR (NOT isvalidated)) Heap Fetches: 0 Planning Time: 2.322 ms Execution Time: 1.304 msНа 1 ms быстрее, чем запрос по двум частичным индексам.
А вот причины использования частичных индексов могут быть разными. Например, 95% запросов выполняются только по записям с IsValidated = TRUE, а в таблице записей с IsValidated = FALSE столько же или даже больше, чем записей с IsValidated = TRUE. Тогда эти 95% запросов смогут работать с индексом, в два или больше раз меньшим, чем полный индекс. Что сокращает и потребляемую память, и время выборки по этому индексу.
Запрос по полному индексу только IsValidated:
SELECT T.ID FROM dev.tmp_tmp T WHERE T.SessionId BETWEEN 30 AND 49 AND T.Val BETWEEN 300 AND 699 AND T.IsValidated; Index Only Scan using tmp_tmp_all on tmp_tmp t (cost=0.42..4802.01 rows=40516 width=4) (actual time=0.050..9.381 rows=40000 loops=1) Index Cond: ((sessionid >= 30) AND (sessionid <= 49) AND (val >= 300) AND (val <= 699) AND (isvalidated = true)) Heap Fetches: 0 Buffers: shared hit=759 Planning Time: 0.100 ms Execution Time: 10.310 msИ по частичному:
Index Only Scan using tmp_tmp_isvalidated on tmp_tmp t (cost=0.42..2348.52 rows=40516 width=4) (actual time=0.034..5.445 rows=40000 loops=1) Index Cond: ((sessionid >= 30) AND (sessionid <= 49) AND (val >= 300) AND (val <= 699)) Heap Fetches: 0 Buffers: shared hit=381 Planning Time: 0.116 ms Execution Time: 6.399 msКак видим, время выполнения запроса в полтора раза больше по полному индексу, чем по частичному. А буферов (памяти) в запросе по частичному индексу использовалось в два раза меньше.
Естественно, никто не запрещает иметь и полный индекс, и частичный. Но следует понимать, что раз подавляющее большинство запросов работают с частичным индексом, то он с большой вероятностью уже закеширован в памяти. И для тех редких запросов, для которых оптимален полный индекс, часто эффективней будет считать в память только второй частичный индекс, чем полный.

ALexKud
29.12.2023 17:32+1Статья интересная и полезная. Раньше я не прогонял свой код sql процедур через план запроса, а руководствовалмя известными практикам создания индексов для полей в фильтах и join. Но насколько помню, оператор OR в них не использовал, так как он требуется редко и интуитивно понимал, что он неоптимален с точки зрения быстродействия. Мои специфические задачи и приложения требуют мониторинга в онлайне и поэтому быстродействия важно, так как логи приложений находятся в бд и они активно используются sql процедурами мониторинга и минимально загружают CPU сервера. В мониторинге загрузка CPU и объем используемой памяти отображается каждые 10 секунд специальным запросом.

mserg86
29.12.2023 17:32SELECT T.ID
FROM tmp_tmp2 T
WHERE T.SessionId BETWEEN 30 AND 49
AND T.Val=530
AND T.IsValidated in (0,1)
Касаемо MS SQL, потестил на своем маке (докер + Azure Data Studio)
Пересоздал индексы правильно (без включения ID в некластеризованный индекс), сделал замеры... И создал 1 индекс по колонкам Sessionid, Val, IsValidated без фильтров.
Clustered Index Scan заменился на Index Seek.
Было Est. CPU Cost 0.220031 + 0.220031, Act. CPU Cost 28, Est. IO Cost 3.30979
Стало Est. CPU Cost 0.220157, Act. CPU Cost 22, Est. IO Cost 0.351273.
Также, количество выполнений снизилось с 11 до 1. IO Cost снизилось более чем в 9 раз!
Выводы:
Индексы надо создавать правильно
В некластеризованный индекс не нужно пихать колонку кластеризованного индекса, она там уже есть
Не натягивать сову на глобус (покрывающие индексы для общих примеров)
Кластеризованный индекс - B+ дерево, он будет выбираться по-умолчанию, если нет более точных индексов для конкретных запросов. Можете поиграться с Plan Explorer, чтоб проверить это.
ptr128 Автор
29.12.2023 17:32создал 1 индекс по колонкам Sessionid, Val, IsValidated без фильтров
А теперь перечитайте проблему, рассматриваемую в статье и не занимайтесь упрощениями, которые уже не позволят эту проблему рассмотреть:
Для лучшего понимания, пример будет сильно упрощен. Ровно до того предела, пока проявляется суть проблемы.
Еще раз извиняюсь за столь сильное упрощение, когда индексы различаются лишь фильтром в WHERE. В реальных условиях индексы могут различаться не только этим и вовсе не быть частичными (фильтрованными в терминах MS). Для рассмотрения проблемы нам важно только чтобы это были разные индексы, необходимые в рамках одного запроса.
mserg86
29.12.2023 17:32Обиделся чтоли?) Давай еще один минус, может легче станет.
Кластеризованный ключ не надо пихать в некластеризованный индекс.
Создал 1 индекс вместо 2 (1 лучше чем 2 в этом случае) по 1 колонке IsValidated. И предложенные индексы без фильтрации. Итог - тот же вложенный цикл с Key Lookup. И IO Cost сравнимый с "улучшенной версией", примерно 0.34.
А после создания рекомендованного индекса (добавляем в индекс 1 бит, прикол), IO Cost становится 0.003. От исходного варианта, Вашего, разница примерно в 1100 раз. Занавес. С наступающим)
ptr128 Автор
29.12.2023 17:32Кластеризованный ключ не надо пихать в некластеризованный индекс.
Так как в статье рассматривается поведение сервера как с кластерным первичным индексом, так и без него, то включение ID в остальные индексы вполне оправдано, чтобы не загромождать примеры кода.
Кроме того, хоть при поиске по не кластерному индексу обращение к кластерному индексу и не отображается в плане запроса, но тоже стоит чего-то.
По утверждению MS: Performance gains are achieved because the query optimizer can locate all the column values within the index; table or clustered index data is not accessed resulting in fewer disk I/O operations.
Доказательство. Выполняем запрос:
SELECT V.ID FROM tmp_tmp V WHERE V.SessionId BETWEEN 10 AND 29 AND V.Val BETWEEN 100 AND 899 AND V.IsValidated=1Без INCLUDE(ID):

И с INCLUDE(ID):

Наглядно видно, что INCLUDE(ID) привел как к ускорению запроса, так и к снижению стоимости операции и стоимости ввода-вывода.
Создал 1 индекс вместо 2
И именно за это и получили заслуженный минус. Так как проанализировать проблему оптимизации выполнения запроса, использующего одновременно два разных индекса одной таблицы, с одним индексом уже невозможно физически.
Вы сделали ровно то, о чем я писал открытым текстом. Упростили пример до полной непригодности в целях исследования рассматриваемой проблемы.
Причем второй раз проигнорировали то, что я Вам пишу:
В реальных условиях индексы могут различаться не только этим и вовсе не быть частичными (фильтрованными в терминах MS). Для рассмотрения проблемы нам важно только чтобы это были разные индексы, необходимые в рамках одного запроса.
P.S. Просьба не переходить снова на личности. Это не профессионально.


SSukharev
Не знаю как сейчас, а вот в ms sql 2012 любой in() превращался в кучу OR. Лучше и in() и or избегать везде, где это возможно.
ptr128 Автор
Если востребовано, я могу потом разобрать и случай с IN(). Там не все однозначно. И опять по разному в MS SQL и PostgreSQL. Причем в последнем, до выхода 14-ой версии, IN() был медленней ANY(), так как не хешировался.
NextStalker
Спасибо за разбор, думаю будет интересно почитать про IN().
9982th
Пользуясь случаем попрошу сравнить запрос, использующий IN() с большим количеством аргументов (сотни), и выполнение отдельного запроса для каждого из аргументов, передаваемых IN(), в цикле.
santjagocorkez
Никогда не делай так. Если у тебя огромное количество однотипных параметров, как, например, портянка в IN(), то лучше перепиши на временную таблицу и фильтруй по ней. Если лень с CREATE TEMPORARY TABLE возиться, по крайней мере в PostgreSQL, можно подсунуть JSON в запрос, который СУБД сама развернет во временную таблицу.
Я как-то раз попробовал огромный запрос с OR и IN(). Даже EXPLAIN (без ANALYZE) не дождался, он тупо парсился часами.
ptr128 Автор
В PostgreSQL точно после 14-ой версии включительно пробовали? Потому что с 14-ой версии список IN при парсинге сразу преобразуется в массив, а IN - в ANY.
Так что с "никогда" Вы явно погорячились.
santjagocorkez
Здесь ничтожно малое количество значений. Попробуй с десятком тысяч.
Проблема не в механике работы IN(), а в парсинге самого запроса.
ptr128 Автор
Странный Вы. Могли и сами проверить. Рецепт я Вам дал.
Ну ладно, по той же таблице:
yrub
смысл не в том, что любой OR тормозит, а в том, что только автору понятно как будет оптимальней, если накрутить замороченные индексы. посмотрите квери план своих кверей и успокойтесь, а то наделаете дел :)