

С развитием технологий безопасности и защиты от киберугроз, появляются различные новые методы атак. Одна из сфер которая постоянно развивается в своих возможностях, называется Code Injection. В системах под управлением Windows, это стало весьма распространённым явлением. Поэтому сегодня мы обсудим один из таких способов для инъекции кода, - Reflective Injection.
Ранее на Хабре уже обсуждался и данный способ, и различные другие, поэтому конкретно в данной статье мы затронем способ защиты от подобного метода атак.
PE Header is the head of everything
Несмотря на то, что, DLL-библиотеки инжектированные данным способом не отображаются при помощи перебора EnumProccessModules и подобными способами, их всё равно возможно обнаружить.
Начнём с того, что каждая каждая DLL-библиотека содержит т.н. PE Header, они начинаются с двух определенных символов, иначе называемых Magic Number, - символов MZ (либо 4D 5A). Думаю, уже каждый понял к чему я веду, поэтому нет смысла таить, предлагается перебор всей динамически выделенной памяти процесса на наличие этих двух байт.
Полученные данные позволят нам найти все точки вхождения библиотек в памяти процесса и провести их дальнейшее анализирование.
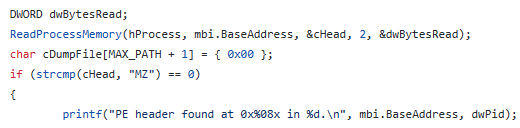
Пробуем изложить наши мысли в виде алгоритма действий, и получаем примерно следующее:
Получаем все дескрипторы модулей процесса через
EnumProcessModulesЗаписываем их базовые адреса в определенный массив
Перебираем всю память процесса (все страницы) и ищем магические числа MZ
Из найденного вытаскиваем базовые адреса и ищем в нашем массиве, отсекая имеющиеся
Оставшиеся и будут разыскиваемыми инъекциями!
Это действительно так просто?
Тут начинается самое интересное, современные инжекторы разработанные энтузиастами и не только ими, способны очищать PE заголовки у инжектируемых библиотек. С этого момента, у нас пропадает возможность как либо идентифицировать библиотеку обычными методами. Так как именно PE Header содержит информацию о библиотеке (в том числе название, физический путь, базовый адрес и т.д.). Поэтому такие части байт-кода внутри памяти процесса следует называть chunk-кодом.
Но, мы ведь встраиваем определённый код в память процесса, и этот процесс не протекает бесследно? Верно, мы всё ещё можем обнаружить такие сегменты при помощи досконального изучения памяти процесса.

Объединив размер всех секций и PE заголовков известных нам (из метода описанного выше) библиотек и самого процесса, мы можем узнать размер оставшегося неизвестного пространства, и получить те самые участки с chunk-кодом. Если снова представить данный способ в виде алгоритма действий, то он будет примерно следующим:
Мы перебираем все модули через
EnumProcessModulesи при помощи способа описанного ранее.Предварительно записав размер всех модулей и нашего процесса из PE заголовков, мы итеративно перемещаемся в (ожидаемый) конец библиотеки.
При обнаружении байт-кода вне известного конца, мы записываем его размер и можем полагать об инъекции в программу с удалением PE заголовков
Но остаётся следующая проблема, мы не можем идентифицировать эти участки как либо. И тут нам в помощь приходят эвристические методы. Например, взяв известную нам последовательность байтов (byte pattern), мы можем найти ее в chunk-коде. И тем самым идентифицировать возможную библиотеку.

Откуда же взять эту последовательность? Тут необходимы ваши знания reverse-engineering`а. У нас есть возможность открыть любую библиотеку в различных дебаггерах и изъять кусок байт-кода любой из функций внутри библиотеки. А после найти этот набор байтов в chunk-коде.
P.S.
Конечно и тут существуют проблемы, данный способ неприменим при self-morphing коде, или обёрнутом в какую либо VM машину (VMProtect к примеру). Так как набор байтов постоянно меняется при выполнении процесса, и не оставляет нам возможности его найти.
Существуют и другие трудности при данном методе обнаружения, код может быть встроен непосредственно в секции памяти программы с патчингом оригинальных PE-заголовков, но при знании оригинального размера программы, я полагаю что, мы способны сравнить ожидаемый размер секций и их размер непосредственно в процессе исполнения для обнаружения различных аномалий.
qw1
TLDR. Если мы знаем, какой нужно найти инжектированный вредоносный код, сканируем всю память процесса и ищем известную подстроку.