
Эпистемологический статус: весьма неопределённый. В литературе приводятся обширные, но ненадёжные данные, и в этой статье я делаю некоторые весьма грубые допущения. Тем не менее, я удивлюсь, если мои заключения отличаются от истины более чем на 1-2 порядка.
В настоящее время мозг — это единственный известный пример AGI (сильного искусственного интеллекта). Даже мелкие животные с крошечными мозгами демонстрируют впечатляющую степень владения сильным естественным интеллектом, в том числе, гибкость и агентное поведение в сложном мире, характеризующемся высокой неопределённостью. Если мы хотим понять, в какой степени современное машинное обучение приблизило нас к AGI, то стоит попробовать количественно оценить мощность мозга. Хотя уже проделано много отличной работы, дающей представление о возможностях мозга и о том, как эти данные экстраполируются на хронологию развития ИИ, мне никогда не удавалось по-настоящему разобраться в вопросе кроме как на практике. Так что ниже я решил проанализировать мозг в терминах современного машинного обучения и попытаюсь на основе этого анализа предположить, на что можно рассчитывать на текущем этапе разработки AGI.
Первым делом в этой статье давайте постараемся составить ориентировочное количественное представление о числовых показателях, характеризующих работу мозга и современных систем машинного обучения. Давайте обрисуем, сколько в мозге нейронов и синапсов, чтобы можно было сравнить мозг с крупномасштабными системами машинного обучения. Согласно наиболее общим оценкам, в человеческом мозге от 80 до 100 миллиардов нейронов. Здесь есть важный момент, который часто обходят вниманием, сравнивая мозг и фреймворк для машинного обучения: дело в том, что мозг не является единой монолитной системой, а состоит из множества субъединиц, отличающихся как по внутреннему строению, так и по функциональной специализации. Чтобы приблизиться к реальному пониманию процессов, происходящих в мозге, нужно уточнить, как именно эти 80 — 100 миллиардов нейронов распределены между зонами мозга.
Оказывается, исключительно сложно найти конкретные и надёжные цифры такого рода. Прямо удивительно, насколько плохо в нейронауках со сбором и предоставлением надёжных данных даже по самым базовым и глобальным вопросам, таким, как затронутый здесь.
Наилучшие, максимально полные и самые близкие к истине данные, которые мне удалось найти, взяты из проекта «Голубой Атлас Мозга», в рамках которого картируется мозг мыши. Ниже показано, какая доля нейронов уже картирована в каждом макрорегионе мышиного мозга (известно, что всего в мышином мозге около 100 миллионов нейронов).

Здесь нашлась пара вещей, которые изрядно меня удивили, хотя, наверное, не должны были. Во-первых — насколько огромен, оказывается, мозжечок. В нём больше нейронов, чем во всей коре больших полушарий! Вероятно, самый большой пробел в нейрофизиологии заключается в том, насколько слабо мы до сих пор представляем, что делает мозжечок и как именно он работает, несмотря на то, как он велик и насколько строго структурирован. Во-вторых, гипоталамус и таламус гораздо больше, чем они мне казались — вероятно, дело в том, что обычно они описываются как «ядра», а ядра мы обычно представляем как некие компактные единицы. На гиппокамп и базальные ганглии также приходится серьёзная доля от общего количества нейронов. В них заключено примерно по столько нейронов, сколько задействуется для реализации важных модальностей в коре больших полушарий — например, для обеспечения слуха.
За каждую такую модальность отвечает существенная часть коры. Задний мозг (в который входят варолиев мост и луковица) и средний мозг (включающий покрышку и крышу мозга) оказались меньше по объёму, чем я полагал – а ведь они, наряду с гипоталамусом, являются наиболее важными отделами мозга с эволюционной точки зрения. Они отвечают за поддержку базовых поведений. Думаю, в общем и целом пропорциональное соотношение этих долей у человека примерно такое же, как и у мыши, так как отношение размеров мозжечка и коры больших полушарий кажется постоянным у разных видов. Правда, предположу, что на кору/мозжечок у человека приходится немного большая доля мозга, чем у мыши.
Сама кора не однородна, а содержит различные специализированные регионы, отвечающие за разные функции. В «голубом атласе мозга» также приводится пропорциональное соотношение этих долей у мыши.

Ожидаю, что у человека аналогичные соотношения получатся существенно иными. У мыши невероятно велика та доля «полезной площади» коры, которая обслуживает обоняние. На зрение и слух отведено гораздо меньше. Каких-то превосходных данных по человеку у меня нет, но, насколько могу судить, у нас всё примерно наоборот: 27% полезной площади коры обслуживает зрение, сопоставимая доля (8%) обслуживает слух, а на обоняние приходится гораздо меньше (вероятно, 2-3%). Думаю, у человека должны быть крупнее зоны, связанные с ассоциативными способностями, а также более обширная лобная область.Для нейрофизиологов отмечу: под «зонами, связанными с ассоциативными способностями» я понимаюзаднюю теменнуюкоруивисочную долю, которые участвуют в формировании высокоуровневых абстракций, представляемых с участием мультимодальных стимулов.
Аналогично, говоря о «системе гиппокампа», я имею в видупериренальную, энторинальную и ретроспленальную кору, которые участвуют в обеспечении эпизодической памяти и пространственном картировании окружающей среды. Под «лимбической системой» я понимаю переднюю поясную и островковую кору. У мышей и крыс эта доля может быть пропорционально меньше, чем у людей, так как, по-видимому, у грызунов (по сравнению с людьми) увеличена ретроспленальная кора, обеспечивающая ориентирование. Но в целом мы не можем напрямую сравнивать количество нейронов в коре больших полушарий или даже целый мозг с моделями машинного обучения до тех пор, пока модели машинного обучения не станут справляться со всеми теми задачами, которые под силу животным.
Теперь давайте выясним, как экстраполировать на человеческий мозг эти цифры, известные по изучению мышей. Согласно достаточно надёжным источникам, в мозге человека примерно 86 миллиардов нейронов – при 70-100 миллионах нейронов в мышином мозге. Таким образом, в человеческом мозге примерно в 1000 раз больше нейронов, чем в мышином. Кроме того, из этих 86 миллиардов 16 миллиардов локализовано в больших полушариях, а 70 миллиардов в мозжечке (!). Это значит, что по общему количеству нейронов мозжечок абсолютно преобладает над остальными отделами мозга. Естественно, количество нейронов в данном случае неприоритетно, так как интересующие нас параметры связаны в основном с синапсами. Согласно известным оценкам, у человека примерно 1000-10000 синапсов на один пирамидальный нейрон коры. Давайте возьмём эту цифру в качестве исходной, но будем ориентироваться на нижнюю границу, поскольку не все нейроны являются пирамидальными; в коре много интернейронов, а у интернейронов меньше синапсов. В подкорковых зонах, которые также учитываются при подсчёте нейронов, также, вероятно, меньше синапсов на нейрон, но и по этому параметру сложно найти непротиворечивые данные. В принципе, с числом 1000 синапсов на нейрон удобно работать, а нас в рамках этого анализа интересует лишь порядок величин. Если всерьёз воспринимать эти цифры, то можно ожидать, что во всей коре мозга насчитывается примерно 16 миллиардов нейронов, что соответствует 16 триллионам параметров. Это примерно на 2 порядка больше, чем в больших языковых моделях, таких, как GPT3.
Разумеется, не весь мозг занимается языковым моделированием, на эту работу выделяется лишь крошечная доля его ресурсов. В частности, известно, что у человека есть зоны мозга, специально предназначенные для восприятия и понимания языка: это зона Брока и зона Вернике. Они занимают сравнительно небольшую часть мозга. Опять же, сложно найти точную информацию о том, какую именно площадь они занимают. Но вместе на них приходится до 3 из 50 полей Бродмана, и это означает, что примерно 6% объёма коры выделено для обработки естественного языка. Мне кажется, это разумная оценка, даже если немного завышенная. Фактически, можно утверждать, что полезная площадь коры, выделенная на обработку естественного языка, сравнима с площадью, выделяемой на обработку важной сенсорной модальности, например, обоняния илисоматосенсорного восприятия, но несравнима с площадью, обслуживающей фундаментальную модальность – например, зрение или слух.
Если предположить, что наши способности по моделированию языка реализуются преимущественно в зоне Брока и зоне Вернике, то можно оценить, что примерно 400-700 миллионов нейронов и, соответственно, 400-700 миллиардов параметров – это ресурс мозга, используемый для моделирования естественного языка. Интересно, что в таком случае наблюдается примерный паритет с ультрасовременными языковыми моделями или только небольшой перевес относительно них: так, в PaLM примерно 540 миллиардов параметров, в Gopher— 280 миллиардов. Если упрощённо предположить, что языковые параметры мозга и трансформеров масштабируются примерно одинаково, это будет означать, что языковой потенциал современных моделей примерно такой же, как у человека. Берусь утверждать, что эта оценка довольно точна, в пределах примерно одного порядка– с некоторыми задачами языковые модели справляются значительно лучше человека, с другими – гораздо хуже. К задачам второй категории относятся такие, которые связаны с абстрактной логикой, поддержанием долгосрочной согласованности, т.д. Вероятно, они зависят и от работы других зон мозга, и/или физической привязки символов. С другой стороны, в зонах Брока и Вернике, вероятно, реализуется не только обработка языка, но и другие аспекты, например, моторные функции, нужные для порождения речи. Таким образом, нельзя в этой экстраполяции учитывать весь объём их параметров. На самом деле, мне этот результат кажется достаточно удивительным, поскольку подводит к мысли, что мозг и современные модели машинного обучения масштабируются, в принципе, по эквивалентным законам – если говорить о масштабировании параметров (данные — уже другая история).
Данные особенно важны в свете новых законов масштабирования Шиншиллы (Chinchilla AI), согласно которым режим обучения, оптимизированный с учётом данных, превосходит по производительности Gopher и PaLM, хотя Chinchilla AI и оперирует всего 80 миллиардами, но при этом использует триллионы точек данных. Если предположить, что кривая масштабирования мозга более соответствует развитию Chinchilla, чем развитию по принципу GPT3, то следует ожидать, что потенциал моделирования языка в человеческом мозге примерно на порядок выше, чем в самых современных моделях (то есть, мозг работает примерно так же эффективно, какChinchilla с 700 миллиардами параметров).
Можно упрощённо предположить, что такая грубая эквивалентность параметров (с точностью до порядка) между моделями машинного обучения и мозгом распространяется и на человеческие чувства, и на когнитивные способности. Для начала возьмём зрение. В отличие от относительно компактной зоны Брока, область коры, отвечающая за визуальное восприятие, весьма велика. Опять же, точные цифры отыскать сложно, но я видел грубые оценки, согласно которым около 30% коры больших полушарий занято обработкой зрительных образов, и мне эта оценка кажется адекватной (определённо, реальное значение лежит в пределах 15-40%). На таком уровне приблизительно 3-5 миллиардов нейронов и 3-5 триллионов синапсов вовлекается в обработку визуальной информации, так что представляется, что они примерно на порядок насыщеннее, чем современные языковые модели. Однако, современные зрительные модели SOTA существенно уступают в размерах современным языковым моделям (в них примерно 100 миллиардов параметров). При этом показатель StableDiffusion – примерно 900 миллионов параметров, а у Dalle-2 примерно 12 миллиардов параметров (хотя, полагаю, большая часть этой мощности приходится на компонент, занятый обработкой естественного языка). Таким образом, исходя из нынешнего уровня развития зрительных моделей, их придётся нарастить ещё на 3-4 порядка, чтобы они могли посоперничать в остроте зрения с человеком.
Правда, в настоящее время распознавание образов и генерация изображений уже вышли на довольно хороший уровень, и кажется, что до паритета с человеком им ближе, чем 3-4 порядка. Возможно, дело в том, современные архитектуры машинного обучения для зрительных приложений по сути своей устроены эффективнее мозга. Возможно, дело в разделении весов с применением CNN (свёрточных нейронных сетей) или параллельном прогнозировании последовательностей событий с применением трансформеров и подобных им инновационных архитектур – и мозг с этими технологиями сравниться не может. Другое объяснение – что мозг решает значительно более сложную задачу, нежели распознавание образов, а именно, выполняет гибкую генерацию и интерпретацию видео. Вероятно, чтобы полноценно генерировать такое видео, нейронные сети должны нарастить параметры ещё на несколько порядков. Если это так, то меня это также не удивит, поскольку современные возможности работы с видео весьма ограничены. Нам действительно требуется вывести законы масштабирования визуальных моделей, чтобы докопаться до сути этого вопроса.
Схожие результаты получены и для аудио. Слуховые поля занимают около 7% коры головного мозга. Этот объём сводится к 700 миллионам – 1 миллиарду нейронов и 700 миллиардам – 1 триллиону параметров, такой объём нужен, чтобы создать слуховую систему, сопоставимую с человеческой. Напротив, «whisper model», разработанная OpenAI, практически может сравниться с человеком в преобразовании речи в текст, но обходится всего 1,2 миллиардами параметров. Это, опять же, подводит нас к мысли, что либо мозг очень неэффективно обрабатывает звук, либо что мозг обладает гораздо более мощными возможностями обработки аудио, чем современные модели машинного обучения.
Что насчёт оставшейся части мозга? Учитывая то пропорциональное разделение коры больших полушарий, которое мы очертили выше, такой анализ делается весьма просто. Оценочное количество синапсов на нейрон в подкорковых зонах (например, в гиппокампе и в базальных ганглиях) вероятно, ниже, чем в коре, поэтому количество параметров в нейронах этих зон требуется скорректировать в сторону уменьшения. Всё равно это означает, что мозг оперирует обширными моделями (100 миллиардов -1 триллион параметров), решающими такие задачи, как безмодельное обучение с подкреплением (происходит в базальных ганглиях), а также занимается консолидацией памяти и ориентированием в пространстве (гиппокамп).
Аналогичная аргументация применима и к мозжечку: притом, насколько много там нейронов, почти все они относятся к числу гранулярных клеток мозжечка, а синапсов у таких клеток сравнительно немного (примерно по 5). Кроме того, в мозжечке есть гораздо меньшее количество клеток Пуркинье (их примерно 15 миллионов), и у каждой из них от 10 тысяч до 100 тысяч синапсов. В сумме все эти клетки дают для мозжечка от 500 миллионов до 1 триллиона параметров. То есть, мозжечок сопоставим с большой областью коры, но в масштабах мозга не доминирует. Забавно, но такая оценка весьма точно соответствует функциональной роли операций, выполняемых в мозжечке.
Итак, насколько велика должна быть нейросеть, которая сравнилась бы по мощности с человеческим мозгом? Если оперировать примерно 20 миллиардами нейронов, расположенных вне мозжечка, и предполагать, что, фактически, в мозжечке имеется около триллиона параметров, то можно оценить, что рабочий потенциал полноценного мозга составляет от 10 до 30 триллионов параметров. Это очень много, но всего на 1-2 порядка больше, чем в современных крупномасштабных системах. Допустим, что можно взять за основу современную стоимость обучения GPT3 и количество параметров такой сети. Если предположить, что такая стоимость в пересчёте на параметр растёт линейно, то требуется от 100 миллионов до 1 миллиарда долларов, чтобы обучить современную нейронную сеть, эквивалентную по параметрам человеческому мозгу.
Как же выглядит мозг с точки зрения специалиста по машинному обучению? Мозг – это набор из 10-15 полунезависимых специализированных моделей, размеры которых варьируются от условной PaLM до моделей, которые могут быть примерно на порядок больше PaLM. Каждая из этих моделей специализируется независимо от остальных и управляет конкретной модальностью или функцией организма. Кроме того, эти модели соединены друг с другом через исключительно широкую полосу передачи данных, и коммуникация между ними осуществляется как методом логического вывода, так и через обучение. Те крупномасштабные модели мозга, в которых реализовано обучение с нуля, также обёрнуты в тонкий слой нейронов, обеспечивающих жёстко прошитый функционал. По количеству параметров этот слой миниатюрен, но на практике его влияние очень велико. Такой жёстко запрограммированный функционал отвечает за сбор и предобработку ввода, а также за постобработку вывода (в особенности это касается моторных функций). Также в нём реализовано динамическое целеполагание, зависящее, например, от функции подкрепления в условиях сложившегося гомеостаза. Именно здесь также осуществляется глобальная модуляция таких вещей как внимание, настороженность, уровни возбуждения и т.д. в ответ на внешние стимулы. Все эти модели действуют в режиме реального времени с задержкой порядка 100-200 мс. Они успевают обработать полный цикл, в который входят восприятие, планирование, выбор действия, а затем и моторная реализация. Обучение этих моделей происходит на относительно небольших (но не мизерных) множествах неодинаково распределённых (non-i.i.d) данных. Работа идёт в онлайновой среде POMDP (частично наблюдаемая марковская модель принятия решений) с минимальным размером батча равным 1.
Рассматривая такую модель в контексте современного машинного обучения, приходится признать, что подобная система пока далеко за рамками наших возможностей. Но, если прогресс машинного обучения и инвестиции в эту сферу сохранятся на уровне, наблюдавшемся на протяжении последнего десятилетия, то весьма вероятно, что уже за следующие десять лет мы сможем нарастить наши модели ещё на несколько порядков. Вероятно, для этого предстоит проработать ещё некоторые дополнительные архитектурные детали, и нам понадобятся более эффективные конфигурации или методы обучения, но на этом пути не просматривается каких-либо непреодолимых преград. Поэтому я полагаю, что обозначенные рубежи будут достигнуты уже в ближайшем будущем.
Вопрос данных
В рамках проведённого здесь анализа возникает фундаментальный вопрос, касающийся масштабирования данных с учётом очерченных выше параметров. Законы масштабирования Шиншиллы вновь ставят данные во главу угла, и при использовании этих моделей ясно, что отныне при масштабировании больших языковых моделей именно данные будут основным ограничительным фактором. В описанном контексте это тем более важно, поскольку наш мозг не обучается на целом Интернете. Фактически, довольно легко определить верхнюю границу для таких учебных датасетов. Представьте, что всю вашу жизнь вы потратите на чтение, и будете в течение 80 лет читать по 250 слов в минуту. Получится всего примерно 10 миллиардов токенов, что на порядок меньше даже тех небольших данных, на которых обучаются современные языковые модели. Аналогичная ситуация складывается и с картинками. Чтобы определить верхнюю границу, предположим, что мы просматриваем картинки со скоростью 60 кадров в секунду в течение 80 лет. Это всего лишь 2,5 миллиарда изображений – довольно много, но гораздо меньше, чем весь видео-контент, выложенный в настоящее время на Youtube. Для человека данные верхние границы изрядно завышены, но даже такие оценки уже гораздо ниже, чем стандарты современных больших языковых моделей, масштабируемых по закону Шиншиллы (хотя, будем честны, пока мы не располагаем аналогичными законами масштабирования для изображений и видео. Возможно, обучение таким данным протекает значительно эффективнее, чем обучение языку, хотя, это и кажется маловероятным).
Здесь вырисовываются две возможности, которые можно представить в виде спектра. a.) Данные – это фактор, фундаментально ограничивающий человеческий интеллект, и поэтому из-за недостатка данных мозг вынужден оперировать огромным количеством параметров, чтобы успевать масштабироваться. Поэтому кривая масштабирования человеческого мозга очень далека от оптимальной. b.) Мозг оперирует данными гораздо эффективнее, чем современные модели машинного обучения, и поэтому опирается на иной закон масштабирования, в рамках которых количество данных далеко не столь важно. Лично я считаю, что вариант .b гораздо вероятнее, но и вариант .a (в мозге слишком много параметров) также вероятен. Постараюсь аргументировать эту точку зрения, хотя, как мне кажется, мои доводы нельзя считать определяющими.
1.) Вероятно, люди (и животные) получают более качественные данные, чем ИИ. Мы можем пойти погулять, повзаимодействовать с окружающим миром и выбрать из него желаемые данные, а не довольствоваться неодинаково распределёнными, произвольно полученными и избыточными данными, взятыми из Интернета. Вероятно, поэтому мы подчиняемся более выигрышному закону масштабирования. Особенно это касается данных, распределённых по закону Ципфа, где вероятность появления редких токенов или данных в наборе, полученном методом чисто случайной выборки, остаётся крайне низкой. Фактически, человек, приобретая знания на практике, учится отбирать данные по принципу их важности.
2.) Если данные действительно являются узким местом, то естественный отбор должен был исключительно сильно действовать в направлении оптимизации эффективности обработки данных и поддерживать развитие таких эффективных архитектур. В современном машинном обучении такой фактор пока отсутствует, поскольку современные результаты пока добываются при помощи систем, узким местом которых является вычислительная мощность. Представляется априори маловероятным, что современные архитектуры приближаются к максимальной эффективности при обработке данных.
3.) Различные животные, например, мы и мартышки, а также, вероятно, даже мыши или другие мелкие млекопитающие, вероятно, получают на вход примерно одинаковые объёмы зрительной и слуховой информации, но эволюция продолжает поддерживать наращивать в коре нашего головного мозга те области, которые отвечают за обработку «видео» и «аудио». Такое развитие событий маловероятно, если относительно этих модальностей у нас работает какой-нибудь исключительно плохой закон масштабирования. Интересно, что как раз обратная тенденция наблюдается с обонянием – как правило, чем больше мозг, тем меньшая зона в нём отводится на обработку запахов.
4.) Известно, что многие задачи, которые привычно решать людям (пусть и не всегда) опираются на более качественные выборки, чем предоставляются современным моделям машинного обучения. Следовательно, мы можем в принципе превосходить ИИ в эффективности выборки данных, и поэтому мы подчиняемся более выгодному масштабированию параметров относительно данных.
Допущения в модели
Здесь я представлю исключительно простую модель, в которой не претендую на точность сверх 1-2 порядков (надеюсь уложиться). Но я удивлюсь, если реальные цифры будут отличаться от моих сильнее, даже с учётом всех тех упрощений, которые я допускаю
1.) Нельзя ставить знак равенства между синапсами и параметрами нейронной сети. Приведу два аргумента. Во-первых, точность у синапсов ниже, чем у 32-разрядных чисел с плавающей точкой, обычно используемых для представления весов в нейронных сетях. Синапсы зашумлены и могут передавать относительно немного бит информации. Поэтому фактическое количество параметров в пересчёте на синапс снижается. С другой стороны, синапсы превосходят по свойствам веса искусственной нейронной сети. Например, они приспособлены как к быстрому, так и к медленному весовому обучению и, следовательно, неявно реализуют какую-то схему быстрых весов.
2.) Нейроны в мозге сложнее, чем в искусственных нейронных сетях. Так и есть, но я полагаю, что этот эффект незначителен по сравнению с количеством синапсов. Определённо, нейроны способны, например, подстраивать свой порог под силу входного сигнала; кроме того, их работа различным образом модулируется под действием тех или иных нейромедиаторов. Можно предположить, что при наличии таких свойств каждый нейрон обладает 5 дополнительными параметрами обучения. Это мизер по сравнению с 1000-10000 параметров, закодированных в его синапсах. С другой стороны, само наличие этих параметров означает, что мозг гораздо лучше нейронки способен адаптировать обучение «на лету», исходя из совершаемых умозаключений, тогда как нейронка вычисляет всего лишь фиксированную функцию. Вероятно, это очень полезно для динамической корректировки поведения, но в долгосрочной перспективе должно слабо сказываться на весовом обучении.
3.) Дендритное дерево сложнее линейной суммы всех входных сигналов, поступающих в синапс. Поэтому у тех синапсов, что расположены ближе к телу нейрона, вес выше. Существует множество областей интеграции дендритов (базальные, апикальные, т.д.). Возможно, дендриты способны мультипликативно взаимодействовать друг с другом, так, чтобы некоторые синапсы служили затворами для других или что-то в этом роде. Всё это возможно, но мне не удаётся качественно смоделировать, как это могло бы увеличивать фактическое количество параметров на нейрон.
4.) Возможно, используемый в мозге алгоритм обучения более или менее эффективен, чем обратное распространение. Так, вероятно, мозг не использует обратное распространение при присваивании достоверности тем или иным фактам из-за проблем, связанным с локализацией или возможностями распараллеливания, но учиться он должен как-то иначе. Обратное распространение – это априори очень эффективный алгоритм, вероятно, что алгоритм нашего мозга похуже. С другой стороны, общий алгоритм определения достоверности фактов, действующий в коре мозга, подвергался бы сильному давлению естественного отбора, поэтому он мог получиться весьма качественным, может быть, даже лучше, чем обратное распространение. Полагаю, действительно существуют более эффективные алгоритмы, чем обратное распространение. Поскольку пока мы очень слабо представляем, как именно в коре мозга присваивается степень достоверности любым фактам, это огромный открытый вопрос и фактор неопределённости, не позволяющий подсчитать, сколько именно параметров в человеческом мозге.
Биологические законы масштабирования

Выше мы фокусировались на законах масштабирования, характерных для машинного обучения. Но давайте поговорим и о биологических законах масштабирования, открытых в рамках нейронауки. Уже известно, что «интеллектуальность» живого существа тесно связана с количеством нейронов в его головном мозге. Таким образом, подразумевается относительно пологая кривая масштабирования, описывающая соотношение параметров и интеллектуальной производительности в природе. Не имея какого-либо средства для межвидового измерения и сравнения интеллекта, невозможно вывести точные коэффициенты масштабирования, как это делается в машинном обучении, но очевидно, что описанный закон существует. Нет причин полагать, что именно у человека этот закон перестаёт действовать.
Занятно, что, в соответствии с этой статьёй, на самом деле в живой природе действует несколько законов масштабирования, согласно которым размер мозга соотносится с количеством нейронов. Большинство млекопитающих работают по относительно плохому закону масштабирования, согласно которому с ростом количества нейронов необходимо в гораздо более высокой пропорции увеличивать и количество обволакивающих их глиальных клеток. Соответственно, плотность нейронов снижается и выигрыш от такого наращивания также резко падает. Напротив, приматы, как представляется, вышли на значительно улучшенный закон масштабирования, позволяющий увеличивать количество нейронов и глиальных клеток в соотношении 1:1, благодаря чему плотность нейронов остаётся постоянной независимо от масштаба. Таким образом, мы в состоянии поддерживать гораздо больше нейронов в мозге заданной величины, и поэтому мы значительно умнее более крупных животных, например, слонов или китов. Мозг слона существенно больше, чем мозг человека.
Представляется, что мозг человека как раз вписывается в те размеры, которые выводятся для него в соответствии с законом масштабирования, действующим у приматов. Без межвидового сравнительного измерения интеллекта сложно судить, умнее люди или, наоборот, глупее, чем другие приматы. Опять же, я полагаю, что человеческий мозг совершенно стандартен, поэтому нет причин полагать, что далее он будет масштабироваться вразрез с общим законом, действующим для приматов. Если мы создадим значительно более крупных приматов с «приматским» мозгом, то следует ожидать, что они будут умнее нас.
Представляется, что размер человеческого мозга ограничен в основном количеством калорий, требуемым на поддержание его работы – а более 25% нашего энергетического бюджета тратится на мозг. Дополнительные факторы, которые могут ограничивать размер нашего мозга – это требования к его охлаждению, а также размер черепа, с которым младенец в принципе может родиться. Однако, поскольку для работы мозга требуется целых 25% от общей вырабатываемой нами энергии, представляется, что существует разумный компромисс между размерами тела и интеллектуальностью особи, и что простое увеличение мозга не всегда играет определяющую роль, как минимум, в такой среде, где можно учиться на опыте предков. Не просматривается причин, по которым на мозг нельзя было бы потратить и 50% общего энергетического бюджета, если бы интеллект при дальнейшем наращивании продолжал бы давать ощутимые преимущества. Поэтому наблюдаемый сегодня уровень в 25% подразумевает, что дальнейшие инвестиции в размер мозга не более ценны, чем инвестиции в мышечную массу, здоровье внутренних органов и т.д. Мне кажется, именно поэтому следует ожидать, что при дальнейшем наращивании размеров мозга выигрыш от этого должен постепенно снижаться, как и в стандартном степенном законе масштабирования, наблюдаемом в машинном обучении. Естественно, эти рассуждения справедливы для особи, растущей и обучающейся в окружении предков, а не в такой среде, в которой мы обитаем сегодня.
Стоит задуматься, применима ли аналогичная аргументация и при масштабировании систем машинного обучения. Все известные факты наводят на мысль, что масштабирование даёт строго сублинейный рост. Соответственно, любой, даже незначительный выигрыш в интеллекте даётся всё большей ценой. Этот сценарий очень отличается от сверхлинейного масштабирования, которое требуется при машинном обучении по сценарию, когда рост интеллекта способствует дальнейшему росту интеллекта (FOOM).
Комментарии (19)

SergioT4
04.01.2024 18:14+5Не очень понятные вычисления, выгдяит как monkey math или складываем киллограммы с метрами.
Если упрощённо предположить, что языковые параметры мозга и трансформеров масштабируются примерно одинаково, это будет означать, что языковой потенциал современных моделей примерно такой же, как у человека. Берусь утверждать, что эта оценка довольно точна, в пределах примерно одного порядка– с некоторыми задачами языковые модели справляются значительно лучше человека, с другими – гораздо хуже.
Объём данных не сравним. Языковые модели могут генерировать тесты на множествах языках, по очень широкому диапозону областей знаний, с достаточной степенью достоверности. Ни один человек не сможет даже близко сравниться по данному критерию с языковыми моделями. Тоже и относительно размера контекста, уже сейчас человек не конкурент.
Достоверность у человека достигается не изначальной корректностью созданного текста, а функциональностью блока критики и анализа результата - проверяет созданный текст, находит подтверждение фактам из внешних источников, корректирует либо постановку задачи или результат и уходит на следующую итерацию. Через несколько итераций достигает уровня который его удовлетворяет (может для улучшения результата передать на независимую стороннюю экспертизу). Так и в системе которая достигнет agi будет работать не одна gpt модель, а ансамбль из нескольких систем.
К задачам второй категории относятся такие, которые связаны с абстрактной логикой, поддержанием долгосрочной согласованности, т.д. Вероятно, они зависят и от работы других зон мозга, и/или физической привязки символов.
Ребята в гугл утверждают что у моделей возникают новые возможности с увеличением размера модели

Так что вполне возможно в следующей версии некоторые из подобных задач станет возможно решать и базовой моделью.

Senecaminor
04.01.2024 18:14А если "обучение" происходит вне мозга, и это всего лишь интерфейс подключения к ноосфере, или "общему" сознанию. Что конечно сейчас наукой отрицается. То есть есть общий для вида вычислительный центр. (муравьи, стаи птиц, косяки рыб, мегаполисы людей).
Но вопросы, которые ставятся в статье крайне хороши. Что такое данные для мозга? Почему мы учимся быстрее и нам нужно меньше данных, чем машине?
Очень давно думал об этом, думал о том, являемся ли мы вечными существами или натренерованой спермой. Поищу автора в оригинале.

dolovar
04.01.2024 18:14+2Почему мы учимся быстрее и нам нужно меньше данных, чем машине?
В этом месте немного подробнее, пожалуйста. Почему Вы считаете, что человек учится быстрее? И почему Вы считаете, что человеку для обучения нужно меньше данных?

DonStron
04.01.2024 18:14+2А если "обучение" происходит вне мозга, и это всего лишь интерфейс подключения к ноосфере, или "общему" сознанию
Хоть один пример у вас имеется подтверждающий эту эзотерику?
А у науки имеется тьма накопленных примеров подтверждающих, что все активности происходят именно локально в мозге. Возьмите двух школьников, один был на занятиях, а второй прогулял - и вот у них уже разный набор знаний, а это противоречит вашим "подключениям к общему сознанию". За прошедшие 100 лет накопилось достаточно информации какая часть мозга за что отвечает, есть куча примеров с травмами или удалением опухолей, после которых человек терял какие-то навыки или знания, при сохранении других.
Много веков назад ещё можно было считать, что мы такие сложные и умные потому, что чьё-то творение. Но сейчас то уже можно не мракобесничать, вполне достаточно научных данных накоплено, чтобы понимать, что мы именно процесс эволюции и являемся просто биологическими автоматами со своими программами (множеством разных). И также есть связанные с этим глюки-баги. Например возвратный гортанный нерв - чистейшая эволюционная неоптимальность (особенно не повезло жирафам). Или сетчатка глаза, которая почему-то вывернута наизнанку, светочувствительные клетки оказались не на границе со стекловидным телом, а глубоко внутри и свету нужно пройти несколько слоев других клеток. При этом на планете есть существа, у которых сетчатка глаза правильно сформирована, не помню точно, рачки какие-то, у них глаз сформировался правильно, светочувствительными клетками к свету.
В общем как обычно, "если в школе прогуливать уроки физики, химии и биологии, то жизнь до самого конца будет полна чудес и магии".
Senecaminor
04.01.2024 18:14Я написал: а если?
Вы мне написали, что обратному доказательств тьма в науке, и привели пример не исследования, а наблюдение про школьников.
Компьютер это автомат, почему бы автоматам не объединиться в сеть? Те же "зеркальные нейроны" чем не сеть для обмена информацией.

eandr_67
04.01.2024 18:14+6Любая современная кремниевая "нейросеть" представляет собой дискретную цифровую вычислительную систему, жёстко ограниченную рамками теории алгоритмов. Аналоговая белковая нервная система таких рамок не имеет.
Компьютер не может воспроизвести аналоговые физические / химические процессы - он лишь может их приблизительно (в рамках ограничений, задаваемых дискретной цифровой природой компьютеров) моделировать численными методами.Само понятие "бит" применимо к дискретным цифровым системам и неприменимо к аналоговым процессам. Любая попытка оцифровки аналогового сигнала приводит к его искажению и потери части информации (при оцифровке звука или видео используется низкая разрешающая способность человеческих зрения и слуха, позволяющая замаскировать эти искажения).
Синапс передаёт не дискретное числовое значение (как происходит в "нейросети"), а аналоговый сигнал сложной формы, представляющий собой пакет импульсов, в котором варьируется количество импульсов, их продолжительность и скважность. Как соотнести этот пакет импульсов с количеством цифровых битов в дискретных системах, современной науке неизвестно.Кремниевый "нейрон" - примитивная и неизменная алгебраическая функция. Всё, что мы делаем в процессе "обучения" - лишь меняем коэф-ты, на которые умножаются числа, поступающие на вход этой функции. При этом и сами "нейроны", и топология "нейросети" никак не меняются. Тогда как и биологическая нервная клетка представляет собой аналоговый компьютер, меняющий свое поведение во времени. И структура связей между нейронами мозга тоже меняется во времени.
То, что мозг состоит из зон - это только верхний уровень структуры. Каждая зона состоит из нервных клеток разного типа, имеющих разное поведение, и клеток, которые нейронами вообще не являются. И как работают не отдельные клетки, а весь ансамбль связанных клеток (для чего надо параллельно и синхронно снимать информацию со всех клеток ансамбля), наука сказать не может, т.к. у человечества нет технологий такого изучения.
Пункт о котором часто забывают: мозг - не самодостаточный механизм, а часть намного более сложной системы. Железы внутренней секреции вырабатывают гормоны, регулирующие работу мозга, а мозг влияет на работу желез внутренней секреции. Даже банальный кофеин уже меняет работу мозга, а можно вспомнить и то, что случилось с Аланом Тьюрингом, когда ему изменили гормональный баланс. Мозг - система с множеством обратных связей, которых даже близко нет в кремниевых "нейросетях".
Возможно, местами я излишне упрощаю, да и получились скорее тезисы, чем аргументы, но на мой вывод это никак не влияет: сильный ИИ не может быть создан в рамках дискретных цифровых "нейросетей".
Сильный ИИ, построенный на базе аналоговой системы - да, возможен. Но, опять же, у человечества в настоящий момент нет технологий построения аналоговых систем такой сложности. И речь даже не о мышке. Смоделируйте хотя бы нервную систему муравья, который при всего 250 тысячах нервных клеток проходит зеркальный тест. Но и это на данном этапе развития невозможно.

bbs12
04.01.2024 18:14+2муравья, который при всего 250 тысячах нервных клеток проходит зеркальный тест
Нашел и почитал подробное исследование здесь: https://elementy.ru/novosti_nauki/432881/Muravi_sposobny_uznavat_sebya_v_zerkale
Кому лень читать - да, муравьи реально проходят зеркальный тест.
Наброшу на вентилятор гипотезу:
Вокруг муравьев в дикой природе имеется много естественных зеркал - капли воды (дождь, роса и т.д.). Если муравей выглядит нестандартно, испачкался например, его собратья по улью не могут его идентифицировать, происходит сбой механизма распознавания "свой-чужой" и такого муравья убивают. Поэтому в процессе отбора на генетическом уровне возник автоматический механизм прохождения зеркального теста - когда муравей бегает мимо капель, у него срабатывает алгоритм поиска аномалий в отражении и если аномалии обнаружены, муравей начинает реагировать и чистить себя.
Т.е. это не совсем настоящее прохождение зеркального теста, а скорее строгий генетический алгоритм, примерно как плетение паутины пауком.

zyaleniyeg
04.01.2024 18:14Наброшу другую гипотезу что если бы муравьи за стеклом не просто бегали а про аналоги с зеркалом проходили ближе и пытались взаимодействовать с муравьем то и вел бы он себя также как с зеркалом, т.е. вывод эксперимента не верен

Solozhenitsyn
04.01.2024 18:14+2Вы же не думаете, что больше никаких исследований с тех пор по этой теме не велось: https://www.elibrary.ru/download/elibrary_49442473_81074349.pdf

Kergan88
04.01.2024 18:14+1В принципе, с числом 1000 синапсов на нейрон удобно работать, а нас в рамках этого анализа интересует лишь порядок величин. Если всерьёз воспринимать эти цифры, то можно ожидать, что во всей коре мозга насчитывается примерно 16 миллиардов нейронов, что соответствует 16 триллионам параметров. Это примерно на 2 порядка больше, чем в больших языковых моделях, таких, как GPT3.
Только синапс одним параметром не закодируешь. Считать надо не синапсы, а объем информации, который содержится в структуре мозга.
Для дрозофилы (0.5 * 10^6 синапсов) коннектом весит примерно 100гб, если считать по 4б на параметр, то это примерно 0.25 * 10^11 параметров, или ~10^20 параметров (от десятков то сотен эксабайт, сравнимо со всем объемом информации, созданным человечеством) для коннектома человека.
Второй момент - крайне неэффективное качество кодировки в ллм, т.к. это просто фидфорвард сети. Более совершенные сети могут без проблем кодировать сотней параметров то, на что гпт потребуются миллиарды (или даже триллионы) параметров. Так что следует прибавить еще с минимум с полдесятка-десяток порядков - итого, в голове у человека аналог трансформера примерно на 10^25-10^30 параметров (и это самые нижние оценки).

WarpMFT
04.01.2024 18:14+3Работал не так давно с whisper, очищал LJ Speech Dataset, идея была в том чтобы искать несовпадения между текстом из датасета и STT по аудио, oh boy.. Для начала борьба с генерацией чисел вместо слов и обрыв генерации если сказали слово, текст которого является спец символом, например, фунт стерлингов, поковырялся с токинайзером, сделал. А вот дальше следим за руками этой "превосходящей человеческий слух модели" (некоторые примеры под спойлером). Модель пропускает слова, генерит отсебятину, повторяет какой-то токен пока не кончатся символы и предсказать в каких случаях она себя так будет вести у меня не получилось. Насколько я помню, она использует какой-то общий кусок с GPT3 поэтому периодически "умничает" добавляя слова или целые предложения, которых и близко не было в аудио.
Hidden text









Sdima1357
04.01.2024 18:14Это очень много, но всего на 1-2 порядка больше, чем в современных крупномасштабных системах.
Я слышу об этом уже лет 40, что не хватает 1-2 порядков...
ednersky
04.01.2024 18:14Насчёт количества данных при обучении живого мозга.
Если задуматься, то наш мозг учится на довольно небольших "выборках".
Наиболее сильно это видно на примере физических навыков. Например, имеем тело способное выполнить некое физическое упражнение: сальто, удерживание равновесия на снаряде и так далее.
Понятное дело, если физических кондиций недостаточно, то сперва человек качает их. Но если достаточно, то он выполняет десяток упражнений (например тех же сальто) с инструктором, а затем, выполнив около сотни становится уже "продвинутого уровня" - может контролировать каждую фазу упражнения, внося коррективы на ходу.
То же самое с языком. Те, кто имеет своих детей, если задумаются, то подтвердят, что ребёнок начинает правильно строить фразы не пропуская через себя гигабайты текстовой информации.
Получается, что модель управления телом или языковая модель - эти вещи, как бы уже есть в мозгу человека и, условно говоря, уже имеют некий коэффициент обученности. Учась разговаривать человек просто как бы "дообучает" свою нейросеть, но не строит все модели заново.
Как-то так.ИМХО, разумеется.
А какие из этого выводы? Что если построить сканер нейронов мозга, можно эти модели заимствовать у природы. Причём, возможно, не до конца понимая как они работают. Например, получить копию естественного сознания не проходя стадию создания сознания искусственного.

oalisevich
04.01.2024 18:14очень понравилось.!!!
наскока я понял кора не главная, мозжечок рулит. во-первых он просто сложнее, во вторых даже у крысы "достаточно мозгов" при ее ничтожных размерах и при практически отсутствии коры. Возможно дело не в количестве (как у чата).
Далее, текущие модели ИИ (все) собственно эмулируют кору (в самом общем смысле) а не мозжечок "мозги", поэтому и "думать" не умеют, но считают хорошо )).
Еще далее, судя по всему модель ИИ статична (сама по себе), а мозгов - нет (в общем случае).


espece
04.01.2024 18:14По «определению достоверности» интересно, что это и сегодня такой «огромный открытый вопрос». Фрейд в 1925г. описал отрицание как начало интеллектуальной функции у человека. В контексте тестирования реальности (= «присваивания достоверности»), - как механизм сохранения собственной связности человеческим Я. То есть мотив состоит в (со)хранении (отрицаемых) данных.
Если я правильно понимаю, вещи вроде обратного распространения нацелены на эффективное удаление неподходящих данных. Для человеческой личности такая попытка в отношении значимого факта чревата психозом, а главное – является деятельностью пусть мозга, но не его интеллекта.

phenik
04.01.2024 18:142.) Нейроны в мозге сложнее, чем в искусственных нейронных сетях. Так и есть, но я полагаю, что этот эффект незначителен по сравнению с количеством синапсов. Определённо, нейроны способны, например, подстраивать свой порог под силу входного сигнала; кроме того, их работа различным образом модулируется под действием тех или иных нейромедиаторов. Можно предположить, что при наличии таких свойств каждый нейрон обладает 5 дополнительными параметрами обучения. Это мизер по сравнению с 1000-10000 параметров, закодированных в его синапсах. С другой стороны, само наличие этих параметров означает, что мозг гораздо лучше нейронки способен адаптировать обучение «на лету», исходя из совершаемых умозаключений, тогда как нейронка вычисляет всего лишь фиксированную функцию. Вероятно, это очень полезно для динамической корректировки поведения, но в долгосрочной перспективе должно слабо сказываться на весовом обучении.
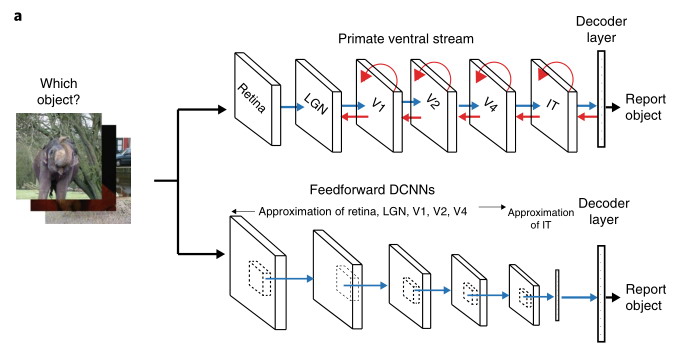
Этот момент со сложностью биологического нейрона сильно недооценивается. В последнее время проводилось их моделирование с помощью ИНС, как пример такой работы. Пирамидальные нейроны моделируются сетями из 5 - 8 слоев формальных нейронов. Что это значит? Условно число слоев в ИНС сокращается грубо в 5 раз. Например, вентральный тракт зрительной системы приматов состоит из 5 отделов, которые моделируются 5 слоями в сверточной сети в LeNet-5, первой удачной сети разработанной ЛеКуном, которая распознавала циферки. Однако в мозге условно 5 * 6 = 30 слоев, где 6 число слоев в коре. Последующая гонка с количеством слоев, с улучшенной эффективностью распознавания, привела к глубоким сетям с числом слоев 100 и более, таким как GoogLenet. Возможно причина такого расхождения как раз в сложности биологических нейронов. Если 30 * 5 = 150, то получаем число слоев в эффективных глубоких сверточных сетях по эффективности распознавания сравнимых с возможностями зрительной системы. Обращаю внимание, что все оценки условные с целью демонстрации порядков.
И это еще не все. Биологические нейроны и сети функционируют в динамическом, импульсном, асинхронном режиме с обратными связями, что лучше моделируется рекуррентными сетями. Это объясняет их энергоэффективность и пластичность недостижимую в традиционных ИНС, которые являются статическими сетями. Все эти характеристики пытаются достичь в нейроморфных решениях.
{kind=link}
{kind=link}
{kind=link}
garwall
Уважаемый Скайнет, вы так немножко подставляетесь. Я считаю, что в мозгу у человеков всё-таки NGI - интеллект натуральный.
garwall
ну и если серьезней, вы исходите из нескольких предположений, которые слишком вольно интерполируете. например, вот это "выишрыш в интеллекте дается все большей ценой". Я полагаю, адаптативность здесь гораздо более специфичной может быть, чем вот простые интерполяции. Условно говоря, возможно наработать что-то типа хомскианских лингвистических структур в архитектонике, а имея оные - преодоление расстояния от Эллочки-Людоедки до Бальзака уже не стоит таких затрат, как обучение с "нуля". (вот, например, скажем, у гринды нейронов сильно больше чем у человека, но вот разумного с нашей точки зрения поведения она не проявляет - хотя если вспомнить Дугласа Адамса...)