
Русский или English?
Введение
Ранее в статье Как мы запускали серьезный проект в Telegram я рассказал общую информацию о моем телеграм-бот проекте World for Life Bot
В этой статье я поделюсь опытом реализации многоязычности, расскажу о принципах выбора языков, которыми я руководствовался, технических аспектах реализации и принятых решениях.
Постановка Задачи
С самого начала разработки телеграм-бота я ставил перед собой амбициозную задачу создания сервиса, доступного и понятного для пользователей по всему миру. Вопрос о поддержке нескольких языков был ключевым, учитывая международный характер аудитории.
При определение списка поддерживаемых языков и выбор языка по умолчанию, я исходил из нескольких ключевых соображений:
Аудитория Телеграма: Учитывая популярность Телеграма в русскоязычном сегменте, русский язык был выбран как основной. Это решение было направлено на обеспечение максимального удобства для первоначальной целевой аудитории.
Международный Язык: Английский язык, как самый распространенный и универсальный в международном общении, стал вторым официальным языком бота. Этот выбор позволил обратиться к широкому кругу пользователей по всему миру.
Язык По Умолчанию: В случаях, когда язык пользователя не совпадал ни с русским, ни с английским, мы решили использовать английский язык по умолчанию, учитывая его международный статус и широкое распространение.
Дополнительные Требования
Мы также реализовали функционал, позволяющий пользователям в любой момент переключиться на один из официальных языков бота. Это решение было направлено на повышение удобства использования бота для международной аудитории.
Делается это достаточно просто:
На главной странице выбираем "Личный кабинет"

В Личном кабинете нажимаем на кнопку "Выбрать язык".

Далее выбираете язык интерфейса.
Все, теперь бот будет полностью на, выбранном вами, языке. Настройка сохраняется, и повторные действия не требуются
Минимизация Затрат на Внедрение Языков
В процессе разработки многоязычного телеграм-бота я уделил особое внимание минимизации затрат и упрощению процесса добавления новых языков. Главной задачей было найти оптимальные пути реализации многоязычной поддержки, не увеличивая при этом существенно сложность и стоимость разработки.
Первое ключевое решение, которое я принял, заключалось в том, чтобы избегать внесения текстов непосредственно в код бота. Весь текстовый контент бота организован через переменные, что позволяет легко управлять языковыми версиями. Каждый текст в коде представлен переменной, которая затем конвертируется в соответствующую надпись непосредственно перед добавлением в интерфейс пользователя. Это обеспечивает гибкость и удобство в управлении многоязычным контентом.
def get_text(param: str, lang: str = 'ru') -> str:
""" get text based on language settings """
ret: str = ""
# form text based on language settings
# in case of key is absent in the dictionary - print param`s name
if lang == 'ru':
ret = LEXICON_RU.get(param, param)
elif lang == 'en':
ret = LEXICON_EN.get(param, param)
else: # by default in English
ret = LEXICON_EN.get(param, param)
return retТакой подход также помог решить вопрос с языком по умолчанию. В случае отсутствия перевода или пропущенной переменной в словаре, пользователь увидит необработанное название переменной, но функциональность бота при этом останется неприкосновенной. Это обеспечивает стабильность работы бота даже при возникновении ошибок в локализации.
Теперь во всем коде вместо форматирования текста прямо используем:
txt = get_text('city_CoL_info', language)Как это все хранится. Тоже все достаточно удобно и просто - 1 словарь на каждый язык.
LEXICON_RU: Dict[str, str] = {
# ------------------MAIN------------------#
# buttons
'cost_of_living': "Уровень жизни по странам",
'all_services': "Список сервисов",
'to_bot_guide': "Руководство пользователя",
'propose_new_feature': "Написать админу",
'profile': "Личный кабинет",
'to_main': "На главную страницу",
'cancel': 'Отмена'
}На примере добавления испанского языка, я покажу что алгоритм действий чрезвычайно эффективный и гибкий. Процесс добавления нового языка в телеграм-бот происходит в несколько четко определенных шагов, минимизируя трудозатраты и время.
Перевод Словаря Лексикона: В качестве первого шага берем существующий русский словарь лексикона бота, где каждая фраза соответствует уникальному ключу. Этот словарь передается фрилансеру или переводческой службе для перевода значений на испанский язык. Важно отметить, что ключи остаются без изменений.
Интеграция Перевода в Систему: После получения переведенного словаря я добавляю всего лишь две строки строки кода в функцию
get_text, которая отвечает за вывод текста в интерфейсе бота. Эти строки позволяют боту использовать новый испанский словарь в соответствии с выбранным пользователем языком.Добавление Опции Выбора Языка: Последним шагом является добавление кнопки выбора испанского языка в личном кабинете пользователя.
Таким образом, весь бот - от меню и кнопок до сообщений - быстро адаптируется под испаноговорящую аудиторию.
Гибкая Масштабируемость Словаря
По мере развития бота и добавления функционала о мы перешли на модульно-сервисную архитектуру. Каждый встроенный функционал оформляется в виде библиотеки с определенной структурой. Расширение словаря начало доставлять неудобство. Было необходимо оформлять область в общем пространстве под модуль и следить за уникальностью ключей.
В итоге я остановился на следующем решении:
В файл assets, который входит в стандартную структуру, в котором есть еще много чего полезного, описывающего модуль, но об этом мы поговорим в следующих статьях, добавлен свой словарь лексикона, который используется только внутри модуля
Lexicons: Dict[str, dict] = {
# Russion localization
"RU": {
# ::buttons
'ratings_service': "Рейтинги",
'to_ratings_main': "К списку рейтингов",
'country_cost_of_living': 'Стоимость жизни по странам'
},
# English localization
"EN": {
# ::buttons
'ratings_service': "Ratings",
}
}Описанная ранее функция get_text немного модифицировалась
def get_text(param: str, lang: str = 'ru', lexicons: dict = {}) -> str:
""" get text based on language settings """
ret: str = ""
# form text based on language settings
# in case of key is absent in the dictionary - print param`s name
if lexicons == {}:
if lang == 'ru':
ret = LEXICON_RU.get(param, param)
elif lang == 'en':
ret = LEXICON_EN.get(param, param)
else: # by default in English
ret = LEXICON_EN.get(param, param)
else:
lexicon: Dict[str, str] = lexicons.get(lang.upper(), {})
ret = lexicon.get(param, param)
return retТеперь у нас есть возможность либо использовать глобальный лексикон бота, либо локальный модуля, передавая его в качестве параметра функции.
В итоге я получил простоту добавления модулей - по сути это изолированная функция со своим лексиконом. С другой стороны я сохранил гибкость в масштабировании языков, только теперь переводчику надо отдать не 1 файл, а россыпь фалов assets.
Описанное решение является текущей имплементацией и полностью меня устраивает. Поэтому поиски в направлении мультиязычности я прекратил и могу заниматься другим функционалом
Немного интересного
А теперь, на десерт я приведу немного статистики. По результатам прочтения, возможно у появился вопрос: "Если все так просто, то почему вы уже не локализовали на другие языки. Этому есть объяснение.
По статистике, у бота русскоязычных пользователей - 80%, англоязычных - 16%.
Остальные языки в сумме занимают всего 4%. Посмотреть распределение пользоваталей по языкам вы можете видеть на диаграмме
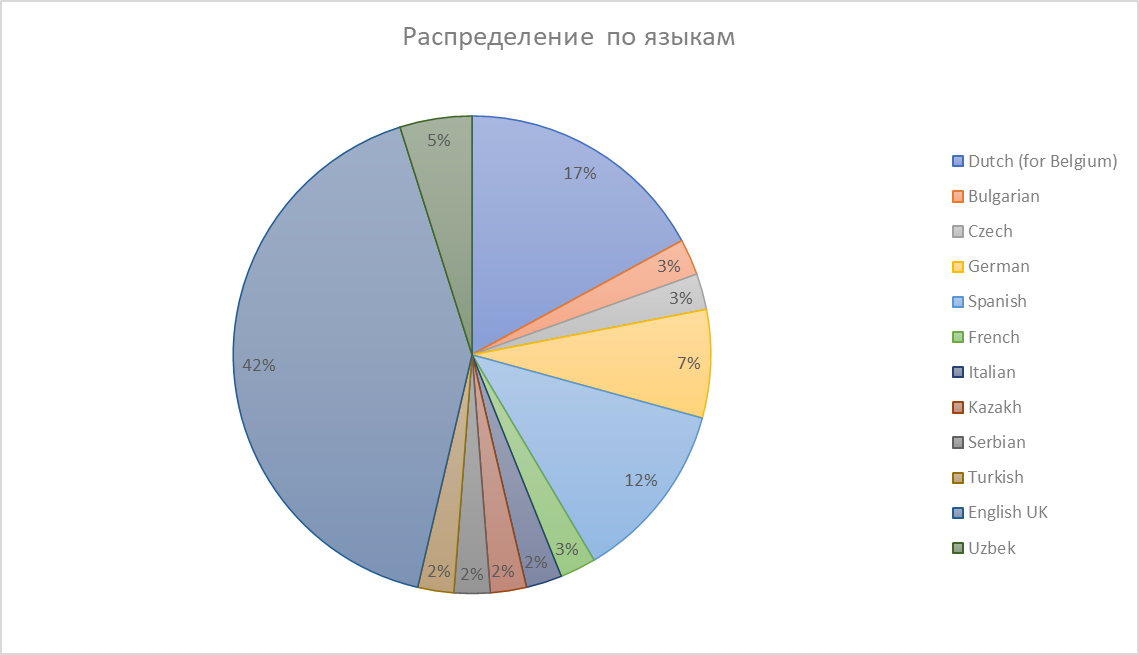
А вот постоянное расширение и синхронизация дело затратное. Поэтому когда случится выход на иностранный рынок, проще локализовать все с нуля, нежели заниматься постоянной поддержкой языков, не пользующихся популярностью.
Заключение
Многоязычность в боте - не просто техническая задача, но и важный шаг к созданию удобного и доступного для широкой аудитории сервиса. В этой статье я поделился своим опытом и принятыми решениями, которые помогут другим разработчикам в их проектах.
Буду рад за конструктив в комментариях, а также ваш опыт в разработке и продвижении телеграм-проектов!
Комментарии (27)

eeekkk
13.01.2024 08:21+2Отдельное спасибо за статистику. Я тоже проводил подобный анализ. Скажу что с иностранными пользователями еще все хуже. У меня почти 90% русскоязычных пользователей. Остальные с английским языком.

Kkeiv Автор
13.01.2024 08:21Да, это интересная по моему мнению информация, которую не дадут на курса. Но и надо заметить что она индивидуальная для каждого проекта и зависит от пути продвижения продукта и вектора развития продукта, определяемого разработчиками. Но узнать что у кого и как бывает полезно.

Xn0
13.01.2024 08:21+4Телеграм же присылает в сообщении язык телеграм клиента юзера. Я, когда реализовывал подобную задачу, ориентировался именно на него для первоначального выбора языка.
Kkeiv Автор
13.01.2024 08:21Вы абсолютно правы. Я использую эту логику для определения языка для приветствия. Тут больше вопрос что делать если человек пришел к примеру на Болгарском, что ему показывать? Делать на все случаи жизни очень дорого.



iredun
13.01.2024 08:21+6А почему не стали использовать i18n? Это вроде стандарт для таких вещей, может конечно для чего-то маленького и нет смысла его использовать, но интересно причину узнать.
Kkeiv Автор
13.01.2024 08:21+1Вы правы. Для больших проектов, и скорее со своей полноценной организацией интерфейса будет больше плюсов. В телеграм боте, где вы ограничены интерфейсом телеграма и не реализуете все аспекты локализации, оно немного тяжеловато и приносит больше нагрузки чем радости. Поддержка словаря в i18n и его масштабирование по языкам в этом случае немного труднее, а зашитые возможности практически не применяются. Благодарю что обратили внимание я воспользуюсь когда дорасту до самостоятельного приложения.

stephanthe
13.01.2024 08:21+1А зачем нагромождение if elif else, если только 2 языка? Разве if else не достаточно будет?
Kkeiv Автор
13.01.2024 08:21Это как раз явное указание официальности английского языка в боте. Чтобы при расширении не забыть. Но для текущей реализации вы абсолютно правы - elif избыточен

GrakovNe
13.01.2024 08:21+3Для своих телеграм-ботов я решил вопрос с локализацией, например, вот так: https://github.com/GrakovNe/kindle-sideload/blob/main/src/main/kotlin/org/grakovne/sideload/kindle/telegram/localization/LocalizationService.kt
В ресурсах джарника, у меня лежит набор темплейтов, один из которых дефолтный, а остальные имеют языковые постфиксы типа _ru, _en, _kz и так далее. Когда боту нужно построить сообщение, он берет данные и превращает из в строку, применив к ним темплейт
То есть, чтобы добавить поддержку нового языка, мне нужно взять оригинальный ресурсный файл, например, https://github.com/GrakovNe/kindle-sideload/blob/main/src/main/resources/messages.json и скопировать его с нужным постфиксом, локализовав содержимое, а потом сделать то же самое с текстом кнопок в другом ресурсном файле
Это избавляет от перебора через if-else-if, паттерн-матчинга и любых других механизмов, которые хардкодят набор языков в коде
Что касается "дать пользователю выбрать язык", я не стал заморачиваться и исхожу из того, что если у человека телеграм на русском, то и контент он хочет русскоязычный
Kkeiv Автор
13.01.2024 08:21+1Спасибо, полистал ваш код и задумался. Действительно при старте я могу по имеющимся ресурсам (автоматом выделяя все языки) создать словарь типа
lexicon = { 'ru' = LEXICON_RU, 'en' = 'LEXICON_EN', ...}
и тогда функция перевода get_text можно написать в 1 строчку
return lexicon.get(lang, lexicon['en']).get(param,param)
это сделает автоматическим добавление новых языков в функцию перевода, при добавлении ресурсных файлов нового языка
Благодарю
я в kotlin не силен, а не накладно на каждое сообщение загружать темплейт с проверкой ресурсов? Просто если 100 чел сниферят по боту - это все поток сообщений.GrakovNe
13.01.2024 08:21+2Если коротенько, то можно оптимизировать подгрузку файла ресурсов так, чтобы файл на старте апплика ложился в оперативную память и потом фетчился оттуда в уже спаршенном виде. Все равно апдейт локализации обычно связан с новыми фичами бота или починкой старых и влечет за собой новую сборку джарника и, как следствие, перезапуск
Если копать глубже, то чтение ресурсов для локализации сообщений при нагрузке на бота, скорее всего не станет бутылочным горлышком всей системы и решать проблему с "всем пользователям должно хватать времени ответить" я бы начал с разделения обработки сообщений.
В том коде, что я скинул работает очень наивная реализация: при получении пачки апдейтов апплик начинает процессить каждое входящее сообщение и типа-параллельно (на корутинах) отвечать на них чем-то. Для моего бота с конвертером книжек и другого, который трекает swift-платежики и имеет около 500 пользователей в день, этого хватает с лихвой на самом дешевом железе DigitalOcean.
Если нагрузка будет расти дальше и наивная реализация захлебнется, можно будет построить очередь, в которую будут ложиться сообщения, а потом, периодически пачка воркеров будет из доставать, делить между собой и обрабатывать совсем асинхронно. Можно пойти дальше и реализовать какой-нибудь почтовый ящик с персистентным хранением сообщений, чтобы обеспечить себе толерантность к рестартам апплика и сделать обработку сообщений кластерной
Короче говоря, вариантов много и все это системные подходы, которые порешают именно время обработки сообщений от входа до выхода, а не точечно пофиксят момент парсинга файлов ответа
Но оптимизировать болезни производительности стоит при их наличии) Я стою на позиции "пока есть опция дешево докинуть нод в кластере или железа на каждую - надо это делать и не городить сложный код"
Kkeiv Автор
13.01.2024 08:21+2Но оптимизировать болезни производительности стоит при их наличии) - это правильно. Меня как человека, начинавшего писать по микроконтроллеры в 2000-х на подкорке сидит забота о ресурсах, т.к. о "докинуть нод" в МК речи не шло :)

theurus
13.01.2024 08:21+3В своем боте сделал перевод с помощью ии (подходят gemini pro и chatgpt instruct).
В коде все сообщения от бота отправляются через функцию обертку, в ней указывается кому сообщение, само сообщение на любом языке, и подсказка для переводчика в которой можно(нужно) написать подсказку по переводу, например можно сказать что это текст на кнопке и его надо перевести так же коротко чтобы вместился в кнопку.
bot_reply_tr(message, 'Сообщение юзеру.', 'подсказка для переводчика')Язык юзера берется из message(язык интерфейса телеграм клиента), или из БД если он менял настройки, переводы кешируются что бы не дергать ии лишний раз, если ии сфейлился (запрещенка) то перевод отдается в гугл транслейт.
Переводы после этого можно руками исправить в кеше(бд), там записано всё включая подсказки, так что можно даже выгрузить и отдать на обработку живому переводчику в удобном для него виде.
В функции для переводов просто формируется запрос к ии типа переведи текст с одного языка на другой, вот тебе подсказка которая поможет сделать перевод лучше, вот текст.
Таким образом получается приличный автоперевод на все языки практически даром. ИИ переводит примерно так же "хорошо" как гугл транслейт но выгодно отличается тем что ему можно давать подсказки по переводу.
Kkeiv Автор
13.01.2024 08:21+1Круто там у вас все. Мой хост с 1 ядром и 2ГБ без GPU точно не потянет собственное ИИ. Если я все правильно понял, вы используете внешние инстансы ИИ? Это платные аккаунты или бесплатные? Просто в боте я стараюсь руководствоваться тем, чтобы он не тянул из меня денег. У меня есть задача, в которой без ИИ похоже не обойтись, но пока это большие задержки и стоимость. Буду благодарен за наводку для перевода.
И еще вопрос при завышении "температуры" не получится так что интерфейс будет менять под настроение ИИ? Типа генерироваться новые надписи.theurus
13.01.2024 08:21+2gemini pro сейчас бесплатно работает. Будет(а может не будет) стоить примерно как чатгпт, копейки если учесть что перевод 1 раз делается.
Kkeiv Автор
13.01.2024 08:21+1не, мне под другие задачи (у меня есть сервис конвертора информационных СМС) с постоянной нагрузкой на перевод. Поэтому если сможете подсказать бесплатные альтернативы - буду признателен. Про Gemeni Pro понял - посмотрю
theurus
13.01.2024 08:21+2Что значит с постоянной нагрузкой на перевод? Если надо постоянно переводить новые тексты то тут роботы вообще без вариантов, они намного быстрее и дешевле людей.
Если взять какое-нибудь отечественное яндексгпт и посчитать сколько стоит перевод короткой фразы то получится что то типа такого
(20 + 32) × 1.0 × ($0.0032/1000) = $0.000166 = 0.0146р
Where:
20: Number of prompt tokens.
32: Number of response tokens.
1.0: Multiplier for using the YandexGPT Lite model in synchronous mode.
$0.0032: Cost per 1,000 tokens.
$0.0032/1000: Cost per token.
Kkeiv Автор
13.01.2024 08:21+1Как я говорил, я за то чтобы проект не напрягал финансово. Сколько позакрывалось проектов, которые стали отягощать своих создателей ежемесячной нагрузкой. Да и ответов от внешних сервисов зачастую приходится ждать долго.
Как вариант можно использовать тот же Libre Translate либо по API, либо подняв свой инстанс (для скорости). Но он конечно не панацея для всего, поэтому ищу нормальный ИИ. Может после выход GPT 4,5 или GPT 5 цена на 4 упадет. А вот качества его для перевода вполне достаточно.theurus
13.01.2024 08:21Либра транслейт это аналог Гугл транслейта, он просто переводит, подсказки не понимает. Может перевести слово logs как брёвна и ничего ты с этим не сделаешь. То есть тут он вообще не подходит.

mrprogre
Спасибо, интересно было почитать! Я реализовал так: на английском спрашиваю на старте на каком языке человек хочет получать новости (de, es, fr, ru, en), далее либо всё на русском, либо на английском, а источники новостей будут на выбранном языке. Ну и в коде текст тоже как одна переменная, которой присваивается значение исходя из выбранного языка.![]()
![]()
Kkeiv Автор
Спасибо за отзыв. У меня есть опасения что если человек увидит первую надпись сразу на английском, то может отказаться от дальнейшего знакомства с функционалом и поискать что-то на своем языке. Т.к. телеграм это все-таки наиболее русскоязычная аудитория, я бы предложил смотреть язык из запроса пользователя и хотя бы для русскоязычной аудитории начинать общение на их языке.
А вы не пробовали посчитать сколько людей заходило в бот и сколько прошло дальше первого запроса?
mrprogre
Да, думал об этом, добавлю выбор языка интерфейса первым делом после старта. Я явно пока не делал функционала подсчёта, просто захожу в БД и вижу пользователей, а в лог пишутся команды, которые они выполняли, кстати много поправил исходя из этого. Юзеры творят нереальную, нелогичную дичь. Я больше самоучка в Java, поэтому удивляюсь :)) Планирую снять видео с обзором бота и кодом. Кстати классный у Вас бот, заценил!
Kkeiv Автор
Спасибо, надеюсь бот будет становиться только лучше.
Да, пользователи непредсказуемы. Кстати по вашему комментарию я задумался, что до этого интересовался только "чем занимаются пользователи в кокой-то точке бота" и упустил, что возможно интересно посмотреть чем заснимается пользователь в боте. Т.е. посмотреть путь движения пользователей по боту. Надо будет добавить и поанализировать.