
Предисловие
Судя по вакансиям на hh.ru, у некоторых компаний в русскоязычном сегменте наступила стадия принятия необходимости введения должности "Эксперт НСИ", хотя бы в виде функциональной роли.
Аббревиатурой "НСИ" (нормативно-справочная информация) в компаниях может обозначаться достаточно широкий спектр источников информации, как структурированной (например таблицы единиц измерения или кодов операций в учётных системах и другие нетранзакционные данные), так и неструктурированной (тексты государственных или отраслевых стандартов, корпоративных организационно-распорядительных документов и т.д.).
Нормализация и классификация записей справочников НСИ, в том числе справочника Номенклатур - одна из типовых функциональных обязанностей, входящих в описание роли "Эксперт НСИ".
Технически справочник НСИ в учётных системах может представляться в виде набора связанных таблиц в базе данных учётной системы, за содержание которых должен бы назначаться ответственный от бизнеса или группа таковых.
На практике, если ответственные не назначены или каждый назначенный руководствуется собственными интуитивными правилами наполнения контента, в справочниках возникают записи:
неполные (отсутствуют обязательные атрибуты)
некорректные (несуществующие либо противоречивые сочетания значений атрибутов)
дублирующиеся
излишне детализированные (например для изделия указывается поставщик)
Когда таких записей в учётной системе становится достаточно много (в реальных системах в результате нормализации количество записей сокращалось в ~3 раза - с ~250тыс до ~80тыс), они становятся реальной проблемой и источником убытков для бизнеса, в том числе из-за закупок несоответствующей продукции.
Исправлением таких записей и приведением их к "эталонному" виду (в англоязычных публикациях - golden records) и занимаются Эксперты НСИ в процессе "нормализации".
В результате такой работы формируется "эталонный" справочник, который по идее должен стать единым достоверным источником (в англоязычных публикациях - single source of truth) для всех систем компании.
Типовые операции в работах по нормализации справочника Номенклатур
Если не вдаваться в нюансы, упрощённо при нормализации справочника Номенклатур выполняются операции:
Профилирование, в т.ч. выделение однородных групп записей
-
По каждой однородной группе:
Описание шаблона эталонной записи, включая:
формирование списка обязательных атрибутов и определение порядка их следования
составление вспомогательных справочников допустимых значений атрибутов и сочетаний значений атрибутов
Приведение каждой записи к шаблону эталонной, включая:
Токенизацию (лексический анализ)
Сопоставление токенов (лексем) значений атрибутам
Формирование эталонной записи по шаблону
Отбраковка дублирующихся, неполных и некорректных записей
Пример исходных данных
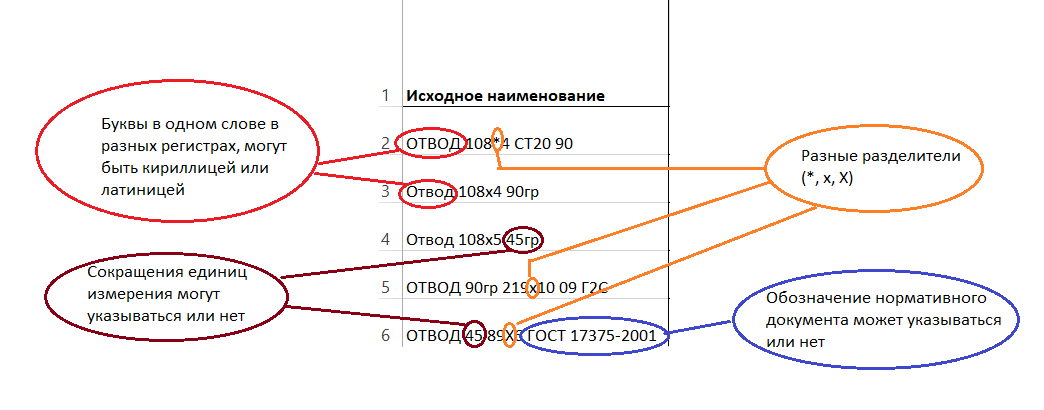
Для примера приведём список отводов по ГОСТ 17375, которые необходимо преобразовать (привести к эталонному виду).
ОТВОД 108*4 СТ20 90
Отвод 108х4 90гр
Отвод 108х5 45гр
ОТВОД 90гр 219х10 09Г2С
ОТВОД 45 89Х6 ГОСТ 17375-2001
Примечание. Исходные записи отводов сгенерированы произвольным образом. Все возможные совпадения с выборками из реальных справочников являются случайными.
Пример – упрощённый, без погружения в нюансы, однако позволит составить представление о способах выполнения типовых операций.
Несложно заметить, что отводы в исходном списке записаны разными способами.
Некоторые несоответствия в записях исходного списка отображены на рисунке ниже:
Для устранения несоответствий и формирования эталонных записей необходимо выполнить типовые операции по нормализации.
В результате нормализации Экспертом НСИ “вручную” может быть получена таблица с характеристиками и эталонными записями примерно в таком виде:

OpenRefine в контексте выполнения типовых операций по нормализации справочников
Хотя достаточно традиционным и распространённым инструментом для выполнения типовых операций Экспертами НСИ является MS Excel, здесь хотелось бы обратить внимание на наличие и других инструментов, в частности OpenRefine.

OpenRefine – это мощный бесплатный опенсорс инструмент для очистки и преобразования данных.
Достоинства:
Бесплатен
С открытым исходным кодом
Запускается локально, не требует доступа в интернет, в этом смысле безопасен, имеет многоязычный интерфейс, включает русский
Обладает обширным гибким (программируемым) функционалом, поддерживается и активно развивается сообществом
Недостатки:
Высокий порог входа – довольно сложен в освоении
Не самый дружелюбный интерфейс пользователя
Сайт:
https://openrefine.org/
https://github.com/OpenRefine/OpenRefine
Пример выполнения некоторых типовых операций при нормализации с помощью OpenRefine
В данном разделе не предполагается ознакомление со всем обширным функционалом OpenRefine, даже не предполагается обзор функционала OpenRefine.
Информацию из этого раздела следует рассматривать как краткое руководство по быстрому запуску OpenRefine для Экпертов НСИ, которые хотели бы присмотреться к этому инструменту.
В примере ниже будут продемонстрированы отдельные специализированные возможности OpenRefine для выполнения типовых операций по нормализации.
Запуск OpenRefine
В системах Linux и MacOS запуск осуществляется из командной строки; в системе MS Windows – двойным кликом по иконке, которая появляется на рабочем столе после установки.
При штатном запуске открывается окно браузера по умолчанию с адресной строкой 127.0.0.1:3333.
После запуска можно выбрать язык интерфейса

Загрузка Excel-файла с исходными записями
Для обработки файла с исходными записями необходимо загрузить его и создать проект.
После выбора файла необходимо указать параметры загрузки – выбрать листы для иморта, если это Excel-файл, можно также указать тип файла, если система не определила его автоматически, и т.д.

Разбор файла данных
После создания проекта можно приступать к разбору данных.
На этом шаге отделим первое/ключевое слово для его последующей нормализации.
Для этого разобьём колонку “Исходное наименование” на 2 колонки, используя регулярное выражение “[ ]+” (группа пробелов) как разделитель, без удаления исходной колонки.


Результат разбиения исходной колонки
Слово “Отвод” в различных написаниях - теперь в колонке “ Исходное наименование 1”

Нормализация слова «Отвод» — отображение фасета
Теперь можно нормализовать слово “Отвод” – свести все варианты написания в колонке “ Исходное наименование 1” к одному.
Для этого воспользуемся функционалом “Фасет”.
Нужно выбрать колонку, по которой будут выделены фасеты (уникальные варианты слова “Отвод” в данном случае) и выбрать опцию “Текстовый фасет”

Отображение фасета
Уникальные варианты написания слова “Отвод” отображаются в левой панели, на вкладке “Фасет/фильтр”
Варианты слов можно откорректировать (привести к одному) в левой панели вручную, но в реальных ситуациях, когда вариантов много, удобнее воспользоваться функционалом “Кластер”

Функционал «Кластер» для фасета
По нажатию кнопки «Кластер» на вкладке «Фасет/фильтр» левой панели выполняется кластеризация и система предлагает варианты приведения различных написаний к одному виду.
Доступны несколько методов кластеризации и функций ключей.

Результат объединения кластеров
После выбора подходящего целевого значения ячейки (в данном случае – “Отвод”) система устанавливает данное значение во всех строках кластера

...и так далее – выполняются операции разбиения либо выделения значений характеристик с последующей их нормализацией. Нормализованные компоненты впоследствии можно собрать в эталонную запись

Эталонные записи из полученного в результате выполнения типовых операций проекта можно выгрузить (экспортировать) в один из доступных форматов (csv, xlsx, json и др.), решив тем самым задачу нормализации группы исходных записей.
В итоге может быть получена таблица, приближённая по форме и содержанию к представленной ранее, полученной Экспертом НСИ вручную, но с меньшими усилиями.
Необходимо отметить, что все операции с OpenRefine выполняются на локальном компьютере, без передачи записей (которые могут быть конфиденциальными) в Интернет, за исключением операций сверки с внешним источником.
Использование инструментов на базе GPT/LLM в контексте выполнения типовых операций по нормализации справочников
В связи с распространением и доступностью онлайн инструментов, построенных на базе технологий GPT/LLM ("Generative Pre-trained Transformer/Large Language Model" - Генеративная предварительно обученная трансформерная/большая языковая модель), логично попытаться применить данные инструменты для выполнения типовых операций по нормализации справочников.
Для этого необходимо корректно сформулировать задачу для GPT+LLM – инструмента. Задача формулируется в виде “промпта” (подсказки-инструкции).
Используем для нашего примера следующий промпт:
Нужно выполнить нормализацию записей так, как это делает эксперт НСИ (data steward). |
Встроенный в скайп Bing AI сгенерировал следующую таблицу в рамках ответа:

Текстовка ответа здесь не приводится, т.к. любой желающий при наличии доступа может воспроизвести ответ этим же инструментом.
Необходимо отметить (и это справедливо для всех доступных онлайн моделей), что записи передаются через сеть Интернет и обрабатываются внешним сервисом, поэтому имеется риск утечки данных.
Кроме того, по умолчанию Bing AI привел все буквы к верхнему регистру и дополнил пропущенные значения, что не всегда допустимо. Такие моменты, впрочем, корректируются уточнением в промпте либо постобработкой полученной таблицы.
Ещё один доступный по адресу https://gpt.h2o.ai онлайн инструмент [Model: gpt-3.5-turbo-0613] сгенерировал следующую таблицу:

Несмотря на то, что порядок характеристик в эталонных записях не соответствует ГОСТ 17375 (значение угла в градусах должно быть первым после слова “Отвод”), характеристики названы и значения отнесены к соответствующим характеристикам корректно, так что после небольших доработок со стороны Эксперта НСИ требуемый результат может быть получен относительно небольшими усилиями.
Выводы
Рассмотрены некоммерческие (не требующие лицензионных отчислений) инструменты для выполнения Экспертами НСИ типовых операций по нормализации справочников на примере небольшой выборки справочника Номенклатур.
В OpenRefine все операции выполняются на локальном рабочем месте под полным контролем Эксперта НСИ. Инструмент обладает достаточным функционалом для выполнения типовых операций по нормализации справочников и с этой точки зрения является приемлемой альтернативой MS Excel – подобных продуктов.
В несложных случаях для выполнения типовых операций при отсутствии жёстких требований к нераспространению исходных записей могут быть использованы инструменты на базе GPT/LLM технологий, как доступные онлайн, так и развёрнутые локально (при наличии достаточных вычислительных мощностей).
Послесловие
Отступление относительно выбора источника эталонных записей
Распространённая практика использовать существующий справочник Номенклатур в качестве источника эталонных записей имеет существенный недостаток – в справочнике могут встречаться значения либо сочетания значений характеристик, не предусмотренные стандартом на изделие.
Например, “Отвод 99-89х10 ГОСТ 17375”, хотя такая запись может оказаться в справочнике, не предусмотрен ГОСТ 17375, т.к. допустимые углы по этому ГОСТ – 45,60,90,180 градусов, а сочетание наружного диаметра торца отвода и толщины стенки 89х10 мм отсутствует в таблицах параметров исполнений, хотя отдельно наружный диаметр 89 мм и толщина стенки 10 мм встречаются, например в изделиях с параметрами 89х8 и 102х10.
Известно несколько альтернативных решений задачи выбора достоверных внешних источников для справочника Номенклатур.
Ассоциация ECCMA (eccma.org, ведущая организация-разработчик серии ИСО 22745 стандартов НАТО) предлагает в качестве эталонного источника глобальный каталог продукции, являющийся частью открытого технического словаря eotd.org, включающего по состоянию на конец 2023 года более 6 млн записей о продукции от поставщиков и производителей, в основном англоязычных.
В Республике Казахстан существует ЕНС ТРУ (enstru.kz) - Единый номенклатурный справочник товаров, работ и услуг, в Республике Беларусь – ГСКП (gskp.by) - Государственный каталог продукции. В Российской Федерации - Федеральный каталог продукции под эгидой Центра каталогизации и информационных технологий.
Однако на корпоративном уровне основным источником данных часто остаётся корпоративный справочник, который после нормализации собственными силами или с привлечением внешнего подрядчика объявляется эталонным. Перевод справочника в статус эталонного, однако, не исключает как наличие ошибок, пропущенных в ходе нормализации, так и накопление новых из-за человеческого фактора даже при наличии внедрённой системы управления НСИ.
Экзотические инструменты нормализации
Для отдельных групп стандартизованной номенклатуры существуют технологические решения на основе графов знаний (OWL/RDF-онтологий, демо-пример для англоязычных стандартов по фиттингам - https://v1st.shinyapps.io/stdtd-gui-app/ ), позволяющие генерировать эталонную запись по записи в корпоративном справочнике номенклатур. Однако существующая форма представления стандартов (и других нормативных документов) мало приспособлена к автоматической обработке. Построение же графа знаний по исходным текстам стандартов в формате pdf довольно трудозатратно, хотя вполне возможно.
Если исходные записи нормализованы в OpenRefine, имеется возможность трансформировать историю операций OpenRefine в OWL/RDF-онтологии с помощью экспериментального приложения https://v1st.shinyapps.io/stdgont-app/.
Комментарии (8)

aborouhin
14.01.2024 14:37В недостатки OpenRefine ещё зверский аппетит на RAM надо бы записать. Имеющихся у меня под рукой 192 Гб на некоторые толстые CSVшки из наших государственных данных не хватало.

v1st Автор
14.01.2024 14:37Есть такой момент. С другой стороны - типичный справочник номенклатуры компании нефтегазового сектора (из тех, что проходили через мои руки) - 200-250тыс записей, которые пилятся на 100-5000 однородных групп по 0,01-10 тыс записей. На такие объемы для Openrefine достаточно 8-16Гб ОЗУ.

economist75
14.01.2024 14:37+1OpenRefine хорош, плюсую. есть близкие аналоги, например MitoSheet. Но для подобного ПО нужна крепкая мышь и любовь-терпение в визуальной настройке. Для многих кодеров и DS-ников "длительная" мышь утомительна.
На мой взгляд наибольшее число работ по нормализации НСД пока делаются в Pandas+JupyterLab, поскольку легко разделить работу (коллаборация из коробки), плюс на python легко пишутся UDF для чистки, а fuzzy-алгоритмы для сопоставления грязных данных хорошо масштабируются с отраслевой спецификой.
Ivan22
Почему в статье про MDM нет упоминания MDM ?
sergeyns
! Классное замечание!
v1st Автор
Чем может помочь статье про инструменты нормализации данных упоминание МДМ?
Экспертам НСИ (целевой аудитории статьи) необязательно задумываться о том, что их активность встроена в бизнес -процессы по управлению мастер-данными. Но если есть конструктивные предложения - можно и про МДМ написать.
Ivan22
потому что это НСИ - это часть большой системы MDM. А для управления мастер-данными придумано множество подходов и существуют десятки тулов, кроме этого который в статье
v1st Автор
Обзор МДМ систем и их инструментария - тема отдельной статьи, если не диссертации, которая устареет в момент публикации. Этим периодически издательство Гартнер балуется с магическими квадрантами. Здесь решалась задача попроще.