
Эта статья описывает, как из прогнозов ряда ML-моделей получить ценность клиента с горизонтом в 5 лет. Напомним, что показатель CLTV представляет из себя композицию прогнозов ее компонент (подробнее в статье). В нашей реализации максимальный период прогнозирования моделей — 24 месяца. Важно отметить, что чем выше горизонт прогнозирования, тем менее точный прогноз способна сделать модель. А показатель CLTV интересен бизнесу на более длинном горизонте, в нашем случае - пять лет. Как же из прогнозов на два года получить прогноз на пять лет? Ответ прост: экстраполировать прогнозы.
Основная идея продления (экстраполяции) прогнозов - это разбиение пользователей на несколько групп, а в каждой группе единообразно продлить ряд прогноза.
Далее мы обсудим:
подходы к экстраполяции ряда, их достоинства и проблемы
как выбирать группы и подготовить данные для экстраполяции
достоинства выбранного подхода к продлению прогнозов на 5 лет, трудности и пути их решения.
1. Подходы к экстраполяции
Итак, давайте разберемся, что же нам нужно экстраполировать и как это можно сделать. Нам доступны помесячные прогнозы каждой из компонент CLTV на 24 месяца. Конечная цель - вывести некоторые коэффициенты, при помощи которых мы, имея прогноз на 24 месяцев, можем получить прогноз на 25, 26, 27, … 60 месяц . Для этого необходимо экстраполировать или продлить ряд прогнозов.
Для построения коэффициентов нам доступны исторические и прогнозные данные.
На наш взгляд, расчет коэффициентов на исторических данных (факте) имеет много недостатков, поскольку на их изменение влияет множество внешних факторов (изменение стоимости тарифных планов, кризисы, действия конкурентов), влияние которых мы хотим избежать и изучать отдельно в рамках экспериментов и тестов. Кроме того, для 5-ти летних коэффициентов экстраполяции пришлось бы использовать очень старые исторические данные, что привело бы к неактуальным значениям коэффициентов. Например, поведение абонентов (в частности, выживаемость) в последний год отличается от их поведения 3 года назад. По этой же причине ML модели не предсказывают выручку и затраты на 5-ти летнем горизонте. К достоинствам этого подхода можно отнести доступность информации о фактических колебаниях сервисной маржи на длинных горизонтах. В результате применения такого подхода, если база с каждым годом улучшается, мы получим заниженные оценки коэффициентов. Исторические данные нами использовались только для валидации.
По причинам описанным выше для построения коэффициентов были использованы прогнозные значения. Для экстраполяции мы строили регрессии, имея более-менее монотонно убывающие/возрастающие ряды прогнозов. Однако не всегда можно увидеть такую зависимость в ряде данных, в таком случае можно посмотреть на ряд прогнозов, посчитанных с накопительным итогом и так прийти к монотонности.
Пример: есть ряд наблюдений за 2 года для базы пользователей, активных в декабре 2021 года (зафиксировали группу пользователей). Наблюдение = сумма выручки, которые мы спрогнозировали на 1, 2, 3 ... 24 месяцев вперед. Описанный ряд изобразим синей линией, на графике, где ось абсцисс - месяц прогноза, ось ординат - выручка. Видим, что синяя линия поначалу убывает, а потом колеблется вокруг нуля. Оранжевым изображен ряд, посчитанный накопительным итогом - в нем видна явная логарифмическия зависимость между накопленным прогнозом выручки и месяцем прогноза.
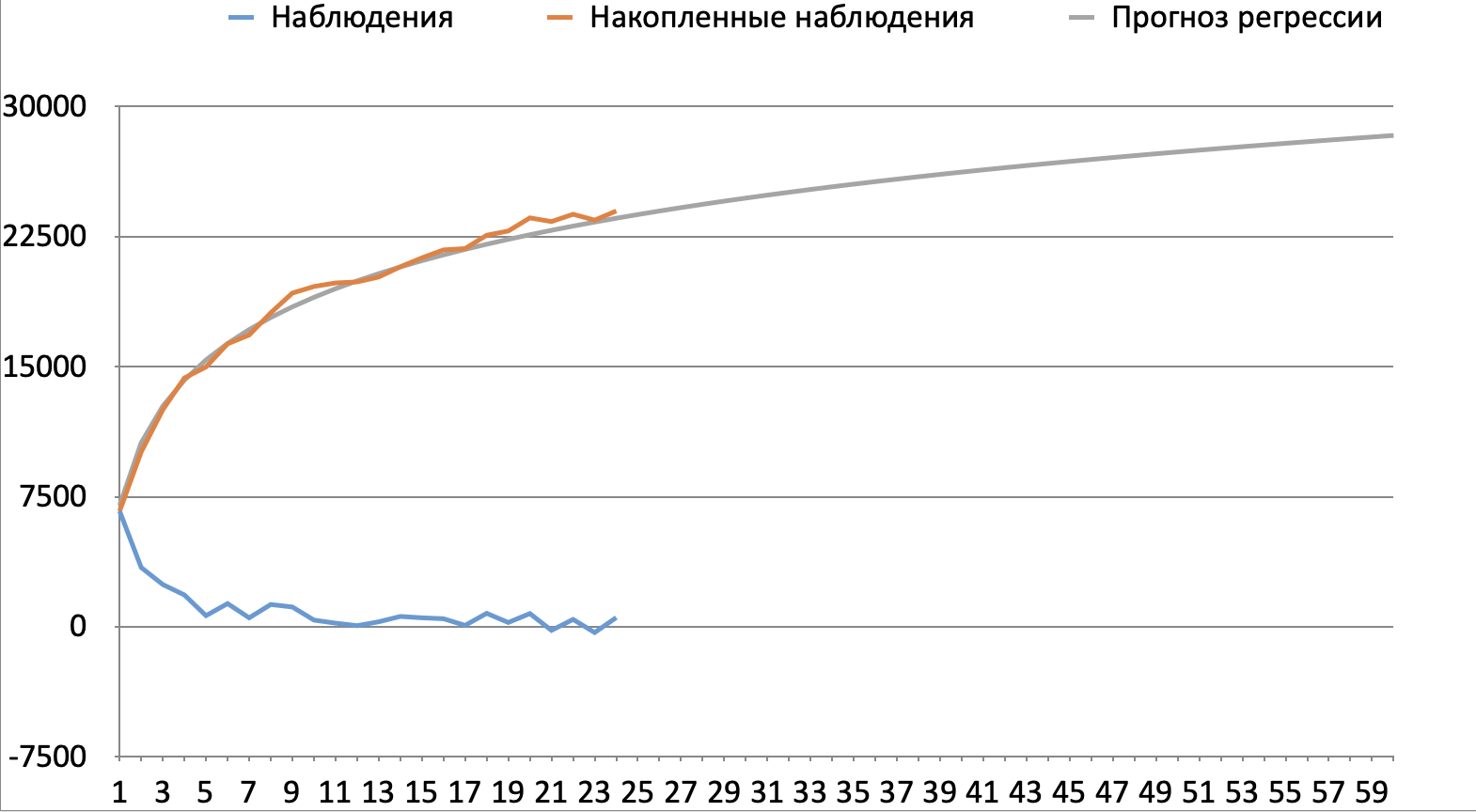
Данные для графика
Факт маржи |
Накопленный факт |
Прогноз |
период |
|
2020-01-01 |
6666 |
6666 |
7000 |
1 |
2020-02-01 |
4199,3599479678 |
10865,3599479678 |
10612,3599479678 |
2 |
2020-03-01 |
2683,0951086681 |
13548,4550566359 |
12725,4550566359 |
3 |
2020-04-01 |
1245,2648392996 |
14793,7198959355 |
14224,7198959355 |
4 |
2020-05-01 |
1263,9201560967 |
16057,6400520322 |
15387,6400520322 |
5 |
2020-06-01 |
949,1749525715 |
17006,8150046037 |
16337,8150046037 |
6 |
2020-07-01 |
658,3614755674 |
17665,1764801711 |
17141,1764801711 |
7 |
2020-08-01 |
423,9033637322 |
18089,0798439033 |
17837,0798439033 |
8 |
2020-09-01 |
781,8302693686 |
18870,9101132719 |
18450,9101132719 |
9 |
2020-10-01 |
15,0898867281 |
18886 |
19000 |
10 |
2020-11-01 |
1090,7122218988 |
19976,7122218988 |
19496,7122218988 |
11 |
2020-12-01 |
619,4627306726 |
20596,1749525714 |
19950,1749525714 |
12 |
2021-01-01 |
784,1452751107 |
21380,3202276821 |
20367,3202276821 |
13 |
2021-02-01 |
547,2162004568 |
21927,5364281389 |
20753,5364281389 |
14 |
2021-03-01 |
221,5586805293 |
22149,0951086682 |
21113,0951086682 |
15 |
2021-04-01 |
194,3446832028 |
22343,439791871 |
21449,439791871 |
16 |
2021-05-01 |
-22,0527353318 |
22321,3870565392 |
21765,3870565392 |
17 |
2021-06-01 |
582,8830047005 |
22904,2700612397 |
22063,2700612397 |
18 |
2021-07-01 |
-275,2268498057 |
22629,043211434 |
22345,043211434 |
19 |
2021-08-01 |
131,3167365338 |
22760,3599479678 |
22612,3599479678 |
20 |
2021-09-01 |
-318,7284111608 |
22441,631536807 |
22866,631536807 |
21 |
2021-10-01 |
426,4406330595 |
22868,0721698665 |
23109,0721698665 |
22 |
2021-11-01 |
21,6618623446 |
22889,7340322111 |
23340,7340322111 |
23 |
2021-12-01 |
389,8008683282 |
23279,5349005393 |
23562,5349005393 |
24 |
2022-01-01 |
-77,2547964748 |
23202,2801040645 |
23775,2801040645 |
25 |
2022-02-01 |
605,4000715853 |
23807,6801756498 |
23979,6801756498 |
26 |
2022-03-01 |
517,6849942581 |
24325,3651699079 |
24176,3651699079 |
27 |
2022-04-01 |
513,5312061987 |
24838,8963761066 |
24365,8963761066 |
28 |
2022-05-01 |
82,8795986809 |
24921,7759747875 |
24548,7759747875 |
29 |
2022-06-01 |
572,6790818484 |
25494,4550566359 |
24725,4550566359 |
30 |
2022-07-01 |
657,8852693753 |
26152,3403260112 |
24896,3403260112 |
31 |
2022-08-01 |
-7,5405861723 |
26144,7997398389 |
25061,7997398389 |
32 |
2022-09-01 |
-77,6324613042 |
26067,1672785347 |
25222,1672785347 |
33 |
2022-10-01 |
92,5797259724 |
26159,7470045071 |
25377,7470045071 |
34 |
2022-11-01 |
693,0695276963 |
26852,8165322034 |
25528,8165322034 |
35 |
2022-12-01 |
-74,1865229959 |
26778,6300092075 |
25675,6300092075 |
36 |
2023-01-01 |
579,7906795964 |
27358,4206888039 |
25818,4206888039 |
37 |
2023-02-01 |
735,9824705978 |
28094,4031594017 |
25957,4031594017 |
38 |
2023-03-01 |
-29,6278750837 |
28064,775284318 |
26092,775284318 |
39 |
2023-04-01 |
-180,0553883825 |
27884,7198959355 |
26224,7198959355 |
40 |
2023-05-01 |
-339,3136152986 |
27545,4062806369 |
26353,4062806369 |
41 |
2023-06-01 |
154,5852041379 |
27699,9914847748 |
26478,9914847748 |
42 |
2023-07-01 |
621,6299821803 |
28321,6214669551 |
26601,6214669551 |
43 |
2023-08-01 |
497,8106508792 |
28819,4321178343 |
26721,4321178343 |
44 |
2023-09-01 |
460,1180474698 |
29279,5501653041 |
26838,5501653041 |
45 |
2023-10-01 |
93,5438148747 |
29373,0939801788 |
26953,0939801788 |
46 |
2023-11-01 |
361,0803150498 |
29734,1742952286 |
27065,1742952286 |
47 |
2023-12-01 |
-450,2794467215 |
29283,8948485071 |
27174,8948485071 |
48 |
2. Подготовка данных
Если посмотреть на ряды прогнозов одной и той же метрики для разных абонентов, мы увидели, что для одних абонентов эти ряды растут сильнее, для других - слабее, для третьих - убывают. Тогда если мы экстраполируем все ряды одинаковыми коэффициентами, получим на одних абонентах завышенные показатели, на других - заниженные, но в среднем на всех - хорошие. При этом, если мы будем строить отдельно коэффициенты для каждого абонента, то не сможем гарантировать такую правильную форму кривой ряда, какую мы увидели на совокупности абонентов. Середина между двумя крайностями - делить базу на крупные сегменты. Мы делим абонентскую базу на сегменты, поведение абонентов (выживаемость, выручка, затраты) в которых существенно различаются между собой, но имеют схожую динамику изменений внутри сегмента. При таком подходе при увеличении того или иного сегмента общий показатель лучше подстраивается под изменения. Сегменты могут быть выбраны экспертно или на основании кластерного анализа.
В билайн для определения сегментов использовались комбинации:
стаж клиента в компании (lifetime). У себя мы выделяем 0-3 месяцев, 4-12 месяцев, 13+ месяцев
соцдем-характеристики клиента
географическая принадлежность клиента
активность клиента за последние год/полгода/месяц и прочее
Обозначим каждую группу характеристик номером как в списке. Пусть признак 1 принимает К1 = 5 значений, фича 2 К2 = 6 , К3 = 8. В итоге получается К1*K2*K3 = 5*6*8*10 = 240 сегментов. Пример такого сегмента - абоненты с lifetime от года из северных регионов и активные на конец периода.
Далее возникает вопрос, за какой период брать выборку для расчета коэффициентов. Мы пробовали 2 подхода: 10% сэмпл базы за несколько лет и всю базу за последние полгода. Победил 2 вариант, так как сокращение периода сбора предсказаний позволяет уловить актуальное поведение абонентов.
Итак, мы сформировали некоторую выборку клиентов за последние 6 месяцев, подтянули к ним их характеристики, позволяющие понять, к какому сегменту относится каждый абонент. Далее подтягиваем к этой таблице доступные нам на данный момент помесячные прогнозы некоторой компоненты CLTV. В случае компоненты SM Mobile, получаем таблицу следующего вида:
ID клиента |
Отчетная дата |
Х-ка 1 |
Х-ка 2 |
Сегмент |
Прогноз маржи на 1 месяц вперед |
Прогноз маржи на 2 месяца вперед |
… |
Прогноз маржи на 24 месяца вперед |
123456 |
2023-02-01 |
1 |
South |
1_South |
110 |
100 |
... |
80 |
123456 |
2023-03-01 |
1 |
South |
1_South |
100 |
98 |
... |
78 |
234567 |
2023-03-01 |
0 |
West |
0_West |
3 |
0 |
... |
-20 |
Далее внутри отчетной даты и сегмента вертикализируем ряд прогнозом на 1-24 месяц для удобства, получаем 24 строки вместо 24 столбов с прогнозами ранее с рядами y1, y2, y3, y4, ... y24 для каждого сегмента.
Отчетная дата |
Х-ка 1 |
Х-ка 2 |
Сегмент |
Сумма прогнозов маржи на k-тый месяц вперед |
Месяц прогноза (месяц k, где к от 1 до 24) |
Количество клиентов в сегменте в отчетный месяц |
2023-02-01 |
1 |
South |
1_South |
100 000 000 |
1 |
1 000 000 |
2023-03-01 |
1 |
South |
1_South |
100 020 000 |
2 |
1 000 200 |
2023-03-01 |
0 |
West |
0_West |
30 000 000 |
22 |
500 000 |
3. Экстраполяция
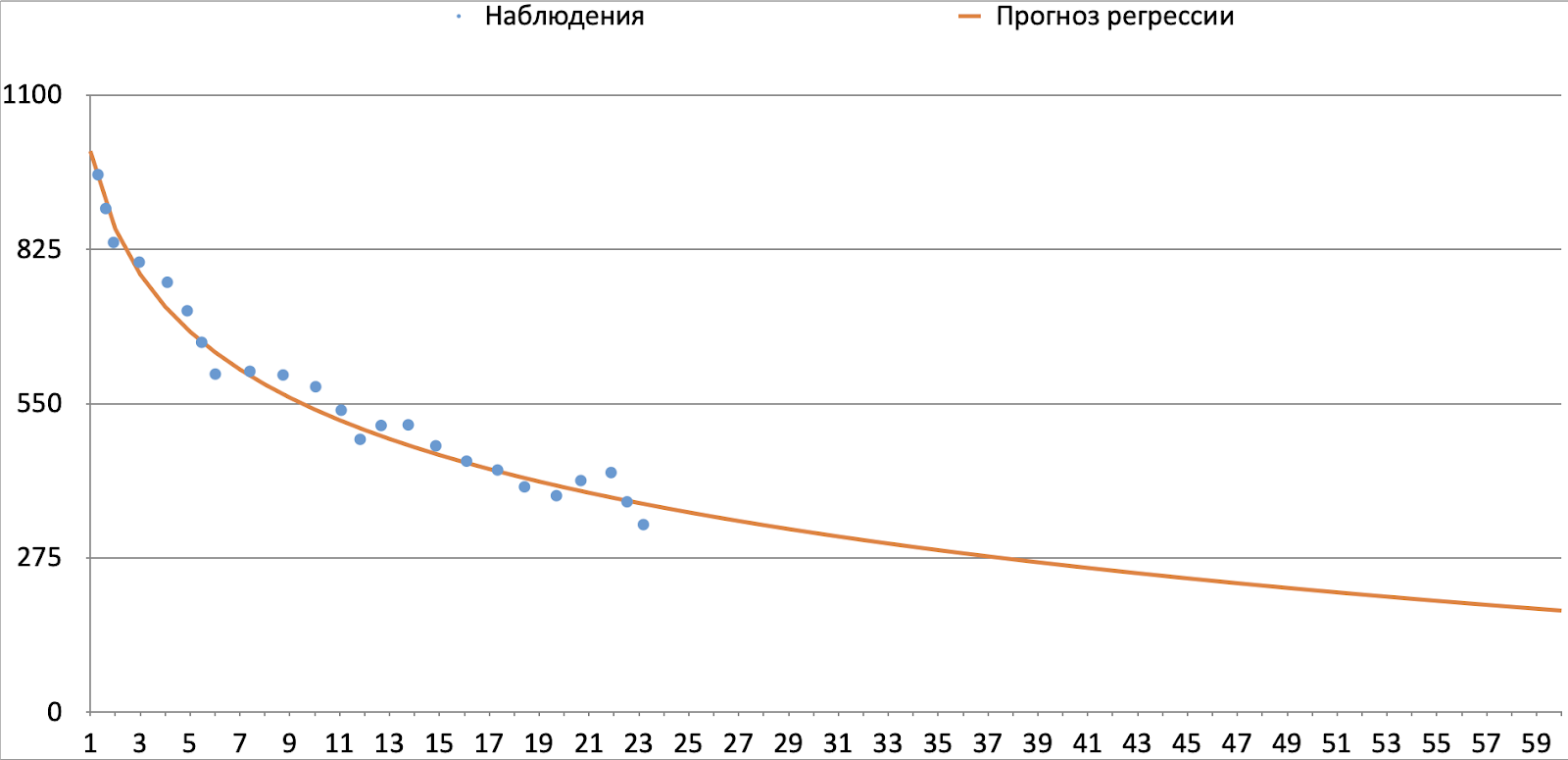
На графике ниже приведена динамика факта и прогноза для некоторой когорты клиентов (например, активных в декабре 2019 года с lifetime от года из северных регионов). Видим, что средний факт и прогноз маржи убывают с ростом периода из-за фактора выживаемости. Прирост с ростом периода становится все меньше и меньше стремится к определенному значению, не пересекая 0 значение, так как большинство прогнозируемых метрик не могут принимать отрицательные значения (гб, минуты, доход). Также можно отметить выпуклость кривой вниз. Запросим от нашего уравнения эти свойства: монотонное убывание, выпуклость вниз, непересечение оси абсцисс (не для всех компонент верно это условие, в некоторых случаях ряд стремится к некоторому отрицательному значению и пересекает ось абсцисс. В таком случае константа будет отрицательной). Заявленным условиям удовлетворяет

Для каждого сегмента строим по модели, которая будет описывать зависимость компоненты CLTV от месяца предсказания уравнением
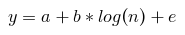
(можно сделать это в цикле, строить парную регрессию для каждого сегмента, а можно добавить в уравнение переменную, отвечающую за сегмент и домножить ее на x). Для расчета коэффициентов используем последние 6 месяцев прогноза - 6 поколений (где поколение = группа абонентов, для которых доступен прогноз на 24 месяца вперед на рассматриваемый месяц). Таким образом, исходная таблица - это список абонентов за последние 6 месяцев, их прогнозы на каждый из 6 месяцев на 2 года вперед и ряд характеристик абонентов, которые позволяют определить, к какому сегменту относится абонент.
Будем строить парную регрессию для каждого сегмента в цикле.
Итак, в каждом сегменте для каждой когорты у нас есть ряд прогнозов на 1,2,3,..12,...24 месяцев вперед, экстраполируем его методом наименьших квадратов (мы использовали statsmodels). Спецификацию (формулу, как зависит у от х, логарифмически, линейно, экспоненциально ...) уравнения выбираем на основании вида ряда предиктов и ряда фактов. Для выбора наиболее подходящей спецификации можно использовать тест Рамсея и другие тесты на спецификацию.
Код ниже помогает создать список коэффициентов продления для выбранного сегмента сегмента segm, строит саммари и график модели для данного сегмента, можно удобно посмотреть основные статистики модели.
import numpy as np
import math
import pandas as pd
import statsmodels.api as sm
import statsmodels.formula.api as smf
# df - таблица с рядами суммарных прогнозов по сегментам
SEGM = '...' # выбранный сегмент для расчета
df_segm = df[df['segment'] == SEGM]
form_reg = '(service_margin) ~ 1 + np.log(period_key)'
model = smf.ols(formula=form_reg, data=df_segm)
result = model.fit()
# вынимаем a и b из y = a + b(ln(x))
a = result.params[0]
b = result.params[1]
# смотрим саммари
print(result.summary())
N_PRED_HORIZON = 24
y_fact = list(df_segm['service_margin'])
y_pred = []
for period in range(1,25):
y_pred+=[a+b*np.log(period)]
for period in range(25,61):
y_fact+=[a+b*np.log(period)]
y_pred+=[a+b*np.log(period)]
segment_coeffs = y_pred[N_PRED_HORIZON:]/y_pred[N_PRED_HORIZON-1]
# строим прогноз и факт на 1 графике
print(segm)
plt.plot(y_fact, label="y_fact")
plt.plot(y_pred, label="y_pred")
plt.legend(loc="upper right")
plt.show()На этом этапе контролируются коэффициенты детерминации (
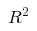
) и адекватность коэффициентов построенных моделей. Далее подставляем для каждого сегмента и периода с 25 по 60, получаем предсказанный
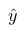
и делим его на
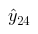
, получаем коэффициент перевода прогноза на 24 месяц в прогноз на выбранный период как в коде выше.
Пример: на сегменте ХХХ после применения МНК получили уравнение
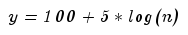
, подставляем в уравнение
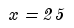
, получаем
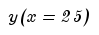
, делим на прогноз на 24 период
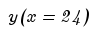
и получаем коэффициент
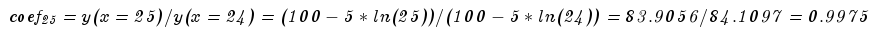
Вместо построения по модели для каждого сегмента можно добавить в уравнение по переменной, отвечающей за каждый сегмент и домножить ее на период. При 240 сегментах уравнение будет выглядеть примерно так
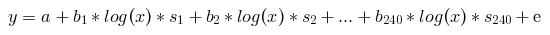
, где s1, s2,... - активные переменные сегментов, принимают значения 0 и 1. Для каждого сегмента только одна переменная s будет равна 1, остальные занулятся, таким образом задача сведется к той же парной регрессии, как мы построили в предыдущем варианте.
4. Проблемы и подходы к их решению
Не учтены важные переменные. (эндогенность) Эта проблема может возникнуть, если наша компонента CLTV сильно зависит от какого-то параметра. В нашем случае этим параметром является количество дней в месяце, от которого зависит в величина месячного платежа в тарифах с подневной оплатой. Отсюда получаем проблему, случайная ошибка больше не случайна, а зависит от количества дней в месяце прогноза, поэтому оценки коэффициентов не состоятельные. В этом случае можно поделить нашу целевую переменную на количество дней в месяце и строить модели для средненевной компоненты.
Временной ряд скоров не повторяет особенности ряда фактов. Эта проблема может возникнуть, если модель в среднем работает хорошо, но в отдельных сегментах завышает прогноз, на других - занижает. Например, на графике ниже ряд прогнозов убывает, ряд фактов - растет. В подобном случае мы продлевали скользящим средним.
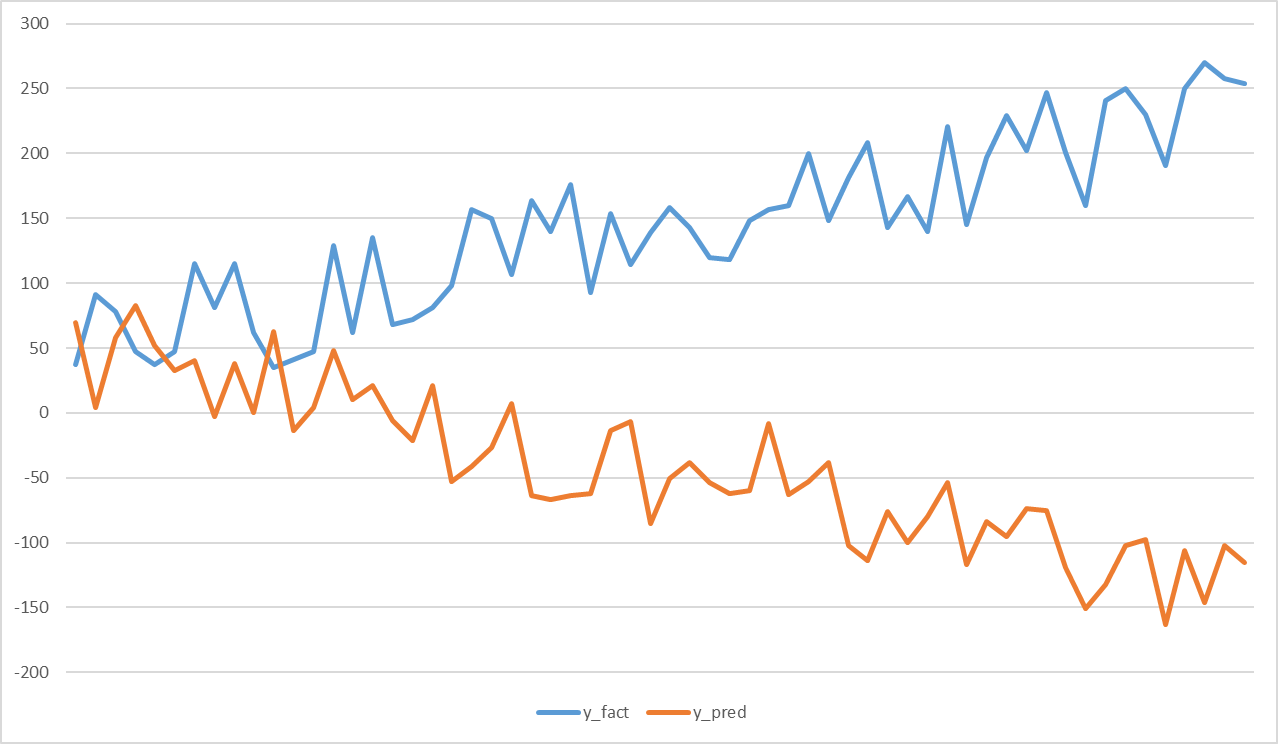
Hidden text
x |
y_fact |
y_pred |
1 |
37 |
70 |
2 |
91 |
4 |
3 |
78 |
58 |
4 |
47 |
83 |
5 |
37 |
52 |
6 |
47 |
33 |
7 |
115 |
40 |
8 |
81 |
-3 |
9 |
115 |
38 |
10 |
62 |
0 |
11 |
35 |
63 |
12 |
41 |
-14 |
13 |
47 |
4 |
14 |
129 |
48 |
15 |
62 |
10 |
16 |
135 |
21 |
17 |
68 |
-6 |
18 |
72 |
-21 |
19 |
81 |
21 |
20 |
98 |
-53 |
21 |
157 |
-41 |
22 |
150 |
-27 |
23 |
107 |
7 |
24 |
164 |
-64 |
25 |
140 |
-67 |
26 |
176 |
-64 |
27 |
93 |
-62 |
28 |
154 |
-14 |
29 |
114 |
-7 |
30 |
139 |
-85 |
31 |
158 |
-51 |
32 |
143 |
-38 |
33 |
120 |
-54 |
34 |
118 |
-62 |
35 |
148 |
-60 |
36 |
157 |
-8 |
37 |
160 |
-63 |
38 |
200 |
-53 |
39 |
148 |
-38 |
40 |
181 |
-102 |
41 |
208 |
-114 |
42 |
143 |
-76 |
43 |
167 |
-100 |
44 |
140 |
-80 |
45 |
221 |
-54 |
46 |
145 |
-117 |
47 |
197 |
-84 |
48 |
229 |
-95 |
49 |
202 |
-74 |
50 |
247 |
-75 |
51 |
201 |
-119 |
52 |
160 |
-151 |
53 |
241 |
-132 |
54 |
250 |
-102 |
55 |
230 |
-98 |
56 |
191 |
-163 |
57 |
250 |
-106 |
58 |
270 |
-146 |
59 |
258 |
-102 |
60 |
254 |
-115 |
3. Первые 1-3 месяца прогноза "скачут" или имеют другой характер кривой. (выпуклая вверх). Такая проблема возникает для свежих и неактивных абонентов, потому что модели отрабатывают на них хуже. В этом случае можно экстраполировать ряд начиная с 4-5 месяца прогноза или рассчитывалось скользящее среднее с окном в 3 месяца и на нем уже строить статистические модели.
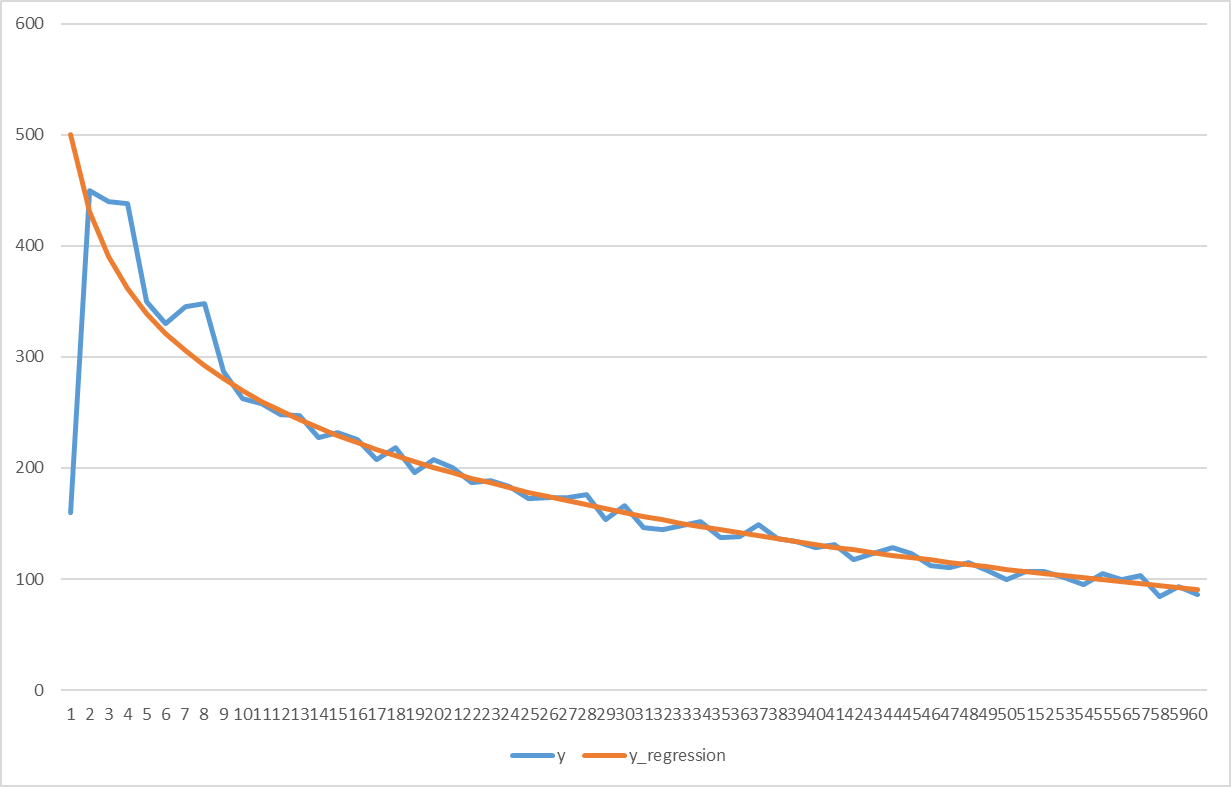
Hidden text
y |
y_regression |
|
1 |
160 |
500 |
2 |
450 |
430,6853 |
3 |
440 |
390,1388 |
4 |
438 |
361,3706 |
5 |
350 |
339,0562 |
6 |
330 |
320,8241 |
7 |
345 |
305,409 |
8 |
348 |
292,0558 |
9 |
287,2775 |
280,2775 |
10 |
262,7415 |
269,7415 |
11 |
258,2105 |
260,2105 |
12 |
248,5093 |
251,5093 |
13 |
247,5051 |
243,5051 |
14 |
227,0943 |
236,0943 |
15 |
232,195 |
229,195 |
16 |
225,7411 |
222,7411 |
17 |
207,6787 |
216,6787 |
18 |
217,9628 |
210,9628 |
19 |
195,5561 |
205,5561 |
20 |
207,4268 |
200,4268 |
21 |
200,5478 |
195,5478 |
22 |
186,8958 |
190,8958 |
23 |
188,4506 |
186,4506 |
24 |
183,1946 |
182,1946 |
25 |
172,1124 |
178,1124 |
26 |
173,1903 |
174,1903 |
27 |
173,4163 |
170,4163 |
28 |
175,7795 |
166,7795 |
29 |
153,2704 |
163,2704 |
30 |
165,8803 |
159,8803 |
31 |
146,6013 |
156,6013 |
32 |
144,4264 |
153,4264 |
33 |
148,3492 |
150,3492 |
34 |
151,3639 |
147,3639 |
35 |
137,4652 |
144,4652 |
36 |
138,6481 |
141,6481 |
37 |
148,9082 |
138,9082 |
38 |
136,2414 |
136,2414 |
39 |
133,6438 |
133,6438 |
40 |
128,1121 |
131,1121 |
41 |
130,6428 |
128,6428 |
42 |
117,233 |
126,233 |
43 |
122,88 |
123,88 |
44 |
128,581 |
121,581 |
45 |
123,3338 |
119,3338 |
46 |
112,1359 |
117,1359 |
47 |
109,9852 |
114,9852 |
48 |
114,8799 |
112,8799 |
49 |
107,818 |
110,818 |
50 |
99,7977 |
108,7977 |
51 |
106,8174 |
106,8174 |
52 |
106,8756 |
104,8756 |
53 |
100,9708 |
102,9708 |
54 |
95,1016 |
101,1016 |
55 |
105,2667 |
99,26668 |
56 |
99,46483 |
97,46483 |
57 |
102,6949 |
95,69487 |
58 |
83,9557 |
93,9557 |
59 |
93,24626 |
92,24626 |
60 |
85,56554 |
90,56554 |
Итак, мы обсудили, какие подходы к экстраполяции могут быть использованы для продления прогнозов до 5-летнего горизонта. О том, что с этими показателями дальше делать, а также об особенностях прогнозирования компонент CLTV расскажут ребята из команды CLTV билайна совсем скоро в следующих статьях.
adeshere
Хороший подход!
Мы в геофизике точно так же какое-то время назад пришли к идее разделения сигнала на физически обусловленные компоненты, с каждой из которых затем можно работать (в том числе прогнозировать) отдельно. И даже реализовали этот подход в своих программах анализа временных рядов. Надеюсь, у вас тоже получится!
Если интересны подробности,
вот несколько ссылок
Рассуждения и примеры применения этой идеи в геофизике есть в публикациях: раз, два, три (ну и см. ссылки оттуда). Полные тексты статей можно скачать здесь. Чуть подробнее "философия" этого подхода (взгляд со стороны геофизики) изложена в справочной системе нашей программы ABD: см. раздел 3.I4 в файле WinABD_Help.chm в каталоге с программой ABD. Саму программу можно скачать там же.