
Одноклеточное РНК-секвенирование (scRNA-seq) – метод изучения экспрессионных профилей на уровне отдельных клеток, то есть определения, какие РНК присутствуют в каждой клетке и в каком количестве. Это позволяет ученым понимать, как функционирует каждая клетка и какие функции она выполняет.
Простыми словами: данный метод помогает понять, какие гены в клетке "включены" и "выключены" в данный момент. Это важно, потому что активные гены определяют, как клетка будет себя вести, например, будет ли она здоровой, превратится ли в раковую, поможет ли она иммунной системе бороться с инфекцией и так далее. Таким образом, РНК-секвенирование применяют для разработки лекарств, при изучении болезней и их лечении, а также для того, чтобы понять, как развиваются и функционируют различные живые организмы на уровне их клеток.
Весь процесс достаточно сложный, но как GPT-4 помогает в его осуществлении? Об этом подробно и доступно я расскажу в этой статье!
Приятного прочтения! :)
Введение в исследование
Данное исследование основывается на использовании большой языковой модели GPT-4 для автоматизации процесса аннотирования типов клеток в данных одноклеточного РНК-секвенирования.
Одноклеточное РНК-секвенирование – это высокотехнологичный метод исследования, который позволяет ученым заглянуть внутрь отдельных клеток и узнать, какие гены в них активны. Каждый ген, который "включен", производит РНК, и именно эту РНК ученые "читают" с помощью секвенирования. Это осуществляется с помощью расшифровки последовательностей нуклеотидов!
Можно представить, что внутри каждой клетки есть небольшой заводик, где гены – это рабочие, которые выполняют разные задачи. Некоторые рабочие активны в определенное время, а другие отдыхают. Одноклеточное РНК-секвенирование как раз и позволяет выяснить, кто из рабочих сейчас "на смене". Это очень важно, поскольку разные типы клеток выполняют разные функции в организме, и активность генов отражает эти функции. Например, клетки печени будут активировать один набор генов, а клетки мозга – совершенно другой :Р
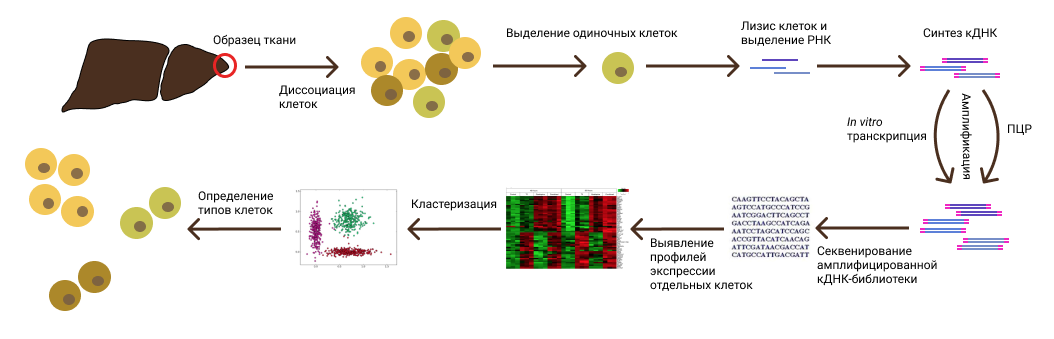
Теперь об аннотировании типов клеток. После того как ученые получили данные от одноклеточного РНК-секвенирования, перед ними стоит задача понять, какие клетки они изучали. Ведь образцы для исследования часто берут из тканей, где содержится множество разных клеток. Аннотирование – это процесс, при котором ученые сопоставляют группы клеток с уже известными типами клеток, основываясь на их генной активности. Если вернуться к аналогии с заводом, то это как если бы вы определяли, что за продукцию выпускает завод, глядя на то, какие рабочие сейчас на смене :)

GPT-4 способен распознавать и классифицировать различные типы клеток, опираясь на информацию о генах-маркерах, то есть о генах, которые специфичны для определенных типов клеток.
Эффективность GPT-4 была проверена на большом количестве типов тканей и клеток, и результаты, полученные моделью, показали высокую степень согласованности с аннотациями, выполненными вручную специалистами. Это означает, что GPT-4 может точно идентифицировать типы клеток внутри сложных биологических образцов, что обычно требует глубоких знаний и много времени при традиционном подходе.
Также был создан специальный программный пакет для языка программирования R, названный GPTCelltype.
Этот пакет как раз и представляет собой инструмент, который позволяет использовать возможности GPT-4 для автоматической аннотации типов клеток, упрощая и ускоряя этот процесс для исследователей.
Таким образом, применение GPT-4 в анализе одноклеточного РНК-секвенирования открывает возможности для уменьшения рабочей нагрузки исследователей и упрощения процесса аннотации, делая его более доступным и менее затратным по времени.
Методы и результаты исследования

GPT-4 обеспечивает экономическую эффективность и непрерывную интеграцию в существующие пайплайны анализа одиночных клеток, такие как Seurat, что исключает необходимость создания дополнительных пайплайнов и сбора высококачественных эталонных наборов данных. Обширный массив обучающих данных GPT-4 позволяет использовать его в широком спектре приложений для различных тканей и типов клеток, а его природа чат-бота дает возможность пользователям уточнять аннотации.
Seurat – это пакет программного обеспечения для R, который разработан специально для анализа данных одноклеточного РНК-секвенирования. Seurat предоставляет пользователям инструменты для качественной обработки данных, идентификации и классификации типов клеток, анализа молекулярных путей и других распространенных задач одноклеточной геномики. С его помощью исследователи могут обрабатывать сложные наборы данных одноклеточной последовательности, чтобы выявлять гетерогенность и молекулярные механизмы клеточной функции и взаимодействия.

Исследователи систематически оценивали производительность GPT-4 по десяти наборам данных, охватывающим пять видов и сотни типов тканей и клеток, включая как нормальные, так и раковые образцы.

Запросы к GPT-4 были выполнены с использованием GPTCelltype. Для сравнения, исследователи также оценили GPT-3.5, предыдущую версию GPT-4, и CellMarker2.0, SingleR и ScType, которые являются автоматическими методами аннотирования типов клеток и предоставляют справочные данные, применимые к большому числу тканей.
Аннотации типов клеток, выполненные с помощью GPT-4 или конкурирующих методов, оценивались на основе их соответствия ручным аннотациям, предоставленным первоначальными исследованиями. Степень согласия измерялась с использованием числового балла. Дополнительная таблица ниже представляет пример оценки аннотаций типов клеток GPT-4 в ткани человеческой простаты.

Также ученые исследовали различные факторы, которые могут повлиять на точность аннотации GPT-4.
На рисунке ниже представлены различные базы данных, проекты и типы раков, которые имеют значение в исследованиях, направленных на понимание сложности клеточных популяций в здоровых и патологически измененных тканях:
Azimuth — это инструмент или платформа для аннотирования типов клеток в данных scRNA-seq. Он использует обширные референсные наборы данных для определения клеточных типов на основе их профилей экспрессии генов.
Colon Cancer — это общий термин для рака толстой кишки. В контексте аннотирования типов клеток, исследования могут быть направлены на идентификацию и классификацию различных клеточных типов в тканях, пораженных раком толстой кишки, для лучшего понимания его патогенеза.
HCL (Human Cell Landscape) — это проект, предназначенный для картографирования клеточных типов и состояний в различных тканях и органах человека. Он предоставляет богатую информацию, которая может быть использована для аннотирования и сравнения клеточных типов в scRNA-seq данных.
Lung Cancer — это рак легких. Аналогично раку толстой кишки, в контексте аннотирования типов клеток, данные исследования направлены на различение клеточных типов в раковых и нормальных образцах легких.
BCL (Blood Cancer Lymphoma) — это лимфома или рак крови. В исследованиях типов клеток, это может относиться к анализу клеточной гетерогенности и подтипов рака крови, включая лимфому.
GTEx (Genotype-Tissue Expression) — проект и база данных, которые содержат информацию об экспрессии генов в различных тканях нормального человеческого организма. Эти данные могут служить важной референсной информацией для аннотирования и сравнения клеточных типов.
MCA (Mouse Cell Atlas) — является атласом клеток мыши, аналогичным Human Cell Landscape, но для модельного организма мыши.
TS (Tissue Specificity) — это термин, относящийся к экспрессии генов, которая специфична для определенных тканей. В контексте аннотирования типов клеток, это относится к идентификации клеточных типов, которые характерны для конкретной ткани.

Таким образом, исследователи обнаружили, что GPT-4 показывает наилучшие результаты при использовании 10 ведущих дифференциально экспрессированных генов (при сравнении с 20 и 30) и при использовании двустороннего теста Вилкоксона для получения дифференциальных генов.
Двусторонний тест Вилкоксона — это непараметрический статистический тест, который используется для сравнения двух выборок, чтобы определить, есть ли между ними значимые различия. Он часто применяется когда данные не соответствуют нормальному распределению, что делает его альтернативой t-тесту Стьюдента, предназначенного для данных с нормальным распределением.
В контексте генетических данных, таких как экспрессия генов в различных клеточных типах, тест Вилкоксона может быть использован для определения генов, которые дифференциально экспрессируются между двумя группами, например, между здоровыми и больными образцами или между разными типами клеток.
Точность GPT-4 оказалась схожей при использовании различных стратегий подсказок, включая базовую стратегию подсказки, стратегию подсказки, вдохновленную методом цепочки мыслей, которая включает этапы рассуждения, и стратегию повторяющихся подсказок (также отображено на рисунке выше).
Базовая стратегия подсказки: Здесь информация предоставлялась GPT-4 в простом и прямом формате, без дополнительных пояснений или указаний.
Стратегия подсказки, вдохновленная методом цепочки мыслей: В этом подходе в запрос включались последовательные этапы рассуждений. Это означает, что каждый шаг логического вывода явно формулировался в запросе к модели, давая ей "подсказку" о том, как следует рассуждать для достижения вывода.
Стратегия повторяющихся подсказок: Это подразумевает повторный запрос одной и той же или измененной информации за несколько попыток, возможно, для углубления анализа или уточнения ответов.
В последующих анализах как GPT-4, так и GPT-3.5 использовали базовую стратегию подсказки с десятью ведущими дифференциально экспрессированными генами, полученными с помощью теста Вилкоксона, в качестве входных данных для применимых наборов данных.
Аннотации GPT-4 полностью или частично совпадают с ручными аннотациями более чем для 75% типов клеток в большинстве исследований и тканей, что демонстрирует его компетентность в создании аннотаций типов клеток, сопоставимых с экспертными.


Это совпадение особенно велико для маркерных генов, найденных в литературе, по крайней мере, в 70% случаев полного совпадения в большинстве тканей. Хотя для генов, идентифицированных путем дифференциального анализа, совпадение меньше, но оно все же остается высоким. Однако результаты из наборов данных, опубликованных до сентября 2021 года, следует интерпретировать с осторожностью, так как они предшествуют дате обучения GPT-4.
Основные выводы:
Исследователи сделали вывод, что GPT-4 лучше справляется с иммунными клетками, такими как гранулоциты, по сравнению с другими типами клеток. Он идентифицирует злокачественные клетки в наборах данных рака толстой кишки и легких, но испытывает трудности с В-лимфомой, возможно из-за отсутствия четких наборов генов. Идентификация злокачественных клеток могла бы извлечь выгоду из применения других подходов, таких как вариация числа копий генов.
Также производительность немного снижается в небольших популяциях клеток, состоящих не более чем из десяти клеток, возможно из-за ограниченного количества доступной информации.
Аннотации GPT-4 чаще полностью совпадают с ручными аннотациями для основных типов клеток (например, Т-клеток) по сравнению с подтипами (например, памяти Т-клеток CD4), в то время как более 75% подтипов все еще достигают полного или частичного совпадения.
Т-клетки, также известные как Т-лимфоциты, являются ключевой составляющей адаптивной иммунной системы у млекопитающих, в том числе у человека. Эти клетки развиваются из стволовых клеток в костном мозге и зреют в тимусе (отсюда и название "Т"), который является небольшим органом, расположенным перед грудной клеткой.
В зависимости от их функции и типа антигенного рецептора на их поверхности, Т-клетки подразделяются на несколько основных типов. Т-хелперные клетки (CD4+ Т-клетки), раз уж о них зашла речь, помогают активировать другие иммунные клетки, включая В-клетки для производства антител и Т-киллерные клетки для уничтожения инфицированных клеток.
Низкий уровень согласия между аннотациями GPT-4 и ручными аннотациями в некоторых типах клеток не обязательно означает, что аннотации GPT-4 неверны.
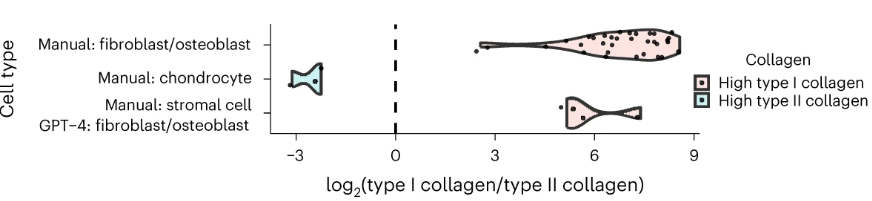
Например, к типам клеток, классифицированным как стромальные клетки, относят фибробласты и остеобласты, экспрессирующие гены коллагена типа I, и хондроциты, экспрессирующие гены коллагена типа II.
Фибробласты – это наиболее распространенный тип клеток в соединительной ткани. Они играют ключевую роль в процессах заживления ран и ремонта тканей, производя важные внеклеточные матриксные компоненты, такие как коллаген, фибронектин и гликозаминогликаны. Фибробласты обеспечивают механическую прочность ткани и участвуют в создании внеклеточного матрикса.
Остеобласты – это клетки, которые отвечают за образование кости. Они производят и секретируют матрикс кости, который затем минерализуется, превращаясь в твердую костную ткань. Остеобласты также играют важную роль в процессе ремоделирования кости, то есть в постоянном обновлении и восстановлении костной ткани.

Хондроциты – это клетки, которые являются основными и единственными клетками хрящевой ткани. Они отвечают за синтез и поддержание внеклеточного матрикса хряща, который включает коллаген (в основном тип II), протеогликаны и другие компоненты. В отличие от остеобластов, которые образуют костную ткань, хондроциты не производят твердого матрикса, который минерализуется, а вместо этого создают гибкий и упругий матрикс, который позволяет хрящу выполнять свои функции.
Для клеток, аннотированных вручную как стромальные клетки, GPT-4 присваивает аннотации клеточного типа с более высокой детализацией (например, фибробласты и остеобласты), что приводит к частичным совпадениям и более низкому уровню согласия. Для типов клеток, которые вручную аннотированы как стромальные клетки, но определены GPT-4 как фибробласты или остеобласты, гены коллагена типа I показывают значительно более высокую экспрессию, чем гены коллагена типа II. Это согласуется с наблюдаемой картиной в клетках, которые вручную аннотированы как хондроциты, фибробласты и остеобласты, что предполагает, что GPT-4 предоставляет более точные аннотации типов клеток для стромальных клеток.
GPT-4 значительно превосходит другие методы, основанные на средних показателях согласия.

Используя GPTCelltype в качестве интерфейса, GPT-4 работает также заметно быстрее, отчасти из-за использования дифференциальных генов из стандартных пайплайнов анализа отдельных клеток, таких как Seurat.

Учитывая неотъемлемую роль этих пайплайнов, исследователи рассматривают дифференциальные гены как непосредственно доступные для GPT-4. В отличие от них, другие методы, такие как SingleR и ScType, требуют дополнительных шагов для повторной обработки матриц экспрессии генов.
Кроме того, по сравнению с другими бесплатными методами, GPT-4 взимает ежемесячную плату в размере 20 долларов за использование веб-портала. Стоимость GPT-4 API линейно коррелирует с количеством запрашиваемых типов клеток и не превышает $0,1 для всех запросов в данном исследовании.

Исследователи также оценили устойчивость GPT-4 в сложных реальных данных с использованием смоделированных наборов данных. GPT-4 может различать чистые и смешанные типы клеток с точностью 93%, а также различать известные и неизвестные типы клеток с точностью 99%. Когда входной набор генов включает меньше генов или содержит шум, производительность GPT-4 снижается, но остается высокой. Эти результаты демонстрируют устойчивость GPT-4 в различных сценариях.

Наконец, исследователи оценили воспроизводимость аннотаций GPT-4 с использованием предыдущих смоделированных исследований. GPT-4 генерировал идентичные аннотации для тех же маркерных генов в 85% случаев, что указывает на высокую воспроизводимость.

Аннотации двух версий GPT-4 показали идентичные показатели согласия в большинстве случаев с коэффициентом Каппа Коэна равном 0.67, что свидетельствует о значительной согласованности.
Коэффициент Каппа Коэна (Cohen’s κ) — это статистическая мера, используемая для оценки степени согласия или надежности между двумя или более оценщиками, которые независимо классифицируют каждый элемент в категориальные шкалы.

Хотя GPT-4 превосходит существующие методы аннотирования типов клеток, есть ограничения, которые следует учитывать. Во-первых, нераскрытый характер корпуса обучения GPT-4 затрудняет проверку основы его аннотаций, что требует человеческой оценки для обеспечения качества и надежности. Во-вторых, участие человека в возможной дополнительной настройке модели может повлиять на воспроизводимость из-за субъективности и может ограничить масштабируемость модели в больших наборах данных. В-третьих, высокий уровень шума в данных scRNA-seq и ненадежные дифференциальные гены могут неблагоприятно сказаться на аннотациях GPT-4.
Исследователи рекомендуют проводить проверку аннотаций типов клеток GPT-4 экспертами-людьми перед проведением последующих анализов.
Несмотря на то, что исследование сосредоточено на стандартной версии GPT-4, дополнительная настройка GPT-4 с использованием высококачественных списков референсных маркерных генов может дополнительно улучшить производительность аннотирования типов клеток, используя такие услуги, как "GPTs", предоставляемые OpenAI.
Выводы
Важно отметить, что применение на данном этапе исключительно сил ИИ и GPT-4 недопустимо, т.к. требует доработки и дополнительных проверок, но этот метод действительно имеет отличные перспективы в будущем!
Авторами основного исследования являются Wenpin Hou (Департамент биостатистики, Школа общественного здравоохранения Колумбийского университета) и Zhicheng Ji (Кафедра биостатистики и биоинформатики, Медицинская школа Университета Дьюка).
Спасибо за прочтение! Будем ждать Вас в комментариях :)
Комментарии (5)

NechkaP
06.04.2024 16:41+1Очень интересный обзор, спасибо! Я не разбираюсь в биологии, но был опыт использования краудсорсингом для аннотирования данных, и взаимодействия с GPT-4. Сразу пришел в голову такой вопрос: совпадают ли те категории клеток, в которых чаще ошибается GPT, и те, где ошибаются/испытывают затруднения сами биологи? (Вижу в статье упоминание типов клеток, с которыми больше всего расхождений, но это ответ на чуть другой вопрос)
Если не совпадают, то это прям отличный простор для ускорения и масштабирования разметки в такой комбинации, естественно, с осторожностью в выводах и применении и должным контролем качества
aansty4U Автор
06.04.2024 16:41Спасибо за Ваш комментарий! Категории клеток, в которых испытывает затруднение GPT, зачастую бывают неприятны и для специалистов)


Vsevo10d
06.04.2024 16:41Вообще не понял.
1) почему речь именно про single cell? Начать можно было с профилирования тканей (либо событий типа пролиферации, воспаления) по обычному реалтайму;
2) нафиг гпт4? Почему не самописная локальная модель без лишних данных? Сложнее в исполнении, но точнее в перспективе и упаковывается в продукт ( наверняка множество РнД отделов биотеха этим и заняты);
3) обучается на литературных данных или специально подготовленных экспериментальных? Я бы доверял только специально созданным датасетам;
4) (мечтательно): профилировать и я могу, вот бы она праймеры подбирать умела...
Meklon
Не добрался до исходного текста ещё, но можно вопрос? GPT-4 содержал коллекции нуклеотидных последовательностей в обучающей выборке?