
В Yandex Cloud с сегодняшнего дня открыт доступ к тестированию YandexART API — нейросети для генерации изображений и анимаций, которая лежит в основе приложения Шедеврум. Протестировать API можно в сервисе Foundation Models, в котором доступно несколько моделей машинного обучения, включая YandexGPT для генерации текстов и эмбеддинги для задач семантического поиска.
Меня зовут Сергей Кастрюлин, я работаю в команде Yandex Research и занимаюсь исследованиями в области компьютерного зрения и генеративных нейросетей. В этой статье расскажу, какие подходы лежат в основе YandexART, как мы повышали эффективность работы этой нейросети и замеряли качество генераций — будет интересно и специалистам, и тем, кто захочет протестировать API в облаке и встроить генерацию картинок в свои сервисы и веб‑приложения.

Коротко об эволюции YandexART
Первые эксперименты с моделями для генерации изображений в Yandex Research начались более двух лет назад, когда в отделе накопилась экспертиза по диффузионным моделям, а в отрасли появились вдохновляющие примеры того, что могут такие нейросети: сначала Imagen и DALL‑E 2, потом Midjourney со Stable Diffusion и другие. За эти два года мы сами прошли несколько стадий.
Первые опыты начинались с латентной моделью от прародителей будущей Stable Diffusion. В качестве первой выборки данных мы взяли датасет, созданный на основе пользовательских запросов в поисковую систему. По сути, у нас был набор в виде пар «текст–картинка» из интернета. Но у него были недостатки: это «шумные» данные низкого качества, изображения и тексты были мало связаны между собой. Обученная на них модель показывала низкие результаты по большинству метрик.
Затем мы перешли на открытые датасеты: тогда как раз появился LAION. Оглядываясь назад, мы понимаем, что это был не очень хороший датасет. Но других ещё не было, а мы с помощью LAION получили первые результаты, которые уже нравились нам по качеству генерации.
Набравшись опыта, мы перешли на собственный пайплайн сборки датасета. С этого момента открытые датасеты составляли лишь малую часть от всего набора данных.
А затем начались серьёзные эксперименты с каскадной диффузией.
Пара лет экспериментов помогли нам сформулировать, что считать действительно качественным датасетом для генерации красивых картинок (и заодно определить для себя критерии этой «красоты»). Но помимо этого мы постоянно решали задачу оптимизации ресурсов. Диффузионные модели часто обучают на больших наборах данных, и этот процесс требует производительных GPU и довольно много времени. Мы же постоянно искали такое соотношение качества и количества данных на этапе предобучения моделей, чтобы можно было масштабироваться за счёт обучения на небольших наборах изображений высокого качества.
Сейчас в Шедевруме работает YandexART v2, которая по факту является уже седьмым поколением модели, если считать по нашей внутренней нумерации. Эта нейросеть также используется во многих сервисах и задачах Яндекса:
В сервисе Яндекс Бизнес нейросеть помогает выбрать готовую картинку из нейрофотостока или сгенерировать новую в один клик.
В Яндекс Браузере она позволяет генерировать изображения в диалоге с Алисой.
Для Яндекс Маркета мы тестировали генерацию фонов на карточки товаров с помощью механизма Outpainting.

В режиме закрытого тестирования одна крупная e‑com сеть сейчас тестирует YandexART API для создания дизайна подарочных карт.
А ещё сгенерированные картинки используются в других наших ML‑задачах, например, для аугментации данных в датасетах.
Расскажу, что находится под капотом нейросети: где случились самые интересные исследовательские прорывы, как и почему данные для обучения приходилось жёстко фильтровать, как мы добивались качества работы нейросети по нужным нам критериям.
Как мы искали подход к архитектуре
С точки зрения архитектуры у нас было два подхода на выбор, и мы попробовали оба:
Латентная модель. В этой схеме работает предобученный вариационный автокодировщик (VAE), у которого есть внутреннее представление с пространственным разрешением, например, 64 × 64, и несколькими, обычно четырьмя или шестнадцатью каналами. Можно генерировать латентный код в этом пространстве, а затем декодировать и получать картинку в высоком разрешении. Такая парадигма используется, например, в Stable Diffusion XL и DALL‑E 3.
Каскадная диффузия. Здесь у нас последовательно работают несколько моделей. Первая пиксельная модель Text‑to‑Image генерирует изображение в низком разрешении, а за её апсемплинг до нужного размера отвечают последующие модели в каскаде. Так работает Imagen от Google и DALL‑E 2.
Первый подход довольно распространён, но качество изображения ограничено исходной производительностью VAE, а она часто бывает невысокой. Для увеличения качества автокодировщик можно дообучить позже, но и это не всегда эффективно из‑за двух факторов. Во‑первых, используя только одну модель апскейлинга, мы вынуждены обучать модель для высоких апскейлинг‑факторов. Типичным сегодня является х8 апскейлинг. Это означает, что из каждого латентного кода модель должна восстановить 64 пикселя, а это очень сложная задача. Во‑вторых, выполнять такую задачу должна модель со сравнительно небольшим числом параметров, иначе работа с большими картами активаций, возникающими на слоях, близких к целевому разрешению, будет вызывать проблемы с видеопамятью.
Помимо этого, при использовании латентного подхода очень распространена проблема Oversaturation — картинки могут получиться слишком яркие, словно пересвеченные, и будут выглядеть искусственно. Также бывают проблемы с балансом цветов, и с этим тоже приходится бороться.
Многоканальные автокодировщики умеют хорошо восстанавливать картинку, но обучать на них диффузию сложнее.
В каскадном подходе функцию декодера выполняют модели Super Resolution, которые работают независимо от основной пиксельной генеративной модели. Благодаря этой автономии, блоки с высоким разрешением легко заменяют друг друга, можно учить каждую модель независимо, за счёт чего задача апскейла высокого порядка разбивается на несколько промежуточных. Это даёт гибкость в распределении вычислительных ресурсов и упрощает процесс экспериментирования. Помимо этого, каждый этап каскада решает свою задачу, и можно выбрать для каждого более подходящие модели и данные.
Таким образом мы остановились на каскадном подходе, и опытным путём пришли к каскаду из трёх элементов:

Сначала на основе промта генерируем картинку 64 × 64 пикселя. Для этого применяем модель GEN64, которая следует архитектуре U‑Net и обуславливается на текстовый ввод через механизм Cross‑Attention.
Затем мы увеличиваем картинку до разрешения 256 × 256 с помощью модели SR256. В основе тоже U‑Net‑подобная архитектура, и эта модель также обусловлена на текст: в качестве условия генерации выступает первая картинка 64 × 64 и промт. Благодаря этому при увеличении мы учитываем текст от пользователя — можно на его основе дорисовать какие‑то детали, что‑то улучшить, исправить ошибки первой генерации.
На третьем этапе увеличиваем ещё раз до размера 1024 × 1024. Здесь мы используем архитектуру Efficient U‑Net, которая уже не учитывает текст и имеет меньше параметров в верхних слоях. Нам уже не нужно генерировать крупные элементы, а вот размер батча и вычислительную сложность за счёт этого можно уменьшить.
Как и в Imagen, для обуславливания на текст мы используем предобученные текстовые энкодеры. Для этого у нас есть собственная модель на 1,3 млрд параметров на основе архитектуры BERT‑xlarge, которую мы внутри называем просто i2t (image‑to‑text). По сути, это наш аналог CLIP (Contrastive Language‑Image Pre‑Training) — модели глубокого обучения, которая предназначена для понимания связи изображений и текста. Изначально эта модель была разработана для целей поиска и развивалась много лет.
Подготовка данных — самый главный фактор, который влияет на обучение и определяет качество работы нейросети. Так что последовательно расскажу о подходах к датасетам, к самому обучению и к оценке качества данных: по эстетичности, соответствию картинки и текста, отсутствию артефактов. Начнём с большого датасета, который был комбинацией общедоступных и собственных наборов данных и использовался для предварительного обучения.
Стратегия отбора данных и оценка их качества
В самом начале у нас был практически дамп всего интернета, как мы его видим: первая выборка состояла из почти триллиона пар «картинка–текст». Первые эксперименты показали, что учить модели даже на миллиарде плохих семплов не эффективно, и нам нужно отобрать самые лучшие пары, а для этого нужно вообще понять, что значит «лучшие».
Экспериментально мы пришли к тому, что нужно отдельно позаботиться о качестве изображений, отдельно о качестве текстов, и проследить, чтобы картинка и текст были максимально связаны между собой. По этим пунктам выделили несколько этапов фильтрации исходного пула данных.
Для фильтрации у каждой пары должен быть предварительно рассчитанный набор предикторов — классификаторов, которые обучены на разных признаках изображений и текстов и связаны с какой‑то характеристикой качества выборки.
Фильтрация изображений.
Сначала мы удалили из датасета изображения сексуального, непристойного и прочего сомнительного характера с помощью собственных классификаторов. Максимально полное удаление нежелательного контента мы считаем наиболее надёжным способом обезопасить последующие генерации. Неизвестность для модели нежелательного контента практически исключает возможность его генерации.
Затем для грубой фильтрации использовался набор данных SAC — Simulacra aesthetic captions. Ансамбль предикторов на основе изображений с весами, дообученными на SAC, предсказывал общую привлекательность картинки для человека. В ходе экспериментов мы проверили соответствие этих предсказаний с оценками независимых наблюдателей, и в целом прогноз совпадал.
По этому критерию мы оставили только лучшую треть изображений, потому что большинство кадров ниже этого порога выглядели непривлекательно или неоднозначно для оценивающих.Также в итоговый набор попали только картинки с размером в диапазоне [512, 10 240] пикселей и соотношением сторон в диапазоне [0,5, 2]. Такие изображения были наиболее полезны для обучения, это подтвердили промежуточные эксперименты, а ещё это упрощало пайплайн подготовки данных.
Дальше работали классификаторы, которые касались, скорее, технического качества картинки. Здесь было несколько параметров: уровень шума, размытость, наличие водяных знаков, клетчатый фон, степень сжатия.
С самых первых экспериментов мы поняли важность эстетической привлекательности изображений, поэтому далее использовались классификаторы эстетичности, обученные на публичных датасетах AVA, TAD66k. Пороговые значения для фильтраций подбирали вручную, соблюдая баланс между качеством и размером датасета.
На этом примере можно увидеть, почему нам нужно было сразу несколько классификаторов, которые обучены на разных датасетах:

Также мы хотели, чтобы наша модель была способна генерировать сложные сцены с большим количеством деталей. Это можно контролировать, выбирая данные на основе классификатора Image Complexity, который мы обучали на датасете IC9600.
Явным образом мы следили и за монотонностью фона. Для этого набор данных разделили на две части: с монотонным и более «интересным» фоном. Поэкспериментировав, мы пришли к тому, что только 10% обучающей выборки у нас содержали монотонный фон. Мы хотели, чтобы модель умела в первую очередь генерировать интересные и разнообразные фоны, но при этом сохраняла возможность создавать изображения с монотонным фоном при необходимости.

Но это только визуальная часть выборки, фильтруем дальше.
Фильтрация текста. Здесь ситуация была даже немного хуже: исходный датасет основан на текстовой информации, находящейся рядом с картинками в интернете. В итоге туда могли попадать не совсем релевантные тексты, а ещё там могла встречаться нерелевантная техническая информация и хештеги. А нам нужно сделать текст похожим на релевантный картинке запрос.
В первую очередь мы сфокусировались только на текстах на английском: язык текста распознавали с помощью нашего внутреннего классификатора языков. Затем вручную разметили случайную выборку из 4,8 тыс. текстов: для каждого исходного текста указывали либо очищенную версию, либо пустую метку, которая показывала, что текст совсем не подходит для обучения. В конце сформировали датасет для обучения из очищенных текстов, отфильтровав строки с пустыми метками. Затем дообучили на этом датасете небольшую языковую модель с 180 миллионами параметров и использовали её предсказания как фактор качества текста. Все пары, содержащие не английский или плохой (согласно классификатору) текст, удалялись из датасета.
Комбинация подходов. К этому моменту у нас был набор относительно невысокого качества из 2,3 млрд пар «картинка–текст», которые нужно было отфильтровать ещё сильнее. Для этого мы вручную разметили 66 тыс. пар с точки зрения визуальной привлекательности изображений, релевантности текстов, а также их соответствия картинкам. Мы использовали систему оценки по шкале от 1 до 3: хорошо, нормально и плохо. В отличие от часто используемой шкалы Ликерта, такая упрощённая шкала позволила подобрать нужный нам баланс между информативностью и разнообразием оценок от реальных людей.
После этого мы обучили модель CatBoost на наборе из 56 факторов, среди которых было 6 вариаций CLIP Score, 38 факторов, связанных исключительно с текстом, и 12 факторов, связанных исключительно с изображениями. Получилась модель, которая оценивает, насколько семпл в целом подходит для обучения модели. Мы назвали её Sample Fidelity Classifier (SFC).
Все пары с предыдущего этапа фильтрации мы отсортировали согласно прогнозам модели SFC и отобрали лучшие пары. В конце установили пороговые значения, чтобы в итоговый набор данных входило 300 млн изображений с немонотонным фоном и 30 млн с монотонным.
К этой схеме подготовки данных мы пришли опытным путём в результате множества экспериментов. После этого приступили к предобучению моделей в каскаде.
Обучение моделей
В архитектуре у нас есть три модели, и у каждой своя задача в каскаде.
GEN64. Главная модель для генерации с 2,3 млрд параметров (модель 2.3B).
SR256. Первая модель для апсемплинга, имеет уже 700 млн параметров.
SR1024. Вторая модель для апсемплинга тоже с 700 млн параметров.
Для обучения GEN64 и SR256 использовался один датасет, для SR1024 — другой. Также SR1024 обучался с немного другим набором классификаторов, поскольку нам было важно уделить больше внимания техническому качеству изображений: отсутствию шумов, размытий и артефактов компрессии.
Дальнейшее дообучение моделей было призвано усилить их определённые характеристики, например, следование промту или эстетичность генераций. Здесь нам тоже понадобилось два разных набора данных: один для моделей GEN64 и SR256 и один для модели SR1024.
Как готовили наборы для дообучения.
Улучшить набор данных снова помогли ML‑модели и асессоры.
Сначала мы отфильтровали первоначальный датасет с помощью набора классификаторов и сократили его объём до нескольких сотен тысяч пар. Мы старались выбирать изображения из разных категорий: природа, товары, интерьеры, автомобили, еда и т. д.
Затем асессоров попросили отбросить дефектные изображения: картинки, где размер объекта, положение конечностей, выражение лица человека или морды животного казались неестественными.
После этого участников также попросили переформулировать описания: убрать из них лишние слова, подробно описать объекты, их характеристики, действия и взаимодействия между ними, фон и окружение, а также стиль изображения.
Полученные в результате 50 тыс. пар обладали крайне высоким качеством, особенно с точки зрения соответствия изображения и текста. Они использовались для дообучения модели с учителем (Supervised Fine-Tuning), что позволило существенно улучшить следование промту, но и этого нам показалось недостаточно.
Многочисленные исследования показывают, что дообучение диффузионных моделей на чистом отобранном наборе данных значительно повышает качество генерируемых изображений, но для дальнейшего улучшения изображений нужны другие методы. На финальном этапе мы использовали обучение с подкреплением (Reinforcement Learning, RL) для дальнейшего улучшения эстетичности и уменьшения дефектности генераций.
Как поощрять нейросеть генерировать ещё более красивые картинки. В постановке задачи обучения с подкреплением мы следовали статье DDPO и использовали PPO‑loss с ε = 0,5. Последний факт важен с практической точки зрения и является нашей небольшой находкой. Дело в том, что обычно ε принимают равным 0,1, чтобы значения reward‑моделей не были слишком шумными. Но оказалось, что в задачах с изображениями его можно делать больше, за счёт чего существенно ускоряется процесс дообучения.
Мы использовали три модели вознаграждения:
Соответствие картинки и текста (Relevance) в терминах OpenCLIP ViT‑G/14.
«Отсутствие дефектов» (Consistency).
«Красота» (Aesthetics).
Второй и третий пункт — это наши собственные reward‑модели на основе пользовательских предпочтений. Так что здесь тоже использовали ручную разметку данных.
Потери рассчитывали независимо для каждого reward'а, а затем вычисляли среднее с весами. Нашей целью было повысить красоту и уменьшить дефектность генераций без существенного ухудшения следованию промту. Экспериментально мы выяснили, что взвешивание, приводящее значения reward‑моделей к одному масштабу удовлетворяет этому требованию.
 и красоты (Aesthetics), в то время как релевантность остаётся почти неизменной. Вместе с этим, модель становится более предпочтительной с точки зрения пользователей (справа).")
Но что ещё интереснее, мы смогли проследить зависимость оценок асессоров от метрик изменения вознаграждения на этапе обучения с подкреплением. Другими словами, оценки асессоров подтвердили, что использование Reinforcement Learning на финальной стадии обучения улучшило общее качество генераций.
Как замерить качество генерации изображений
После всех этапов дообучения важно убедиться, что мы действительно добились нужного результата и можем генерировать красивые картинки. Для этого нам необходимы понятные и надёжные критерии качества. Мы замеряли качество общепринятыми автоматическими метриками (FID/CLIP score) и с помощью собственного инструмента ручной разметки.
Автоматические оценки. Метрики FID и CLIP score часто используются для замеров как промежуточного (в ходе обучения модели) так и финального качества генераций. Ранее многие работы, наподобие этой или этой, показали, что эти метрики не всегда коррелируют с мнениями людей. На практике мы подтвердили это наблюдение. Например, оказалось, что с какого‑то уровня качества FID практически не способна отличать просто нормальные модели от очень хороших. На графике снизу мы видим, что модель, которая выигрывает базовую всего в 20% случаев, имеет всего на несколько десятых меньший FID, чем модели с примерно пятьюдесятью процентами побед.

Поэтому основным критерием качества мы считали оценки реальных людей. Важно было организовать строгую процедуру, которая позволила бы получать интуитивно понятные, интерпретируемые и статистически значимые результаты.
Human Evaluation. Для финальных замеров мы также привлекали обычных людей на краудсорсинговой платформе. Все участники проходили предварительное обучение, а к присвоению меток допускали только тех кандидатов, которые набрали не менее 80% в тесте с двадцатью заранее подготовленными заданиями.
Всем асессорам нужно было попарно сравнивать картинки, которые были сгенерированы с помощью запросов из двух наборов:
DrawBench, который состоит из 200 запросов и уже де‑факто стал стандартом оценки моделей генерации изображений из текста.
-
Наша корзинка промтов YaBasket-300, которая содержит запросы, разбитые по категориям «Здравый смысл» (Common Sense) и «Продукты» (Products), а ещё собственный набор запросов, который дополняет общедоступные бенчмарки практически важными сценариями.
. Продуктовая часть затем делится на восемь почти одинаковых по размеру подкатегорий (b)")
Содержимое набора запросов YaBasket: соотношение верхнеуровневых категорий запросов (a). Продуктовая часть затем делится на восемь почти одинаковых по размеру подкатегорий (b)
Каждому участнику мы показывали рядом два изображения, сгенерированные разными нейросетями по одному запросу. Участники не знали, какие модели они сравнивают. После этого их просили выбрать одно из изображений на основе трёх критериев оценки в порядке важности:
Наличие дефектов: например, искажения объектов, конечностей, лиц и морд.
Соответствие изображения тексту.
Эстетический аспект, включая выбор и баланс цветов, красоту фона и так далее.
Если по всем трём критериям изображения оказывались одинаковыми, участник отмечал изображения как одинаковые по качеству. Каждая пара изображений оценивалась тремя участниками, после чего балл получало то изображение, которое набрало больше голосов.

По оценкам асессоров, результаты работы нейросети YandexART превзошли Stable Diffusion XL (SDXL) в 77% случаев, Kandinsky v3 — в 72% случаев. В сравнении с MidJourney v5 модель оказалась практически равной по качеству.
Результаты для YaBasket-300, октябрь-ноябрь '23:

Результаты для DrawBench, октябрь-ноябрь '23:

В ходе работы над моделью YandexART v2 мы проводили множество исследований стадии GEN64 и основного датасета для её обучения. Например, мы проверяли можно ли добиться такого же качества, используя меньшую по числу параметров модель, но более долгую процедуру обучения, сравнивали эффективность обучения моделей разного размера, исследовали, как влияет размер датасета на финальное качество. Ответы на все эти вопросы имеют мало смысла, если качество предобученной модели слабо связано с качеством файнтюна, поэтому эту взаимосвязь мы также рассмотрели отдельно. Про эти и другие эксперименты можно прочитать в нашей работе, опубликованной на arxiv.
На этом развитие генеративных технологий Яндекса не заканчивается. Сейчас команда YandexART активно разрабатывает новое поколение моделей, которые ещё лучше решают задачи пользователей. Например, недавно мы решили вновь присмотреться к латентной диффузии. Кроме описанных выше минусов, у неё есть и существенные плюсы: такие модели могут работать быстрее за счёт отсутствия необходимости использовать вычислительно сложные диффузионные апскейлеры, а ещё их проще использовать для смежных задач вроде генерации видео и смешивания изображений.
Также мы продолжаем исследовать возможности по улучшению данных, использованию синтетических текстов, отбору исключительно красивых изображений. Мы экспериментируем с использованием нескольких текстовых энкодеров, архитектурой и размером моделей. Один из результатов наших экспериментов — бета‑версия модели YandexART v3 — уже доступен широкой публике в приложении Шедеврум. А скоро модель появится и в сервисе Foundation Models.
Комментарии (21)

CBET_TbMbI
09.04.2024 08:48+1А для обычных пользователей шедевриум по-прежнему доступен только в приложениях на телефон?

snk4tr Автор
09.04.2024 08:48Есть еще веб, то там пока только просмотр без генераций https://shedevrum.ai/en/top/week/

retry
09.04.2024 08:48Будет ли возможность для upscale/улучшения своих изображений(img2img)?

kolabaister
09.04.2024 08:48Поддерживаю. Очень нужно надежное отечественное вменяемое решение. Нейросетей под эту задачу много, но все какая то ерунда или услуги стоят как крыло самолета или вовсе не продаются у нас.

dolotov
09.04.2024 08:48Технология YandexART обладает большим набором полезных свойств. Мы будем выбирать наиболее востребованные и шипить их в API в следующих апдейтах. Вашу заявку посчитали :)

hphphp
09.04.2024 08:48

LAutour
09.04.2024 08:48А возможно встроить ИИ в браузеры, чтобы он определял устаревшие куки и кэш? А то годы идут, технологии появляются, а на каждый глюк с отображением страниц техподдержки сайтов всегда посылают вручную чистить кэш и куки.

theurus
09.04.2024 08:48Если дернуть курлом как показано в примере то получается ответ 200 и что то типа [{'id': 'fbvek5fhna747e25ekoj', 'description': '', 'createdAt': None, 'createdBy': '', 'modifiedAt': None, 'done': False, 'metadata': None}]
И куда дальше?
Код запросаcurl -X POST -H "Authorization: Bearer $IAM_TOKEN" -d '{"model_uri":"art://b1gcvk4tetlvtrjkktek/yandex-art/latest","messages":[{"text":"ватрушка на узи \n","weight":1}],"generation_options":{"mime_type":"image/jpeg","seed":3124866248914952}}' https://llm.api.cloud.yandex.net:443/foundationModels/v1/imageGenerationAsyncА с сервера в нидерландах вообще не подключается к этому адресу.
dolotov
09.04.2024 08:48+1Как мы подробно описали в документации (https://yandex.cloud/ru/docs/foundation-models/operations/yandexart/request), обращение к API YandexART доступно только асинхронно – поскольку генерация изображений занимает иногда много времени.
В рамках асинхронного API, чтобы получить результат генерации, необходимо не только отправить запрос на генерацию, но затем отправить запрос на получение результата. Вот что про это написано в документации:
Генерация изображения занимает некоторое время. Подождите 10 секунд и отправьте запрос, чтобы получить результат генерации. Если изображение готово, результат вернется в кодировке Base64 и будет записан в файл
image.jpeg.curl -X GET -H "Authorization: Bearer <значение_IAM-токена>" https://llm.api.cloud.yandex.net:443/operations/<идентификатор_запроса> | jq -r '.response | .image' | base64 -d > image.jpeg
Где:
<значение_IAM-токена>— IAM-токен, полученный перед началом работы.<идентификатор_запроса>— значение поляid, полученное в ответе на запрос генерации.

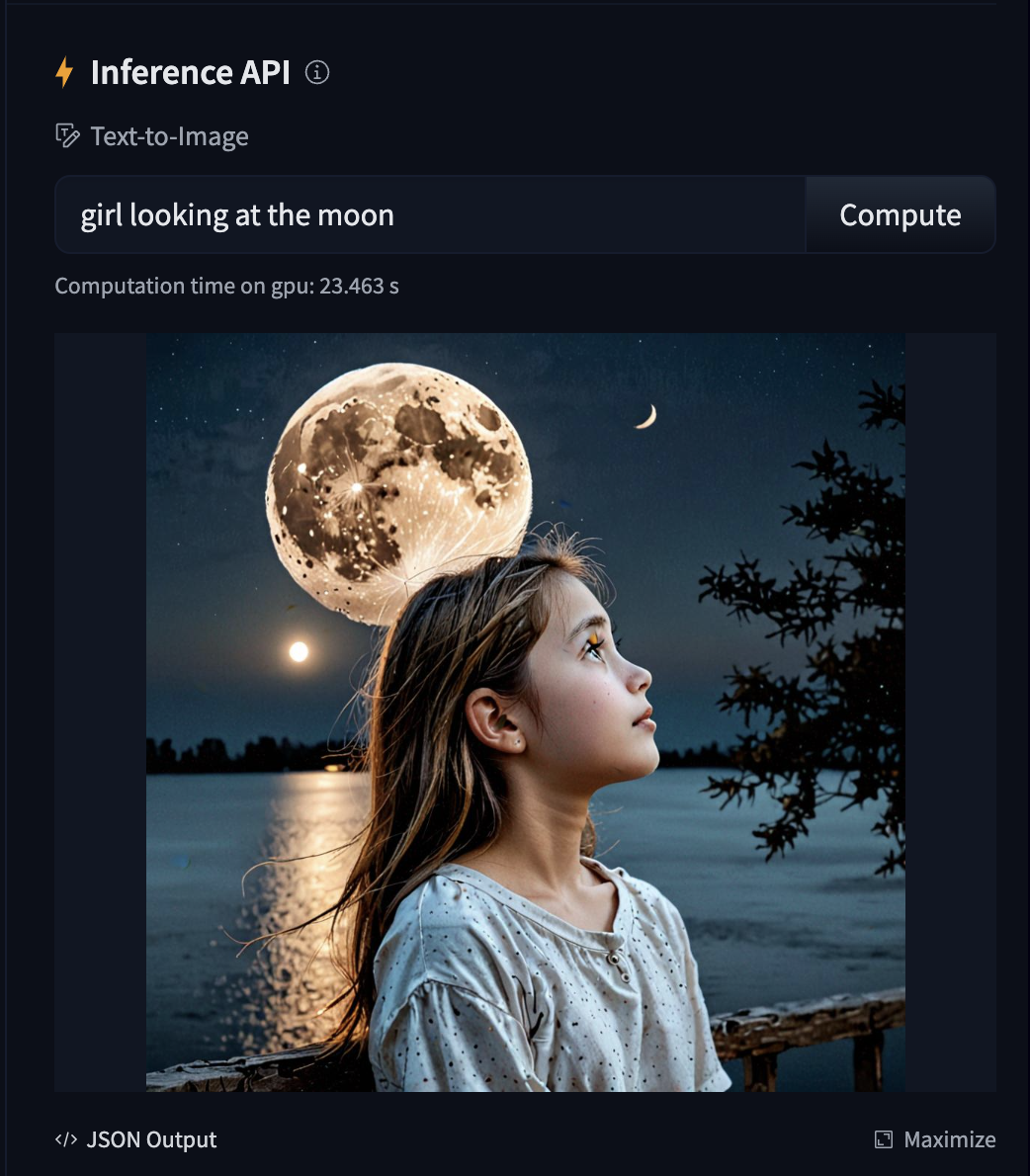
recompileme
09.04.2024 08:48А почему такие мыльные картинки?
например, girl looking at the moon

она же в sdxl
man throws a tiger, still from bollywood film


CBET_TbMbI
09.04.2024 08:48Кстати, да. Когда баловался в Шедевруме тоже обратил внимание. Будто пикселей недокладывают. Или в фокус не попадает... Хотя топы недели и прочие топы весьма качественные. Но именно мне приходят смазанные картинки. Или просто нужно сделать сотню попыток, чтобы найти хотя бы одну приличную.

slivka_83
09.04.2024 08:48+1В примере (в начале статьи) показано как с этим бороться: высока детализация, высокое разрешение




theurus
09.04.2024 08:48Рисует так же не очень как бесплатные модельки с хаггин фейса Ж( https://t.me/kun4sun_pics_ch
Это провал.

Devastor87
09.04.2024 08:48Есть ли в планах создание чего-то типа Sora?
Насколько перечисленные в статье технологии применимы в создании ИИ для генерации видео?
Bardakan
Тарифы?
dolotov
Пока совершенно бесплатно
Gorky
ну ориентиры какие-то есть предварительно?
dolotov
Тут обещаний никаких дать не можем. Я думаю, что не меньше месяца бесплатное потребление будет сохраняться. Возможно, несколько месяцев