

Локатор — обязательный элемент любого автотеста, который позволяет системе находить правильный путь к тестируемому компоненту интерфейса. От точности локатора и корректности его оформления зависит не только, смогут ли разобраться с локатором тестировщики и другие коллеги, но и сможет ли в целом автотест безошибочно найти искомый компонент среди множества на странице для выполнения целевой проверки.
Меня зовут Елена Пранова. Я инженер по автоматизации тестирования в ОК. В этой статье я хочу рассказать о том, как мы работаем с локаторами для автотестов: каких принципов придерживаемся, чего стараемся избегать и какие правила выработали на своем опыте.
Кратко об автотестах в ОК
Месячная аудитория ОК достигает 36 млн пользователей, и примерно половина из них заходит в соцсеть из браузеров — как мобильных, так и десктопных. Поэтому нам крайне важно, чтобы соцсеть работала корректно, прогнозируемо и без сбоев. Чтобы обеспечить это, мы активно запусаем автотесты: уже сейчас у нас более 3000 тестов для десктопной версии ОК и свыше 1100 — для мобильного веба. При этом уровень падений автотестов у нас не превышает 6% и 3% соответственно, что является хорошим показателем для UI-автотестов с учётом масштабов и специфики нашего продукта.
Чтобы добиться и поддерживать такие показатели мы используем много подходов и практик. В том числе обеспечиваем точность локаторов.
Немного теории
Каждая страница браузера — это HTML-документ, представленный в виде дерева элементов. Причем каждое такое дерево отображает не только содержание страницы, но и связи между элементами: зависимости, степень вложенности, связи на уровне «родитель/предок» и другие.
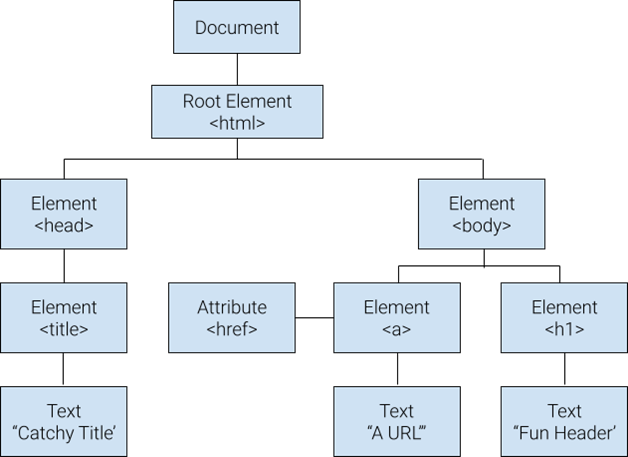
Сами же элементы на странице представляют собой набор тегов и содержания. Причем теги зачастую идут парами (например, <div> и </div>), могут содержать атрибуты и значения атрибутов.

Такая архитектура страницы браузера и элементов на ней дает возможность свободно ориентироваться по дереву и понимать на уровне кода, какой именно элемент рассматривается.
При чём здесь локаторы?
Пользователи взаимодействуют со страницами визуально: скролят, кликают, печатают. Но автотест работает иначе — он взаимодействует со страницами программно. Поэтому, чтобы тест мог безошибочно найти на странице нужный элемент и выполнить с ним какие-либо действия, ему нужна некая «подсказка» в виде указания пути до него.. Таким идентификатором-указателем и является локатор.
Обязательно ли писать локаторы?
Локатор — не обязательно «самописный» указатель. В отдельных случаях можно пойти по «простому пути» — например, найти элемент на странице и скопировать его Xpath или Full Xpath (прим. Xpath — язык запросов) через Devtools браузера.
Проблема в том, что подобные локаторы, генерируемые автоматически, сложно читаются и зачастую не дают понимания, за что этот элемент отвечает и куда в конечном итоге нас направляет. Например:
Copy -> Xpath
//*[@id='anonymPageContent']/div/div[1]/div[2]/div/div[2]/div[2]/div[1]/form/div[4]/input
Copy -> full Xpath
/html/body/div[10]/div[5]/div[3]/div[1]/div/div/div/div[1]/div[3]/div/div/div/div/div/div/div[1]/div[2]/div/div[2]/div[2]/div[1]/form/div[4]/input
Таким образом и структура автотеста на уровне кода будет сложной, запутанной и неочевидной.

Работа с такими локаторами чревата потенциальными рисками и ограничениями. Так, в случае падения теста может понадобиться вручную искать тестируемый элемент, фиксить проблему, потенциально разбираться с падениями на регрессе. В результате непонимание логики локатора может стать причиной снижения доверия к тестам и эффективности отлавливания багов. С увеличением количества автотестов такая проблема будет только масштабироваться. В условиях, когда автотестов больше 4000, как в ОК, такая ситуация просто недопустима. Поэтому мы в ОК не используем автогенерируемые локаторы, а пишем их сами, используя Xpath.
Благодаря этому, мы можем перейти от сложной структуры автотестов к «прозрачной» и понятной.


Такой формат описания автотестов помогает быстро ориентироваться в логике теста, позволяет оперативно определить проблему в случае падения теста, упрощает адаптацию новых QA и в целом делает тесты надежнее.
Примечание: Большинство наших локаторов написано на Xpath. Но это не значит, что мы запрещаем работать с CSS — все, кому удобнее использовать CSS-локаторы, могут это делать без каких-либо блокеров. Распространенность Xpath во многом обусловлена только превосходящими возможностями поиска, гибкостью и универсальностью в рамках наших задач. Но ещё вы можете добавлять свои тестовые ID, с которыми можно будет работать в рамках автотеста.
Подходы к написанию локаторов
Есть два подхода к написанию локаторов:
абсолютный путь;
относительный путь.
Абсолютный путь подразумевает, что на пути от корневого до целевого элемента — например, от первого <div> до тега <input>, — надо посетить каждый дочерний элемент родителя.

Подход рабочий, но для нас он не подходит — у нас большие страницы со множеством элементов, поэтому описание абсолютного пути будет неизбежно переусложнено. Поэтому мы пользуемся другим подходом — относительным путем.
Относительный путь подразумевает, что путь до элемента можно сократить — все теги выше целевого можно опустить и заменить их на // (две косые). Например, если целевым является тег <span>, путь будет кратно меньше.

Примечание: Локаторы можно писать через точку в самом начале пути перед
//. Это необязательно, но сильно упрощает работу со сложными запросами, вложенными элементами и т.д. Также допускается использование звездочек — впоследствии это может упростить фильтрацию по атрибутам. При этом все в команде должны понимать, на что именно указывает звездочка.
Локаторы для повторяющихся/схожих элементов
При работе с большими страницами, наполнение которых динамическое и может часто меняться, возможны ситуации, при которых локатор будет находить не один, а несколько элементов. Поэтому мы стараемся избегать чисел в описании локатора. Например: .//form/input[2].
Почему?
В большинстве случаев число не несет смысловой нагрузки и не дает четкого понимания отличия версии от предыдущих или последующих — она актуальна и понятна лишь в момент написания теста.
Вместо этого лучше использовать предикты и враперы, которые делают описание на уровне кода автотестов более подробным, понятным и содержательным.

Подробнее о функциях локаторов
У Xpath много функций, позволяющих «маркировать» локаторы для последующей фильтрации. Среди них: local-name(), position(), node(), not(), normalize-space(), text(), contains(), boolean() и другие. Перечень значительный и предоставляет функции практически под любые запросы и кейсы.
Мы в ОК используем в основном две функции — contains() и text(). Их хватает для решения большинства наших задач.
contains(string, string)— функция, которая возвращаетtrue, если первая строка содержит вторую, иначе возвращаетfalse. Пример: поиск локатора по команде.//*[contains(@class, 'anonym_login_field')]

text()— функция, которая возвращает набор текстовых узлов (содержание какого-либо тега). Например: поиск тега по запросу.//div[text()='Не получается войти?']

Но при работе с text() надо понимать, что наличие текста на странице еще не значит, что он найдется с помощью функции — текст может относиться и к значению атрибута. Для проверки лучше предварительно посмотреть содержание элемента через Devtools.
В Xpath также есть функции для работы с числовыми значениями. К таким относятся:
number position()— функция, которая возвращает позицию элемента во множестве;number last()— функция, которая возвращает номер последнего элемента во множестве;number count(node-set)— функция, которая возвращает количество элементов в node-set.
Но проблема этих функций в том, что они не дают понимания, с каким элементом происходит взаимодействие. Поэтому такие функции мы не рассматриваем для своих задач.
Также есть вариативные функции — например, starts-with(string, string), которая возвращает true, если первая строка начинается со второй, иначе возвращает false. Но мы ими не пользуемся — обычно для наших задач достаточно contains() и text().
Вместе с тем, мы работаем с логическими функциями and и or.
and— логическое «и». Пример:.//*[@type= 'text' and @name='st.email']

Эта логическая функция спасает, когда нужно дополнить запрос и конкретизировать суть искомого элемента. При этом с функцией and надо работать осторожно — чем больше «нагромождений» в локаторе, тем больше риск, что тест со временем сломается из-за изменений в интерфейсе.
-
or— логическое «или». Пример:.//*[text()='Войти' or text()='Войти в Одноклассники'].//*[@class='new_login' or @name='st.email']
Логическое «или» — незаменимая функция для ситуаций, когда нужно учесть несколько возможных вариантов. Например, в ОК регулярно проводятся доработки интерфейса и часто запускаются эксперименты. Поэтому тестировщикам иногда нужно учитывать, что один и тот же элемент в разных версиях релиза может отличаться — например, вместо названия кнопки «Войти» будет «Войти в Одноклассники». Таким образом, функция
orпозволяет тесту стабильно выполняться, независимо от того, на какую версию интерфейса попадет автотест.
Но при работе с функцией or надо понимать, что ее применение должно быть временным — после окончательной выкатки обновления в прод надо удалить функцию из локатора, чтобы не загромождать его, ведь при следующем обновлении, возможно, также придется использовать логическое «или».
Доверие к элементам
Как правило, автотесты используются для регулярных и неизменяемых проверок элементов интерфейса. Поэтому локатор обычно тоже пишется раз и условно «навсегда» (как минимум надолго). Чтобы обеспечить подобное «долголетие», для локатора важно выбирать элементы, которые «вызывают доверие». К таким можно отнести все элементы на странице, описание и атрибуты которых позволяют четко идентифицировать назначение элемента, его версию и другую информацию. Например, id, button, popup, dialog, photolayer, music, feed-list и другие.
Если значения атрибутов указывают на «временность» элемента, нельзя гарантировать, что элемент не изменится в ближайшее время и не спровоцирует падение автотестов. Поэтому значениям вроде hidden, active, cred, __new, __2022, __red, лучше не доверять.
Правила и рекомендации по работе с Xpath
Корректность проведения автотестов зависит от множества факторов и один из главных среди них — правильно составленный локатор.
Длительная и непрерывная работа с автотестами позволила нам выработать небольшой свод правил работы с Xpath, которому следуем сами и можем рекомендовать другим.
Нет сложным Xpath. Нужно стараться минимизировать локаторы, в которых много тегов и непонятен конечный элемент — их сложно читать, поддерживать в актуальном состоянии, оберегать от «поломок» в случае изменений в верстке страницы. Лучше стремиться к лаконичным Xpath вроде
.//div/a[@class='class'].Нет длинным Xpath. Даже правильные, но длинные XPath (например,
.//*[@id='aq-block']/div[@class='one-th columns’]/*[@class=‘feature']) сложно читать и понимать. Более того, в случае любых изменений, могут потребоваться правки на уровне содержания запроса. Поэтому лучше стараться использовать сокращенные XPath типа.//div[@class='one-th columns']/a— они более читабельные и работать с ними проще.Нет цифрам в Xpath. Я уже упоминала, как цифры влияют на понимание сути целевого элемента и доверие к нему. То есть:
.//*[@id='email']/div[1]/div/div[2]/h3/a— плохо,.//*[@id='email']/div[@class='class']/a— хорошо.
Работа с Xpath — важная часть автотестов, которая при грамотном подходе позволяет эффективно взаимодействовать с элементами. Мы прошлись по ключевым моментам, но наш опыт показывает, что при понимании основ, возможных «подводных камней» и соблюдении простых правил, Xpath может стать залогом стабильности автотестов и повысить доверие к ним как со стороны разработчиков и тестировщиков, так и со стороны бизнеса. В комментариях можно поделиться своими правилами работы с локаторами:)
Комментарии (5)

UnusualLetter
10.04.2024 10:44В заголовке сказано про стабильность, в тексте ни слова о стабильности.

B_Z
10.04.2024 10:44Да правила в общем те же, только всё равно есть моменты, когда без цифр не обойтись.
Например, вам нужен текст из ячейки какой-нибудь таблицы, все ячейки однотипные, текст в них может быть разным. Там последовательность вообще в принципе единственная характеристика, по которой можно ориентироваться.

wildeee
10.04.2024 10:44Залог стабильных автотестов (да и то, малая часть этого залога, если честно) - это стабильные локаторы, а не xpath/css/whatever.
Несколько странно не увидеть от продуктовой компании рекомендации №0 (которая, впрочем, и единственная) - развешивайте кастомные атрибуты над элементами, с которыми взаимодействует тест, причем название атрибутов не имеет значения. Хотя если придерживаться распространенного названия `data-testid`, современные инструменты (например, playwright) смогут вам сгенерировать локаторы автоматически.
mayorovp
Что-то вы про абсолютные и относительные написали нечто странное. Абсолютные XPath начинаются с /, относительные - все остальные.
Когда вы ищете элемент в документе начиная с корня - разницы между относительным и абсолютным xpath нет, но вот при более точном поиске - есть. Или, к примеру. в предикатах обычно используют именно относительные xpath, по понятным причинам.
UnusualLetter
del