
Это четвертая часть серии мега-учебника Flask, в которой я собираюсь рассказать вам, как работать с базами данных.
Оглавление
Глава 4: База данных (Эта статья)
Глава 5: Логины пользователей
Глава 6: Страница профиля и аватары
Глава 7: Обработка ошибок
Глава 8: Подписчики
Глава 9: Разбивка на страницы
Глава 10: Поддержка по электронной почте
Глава 11: Подтяжка лица
Глава 12: Даты и время
Глава 13: I18n и L10n
Глава 14: Ajax
Глава 15: Улучшенная структура приложения
Глава 16: Полнотекстовый поиск
Глава 17: Развертывание в Linux
Глава 18: Развертывание на Heroku
Глава 19: Развертывание в контейнерах Docker
Глава 20: Немного магии JavaScript
Глава 21: Уведомления пользователей
Глава 22: Фоновые задания
Глава 23: Интерфейсы прикладного программирования (API)
Тема этой главы чрезвычайно важна. Для большинства приложений потребуется поддерживать постоянные данные, которые можно эффективно извлекать, и это именно то, для чего созданы базы данных.
Ссылки на GitHub для этой главы: Browse, Zip, Diff.
Базы данных в Flask
Я уверен, что вы уже слышали, Flask изначально не поддерживает базы данных. Это одна из многих областей, в которых Flask намеренно не придерживается мнения, и это здорово, потому что у вас есть свобода выбора базы данных, которая наилучшим образом соответствует вашему приложению, вместо того, чтобы быть вынужденным адаптироваться к какой-либо другой.
Для баз данных на Python есть отличный выбор, многие из них с расширениями для Flask, которые обеспечивают лучшую интеграцию с приложением. Базы данных можно разделить на две большие группы: те, которые следуют реляционной модели, и те, которые этого не делают. Последнюю группу часто называют NoSQL, указывая на то, что они не реализуют популярный язык реляционных запросов SQL. Хотя в обеих группах есть отличные продукты для баз данных, мое мнение таково, что реляционные базы данных лучше подходят для приложений, которые имеют структурированные данные, такие как списки пользователей, записи в блогах и т.д., В то время как базы данных NoSQL, как правило, лучше подходят для данных с менее определенной структурой. Это приложение, как и большинство других, может быть реализовано с использованием любого типа базы данных, но по причинам, изложенным выше, я собираюсь использовать реляционную базу данных.
В главе 3 я показал вам первое расширение Flask. В этой главе я собираюсь использовать еще два. Первое - это Flask-SQLAlchemy, расширение, предоставляющее оболочку, дружественную к Flask, для популярного пакета SQLAlchemy, который представляет собой объектно-реляционное отображение или ORM. ORM позволяют приложениям управлять базой данных, используя высокоуровневые сущности, такие как классы, объекты и методы, вместо таблиц и SQL. Работа ORM заключается в преобразовании высокоуровневых операций в команды базы данных.
Самое приятное в SQLAlchemy то, что это ORM не для одной, а для многих реляционных баз данных. SQLAlchemy поддерживает длинный список движков баз данных, включая популярные MySQL, PostgreSQL и SQLite. Это чрезвычайно мощный инструмент, потому что вы можете выполнять свою разработку, используя простую базу данных SQLite, для которой не требуется сервер, а затем, когда придет время развертывать приложение на производственном сервере, вы сможете выбрать более надежный сервер MySQL или PostgreSQL без необходимости изменять свое приложение.
Чтобы установить Flask-SQLAlchemy в вашей виртуальной среде, сначала убедитесь, что вы ее активировали, а затем запустите:
(venv) $ pip install flask-sqlalchemyМиграции баз данных
Большинство туториалов по базам данных, которые я видел, посвящены созданию и использованию базы данных, но в них неадекватно рассматривается проблема внесения обновлений в существующую базу данных по мере изменения или расширения приложения. Это сложно, потому что реляционные базы данных сосредоточены вокруг структурированных данных, поэтому при изменении структуры данные, которые уже есть в базе данных, необходимо перенести в измененную структуру.
Второе расширение, которое я собираюсь представить в этой главе, - это Flask-Migrate, которое на самом деле создано мной. Это расширение представляет собой оболочку Flask для Alembic, платформы миграции баз данных для SQLAlchemy. Работа с миграциями баз данных добавляет немного работы для запуска базы данных, но это небольшая плата за надежный способ внесения изменений в вашу базу данных в будущем.
Процесс установки Flask-Migrate аналогичен другим расширениям, которые вы видели:
(venv) $ pip install flask-migrateКонфигурация Flask-SQLAlchemy
Во время разработки я собираюсь использовать базу данных SQLite. Базы данных SQLite являются наиболее удобным выбором для разработки небольших приложений, иногда даже не очень маленьких, поскольку каждая база данных хранится в одном файле на диске и нет необходимости запускать сервер баз данных, такой как MySQL и PostgreSQL.
Flask-SQLAlchemy нуждается в добавлении нового элемента конфигурации в конфигурационный файл:
config.py: Конфигурация Flask-SQLAlchemy
import os
basedir = os.path.abspath(os.path.dirname(__file__))
class Config:
# ...
SQLALCHEMY_DATABASE_URI = os.environ.get('DATABASE_URL') or \
'sqlite:///' + os.path.join(basedir, 'app.db')Расширение Flask-SQLAlchemy определяет местоположение базы данных приложения из переменной конфигурации SQLALCHEMY_DATABASE_URI. Как вы помните из главы 3, в целом хорошей практикой является установка конфигурации из переменных среды и предоставление резервного значения, когда среда не определяет переменную. В этом случае я беру URL базы данных из переменной окружения DATABASE_URL, и если это не определено, я настраиваю базу данных с именем app.db, расположенную в главном каталоге приложения, которая хранится в переменной basedir.
База данных будет представлена в приложении экземпляром базы данных. Механизм миграции базы данных также будет иметь экземпляр. Это объекты, которые необходимо создать после приложения, в app/init.py файле:
app/__init__.py: Инициализация Flask-SQLAlchemy и Flask-Migrate
from flask import Flask
from config import Config
from flask_sqlalchemy import SQLAlchemy
from flask_migrate import Migrate
app = Flask(name)
app.config.from_object(Config)
db = SQLAlchemy(app)
migrate = Migrate(app, db)
from app import routes, modelsЯ внес три изменения в файл init.py. Во-первых, я добавил объект db, представляющий базу данных. Затем я добавил migrate, чтобы представить механизм миграции баз данных. Надеюсь, вы видите шаблон работы с расширениями Flask. Большинство расширений инициализируются как эти два. В последнем изменении я импортирую новый модуль с именем models внизу. Этот модуль будет определять структуру базы данных.
Модели баз данных
Данные, которые будут храниться в базе данных, будут представлены набором классов, обычно называемых моделями базы данных. Уровень ORM в SQLAlchemy выполнит преобразования, необходимые для отображения объектов, созданных из этих классов, в строки в соответствующих таблицах базы данных.
Давайте начнем с создания модели, представляющей пользователей. Используя инструмент WWW SQL Designer, я нарисовал следующую диаграмму для представления данных, которые мы хотим использовать в таблице users:
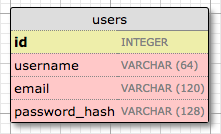
Поле id обычно есть во всех моделях и используется в качестве первичного ключа. Каждому пользователю в базе данных будет присвоено уникальное значение id, хранящееся в этом поле. Первичные ключи в большинстве случаев автоматически назначаются базой данных, поэтому мне просто нужно указать поле id, помеченное как первичный ключ.
Поля username, email и password_hash определены как строки (или, как говорят на жаргоне баз данных VARCHAR), а их максимальная длина указана для того, чтобы база данных могла оптимизировать использование пространства. Хотя поля username и email говорят сами за себя, поле password_hash заслуживает некоторого внимания. Я хочу убедиться, что приложение, которое я создаю, использует лучшие практики безопасности, и по этой причине я не буду хранить пароли пользователей в виде обычного текста. Проблема с хранением паролей заключается в том, что если база данных когда-либо будет скомпрометирована, злоумышленники получат доступ к паролям, и это может иметь разрушительные последствия для пользователей. Вместо того, чтобы писать пароли напрямую, я собираюсь написать хэши паролей, что значительно повысит безопасность. Это будет темой другой главы, так что пока не беспокойтесь об этом слишком сильно.
Итак, теперь, когда я знаю, что я хочу для своей таблицы users, я могу перевести это в код в новом модуле app/models.py:
app/models.py: Модель пользовательской базы данных
from typing import Optional
import sqlalchemy as sa
import sqlalchemy.orm as so
from app import db
class User(db.Model):
id: so.Mapped[int] = so.mapped_column(primary_key=True)
username: so.Mapped[str] = so.mapped_column(sa.String(64), index=True, unique=True)
email: so.Mapped[str] = so.mapped_column(sa.String(120), index=True, unique=True)
password_hash: so.Mapped[Optional[str]] = so.mapped_column(sa.String(256))
def __repr__(self):
return '<User {}>'.format(self.username)Я начинаю с импорта модулей sqlalchemy и sqlalchemy.orm из пакета SQLAlchemy, которые предоставляют большинство элементов, необходимых для работы с базой данных. Модуль sqlalchemy включает в себя функции базы данных общего назначения и классы, такие как типы и помощники по построению запросов, в то время как sqlalchemy.orm обеспечивает поддержку использования моделей. Учитывая, что имена этих двух модулей длинные и на них нужно будет часто ссылаться, псевдонимы sa и so определяются непосредственно в операторах импорта. В экземпляр db из Flask-SQLAlchemy и Optional также импортируются аннотации с поддержкой неопределенных значений.
Созданный выше класс User будет представлять пользователей, хранящихся в базе данных. Класс наследуется от db.Model, базовый класс для всех моделей из Flask-SQLAlchemy. В User модель определяет несколько полей как переменные класса. Это столбцы, которые будут созданы в соответствующей таблице базы данных.
С помощью аннотаций Python полям присваивается тип, обернутый в общий тип Sqlalchemy so.Mapped. Объявление типа, такое как so.Mapped[int] или so.Mapped[str] определит тип столбца, а также указывает обязательность значения, или ненулевой в терминах базы данных. Чтобы определить столбец, который может быть пустым или обнуляемым, из Python добавлен модуль Optional , поскольку поле password_hash требует именно такую поддержку.
В большинстве случаев для определения столбца таблицы требуется нечто большее, чем просто тип столбца. SQLAlchemy использует вызов функции so.mapped_column(), который назначен каждому столбцу для обеспечения этой дополнительной конфигурации. В случае поля id столбец настроен в качестве первичного ключа. Для строковых столбцов во многих базах данных требуется указывать длину, поэтому это также включено. Я включил другие необязательные аргументы, которые позволяют мне указывать, какие поля уникальны и проиндексированы, что важно для обеспечения согласованности базы данных и эффективности поиска.
Магический метод __repr__ сообщает Python, как печатать объекты этого класса, что будет полезно для отладки. Вы можете видеть метод __repr__() в действии в приведенном ниже сеансе интерпретатора Python:
>>> from app.models import User
>>> u = User(username='susan', email='susan@example.com')
>>> u
<User susan>Создание репозитория миграции
Класс модели, созданный в предыдущем разделе, определяет исходную структуру базы данных (или схему) для этого приложения. Но поскольку приложение продолжает расти, вполне вероятно, что мне нужно будет вносить изменения в эту структуру, такие как добавление новых элементов, а иногда и изменять или удалять элементы. Alembic (платформа миграции, используемая Flask-Migrate) внесет эти изменения в схему таким образом, чтобы не требовалось воссоздавать базу данных с нуля каждый раз, когда вносятся изменения.
Для выполнения этой, казалось бы, сложной задачи Alembic поддерживает репозиторий миграции, который представляет собой каталог, в котором он хранит свои сценарии миграции. Каждый раз, когда вносится изменение в схему базы данных, в репозиторий добавляется сценарий миграции с подробной информацией об изменении. Чтобы применить миграции к базе данных, эти сценарии миграции выполняются в той последовательности, в которой они были созданы.
Flask-Migrate предоставляет доступ к своим командам с помощью команды flask. Вы уже видели flask run, которая является вложенной командой, встроенной в Flask. В Flask-Migrate добавлена подкоманда flask db для управления всем, что связано с миграциями баз данных. Итак, давайте создадим репозиторий миграции для microblog, выполнив flask db init:
(venv) $ flask db init
Creating directory /home/miguel/microblog/migrations ... done
Creating directory /home/miguel/microblog/migrations/versions ... done
Generating /home/miguel/microblog/migrations/alembic.ini ... done
Generating /home/miguel/microblog/migrations/env.py ... done
Generating /home/miguel/microblog/migrations/README ... done
Generating /home/miguel/microblog/migrations/script.py.mako ... done
Please edit configuration/connection/logging settings in
'/home/miguel/microblog/migrations/alembic.ini' before proceeding.Помните, что flask команда полагается на переменную среды FLASK_APP, чтобы узнать, где находится приложение Flask. Для этого приложения вы хотите установить FLASK_APP значение равное microblog.py, как описано в главе 1. Если вы включили файл .flaskenv в свой проект, то все подкоманды команды flask автоматически получат доступ к приложению.
После выполнения команды flask db init вы обнаружите новый каталог migrations с несколькими файлами и подкаталогом versions внутри. Отныне все эти файлы следует рассматривать как часть вашего проекта и, в частности, добавлять в систему управления версиями вместе с кодом вашего приложения.
Первая миграция базы данных
Теперь, когда репозиторий миграции создан, пришло время создать первую миграцию базы данных, которая будет включать таблицу users, соответствующую модели базы данных User. Есть два способа создать миграцию базы данных: вручную или автоматически. Чтобы сгенерировать миграцию автоматически, Alembic сравнивает схему базы данных, определенную моделями баз данных, с фактической схемой базы данных, используемой в данный момент в базе данных. Затем скрипт миграции заполняется изменениями, необходимыми для приведения схемы базы данных в соответствие с моделями приложений. В этом случае, поскольку предыдущей базы данных нет, автоматическая миграция добавит всю модель User в сценарий миграции. Подкоманда flask db migrate генерирует эти автоматические миграции:
(venv) $ flask db migrate -m "users table"
INFO [alembic.runtime.migration] Context impl SQLiteImpl.
INFO [alembic.runtime.migration] Will assume non-transactional DDL.
INFO [alembic.autogenerate.compare] Detected added table 'user'
INFO [alembic.autogenerate.compare] Detected added index 'ix_user_email' on '['email']'
INFO [alembic.autogenerate.compare] Detected added index 'ix_user_username' on '['username']'
Generating /home/miguel/microblog/migrations/versions/e517276bb1c2_users_table.py ... doneВывод команды дает вам представление о том, что Alembic включил в миграцию. Первые две строки являются информационными и их обычно можно игнорировать. Затем говорится, что найдена таблица пользователя и два индекса. Затем он сообщает вам, где был написан сценарий миграции. Значение e517276bb1c2 представляет собой автоматически сгенерированный уникальный код для миграции (у вас он будет другим). Комментарий, приведенный с параметром -m, необязателен, он просто добавляет короткий описательный текст к миграции.
Сгенерированный сценарий миграции теперь является частью вашего проекта, и если вы используете git или другой инструмент управления версиями, его необходимо включить в качестве дополнительного исходного файла вместе со всеми другими файлами, хранящимися в каталоге migrations. Вы можете ознакомиться со скриптом, если вам интересно посмотреть, как он выглядит. Вы обнаружите, что у него есть две функции, которые называются upgrade() и downgrade(). Функция upgrade() применяет миграцию, а функция downgrade() удаляет ее. Это позволяет Alembic переносить базу данных в любую точку истории, даже в более старые версии, используя путь понижения версии.
Команда flask db migrate не вносит никаких изменений в базу данных, она просто генерирует сценарий миграции. Чтобы применить изменения к базе данных, необходимо использовать команду flask db upgrade.
(venv) $ flask db upgrade
INFO [alembic.runtime.migration] Context impl SQLiteImpl.
INFO [alembic.runtime.migration] Will assume non-transactional DDL.
INFO [alembic.runtime.migration] Running upgrade -> e517276bb1c2, users tableПоскольку это приложение использует SQLite, команда upgrade обнаружит, что база данных не существует, и создаст ее (вы заметите, что после завершения работы этой команды добавляется файл с именем app.db, который является базой данных SQLite). При работе с серверами баз данных, такими как MySQL и PostgreSQL, вы должны создать базу данных на сервере баз данных перед запуском upgrade.
Обратите внимание, что Flask-SQLAlchemy по умолчанию использует соглашение об именовании таблиц базы данных в виде "змеиного падежа". Для User модели, приведенной выше, соответствующая таблица в базе данных будет названа user. Для класса модели AddressAndPhone таблица будет называться address_and_phone. Если вы предпочитаете выбирать собственные имена таблиц, вы можете добавить атрибут с именем tablename к классу модели, присвоив ему желаемое имя в виде строки.
Рабочий процесс обновления и понижения версии базы данных
На данный момент приложение находится в зачаточном состоянии, но не помешает обсудить, какой будет стратегия миграции базы данных в будущем. Представьте, что у вас есть приложение на компьютере разработчика, а также есть копия, развернутая на рабочем сервере, который подключен к сети и используется.
Допустим, что для следующего выпуска вашего приложения вам необходимо внести изменения в ваши модели, например, необходимо добавить новую таблицу. Без миграций вам нужно было бы выяснить, как изменить схему вашей базы данных, как на вашей машине разработки, так и затем снова на вашем сервере, и это могло бы потребовать много работы.
Но благодаря поддержке миграции баз данных после изменения моделей в вашем приложении вы создаете новый сценарий миграции (flask db migrate), просматриваете его, чтобы убедиться, что автоматическая генерация выполнила все правильно, а затем применяете изменения к своей базе данных разработки (flask db upgrade). Вы добавите сценарий миграции в систему управления версиями и зафиксируете его.
Когда вы будете готовы выпустить новую версию приложения на свой рабочий сервер, все, что вам нужно сделать, это получить обновленную версию вашего приложения, которая будет включать новый сценарий миграции, и запустить flask db upgrade. Alembic обнаружит, что производственная база данных не обновлена до последней версии схемы, и запустит все новые сценарии миграции, которые были созданы после предыдущего выпуска.
Как я упоминал ранее, у вас также есть flask db downgrade команда, которая отменяет последнюю миграцию. Хотя вам вряд ли понадобится эта опция в производственной системе, она может оказаться очень полезной во время разработки. Возможно, вы сгенерировали сценарий миграции и применили его только для того, чтобы обнаружить, что внесенные вами изменения не совсем то, что вам нужно. В этом случае вы можете понизить рейтинг базы данных, удалить сценарий миграции, а затем сгенерировать новый для его замены.
Взаимосвязи с базами данных
Реляционные базы данных хороши для хранения связей между элементами данных. Рассмотрим случай, когда пользователь пишет сообщение в блоге. У пользователя будет запись в таблице users, а у публикации будет запись в таблице posts . Самый эффективный способ записать, кто написал данный пост, - это связать две связанные записи.
Как только связь между пользователем и публикацией установлена, база данных может отвечать на запросы об этой ссылке. Самый тривиальный - это когда у вас есть запись в блоге и вам нужно знать, какой пользователь ее написал. Более сложный запрос, обратный этому. Если у вас есть пользователь, вы можете захотеть ознакомиться со всеми публикациями, написанными этим пользователем. SQLAlchemy помогает с обоими типами запросов.
Давайте расширим базу данных для хранения записей в блоге, чтобы увидеть взаимосвязи в действии. Вот схема для новой таблицы записей.:

В таблице posts будут указаны требуемые id, body (тело публикации) и timestamp. Но в дополнение к этим ожидаемым полям я добавляю поле user_id, которое связывает публикацию с ее автором. Вы видели, что у всех пользователей есть первичный ключ id, который уникален. Способ связать запись в блоге с пользователем, который ее создал, заключается в добавлении ссылки на id пользователя, и это именно то, для чего предназначено поле user_id. Это поле user_id называется внешним ключом, потому что оно ссылается на первичный ключ другой таблицы. На приведенной выше схеме базы данных внешние ключи показаны как связующее звено между своим полем и полем id таблицы, на которую оно ссылается. Такого рода отношения называются один ко многим, потому что "один" пользователь пишет "много" сообщений.
Измененный app/models.py показан ниже:
app/models.py: Публикует таблицу базы данных и взаимосвязь
from datetime import datetime, timezone
from typing import Optional
import sqlalchemy as sa
import sqlalchemy.orm as so
from app import db
class User(db.Model):
id: so.Mapped[int] = so.mapped_column(primary_key=True)
username: so.Mapped[str] = so.mapped_column(sa.String(64), index=True,
unique=True)
email: so.Mapped[str] = so.mapped_column(sa.String(120), index=True,
unique=True)
password_hash: so.Mapped[Optional[str]] = so.mapped_column(sa.String(256))
posts: so.WriteOnlyMapped['Post'] = so.relationship(
back_populates='author')
def __repr__(self):
return '<User {}>'.format(self.username)
class Post(db.Model):
id: so.Mapped[int] = so.mapped_column(primary_key=True)
body: so.Mapped[str] = so.mapped_column(sa.String(140))
timestamp: so.Mapped[datetime] = so.mapped_column(
index=True, default=lambda: datetime.now(timezone.utc))
user_id: so.Mapped[int] = so.mapped_column(sa.ForeignKey(User.id),
index=True)
author: so.Mapped[User] = so.relationship(back_populates='posts')
def __repr__(self):
return '<Post {}>'.format(self.body)Новый класс Post будет представлять записи в блогах, написанные пользователями. Поле timestamp определено с помощью аннотации типа datetime и настроено на индексацию, что полезно, если вы хотите эффективно извлекать записи в хронологическом порядке. Я также добавил аргумент default и передал функцию лямбда, которая возвращает текущее время в часовом поясе UTC. Когда вы передаете функцию по умолчанию, SQLAlchemy присваивает полю значение, возвращаемое функцией. В общем, вам захочется работать с датами и временем UTC в серверном приложении, а не с местным временем того места, где вы находитесь. Это гарантирует, что вы используете единые временные метки независимо от того, где расположены пользователи и сервер. Эти временные метки будут преобразованы в местное время пользователя при их отображении.
Поле user_id было инициализировано как внешний ключ к User.id, что означает, что оно ссылается на значения из столбца id в таблице users. Поскольку не все базы данных автоматически создают индекс для внешних ключей, index=True опция добавлена явно, чтобы оптимизировать поиск по этому столбцу.
У класса User появилось новое поле posts, которое инициализируется с помощью so.relationship(). Это не фактическое поле базы данных, а высокоуровневое представление взаимосвязи между пользователями и публикациями, и по этой причине его нет на схеме базы данных. Аналогично, у Post класса есть author поле, которое также инициализируется как отношение. Эти два атрибута позволяют приложению получать доступ к связанным записям user и post.
Первым аргументом для so.relationship() является класс модели, который представляет другую сторону взаимосвязи. Этот аргумент может быть предоставлен в виде строки, что необходимо, когда класс определяется позже в модуле. Аргумент back_populates ссылается на имя атрибута отношения на другой стороне, так что SQLAlchemy знает, что эти атрибуты относятся к двум сторонам одного и того же отношения.
В атрибуте posts relationship используется другое определение типа. Вместо so.Mapped он использует so.WriteOnlyMapped, который определяет posts как тип коллекции с объектами Post внутри. Не волнуйтесь, если эти детали пока не имеют особого смысла, я покажу вам примеры этого в конце этой статьи.
Поскольку у меня есть обновления моделей приложений, необходимо создать новую миграцию базы данных:
(venv) $ flask db migrate -m "posts table"
INFO [alembic.runtime.migration] Context impl SQLiteImpl.
INFO [alembic.runtime.migration] Will assume non-transactional DDL.
INFO [alembic.autogenerate.compare] Detected added table 'post'
INFO [alembic.autogenerate.compare] Detected added index 'ix_post_timestamp' on
'['timestamp']'
Generating /home/miguel/microblog/migrations/versions/780739b227a7_posts_table.py ... doneИ миграция должна быть применена к базе данных:
(venv) $ flask db upgrade
INFO [alembic.runtime.migration] Context impl SQLiteImpl.
INFO [alembic.runtime.migration] Will assume non-transactional DDL.
INFO [alembic.runtime.migration] Running upgrade e517276bb1c2 -> 780739b227a7, posts tableЕсли вы сохраняете свой проект в системе управления версиями, также не забудьте добавить в него новый сценарий миграции.
Играем с базой данных
Я заставил вас помучиться в течение длительного процесса определения базы данных, но я еще не показал вам, как все работает. Поскольку в приложении пока нет никакой логики базы данных, давайте поиграем с базой данных в интерпретаторе Python, чтобы ознакомиться с ней. Запустите Python, выполнив команду python в вашем терминале. Убедитесь, что ваша виртуальная среда активирована, прежде чем запускать интерпретатор.
Перейдя в приглашение Python, давайте импортируем приложение, экземпляр базы данных, модели и точку входа SQLAlchemy:
>>> from app import app, db
>>> from app.models import User, Post
>>> import sqlalchemy as saСледующий шаг немного странный. Чтобы Flask и его расширения имели доступ к приложению Flask без необходимости передавать app в качестве аргумента в каждую функцию, необходимо создать и передать контекст приложения. Контексты приложений будут рассмотрены более подробно позже в этом туториале, поэтому пока введите следующий код в сеансе Python shell:
>>> app.app_context().push()Далее создайте нового пользователя:
>>> u = User(username='john', email='john@example.com')
>>> db.session.add(u)
>>> db.session.commit()Изменения в базе данных выполняются в контексте сеанса базы данных, доступ к которому можно получить как db.session. За сеанс можно накопить несколько изменений, и как только все изменения будут зарегистрированы, вы можете выпустить один коммит db.session.commit(), который записывает все изменения атомарно. Если в любой момент во время работы с сеансом возникает ошибка, вызов db.session.rollback() прервет сеанс и удалит все изменения, сохраненные в нем. Важно помнить, что изменения записываются в базу данных только при выполнении коммита с помощью db.session.commit(). Сеансы гарантируют, что база данных никогда не останется в несогласованном состоянии.
Вам интересно, как все эти операции с базой данных узнают, какую базу данных использовать? Контекст приложения, который был добавлен выше, позволяет Flask-SQLAlchemy обращаться к экземпляру приложения Flask app без необходимости получать его в качестве аргумента. Расширение ищет в словаре app.config запись SQLALCHEMY_DATABASE_URI, которая содержит URL базы данных.
Давайте добавим еще одного пользователя:
>>> u = User(username='susan', email='susan@example.com')
>>> db.session.add(u)
>>> db.session.commit()База данных может отвечать на запрос, который возвращает всех пользователей:
>>> query = sa.select(User)
>>> users = db.session.scalars(query).all()
>>> users
[<User john>, <User susan>]Переменной query в этом примере присваивается базовый запрос, который выбирает всех пользователей. Это достигается путем передачи класса User вспомогательной функции запроса SQLAlchemy sa.select(). Вы обнаружите, что большинство запросов к базе данных начинаются с вызова sa.select().
Сеанс базы данных, который выше использовался для определения и фиксации изменений, также используется для выполнения запросов. Метод db.session.scalars() выполняет запрос к базе данных и возвращает итератор результатов. Вызов метода all() объекта results преобразует результаты в обычный список.
Во многих ситуациях наиболее эффективно использовать итератор результатов в цикле for вместо преобразования его в список:
>>> users = db.session.scalars(query)
>>> for u in users:
... print(u.id, u.username)
...
1 john
2 susanОбратите внимание, что полям id были автоматически присвоены значения 1 и 2 при добавлении этих пользователей. Это происходит потому, что SQLAlchemy настраивает целочисленные столбцы первичного ключа на автоматическое увеличение.
Вот еще один способ выполнения запросов. Если вы знаете id пользователя, вы можете получить этого пользователя следующим образом:
>>> u = db.session.get(User, 1)
>>> u
<User john>Теперь давайте добавим запись в блог:
>>> u = db.session.get(User, 1)
>>> p = Post(body='my first post!', author=u)
>>> db.session.add(p)
>>> db.session.commit()Мне не нужно было устанавливать значение для timestamp поля, потому что у этого поля есть значение по умолчанию, которое вы можете увидеть в определении модели. А что насчет поля user_id? Напомним, что so.relationship который я создал в Post классе, добавляет атрибут author к записям. Я назначаю автора публикации, используя это поле author вместо того, чтобы иметь дело с идентификаторами пользователей. SQLAlchemy великолепен в этом отношении, поскольку обеспечивает высокоуровневую абстракцию над отношениями и внешними ключами.
Чтобы завершить этот сеанс, давайте рассмотрим еще несколько запросов к базе данных:
>>> # get all posts written by a user
>>> u = db.session.get(User, 1)
>>> u
<User john>
>>> query = u.posts.select()
>>> posts = db.session.scalars(query).all()
>>> posts
[<Post my first post!>]
>>> # same, but with a user that has no posts
>>> u = db.session.get(User, 2)
>>> u
<User susan>
>>> query = u.posts.select()
>>> posts = db.session.scalars(query).all()
>>> posts
[]
>>> # print post author and body for all posts
>>> query = sa.select(Post)
>>> posts = db.session.scalars(query)
>>> for p in posts:
... print(p.id, p.author.username, p.body)
...
1 john my first post!
# get all users in reverse alphabetical order
>>> query = sa.select(User).order_by(User.username.desc())
>>> db.session.scalars(query).all()
[<User susan>, <User john>]
# get all users that have usernames starting with "s"
>>> query = sa.select(User).where(User.username.like('s%'))
>>> db.session.scalars(query).all()
[<User susan>]Обратите внимание, как в первых двух примерах выше используется связь между пользователями и публикациями. Напомним, что у модели User есть атрибут relationship posts , который был настроен с помощью универсального типа WriteOnlyMapped. Это особый тип связи, который добавляет метод select(), возвращающий запрос к базе данных для связанных элементов. Выражение u.posts.select() отвечает за генерацию запроса, который связывает пользователя с его публикациями в блоге.
Последний запрос демонстрирует, как фильтровать содержимое таблицы с помощью условия. Метод where() используется для создания фильтров, которые отбирают только подмножество строк из выбранного объекта. В этом примере я использую оператор like() для выбора пользователей на основе шаблона.
Документация по SQLAlchemy - лучшее место для ознакомления со многими опциями, доступными для запросов к базе данных.
В завершение выйдите из оболочки Python и используйте следующие команды, чтобы удалить тестовых пользователей и записи, созданные выше, чтобы база данных была чистой и готовой к следующей главе:
(venv) $ flask db downgrade base
(venv) $ flask db upgradeПервая команда сообщает Flask-Migrate применить миграции базы данных в обратном порядке. Когда downgrade команде не задан целевой параметр, она понижает рейтинг на одну ревизию. Цель base вызывает понижение рейтинга всех миграций до тех пор, пока база данных не останется в исходном состоянии, без таблиц.
Команда upgrade повторно применяет все миграции в прямом порядке. Целью обновлений по умолчанию является head, которая является кратчайшим путем для самой последней миграции. Эта команда эффективно восстанавливает таблицы, которые были понижены выше. Поскольку при миграции базы данных данные, хранящиеся в базе данных, не сохраняются, понижение рейтинга и последующее обновление приводит к быстрому удалению всех таблиц.
Контекст оболочки
Помните, что вы делали в начале предыдущего раздела, сразу после запуска интерпретатора Python? В начале вы ввели некоторые импортные данные, а затем запустили контекст приложения:
>>> from app import app, db
>>> from app.models import User, Post
>>> import sqlalchemy as sa
>>> app.app_context().push()Во время работы над своим приложением вам нужно будет очень часто тестировать что-либо в оболочке Python, поэтому повторять приведенные выше инструкции каждый раз будет утомительно. Сейчас самое подходящее время для решения этой проблемы.
Подкоманда flask shell - еще один очень полезный инструмент в наборе команд flask. Команда shell - вторая "основная" команда, реализованная в Flask после run. Цель этой команды - запустить интерпретатор Python в контексте приложения. Что это значит? Смотрите следующий пример:
(venv) $ python
>>> app
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'app' is not defined
>>>
(venv) $ flask shell
>>> app
<Flask 'app'>При обычном сеансе интерпретатора объект app неизвестен, если он явно не импортирован, но при использовании flask shell команда предварительно импортирует экземпляр приложения и передает вам контекст его приложения. Приятная особенность flask shell заключается не только в том, что он выполняет предварительный импорт app, но и в том, что вы также можете настроить "контекст оболочки", который представляет собой список других символов для предварительного импорта.
Следующая функция в microblog.py создает контекст оболочки, который добавляет экземпляр базы данных и модели в сеанс оболочки:
import sqlalchemy as sa
import sqlalchemy.orm as so
from app import app, db
from app.models import User, Post
@app.shell_context_processor
def make_shell_context():
return {'sa': sa, 'so': so, 'db': db, 'User': User, 'Post': Post}Декоратор app.shell_context_processor регистрирует функцию как контекстную функцию оболочки. Когда команда flask shell выполняется, она вызывает эту функцию и регистрирует элементы, возвращаемые ею, в сеансе оболочки. Причина, по которой функция возвращает словарь, а не список, заключается в том, что для каждого элемента вы также должны указать имя, под которым на него будут ссылаться в командной строке, которое задается ключами словаря.
После добавления функции контекстного процессора оболочки вы сможете работать с объектами базы данных без необходимости их импорта:
(venv) $ flask shell
>>> db
<SQLAlchemy sqlite:////home/miguel/microblog/app.db>
>>> User
<class 'app.models.User'>
>>> Post
<class 'app.models.Post'>Если вы попробуете вышеописанное и получите исключение NameError при попытке доступа к sa, so, db, User и Post, то функция make_shell_context() не регистрируется в Flask. Наиболее вероятной причиной этого является то, что вы не настроили в среде FLASK_APP=microblog.py. В таком случае вернитесь к главе 1 и рассмотрите, как установить переменную среды FLASK_APP. Если вы часто забываете установить эту переменную при открытии новых окон терминала, вы можете рассмотреть возможность добавления файла .flaskenv в свой проект, как описано в конце этой главы.