
Привет! Мы – Екатерина и Виктория, разработчик и старший разработчик в БФТ-Холдинге. В статье кратко расскажем об основах DGS фреймворка, его преимуществах, проблемах, с которыми мы столкнулись при работе с ним, а также покажем создание простого сервиса с поддержкой WebFlux.
DGS (Domain Graph Service) – open source проект компании Netflix. Сначала он был внутренним проектом компании, однако в 2020 году было решено сделать его открытым для сообщества. Фреймворк развивается с 2019 года и использовался Netflix еще до вывода в open source. По словам создателей, DGS фреймворк является production-ready решением.
DGS – один из нескольких фреймворков для работы с GraphQL в Java. Он построен на основе библиотеки graphql-java и упрощает работу с ней.
Причины выбора DGS Framework
DGS предоставляет удобные готовые инструменты для настройки проекта. Фреймворк предоставляет возможность настраивать шаблонный обработчик запросов через DataFetcher<T> и собирать схему с помощью аннотаций @DgsCodeRegistry и @DgsTypeDefinitionRegistry, что позволяет хранить метаданные схемы в любой структуре и строить их во время старта приложения. В том числе DGS фреймворк умеет загружать уже готовые схемы GraphQLSchema, где они будут объединены с другими схемами (уже готовыми или из аннотаций). В своем примере для простоты мы рассматриваем именно загрузку уже готовой схемы, но на практике проект чаще всего выглядит не так просто.
Технические требования
DGS фреймворк использует Spring Boot. Для 6.x и более поздних версий фреймворка требуется Spring Boot 3 и JDK 17. Однако, можно использовать фреймворк и с более ранними версиями Spring Boot, тогда нужно будет использовать более старые версии DGS фреймворка. Для проектов со Spring Boot 2.7 подойдут релизы DGS 5.5.x. Если же в проекте используется Spring Boot 2.6, тогда потребуется версия 5.4.x.
Реализация GraphQL сервиса
Здесь будут кратко описаны основные моменты создания приложения с использованием DGS фреймворка.
Начальная настройка
Начнем с создания Spring Boot приложения. В проекте использовались JDK 17, Spring Boot 3.0.11, WebFlux и Maven. Напомним, что старые версии Spring Boot не поддерживаются в новых версиях DGS (начиная с 6.x).
Структура проекта будет выглядеть таким образом:
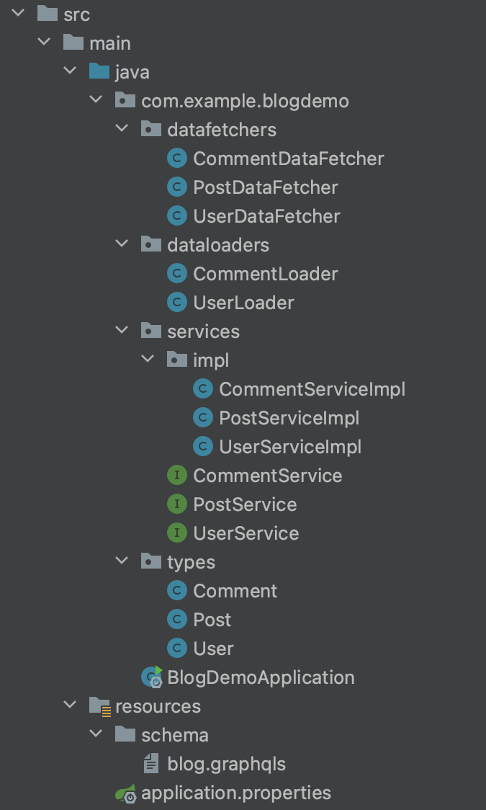
Перейдем в сгенерированный проект. Добавим необходимые зависимости в pom.xml:
<dependencyManagement>
<dependencies>
<dependency>
<groupId>com.netflix.graphql.dgs</groupId>
<artifactId>graphql-dgs-platform-dependencies</artifactId>
<!-- The DGS BOM/platform dependency. This is the only place you set version of DGS -->
<version>6.0.5</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<!-- fix bug Could not initialize class com.netflix.graphql.dgs.DgsExecutionResult$Builder -->
<dependency>
<groupId>com.graphql-java</groupId>
<artifactId></artifactId>
<version>20.3</version>
</dependency>
</dependencies>
</dependencyManagement>
<dependency>
<groupId>com.netflix.graphql.dgs</groupId>
<artifactId>graphql-dgs-webflux-starter</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.28</version>
</dependency>В тестовом проекте мы рассматриваем именно graphql-dgs-webflux-starter, так как по большей части мы стремимся к использованию реактивного программирования, и нам необходимо было выяснить возможность поддержки работы неблокирующего подхода со стороны DGS Framework. Если проект основан на обычном Spring Boot, то можно использовать graphql-dgs-spring-boot-starter.
Блок com.graphql-java в <dependencyManagement> требуется для исправления ошибки Could not initialize class com.netflix.graphql.dgs.DgsExecutionResult$Builder. Причина этой ошибки состоит в том, что по умолчанию тянется неподходящая версия зависимости com.graphql-java. Поэтому нужно указать версию вручную в dependencyManagement (подробнее о проблеме и решении можно почитать здесь).
Кодогенерация
Если есть необходимость генерировать java-модели и data fetcher, можно добавить использование кодогенератора. У фреймворка есть такой плагин (для Gradle, для Maven есть только плагин от комьюнити). Мы использовали только базовые возможности и настройки плагина: указали путь к схеме <schemaPaths> и пакет для сгенерированных классов <packageName>.
Плагин достаточно гибкий и позволяет настроить многие свои параметры. Подробнее о настройках генерации и списке настраиваемых параметров можно прочитать на странице плагина в GitHub.
<dependency>
<groupId>com.netflix.graphql.dgs.codegen</groupId>
<artifactId>graphql-dgs-codegen-client-core</artifactId>
<version>5.1.17</version>
</dependency>
<plugin>
<groupId>io.github.deweyjose</groupId>
<artifactId>graphqlcodegen-maven-plugin</artifactId>
<version>1.24</version>
<executions>
<execution>
<goals>
<goal>generate</goal>
</goals>
</execution>
</executions>
<configuration>
<schemaPaths>
<param>src/main/resources/schema/blog.graphqls</param>
</schemaPaths>
<packageName>com.example.blogdemo.generated</packageName>
</configuration>
</plugin>
<plugin>
<groupId>org.codehaus.mojo</groupId>
<artifactId>build-helper-maven-plugin</artifactId>
<executions>
<execution>
<phase>generate-sources</phase>
<goals>
<goal>add-source</goal>
</goals>
<configuration>
<sources>
<source>${project.build.directory}/generated-sources</source>
</sources>
</configuration>
</execution>
</executions>
</plugin>Схема
Далее, следуя schema-first подходу, добавим GraphQL схему в src/resources/schema/blog.graphqls. В данном проекте в качестве примера будет описана структура простого блога с постами, комментариями и их авторами:
type Query {
posts(titleFilter: String): [Post]
post(idFilter: Int!): Post
}
type Post {
id: Int!
title: String
text: String
likes: Int
author: User!
comments: [Comment]
}
type Comment {
id: Int!
text: String!
user: User!
post: Post!
}
type User {
id: Int!
name: String!
email: String
}Эта схема описывает два запроса: списка постов (posts) и одного поста по его id (post). В запросе posts фильтр по заголовку titleFilter является необязательным, то есть можно будет выполнять запрос с фильтром или без него. Также в схеме содержится описание объектных типов данных, которые используются в этих запросах (Post, Comment и User).
Модели
Затем потребуются аналогичные java-модели, соответствующие каждому описанному в схеме объектному типу. Их можно либо сгенерировать на основе схемы с помощью плагина, о котором говорилось выше, либо написать самостоятельно. Они представляют собой обычные POJO классы и отражают структуру данных, описанную в blog.graphqls. Например, класс данных о посте будет выглядеть таким образом:
@Getter
@Setter
@AllArgsConstructor
@NoArgsConstructor
public class Post {
private Integer id;
private String title;
private String text;
private Integer likes;
private Integer authorId;
}Для упрощения структуры класса использую Lombok.
Data Fetcher
Data fetcher отвечают за обработку запроса и возвращают результат его выполнения. Они так же могут быть сгенерированы или написаны вручную. Эти классы должны быть отмечены аннотацией @DgsComponent. Например, data fetcher для постов будет выглядеть так:
@DgsComponent
@AllArgsConstructor
public class PostDataFetcher {
private final PostService postService;
@DgsQuery
public Flux<Post> posts(@InputArgument String titleFilter) {
if (titleFilter == null) {
return postService.getPosts();
}
return postService.getPostsByTitle(titleFilter);
}
@DgsQuery
public Mono<Post> post(@InputArgument Integer idFilter) {
return postService.getPostById(idFilter);
}
}Методы нужно отметить аннотацией @DgsQuery и они соответствует запросам, описанным в схеме blog.graphqls . Кроме @DgsQuery в DGS фреймворке есть специализированные аннотации, которые указывают на другие GraphQL операции: @DgsMutation и @DgsSubscription.
Для большей наглядности в data fetcher данные получаем из простых сервисов, которые просто возвращают данные из массива.
Data Loader и проблема N+1
Представим, что требуется получить список постов с информацией об авторе каждого поста. И допустим, что посты и авторов мы будем получать из двух разных сервисов. В простой реализации, для получения информации о N постах потребуется 1 раз обратиться к сервису постов для получения списка постов и N раз обращаться к сервису с авторами, по одному разу для каждого поста. Значит, в сумме потребуется выполнить N+1 запрос. Очевидно, что это не очень оптимальное решение.

Описанная ситуация известна как проблема N+1. Она не является уникальной для GraphQL, и, в зависимости от инструмента, может решаться различными способами. При использовании DGS эту проблему можно решить с помощью использования data loader и пакетной загрузки данных.
Процесс получения данных изменится таким образом: после получения списка постов будет подготавливаться список требующихся id авторов. Далее с полученным набором id будет выполнен запрос сразу всего списка авторов.

Реализация такого подхода возможна при выполнении двух условий. Во-первых, сервис авторов должен предоставлять возможность загрузить список пользователей по списку id. И, во-вторых, data fetcher должен быть способен выполнять пакетную загрузку из сервиса пользователей.
Создадим data loader. Этот класс будет реализовывать org.dataloader.BatchLoader или org.dataloader.MappedBatchLoader. Эти классы являются дженериками, поэтому потребуется указать типы для ключа и объекта результата. В данном примере мы будем искать пользователей с типом User по их id типа Integer, поэтому будем использовать org.dataloader.BatchLoader<Integer, User>.
@DgsDataLoader(name = "users")
@AllArgsConstructor
public class UserLoader implements BatchLoader<Integer, User> {
private final UserService userService;
@Override
public CompletionStage<List<User>> load(List<Integer> list) {
return CompletableFuture.supplyAsync(()->userService.getUserListByIds(list));
}
}В созданном классе потребуется реализовать только один метод: CompletionStage<List> load(List keys). Созданный класс необходимо пометить аннотацией @DgsDataLoader, чтобы фреймворк распознал его как data loader. Однако, хоть data loader и будет зарегистрирован благодаря аннотации, он не будет использован, пока не будет описано его использование в data fetcher.
При получении списка комментариев для списка постов, описанный подход останется применимым, но с некоторыми изменениями. Изменятся тип результата и типы данных, которые получает и возвращает переопределяемый метод:
@DgsDataLoader
@AllArgsConstructor
public class CommentLoader implements MappedBatchLoader<Integer, List<Comment>> {
private final CommentService commentService;
@Override
public CompletionStage<Map<Integer, List<Comment>>> load(Set<Integer> list) {
return CompletableFuture.supplyAsync(()->commentService.getCommentListByPostIds(new ArrayList<>(list)));
}
}Использование Data Loader
Как было упомянуто выше, описанный data loader необходимо использовать в каком-нибудь data fetcher. Создадим такой data fetcher. Так как пользователь будет нужен и в посте, и в комментарии, метода в классе будет тоже два.
@DgsComponent
public class UserDataFetcher {
@DgsData(parentType = "Post", field = "author")
public CompletableFuture<User> author(DgsDataFetchingEnvironment dfe) {
DataLoader<Integer, User> dataLoader = dfe.getDataLoader(UserLoader.class);
Post post = dfe.getSource();
Integer id = post.getAuthorId();
return dataLoader.load(id);
}
@DgsData(parentType = "Comment", field = "user")
public CompletableFuture<User> commentUser(DataFetchingEnvironment dfe) {
DataLoader<Integer, User> dataLoader = dfe.getDataLoader("users");
Comment comment = dfe.getSource();
Integer id = comment.getUserId();
return dataLoader.load(id);
}
}
В @DgsData указываем родительский объектный тип и поле, для которого этот метод будет выполняться. Тип возвращаемого значения у методов будет CompletableFuture, это требуется для пакетной загрузки данных. Самое же главное отличие этого data fetcher будет в том, что данные будут подгружаться не напрямую из сервиса с данными, а через data loader.
Получить нужный data loader можно двумя способами, в зависимости от того, что указано в получаемых параметрах метода: DataFetchingEnvironment или DgsDataFetchingEnvironment. В случае работы с DgsDataFetchingEnvironment искать нужный data loader можно по имени класса. Этот способ является более типо-безопасным. Если же использовать DataFetchingEnvironment, то поиск data loader будет осуществляться по его имени. Поэтому потребуется задать это имя с помощью параметра name в аннотации @DgsDataLoader.
В примере выше первый метод использует DgsDataFetchingEnvironment, второй – DataFetchingEnvironment.
RxJava в Data Fetcher
Небольшое замечание о том, почему в data fetcher, использующем data loader, возвращаемым типом является CompletableFuture, а не Flux, как ожидалось. Как уже упоминалось в начале статьи, DGS фреймворк использует внутри библиотеку graphql-java. А graphql-java, в свою очередь, не поддерживает RxJava / WebFlux. И DGS сам конвертирует CompletableFuture в Mono/Flux.
Запуск
DGS фреймворк по умолчанию добавляет в проект возможность использования инструмента GraphiQL. Получить к нему доступ можно по адресу http://localhost:8080/graphiql после стандартного запуска проекта.

Вывод
DGS Framework предоставляет простой и довольно привлекательный способ использования GraphQL. Платформа DGS делает быстрой и доступной обработку выполнения запросов, упрощая процесс разработки проекта. Исходный код демонстрационного проекта можно найти в моем репозитории.
В этой статье рассматривается лишь малая часть того, что умеет DGS Framework, поэтому если у вас остались вопросы по фреймворку, мы с удовольствием ответим на них.
Надеюсь, статья была интересной и полезной. Спасибо за внимание!
JajaComp
Лично мне graphql-kotlin показался более гибким, поэтому выбрал его.