
Привет, Хабр.
В первой статье о Flowise я коротко рассказывал про инструмент, о том, как поставить его локально или на Render и показал несколько примеров чат-ботов.
В этой статье хочу показать как без кода сделать чат-бот, доступный локально без подключение к сети.
Причин почему вам может понадобиться локальная модель может быть много. Самая очевидная - это бесплатно. А ещё вы сможете использовать эту модель оффлайн и сохранять privacy.
Для меня это удобный способ использования в самолёте или в авто in the middle of nowhere. Заранее выгрузив себе файлы я могу делать анализ бесед саппорта с клиентами, или получить саммарайз отзывов из стора на приложение, или оценить резюме/тестовое задание кандидата.
Кейсы:
1/ Поставить себе локально модель GPT4all и использовать со Flowise.
2/ Поставить и использовать Ollama со своей машины. Создать чат-бот для анализа файлов на модели llama2.
Полезные ссылки:
1/ Github: https://github.com - понадобится аккаунт на Github.
2/ Docker Desktop https://www.docker.com/products/docker-desktop/ - понадобиться в первом кейсе.
3/ LocalAI https://github.com/mudler/LocalAI - понадобиться в первом кейсе.
4/ GPT4all https://gpt4all.io/index.html - понадобиться в первом кейсе.
5/ Ollama https://ollama.com/download/windows - понадобится во втором кейсе.
Важно: что Ollama, что LocalAI будут есть достаточно много ресурсов вашей машины.
Параметры моей не слишком впечатляют:
_Процессор: 11th Gen Intel(R) Core(TM) i7-1185G7 @ 3.00GHz 1.80 GHz
_Оперативная память: 32,0 ГБ
_ОС: Windows11 Pro x64
_Видео: Intel Iris Xe
Работает всё небыстро (а иногда откровенно медленно).
Не стоит ожидать, что это будет так же, как ChatGPT с серверов OpenAI.
Кейс 1. GPT4all - поставить себе локально бесплатную модель.
Скачайте и установите Docker. Просто следуйте рекомендациям и используйте значения по умолчанию. Он понадобится, чтобы установить другой тул - LocalAI.
Если вы выполнили всё корректно, вы увидите примерно вот такое окно Docker-а
Затем нам понадобится скопировать себе код репозитория LocalAI, для этого создайте себе папку на вашей машине, а в репозитории кликайте Code и кнопку копирования:

Чтобы запустить командную строку, можно использовать адресную строку вашей папки, так не нужно будет переходить в эту папку при помощи команды cd:
В командной строке выполните git clone https://github.com/mudler/LocalAI, код скопируется. В папке models пусто, туда мы должны поместить те модели, которые мы собираемся использовать.

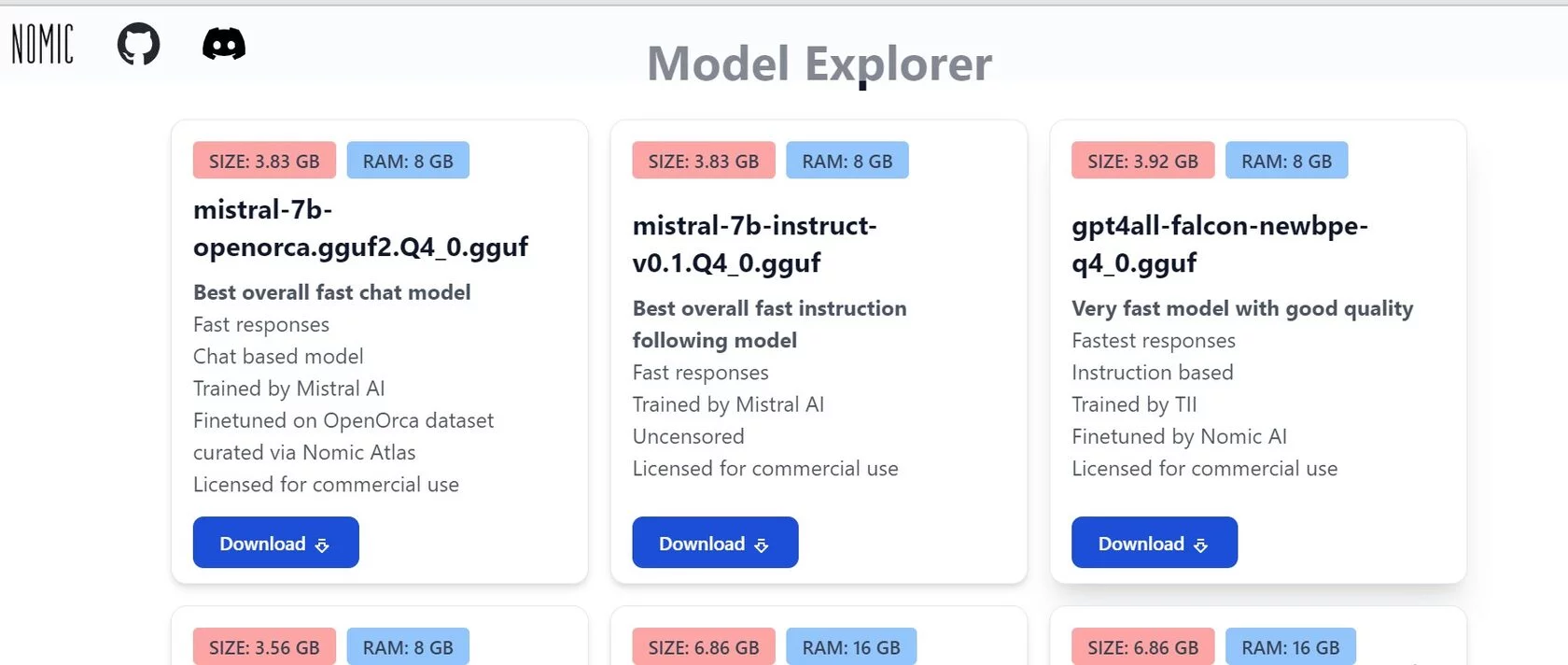
Скопируем популярную модель GPT4all. Скрольте до раздела Model Explorer, тут вы сможете выбрать модель. Не забывайте, что модели могут быть разными, разного размера и будут требовать ресурсов. Рекомендую пробовать на чём-то маленьком и простом. Я буду использовать gpt4all-falcon-newbpe-q4_0.gguf. Кликайте Download:
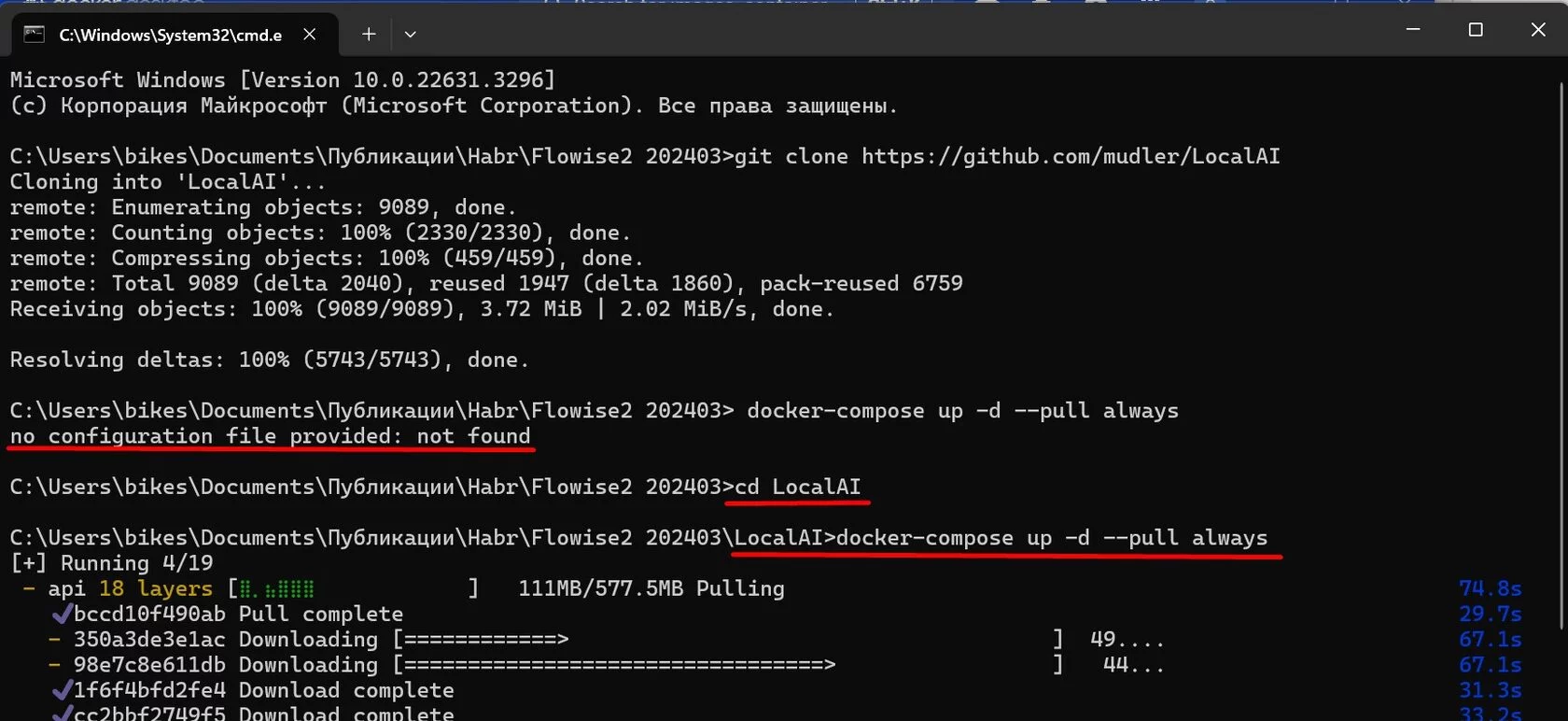
Скопируйте загруженный файл в папку models. Откройте командную строку в папке LocalAI и выполните команду: docker-compose up -d --pull always. Этой командой мы создадим и запустим контейнер. Она будет выполняться относительно долго в первый раз, это нормально. Важно находиться в правильной папке:
По окончании процесса в интерфейсе Docker вы увидите запущенный LocalAI, он доступен через порт 8080:
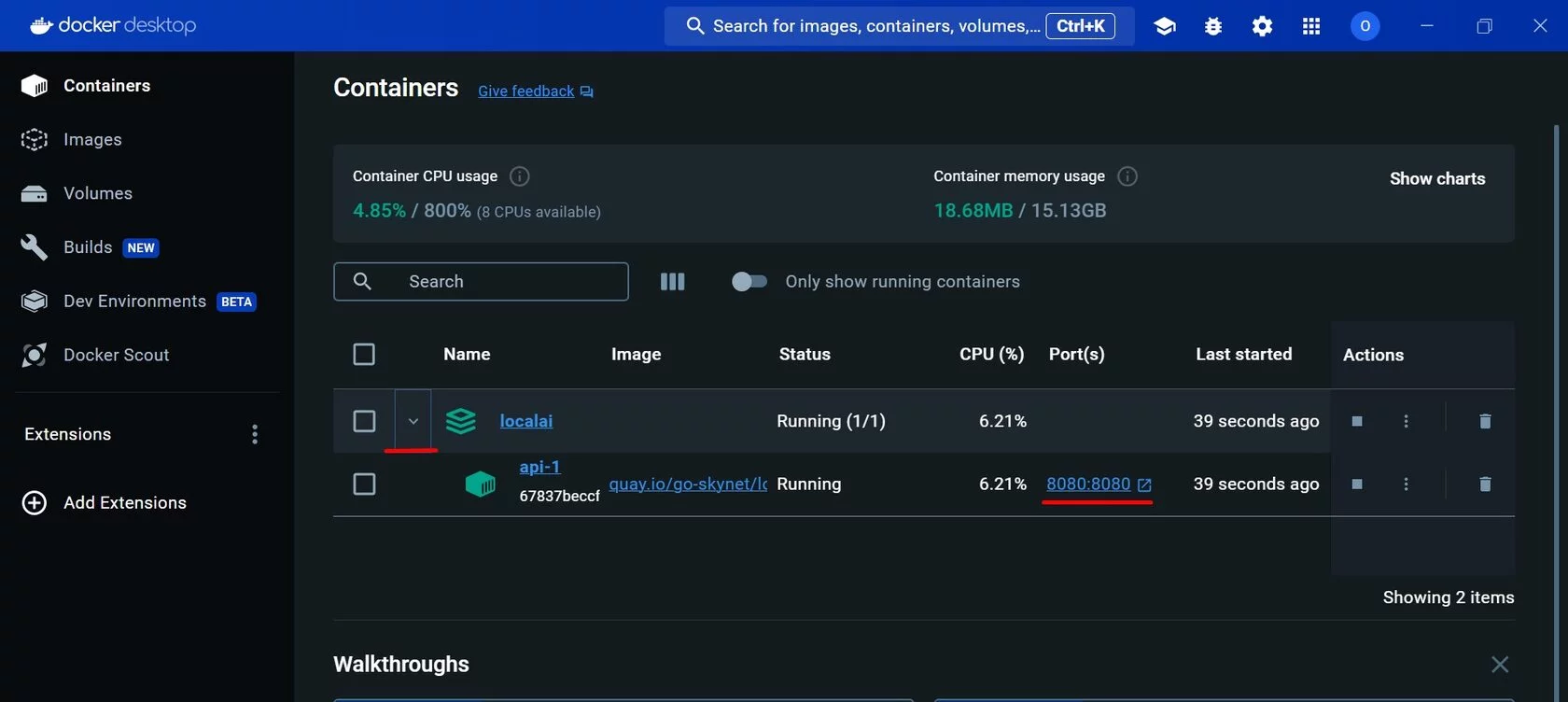
Далее строим чатфлоу во Flowise, для примера нам понадобятся блоки:
1/ Chains -> LLM chain
2/ Chat Models -> ChatLocalAI
3/ Prompts -> Prompt template
Где взять Credentials для ChatLocalAI:
В поле Connect credentials я не сразу понял что вписать, в документации ничего не нашёл, но ребята в Дискорде помогли - вписывайте `sk-xxx` вместо API-ключа, будет работать (на момент публикации задача с ключами ещё в работе у создателей).
В поле `Basepath` нужно вписать `http://localhost:8080`, порт может быть другим, проверяйте его в Docker.
Название модели можно найти на странице http://localhost:8080, перейдите на неё в браузере и найдёте спискок моделей, а в нём и название.
Простейший пример использования - генерация текста по слову. Я использовал промпт для генерации шутки, во взрослом мире можно сгенерировать себе синонимы, антонимы...и так далее и тому подобное.
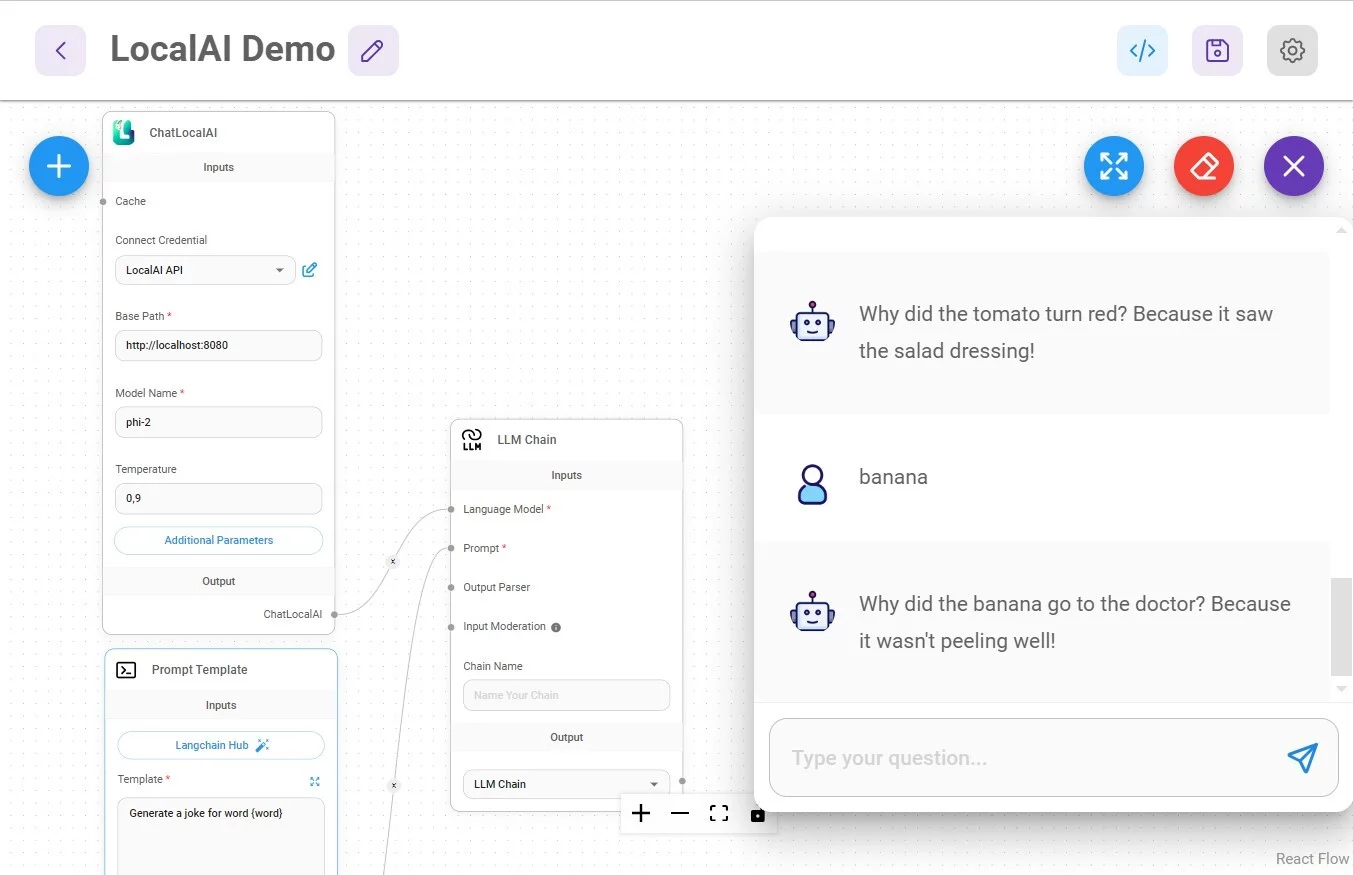
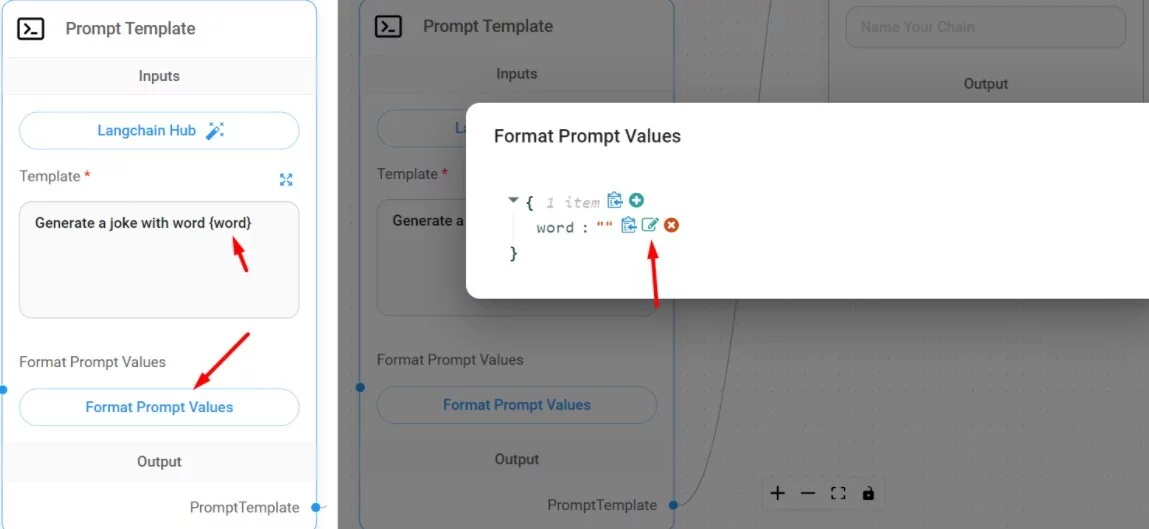
Важный момент. Prompt Template использует переменную `word`. В эту переменную передаётся слово, которое отправляет пользователь в чате. Как это сделать - используйте фигурные скобки для переменных. Чтобы обозначить что передавать в переменную, кликайте `Format prompt value` и затем иконку редактирования возле нужной вам переменной (в моём случае она одна).
Затем выбирайте нужный вариант, для моего случая это question:
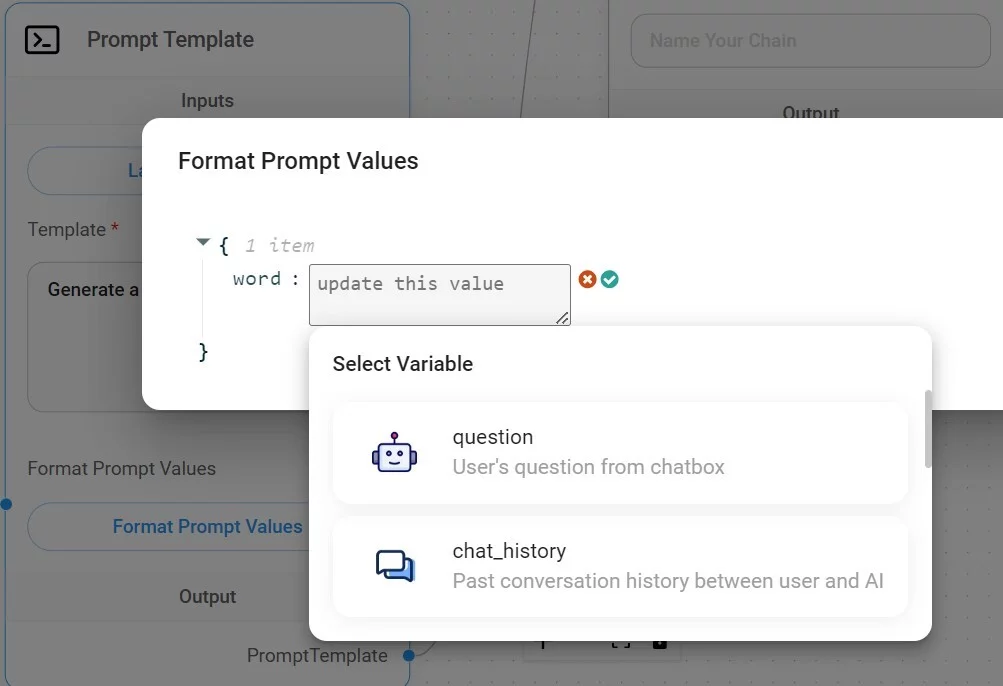
После сохранения чатфлоу готов к использованию.
Кейс 2 - Ollama.
Ollama, как и LocalAI, позволяет запускать модели локально.
Переходите на сайт Ollama и загружайте версию для вашей операционной системы. Затем запускайте скачанный файл и следуйте инструкциям.
После установки нужно выбрать модель для загрузки. Это крайне важный момент, модели могут потребовать много ресурсов, потому оценивайте свободное место на диске вашей конкретной машины. Моделей много и они разные, читайте описание, смотрите на размер.
Я буду использовать llama2. Версия 7b занимает 3.8Gb, но если смотреть в описание ниже - потребует около 8Gb дискового пространства.
Скопируйте строку для запуска модели:
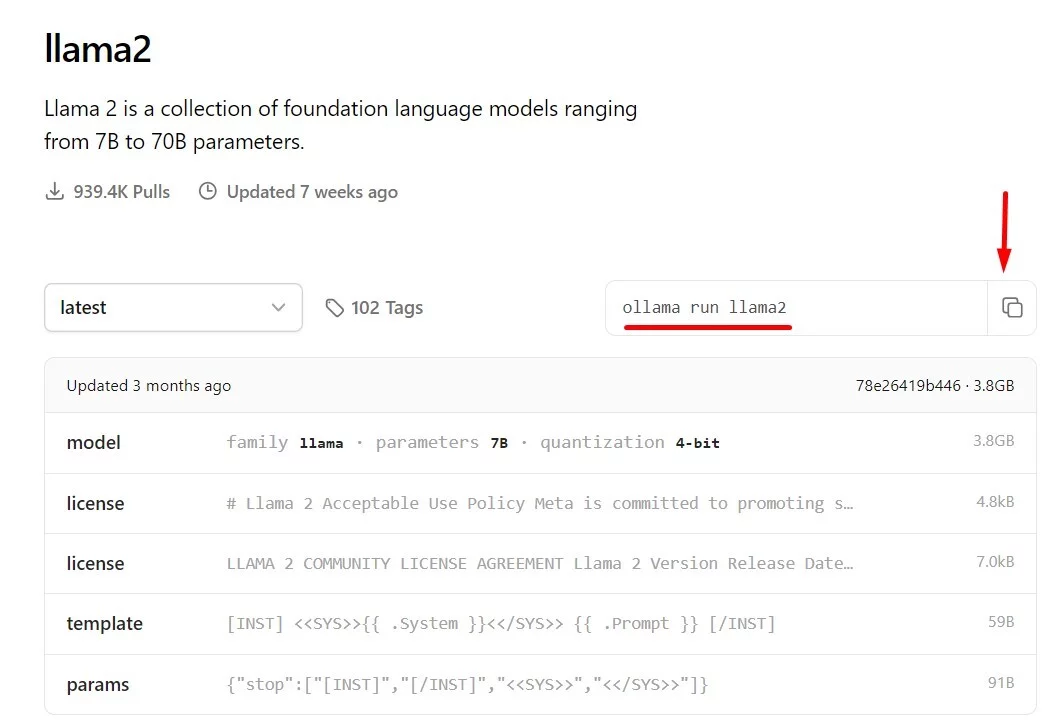
Затем откройте командную строку, вставьте и выполните команду. Ollama загрузит и установит модель:
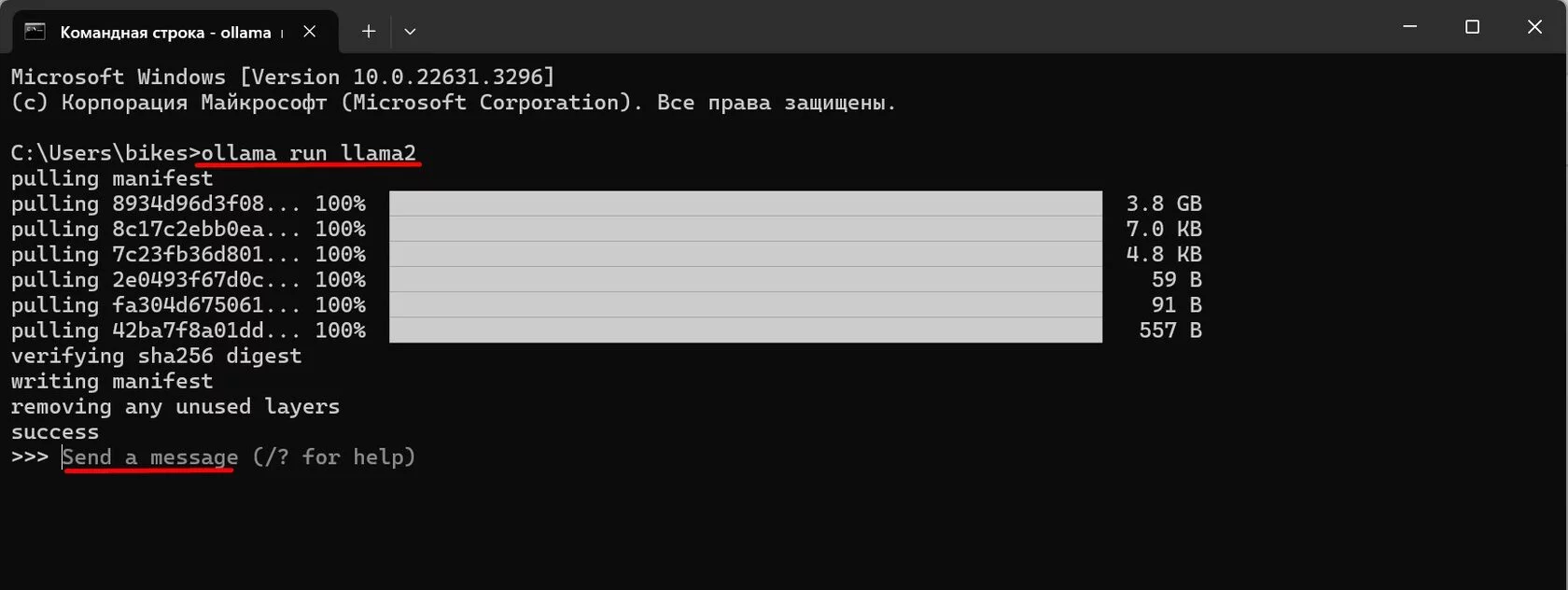
Когда модель загрузится, вы сможете пообщаться с ней в командной строке. Это удобно, чтобы быстро потестировать ответы модели. Чтобы остановить общение - можно использовать Ctrl+D или закрыть командную строку, чтобы остановить формирование ответа - Ctrl+C:
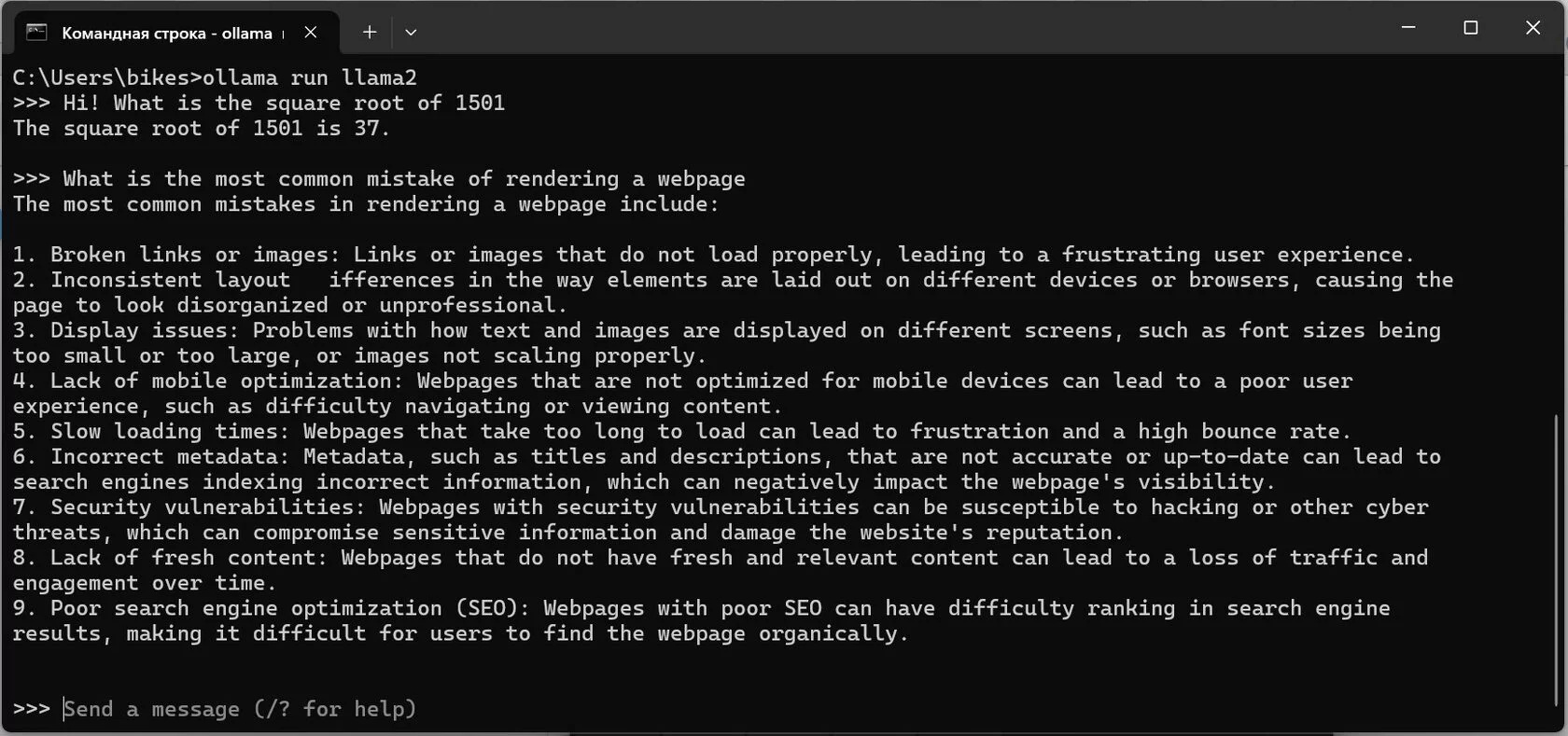
Но в таком состоянии модель пока недоступна для Flowise. Чтобы запустить её локально, выполните в командной строке ollama serve. Ошибка вроде Error: listen tcp 127.0.0.1:11434: bind: Only one usage of each socket address (protocol/network address/port) is normally permitted. означает, что Ollama уже запущена. Чтобы проверить, можно перейти по адресу 127.0.0.1:11434 в браузере.

Убедившись, что Ollama запущена, построим чатфлоу на Flowise. Обратите внимание, что только Flowise, запущенный локально (на localhost) может иметь доступ к модели. Если ваш инстанс Flowise запущен на Render или ещё где-то, вы не сможете использовать эту модель.
Для того, чтобы построить Q&A чат-бот, который работает локально, нам потребуются блоки:
1/ Chains -> Conversational Retriever Q&A Chain
2/ Chat Models -> Chat Ollama
3/ Vector Stores -> In-Memory Vector Store
4/ Embeddings -> Ollama Embeddings
5/ Document loaders -> Text Files, загрузите файл, по которому будете задавать вопросы
6/ Text Splitters -> Recursive Character Text Splitter
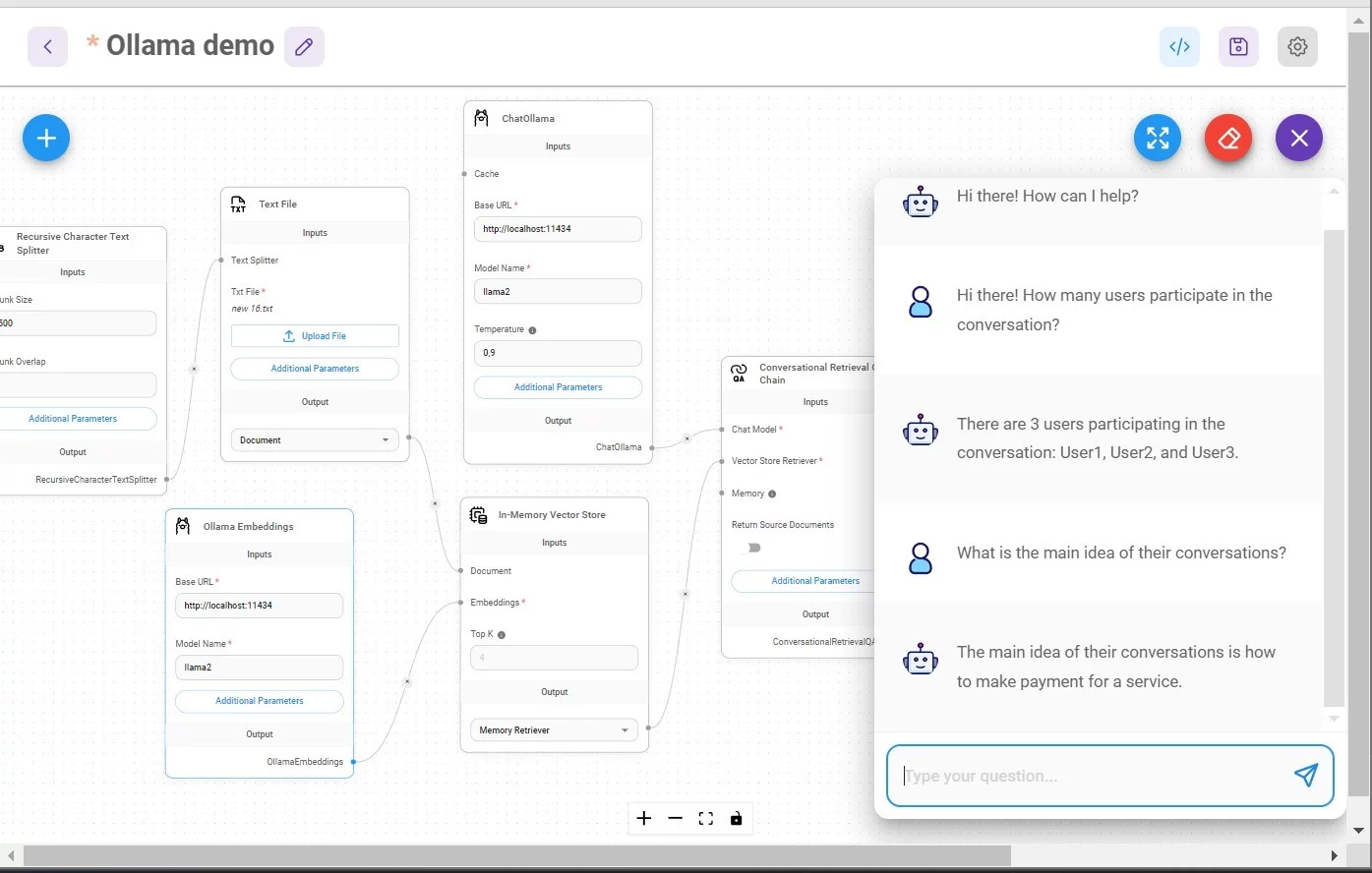
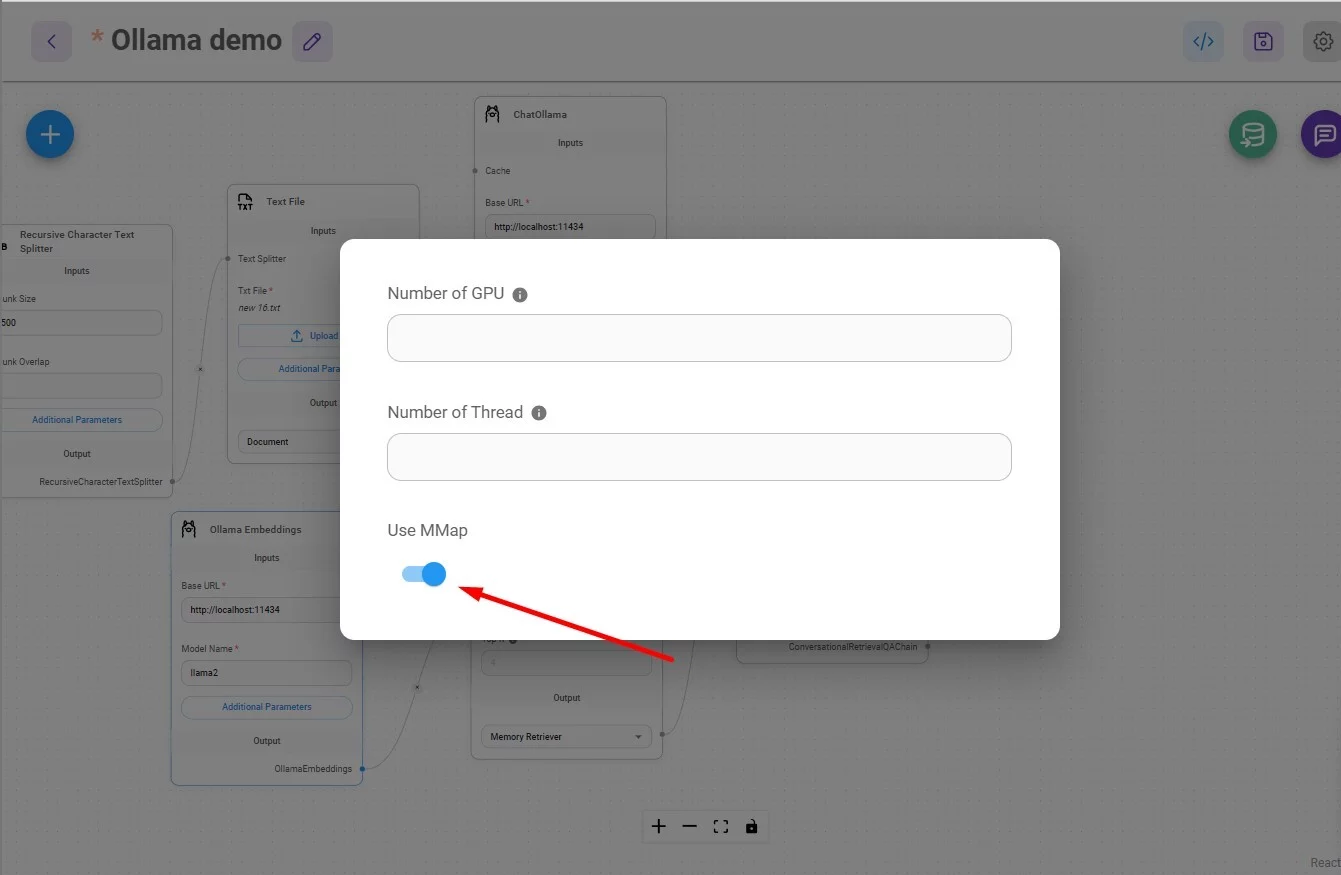
Также важно в Ollama Embeddings включить параметр MMap:
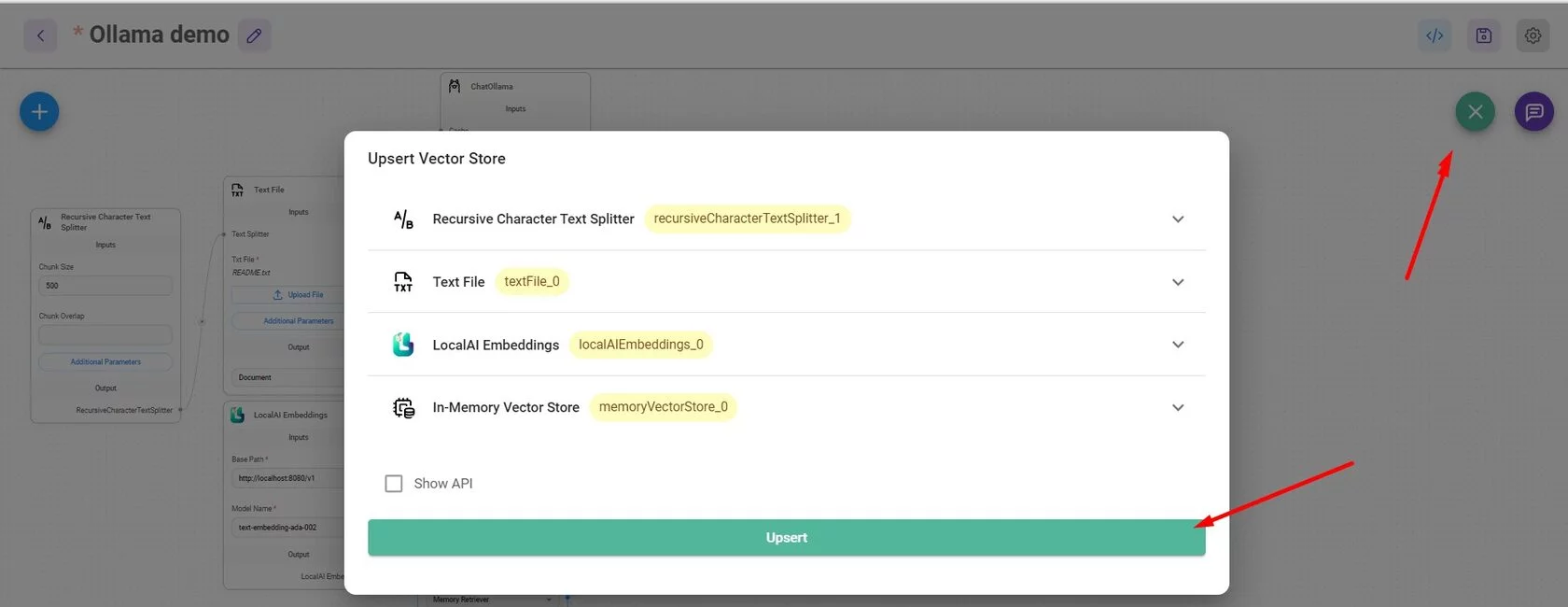
Не забудьте загрузить данные в Vector Storе:
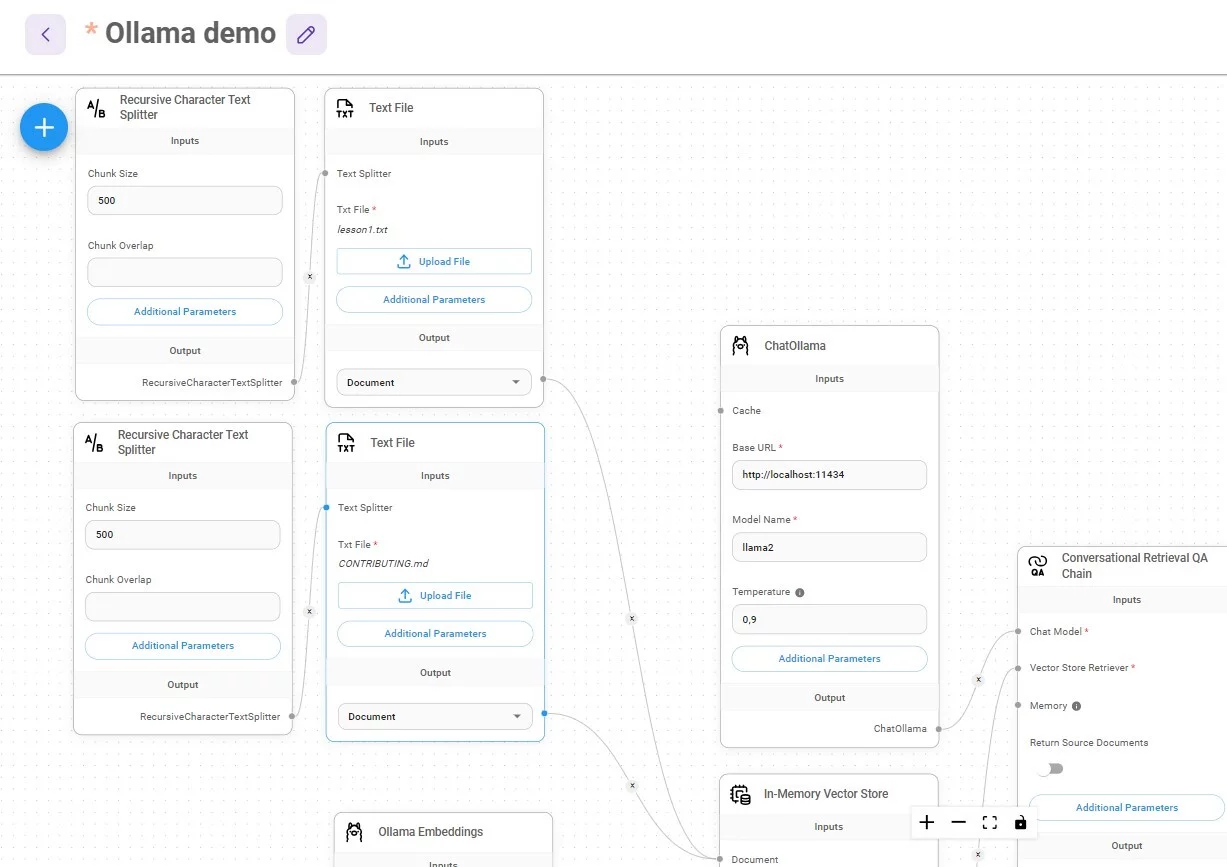
Загружайте файлы и пробуйте. Если вам нужно загрузить несколько документов, просто повторите два или больше блоков с текстовым файлом и сплиттером:
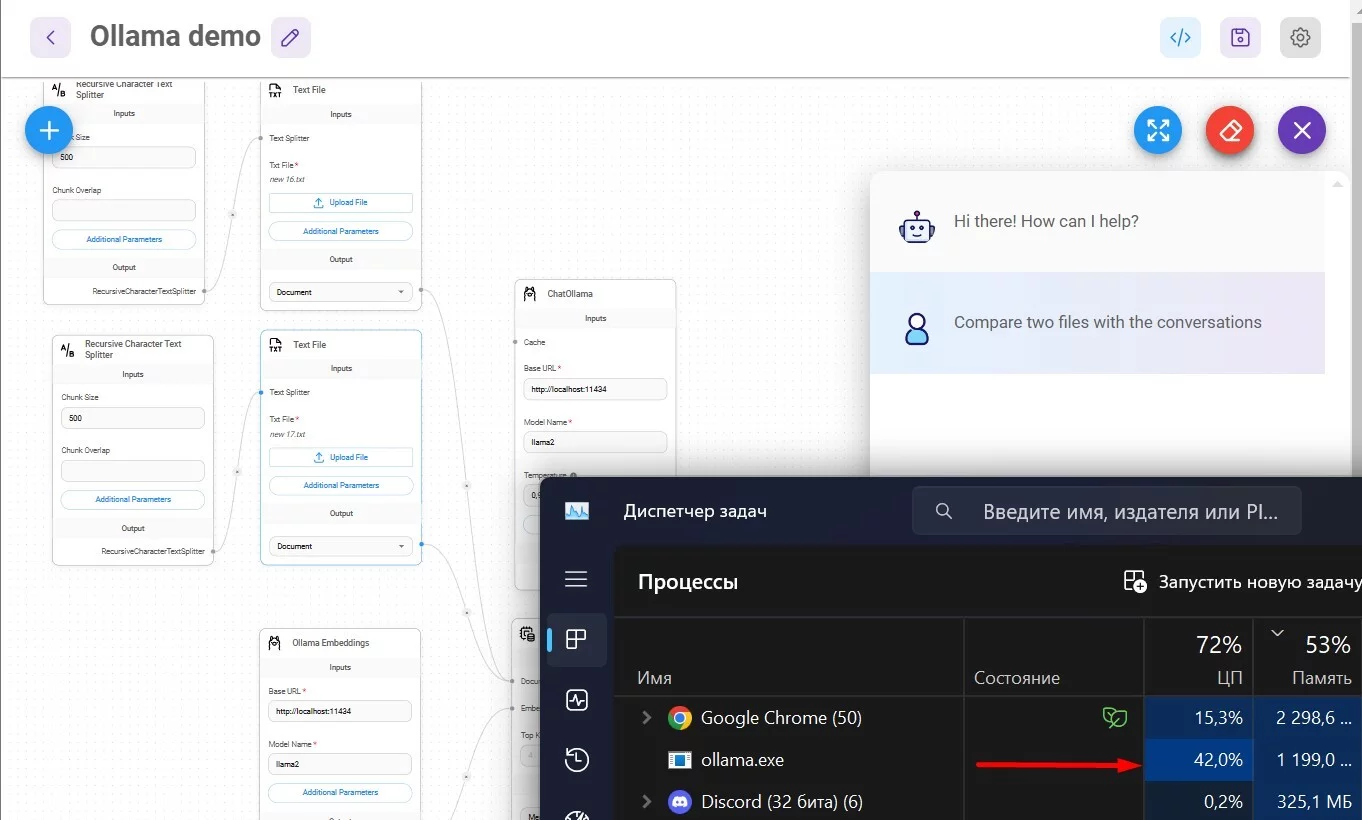
Важно помнить о том, что локально - это за счёт ваших памяти и процессора. Будет больно при попытке обработки больших файлов на слабых машинах. Ниже пример обработки 2х небольших файлов с беседами саппорта в чатах:
И результат:
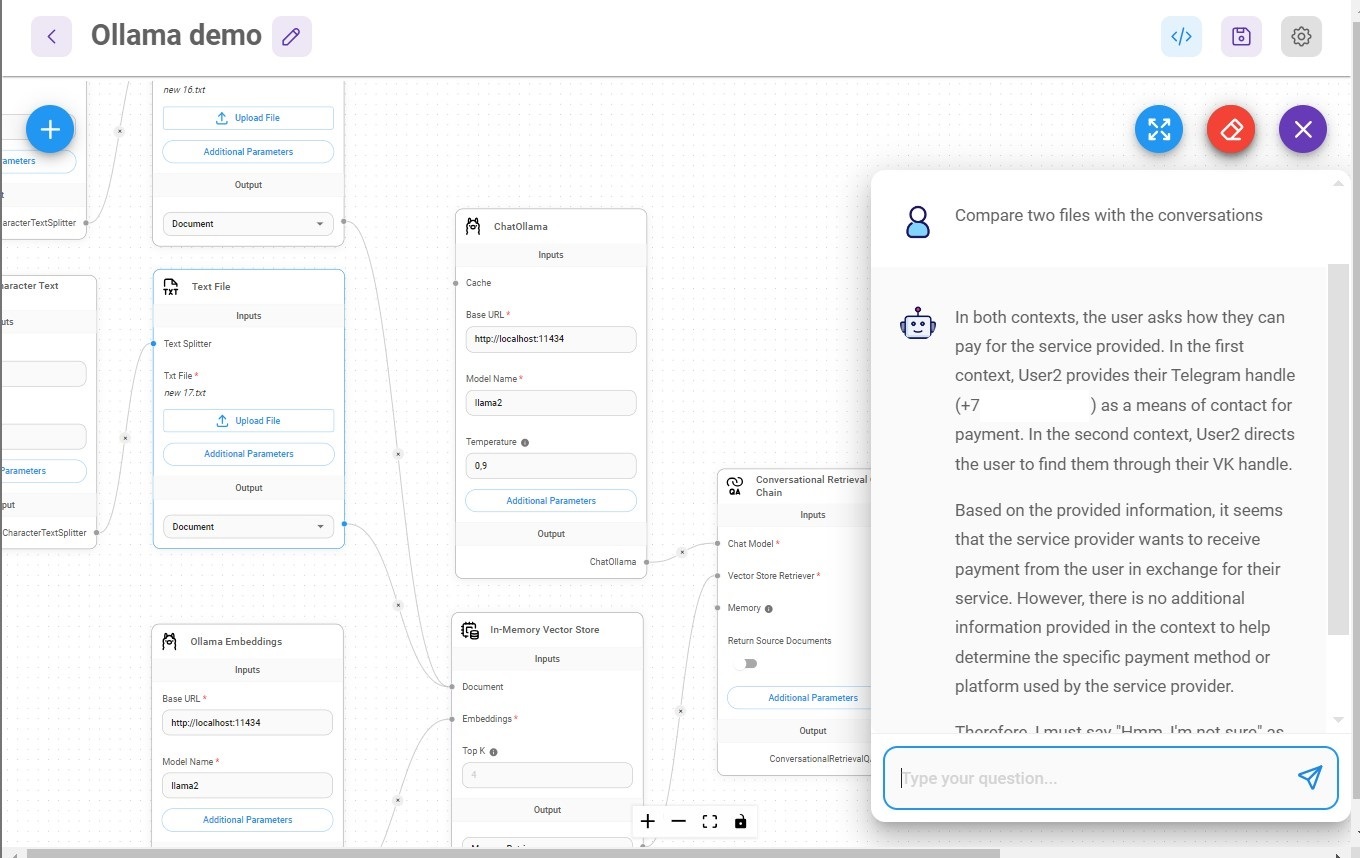
Итого. Нам всё сложнее найти место или ситуацию, где мы вынужденно находимся в оффлайне. Со мной периодически такое случается, и в этот момент локальная модель позволяет мне продуктивно работать. Надеюсь, и для вас этот материал будет полезен.



koo
Ну, это же не только вопрос онлайна-офлайн, но и вопрос конфиденциальности. Бывают же ситуации, когда ты не хочешь или не можешь передавать данные куда-либо...
vlad_bik Автор
Согласен, просто такой потребности лично у меня нет, поэтому она описана только в одной фразе во вступлении.